动手写数据库:实现记录管理
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动手写数据库:实现记录管理相关的知识,希望对你有一定的参考价值。
在数据库中,数据以”记录“作为一个单元来存储,例如一个表的“一行”就对应一条记录。假设我们有一个表叫STUDENT,其中有name, age, sex, class等字段,那么一条记录的信息就由这四个字段对应的信息合成。一条记录如何存储并不是一个简单的事情,例如我们需要考虑如下因素:
1,一条记录是否应该全部存储在一个区块中
2,一个区块存储的记录是否应该全部来自同一张表
3,记录中每个自动的大小是否应该固定
4,一条记录中的字段如何组织,在上面例子一条记录不一定以name,age,sex,class这样的次序存储
假设一个区块的大小是1000字节,现在我们有4条300字节的记录需要存储,前三条记录总共900字节可以存在区块中,第四条应该怎么存储,它是一部分存在第一个区块,另一部分存在第二个区块,还是全部存储到第二个区块?第二种方法的缺点是我们必须浪费区块1中的最后100字节,但是如果采用第一种方案,缺点就是读写复杂度会比较高,同时读取一条记录可能要访问多个区块这样会降低读写效率。
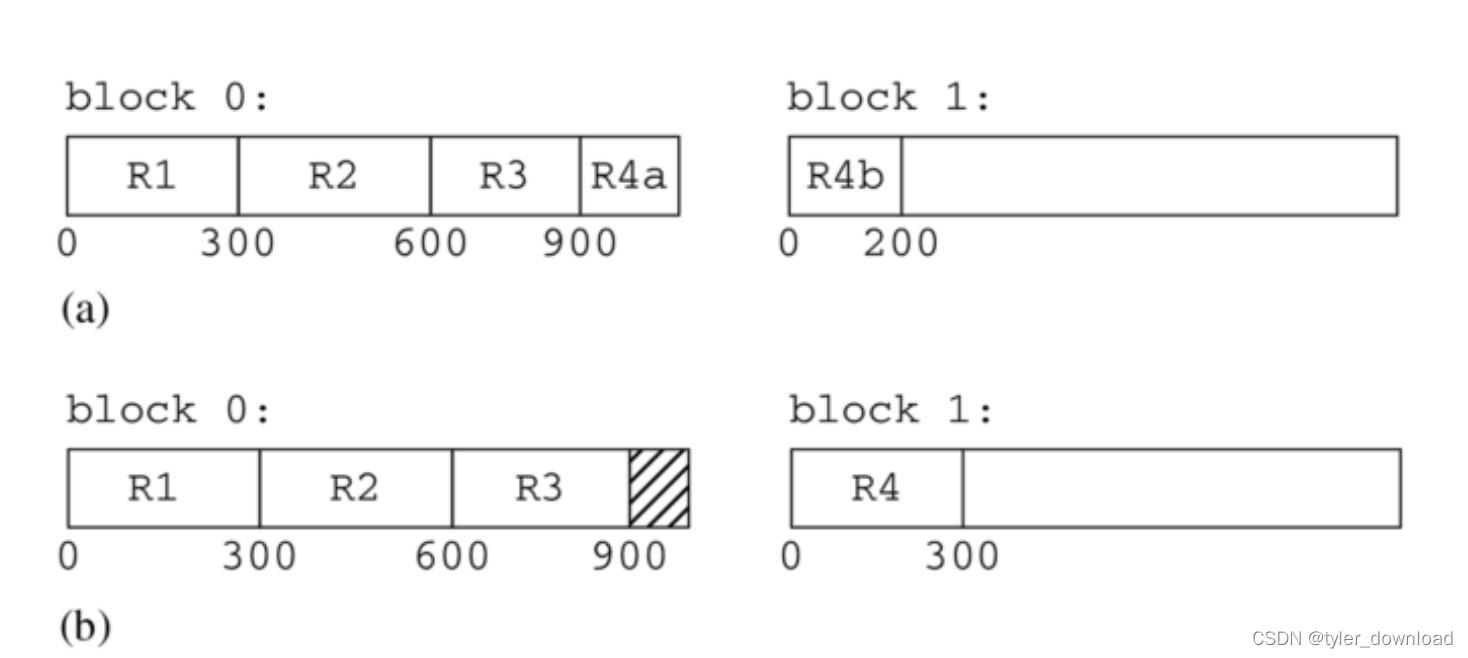
此外还需要考虑的是,一个文件的所有区块都用来存储同一张表的记录,还是用来存储不同表的记录,这两种选择前者好处是方便,后者好处是效率。使用前者我们能很方便的获取同一张表的记录,但是如果我们要做多表操作,例如执行两表的join操作后者的效率就会好很多。
第三个需要考虑的是,记录是固定长度还是可变长度,固定长度意味着无论字段是何种类型,它对应预先给定大小的缓存,如果存入字段的数据长度大于给定长度,那么存入的数据就会被”截断“,两者的主要区别还是复杂度,可变长度的记录其处理起来要比固定长度麻烦很多。例如对于可变长度的记录就意味着数据库允许存入字段的数据变大,极端情况下数据库可能要把处于当前区块中的记录全部迁移到其他区块,以便空出空间来给变长的字段。
在标准SQL中提供了三种数据类型,分别为char(n),它表示要存储的字符串正好有n个字符,varchar(n), clob(n)表示最多存储n个字符,只不过varchar对应的n一般不超过4k,而clob对应的n一般达到几个G。
接下来我们看几种记录的管理实现机制,第一种设计方式针对固定长度的记录,在这种实现模式中,我们规定一个文件所有区块都存储来自同一张表的记录,同时记录采用固定长度,也就是任何一个记录都不会跨越两个区块,于是我们可以把一个区块看做是一个存储记录的数组,我们管这样的区块叫做record page。
这样我们在实现时就能讲区块分成多个”插槽“,每个插槽除了能装下一条记录外,还需要多增加一个字节用于表示这个插槽是否已经被使用。0表示插槽可用,1表示插槽被占用,我们可以把这样的区块想象成一个共享充电宝的柜子。看个具体例子,假设一个区块400字节,每个记录26字节,于是一个插槽就需要27字节,于是一个区块能放置14个插槽,同时有22字节会浪费掉:

我们从上图可以看到插槽1和2的占用标志位都是0,因此这两个插槽没有有效数据,记录管理器想要对记录进行增删改时,它需要使用到如下信息:
1,一个插槽的大小
2,记录中每个字段的名称,类型,长度以及字段在记录中的偏移
上面这些信息我们称之为一个记录的layout,有了记录的layout信息后,管理器就能迅速定位给定记录中的给定字段,假设记录在的编号为k,那么记录的起始位置就是 RL * K,其中RL就是一条记录的长度,假设我们要获取记录中的字段F,那么字段在区块中的位置就是RL * K + Offset(F)。
于是管理器对记录的增删改就可以依照下面的步骤执行:
1,要插入一条记录,管理器可以遍历区块中的每个插槽,如果其对应占用标志位为0,那么我们把记录的数据存储到插槽中,然后将标志位设置为1,如果所有插槽的占用标志位都是1,那么该区块就没有位置让记录插入。
2,要删除一条记录非常简单,将其对应占用标志位设置为0即可。
3,要更改一条记录的某个字段,管理器可以使用前面描述的方法找到字段对应位置然后就行修改
4,要获取某个记录,管理器找到对应插槽,查看其占用标志位是否被设置为1,是的话就能讲数据取出。
另外一种记录管理的实现策略是字段可变长。前面我们描述的情况是记录字段长度必须固定,如果字段长度不固定,那么前面描述的定位方法就必然失效。因此在字段可变长情况下,记录的定位或查找需要特定设计。在记录可变长的情况下,我们不能再像定长记录那样直接查找其地址,同时如果记录变长后,它所在的区块可能装不下它,于是它就必须要跨区块,这时我们需要为其分配一个溢出区块,在代码设计上我们会专门开辟一个”溢出区间“,一旦有记录变长需要跨区块时,新分配的区块就会从”溢出区间“获取。如果记录变得过长必须要跨越多个区块的话,那么我们就从溢出区间分配多个区块,这些区块之间通过指针链接在一起形成一个队列。
