采用spring batch 处理大数据量,瓶颈在数据库吞吐量时,该如何优化?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了采用spring batch 处理大数据量,瓶颈在数据库吞吐量时,该如何优化?相关的知识,希望对你有一定的参考价值。
使用spring batch处理大数据量,数据库采用db2。
处理过程为:从一张千万级别数据量的表中读取百万数据,逐条数据处理后,批量插入另一张千万级别数据量的标准。
批处理量:目前设为10万。
现象:整个过程中,花费近半个小时,读取过程和写入过程的时间占了90%以上,处理过程只用了两三分钟。
临时处理:目前整个过程,采用db2的存储过程实现,只需要5分钟左右。
问题:采用spring batch 处理大数据量,瓶颈在数据库吞吐量时,该如何优化?
批处理框架 Spring Batch,数据迁移量过大如何保证内存?
点击关注公众号,实用技术文章及时了解
来源:blog.csdn.net/topdeveloperr/
article/details/88843186
概述
本篇博客是记录使用spring batch做数据迁移时时遇到的一个关键问题:数据迁移量大时如何保证内存。当我们在使用spring batch时,我们必须配置三个东西: reader,processor,和writer。
其中,reader用于从数据库中读数据,当数据量较小时,reader的逻辑不会对内存带来太多压力,但是当我们要去读的数据量非常大的时候,我们就不得不考虑内存等方面的问题,因为若数据量非常大,内存,执行时间等等都会受到影响。关于spring batch的基础知识和介绍请参考这篇博客:批处理框架 Spring Batch 这么强,你会用吗?
问题是什么
在上面的内容当中我们已经提到了,我们面临的问题是数据迁移量大时的内存问题。但是这样的描述非常笼统,因此博主决定将这一部分单独拎出来说。
在学习了spring batch的知识之后我们应该很清楚的一点是,每一个spring batch的step都包含如下的部分:

即读数据,处理数据,写数据。这三个步骤里面最可能会导致内存变大问题的无疑是读数据环节。读数据作为spring batch的数据输入,是整个spring batch job的开头逻辑。
若我们的数据量不大,如只有几十万条,那我们无疑不会面临内存问题,即便一次将所有数据加载到内存当中,占的内存也不会非常多,且spring batch数据迁移的速度非常之快,几十万条的数据往往是几十秒的时间就可以迁移完成。但是当数据量变大之后,问题就不一样了。
当我们的数据量达到数百万或上千万时,若一次性将所有数据全部读到内存当中,则会占据远远超出正常范围的非常大的内存。该问题示意图如下所示:

我们写的任何程序都会有一个运行内存,假设这个内存的总容量现在只有4g,而我们数据库里需要操作的数据有8g,那么无疑,一次性的将数据读出来就会出错。这便是需要考虑得问题。
Spring提供的reader实现
spring提供了非常丰富的Reader实现,其中比较常用的从数据库读数据的有JdbcCursorItemReader,JdbcPagingItemReader等。
JdbcCursorItemReader
使用JdbcCursorItemReader的示例代码如下:
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}
JdbcCursorItemReader的好处在于使用简单,但是我们从它的sql就能发现,JdbcCursorItemReader会一次把所有的数据全部拿回来,当数据量过大而服务器内存不够时,就会遇到下面无法分配内存的问题:

报错信息为:Resource exhaustion event:The JVM was unable to allocate memory from the heap. 意思就是需要分配内存的数据太多,但是无法找到足够的内存了。
反映在内存里,堆内存会呈现出如下的情况:

随着每一次数据读入,堆内存都会增大,原因就在于JdbcCursorItemReader一次性读回了所有的数据,返回之后就会存在一个对象里面,而这个对象的尺寸过大,因此直接进入了老年代。在数据迁移完成之前,这些数据都不会被回收。如下图所示:

