MongoDB集群架构
Posted 小强同志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB集群架构相关的知识,希望对你有一定的参考价值。
一、MongoDB 复制集特性
- 复制集群的架构
- 复制集群搭建
- 复制集群的选举配置
1.复制集群的架构

2.复制集群搭建基础示例
2.复制集群搭建基础示例
主节点配置
dbpath=/data/mongo/master
port=27017
fork=true
logpath=master.log
replSet=MyCluster
从节点配置
dbpath=/data/mongo/slave
port=27018
fork=true
logpath=slave.log
replSet=MyCluster
#子节点配置2
dbpath=/data/mongo/slave2
port=27019
fork=true
logpath=slave2.log
replSet=MyCluster
- 分别启动三个节点
- 进入其中一个节点
集群复制配置管理
#查看复制集群的帮助方法
rs.help()
添加配置
// 声明配置变量
var cfg ="_id":"tuling",
"members":[
"_id":1,"host":"127.0.0.1:27017",
"_id":2,"host":"127.0.0.1:27018"
]
// 初始化配置
rs.initiate(cfg)
// 查看集群状态
rs.status()
变更节点示例:
// 插入新的复制节点
rs.add("127.0.0.1:27019")
// 删除slave 节点
rs.remove("127.0.0.1:27019")
注:默认节点下从节点不能读取数据。调用 rs.slaveOk() 解决。
3.复制集群选举操作
为了保证高可用,在集群当中如果主节点挂掉后,会自动 在从节点中选举一个 重新做为主节点。
- 演示节点的切换操作
- kill 主节点
- 进入从节点查看集群状态 。rs.status()
选举的原理:
选举协议
pv0: 基于priority 和 optime 选举新主,依赖clock synchronization。
有选举权的节点,每一轮选举最多投一票,在30s内,不能重复投票。
pv1:基于Raft协议,每个成员都有 对候选主列表成员投赞成或者反对票,不是单方面否决选举,没有节点投反对票,且获得赞成票数超过有权投票节点总数的1/2,则能成为Primary。否则进入下一轮选举。
因使用了Raft协议,加快 back-to-back选主,减少整个选举新主所需花费的总时间,相应的会增加WriteConcern(w:1)rollback的可能性。
Raft将时间分为多个term,term以连续的整数来标识,每个term以一次election开始,如果有server被选为leader,则该term的剩余时间该server都是leader。
有些term里,可能并没有选出leader,这时候会开启一个新term来继续选主
2.怎么选举?
选举:
假设X是一个Secondary,那么X会定时检测是否需要选举自己成为Primary。其检测内容包括:
1) 是否集群中有其它节点认为自己是Primary?
2) X节点自己是否已经是Primary?
3) X节点自己是否有资格成为Primary?
如果这三个问题中的任何一个回答是否定的,那么X节点就不会试图把自己变成Primary。(也就是说,只有当X节点是一个能够当Primary 的secondary,并且其它节点都不是Primary时,X才会发起选举并选自己为Primary)。
投票规则:如果没有节点投反对票,且获得赞成票数超过有权投票节点总数的1/2,则能成为Primary。否则进入下一轮选举。
3.2之前(只支持pv0 协议):
|
|
影响选举的因素:
1)优先级(先看优先级,级别越高,优先为主,priority=0:表示不参与选举、不能成为主)
2)optime (如果优先级都相同,则有最新的 optime 的成为主) 注意:集群中 prority 最大,但是optime 不是最新的,落后集群其他最新optime超过10s的prority 最大也不能选为主。
3)心跳 (副本级中的每个member默认都是每2秒ping 其他节点,如果超过"heartbeatTimeoutSecs" : 10 默认是10秒没有回应,则标记节点不可达s_down)
网络分裂(Network Partition):
如果Primary在少数的那一组,那么次Primary会变成Secondary,多数节点(互相能通信)的那组选举新的主(Primary)。
例外情况:如发生网络分裂,被分裂的一组选举出一个新的Primary,老的Primary还没降级,这就出现了2个Primary,这就是脑裂现象。此时2个Primary都有写入,直到网络恢复后,若老主再次成为Primary,则脑裂过程中选举出的新Primary会回滚脑裂过程新写入的数据;若老主成为Secondary,则回滚老主脑裂过程新写入的数据。
>= 3.2开始:
支持pv0 协议、pv1协议,默认是pv1协议。
影响选举的因素:
1)Replication Election Protocol(从3.2开始支持protocolVersion: 1)
2)优先级(先看优先级,级别越高,优先为主,priority=0:表示不参与选举、不能成为主)
3)optime (如果优先级都相同,则有最新的 optime 的成为主)
4)心跳 (副本级中的每个member默认都是每2秒ping 其他节点,protocolVersion:0如果超过"heartbeatTimeoutSecs" : 10 默认是10秒 或者 protocolVersion:1时 electionTimeoutMillis 默认是10秒没有回应,则标记节点不可达s_down,类似Redis sentinel主观下线)
下面status的节点有资格成为选举者:
PRIMARY
SECONDARY
RECOVERING
ARBITER
ROLLBACK
什么时候发生选举主?