我们看一个具体例子,假设数据库有一个表用来记录课程,它由三个字段组成,分别是“编号”,“时长”,和“课程名称”,字段“课程名称”是可变长字段,一开始表内有三条记录:

注意每条记录起始一个字节是占用标志位,第一条记录对应课程名称字段的内容是"DbSys",假设后面这个名称改为"Database Systems Implementation", 并且假设区块长度只有80字节,于是第一条记录长度变更后,第三条记录就不能只存储在当前区块中,于是我们分配一个新区块,将第三条记录放在新区块,同时就区块用一个指针指向新区块:
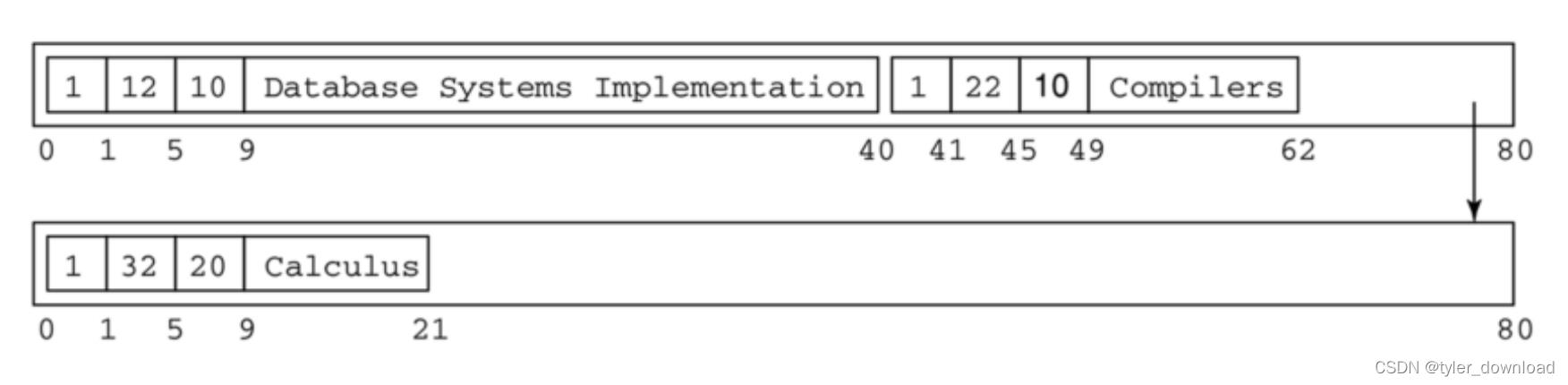
对可变长记录的处理还有一个难点那就是寻址。如果记录是固定长度,那么给定记录的插槽号,我们就能迅速定位记录的起始地址,但是记录可变长的话,我们就无法“一锤定音”的获取其起始地址,解决办法是引入一个id-table,它是一个一维数组,元素的标号对应记录的插槽号,元素的值对应记录的起始地址,具体例子如下:
含有"Calculus"的记录插槽号为2,于是我们在id-table下标为2的元素中查看其起始位置,可以看到id-table下标为2的元素值为43,也就是说插槽号为2的记录起始地址就是43,同理插槽号为0的记录我们就在id-table中下标为0的元素中读取,可以看到插槽号为0的记录其起始地址就是63,注意到这里我们去掉了“占用标志位”,如果某个插槽号对应的记录不存在,那么我们把id-table中相应元素的值设置为0即可,从上图看到id-table中下标为1的元素对应值为0,于是表明插槽号为1的记录不存在。
使用id-table来标记记录的位置信息可以使得我们对记录的管理更加灵活,例如要删除某条记录,我们只要将id-table中对应下标元素的值设置为0即可。同时这么做还能让记录在区块中的位置可以随意变换,假设我们要讲记录0挪到记录2的前面,那么我们只需要把两条记录互换位置后,将id-table中相应元素的值进行修改即可。在数据结构上,我们一般把id-table放在区块的开头,然后记录则从区块的末尾开始添加,于是id-table会随着记录的增多从左向右增长,而记录则会从区块末尾实现从右到左进行增长。
理论完毕,我们看看具体的代码实现。首先我们使用两个类Schema和Layout来管理记录的信息,例如记录包含哪些字段等,我们看看这两个类要实现的接口,在工程目录下创建文件夹record_manager,然后添加文件interface.go,添加内容如下:
package record_manager
type SchemaInterface interface
AddField(field_name string, field_type int, length int)
AddIntField(field_name string)
AddStringField(field_name string, length int)
Add(field_name string, sch *SchemaInterface)
AddAll(sch *SchemaInterface)
Fields() []string
HasFields(field_name string)
Type(field_name string) int
Length(field_name string) int
type LayoutInterface interface
Schema() *Schema
Offset(field_name string) int
SlotSize() int
Schema类将用来描述给定表中一条记录包含哪些字段,Layout用来计算字段相关信息,例如在区块中的偏移,长度等,下面我们看看他们的具体实现,创建schema.go,实现代码如下:
package record_manager
type FIELD_TYPE int
const (
INTEGER FIELD_TYPE = iota
VARCHAR
)
type FieldInfo struct
field_type FIELD_TYPE
length int
func newFieldInfo(field_type FIELD_TYPE, length int) *FieldInfo
return &FieldInfo
field_type: field_type,
length: length,
type Schema struct
fields []string
info map[string]*FieldInfo
func NewSchema() *Schema