毫无疑问,当我们的数据量大时不应该使用这种类型的reader来读取数据。推荐:Java进阶资源
JdbcPagingItemReader
JdbcPagingItemReader的作用和它的名字一样,它可以分页读取数据,但是使用起来相比于JdbcCursorItemReader更加复杂,示例代码如下:
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}
可以看到我们能够设置page的大小,JdbcPagingItemReader将根据这个页的大小,每次读取这么多的数据,因此这些数据返回保存的对象,就只会是小对象,因此他们不会直接在老年代里分配,而是先分配在年轻代,随着年轻代不断变大,minor gc也不断进行,回收掉已经处理完的数据,老年代的内存使用量不会有任何增大,类似下图:
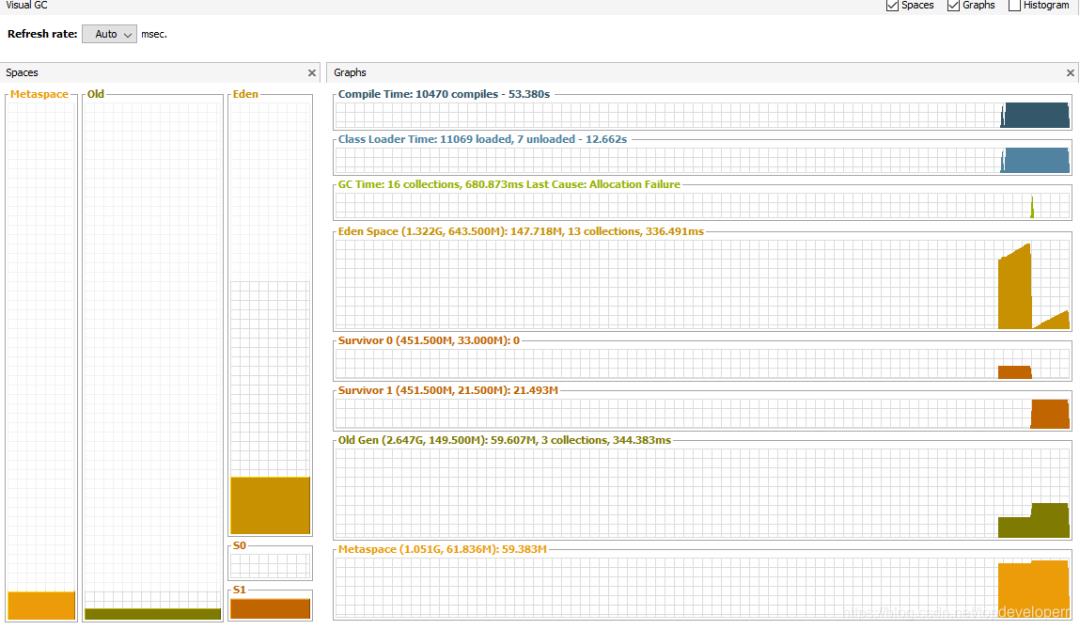
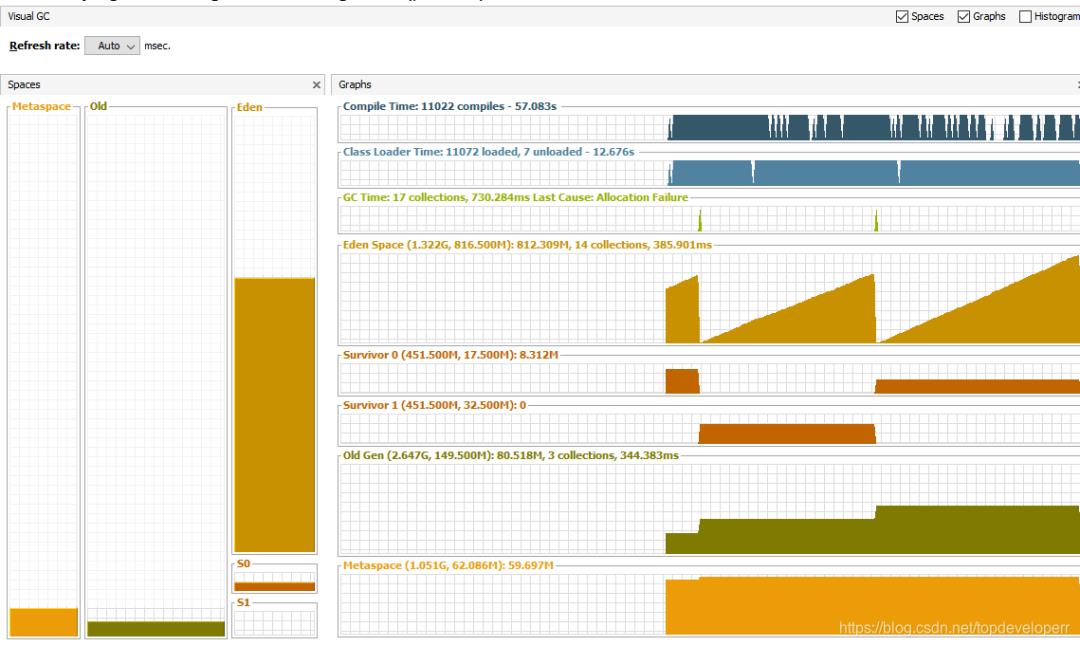
老年代内存不会有任何变化,年轻带会随着服务器数据迁移进行而增大同时被回收。
在使用JdbcPagingItemReader时,有一个必须注意的地方就是排序关键字是必须指定的,原因在于排序是分页实现原理的技术基础。sortKey和我们指定的其他字句一起构建出SQL语句出来。在sortKey上必须使用unique key constraint约束,因为只有这样才能得以确保执行之间不会丢失任何数据。这也可以说是JdbcCursorItemReader相对便利的一点优势。
总结
数据量小时选择的方案差别不会很大,当数据量大时,为了有好的内存表现则使用分页的reader是必要的。但同时,因为要实现分页,也会带来一些不可避免的限制。
欢迎一键三连
推荐:

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
以上是关于采用spring batch 处理大数据量,瓶颈在数据库吞吐量时,该如何优化?的主要内容,如果未能解决你的问题,请参考以下文章