return &Schema
fields: make([]string, 0),
info: make(map[string]*FieldInfo),
func (s *Schema) AddField(field_name string, field_type FIELD_TYPE, length int)
s.fields = append(s.fields, field_name);
s.info[field_name] = newFieldInfo(field_type, length)
func (s *Schema) AddIntField(field_name string)
//对于整型字段而言,长度没有作用
s.AddField(field_name, INTEGER, 0)
func (s *Schema) AddStringField(field_name string, length int)
s.AddField(field_name, VARCHAR, length)
func (s *Schema) Add(field_name string, sch SchemaInterface)
field_type := sch.Type(field_name)
length := sch.Length(field_name)
s.AddField(field_name, field_type, length)
func (s *Schema) AddAll(sch SchemaInterface)
fields := sch.Fields()
for _, value := range fields
s.Add(value, sch)
func (s *Schema) Fields() []string
return s.fields
func (s *Schema)HasField(field_name string) bool
for _, value := range s.fields
if value == field_name
return true
return false
func (s *Schema) Type(field_name string) FIELD_TYPE
return s.info[field_name].field_type
func (s *Schema) Length(field_name string) int
return s.info[field_name].length
下面我们看看Layout的实现,添加layout.go文件,实现代码如下:
package record_manager
import (
"file_manager"
"tx"
)
const (
BYTES_OF_INT = 8
)
type Layout struct
schema SchemaInterface
offsets map[string]int
slot_size int
func NewLayoutWithSchema(schema SchemaInterface) *Layout
layout := &Layout
schema: schema,
offsets: make(map[string]int),
slot_size: 0,
fields := schema.Fields()
pos := tx.UINT64_LENGTH //使用1个int类型作为使用标志位,它占据8个字节
for i := 0; i < len(fields); i++
layout.offsets[fields[i]] = pos
pos += layout.lengthInBytes(fields[i])
layout.slot_size = pos
return layout
func NewLayout(schema SchemaInterface, offsets map[string]int, slot_size int) *Layout
return &Layout
schema: schema,
offsets: offsets,
slot_size: slot_size,
func (l *Layout) Schema() SchemaInterface
return l.schema
func (l *Layout) SlotSize() int
return l.slot_size
func (l *Layout) Offset(field_name string) int
offset, ok := l.offsets[field_name]
if !ok
return -1
return offset
func (l *Layout) lengthInBytes(field_name string) int
fld_type := l.schema.Type(field_name)
p := file_manager.NewPageBySize(1)
if fld_type == INTEGER
return BYTES_OF_INT //int 类型占用8个字节
else
//先获取字段内容的长度
field_len := l.schema.Length(field_name)
/*
因为是varchar类型,我们根据长度构造一个字符串,然后调用Page.MaxLengthForString
获得写入页面时的数据长度,回忆一下在将字符串数据写入页面时,我们需要先写入8个字节用于记录
写入字符串的长度
*/
dummy_str := string(make([]byte, field_len))
return int(p.MaxLengthForString(dummy_str))
Layout类的作用是根据shcema对象来获取给定字段的信息,例如字段的偏移,长度等,完成上面代码后,我们添加一个测试用例,生成layout_test.go,实现代码如下:
package record_manager
import (
"github.com/stretchr/testify/require"
"testing"
"tx"
)
func TestLayoutOffset(t *testing.T)
sch := NewSchema()
sch.AddIntField("A")
sch.AddStringField("B", 9)
sch.AddIntField("C")
layout := NewLayoutWithSchema(sch)
fields := sch.Fields()
/*
字段A前面用一个int做占用标志位,因此字段A的偏移是8,
字段A的类型是int,在go中该类型长度为8,因此字段B的偏移就是16
字段B是字符串类型,它的偏移是9,它自身长度为9,同时存入page时会
先存入8字节的无符号整形用来记录字符串的长度,因此字段C的偏移是16+8+9=33
*/
offsetA := layout.Offset(fields[0])
require.Equal(t, tx.UINT64_LENGTH, offsetA)
offsetB := layout.Offset(fields[1])
require.Equal(t, 16, offsetB)
offsetC := layout.Offset(fields[2])
require.Equal(t, 33, offsetC)
从测试用例的实现我们可以比较清晰的理解Schema,Layout这两个类的基本逻辑。下面我们看看如何使用代码管理记录在页面中的存储,我们使用RecordManager来管理记录在页面中的存储,其接口定义如下,在interface.go中添加如下代码:
type RecordManagerInterface interface
Block() *fm.BlockId //返回记录所在页面对应的区块
GetInt(slot int, fldName string) int //根据给定字段名取出其对应的int值
SetInt(slot int, fldName string, val int) //设定指定字段名的int值
GetString(slot int, fldName string) string //根据给定字段名获取其字符串内容
SetString(slot, fldName string, val string) //设置给定字段名的字符串内容
Format() //将所有插槽中的记录设定为默认值
Delete(slot int) //将给定插槽的占用标志位设置为0
NextAfter(slot int) //查找给定插槽之后第一个占用标志位为1的记录
InsertAfter(slot int) //查找给定插槽之后第一个占用标志位为0的记录
我们看看RecordPage的具体实现,创建record_page.go,创建代码如下:
package record_manager
import (
fm "file_manager"
"tx"
)
type SLOT_FLAG int
const (
EMPTY SLOT_FLAG = iota
USED
)
type RecordPage struct
tx *tx.Transation
blk *fm.BlockId
layout LayoutInterface
func NewRecordPage(tx *tx.Transation, blk *fm.BlockId, layout LayoutInterface) *RecordPage
return &RecordPage
tx: tx,
blk: blk,
layout: layout,
func (r *RecordPage) offset(slot int) uint64
return uint64(slot * r.layout.SlotSize())
func (r *RecordPage) GetInt(slot int, field_name string) int
field_pos := r.offset(slot) + uint64(r.layout.Offset(field_name))
val, err := r.tx.GetInt(r.blk, field_pos)
if err == nil
return int(val)
return -1
func (r *RecordPage) GetString(slot int, field_name string) string
field_pos := r.offset(slot) + uint64(r.layout.Offset(field_name))
val, _ := r.tx.GetString(r.blk, field_pos)
return val
func (r *RecordPage) SetInt(slot int, field_name string, val int)
field_pos := r.offset(slot) + uint64(r.layout.Offset(field_name))
r.tx.SetInt(r.blk, field_pos, int64(val), true)
func (r *RecordPage) SetString(slot int, field_name string, val string)
field_pos := r.offset(slot) + uint64(r.layout.Offset(field_name))
r.tx.SetString(r.blk, field_pos, val, true)
func (r *RecordPage) Delete(slot int)
r.setFlag(slot, EMPTY)
func (r *RecordPage) Format()
slot := 0
for r.isValidSlot(slot)
r.tx.SetInt(r.blk, r.offset(slot), int64(EMPTY), false)
sch := r.layout.Schema()
for _, field_name := range sch.Fields()
field_pos := r.offset(slot) + uint64(r.layout.Offset(field_name))
if sch.Type(field_name) == INTEGER
r.tx.SetInt(r.blk, field_pos, 0, false)
else
r.tx.SetString(r.blk, field_pos, "", false)
slot += 1
func (r *RecordPage) NextAfter(slot int) int
return r.searchAfter(slot, USED)
func (r *RecordPage) InsertAfter(slot int) int
new_slot := r.searchAfter(slot, EMPTY)
if new_slot >= 0
r.setFlag(new_slot, USED)
return new_slot
func (r *RecordPage) Block() *fm.BlockId
return r.blk
func (r *RecordPage) setFlag(slot int, flag SLOT_FLAG)
r.tx.SetInt(r.blk, r.offset(slot), int64(flag), true)
func (r *RecordPage) searchAfter(slot int, flag SLOT_FLAG) int
slot += 1
for r.isValidSlot(slot)
val, _ := r.tx.GetInt(r.blk, r.offset(slot))
if SLOT_FLAG(val) == flag
return slot
slot += 1
return -1
func (r *RecordPage) isValidSlot(slot int) bool
return r.offset(slot+1) <= r.tx.BlockSize()
代
以上是关于动手写数据库:实现记录管理的主要内容,如果未能解决你的问题,请参考以下文章