1)初始化副本集
2)修改了节点的priority (config.members[0].priority = 3)
3)网络分裂(当前的Primary和多数的节点不通,当前Primary变成Secondary多数节点的组重新选Primary)
4)当前主上执行rs.stepDown()
5)Secondary ping超过heartbeatTimeoutSecs 后不可达,则标记Primary s_down,发生选主
示例:
重新配置节点
var cfg ="_id":"tuling",
"protocolVersion" : 1,
"members":[
"_id":1,"host":"127.0.0.1:27017","priority":10,
"_id":2,"host":"127.0.0.1:27018","priority":0,
"_id":3,"host":"127.0.0.1:27019","priority":5,
"_id":4,"host":"127.0.0.1:27020","arbiterOnly":true
]
// 重新装载配置,并重新生成集群节点。
rs.reconfig(cfg)
//重新查看集群状态
rs.status()
节点说明:
PRIMARY 节点: 可以查询和新增数据
SECONDARY 节点:只能查询 不能新增 基于priority 权重可以被选为主节点
RBITER 节点: 不能查询数据 和新增数据 ,不能变成主节点
二、MongoDB 分片操作
知识点:
- 分片的概念
- mongodb 中的分片架构
- 分片示例
1.为什么需要分片?
随着数据的增长,单机实例的瓶颈是很明显的。可以通过复制的机制应对压力,但mongodb中单个集群的 节点数量限制到了12个以内,所以需要通过分片进一步横向扩展。此外分片也可节约磁盘的存储。
1.mongodb 中的分片架构

分片中的节点说明:
- 路由节点(mongos):用于分发用户的请求,起到反向代理的作用。
- 配置节点(config):用于存储分片的元数据信息,路由节点基于元数据信息 决定把请求发给哪个分片。(3.4版本之后,该节点,必须使用复制集。)
- 分片节点(shard):用于实际存储的节点,其每个数据块默认为64M,满了之后就会产生新的数据库。
2.分片示例流程:
- 配置 并启动config 节点集群
- 配置集群信息
- 配置并启动2个shard 节点
- 配置并启动路由节点
- 添加shard 节点
- 添加shard 数据库
- 添加shard 集合
- 插入测试数据
- 检查数据的分布
- 插入大批量数据查看shard 分布
- 设置shard 数据块为一M
- 插入10万条数据
配置 并启动config 节点集群
# 节点1 config1-37017.conf
dbpath=/data/mongo/config1
port=37017
fork=true
logpath=logs/config1.log
replSet=configCluster
configsvr=true
# 节点2 config2-37018.conf
dbpath=/data/mongo/config2
port=37018
fork=true
logpath=logs/config2.log
replSet=configCluster
configsvr=true
进入shell 并添加 config 集群配置:
var cfg ="_id":"configCluster",
"protocolVersion" : 1,
"members":[
"_id":0,"host":"127.0.0.1:37017",
"_id":1,"host":"127.0.0.1:37018"
]
// 重新装载配置,并重新生成集群。
rs.initiate(cfg)
# 配置 shard 节点集群==============
# 节点1 shard1-47017.conf
dbpath=/data/mongo/shard1
port=47017
fork=true
logpath=logs/shard1.log
shardsvr=true
# 节点2 shard2-47018.conf
dbpath=/data/mongo/shard2
port=47018
fork=true
logpath=logs/shard2.log
shardsvr=true
配置 路由节点 mongos ==============
# 节点 route-27017.conf
port=27017
bind_ip=0.0.0.0
fork=true
logpath=logs/route.log
configdb=conf/127.0.0.1:37017,127.0.0.1:37018
// 添加分片节点
sh.status()
sh.addShard("127.0.0.1:47017");
sh.addShard("127.0.0.1:47018");
为数据库开启分片功能
sh.enableSharding("tuling")
为指定集合开启分片功能
sh.shardCollection("tuling.emp","_id":1)
修改分片大小
use config
db.settings.find()
db.settings.save(_id:"chunksize",value:1)
尝试插入1万条数据:
for(var i=1;i<=100000;i++)
db.emp.insert("_id":i,"name":"copy"+i);
db.emp.createIndex(_id: 'hashed')
三、MongoDB用户权限管理
// 创建管理员用户
use admin;
db.createUser("user":"admin","pwd":"123456","roles":["root"])
#验证用户信息
db.auth("admin","123456")
#查看用户信息
db.getUsers()
# 修改密码
db.changeUserPassword("admin","123456")
以auth 方式启动mongod,需要添加auth=true 参数 ,mongdb 的权限体系才会起作用:
#以auth 方向启动mongod (也可以在mongo.conf 中添加auth=true 参数)
./bin/mongod -f conf/mongo.conf --auth
# 验证用户
use admin;
db.auth("admin","123456")
创建只读用户
db.createUser("user":"dev","pwd":"123456","roles":["read"])
重新登陆 验证用户权限
use demo;
db.auth("dev","123456")
Mongodb集群架构之副本集
本文介绍了热门的NoSQL数据库MongoDB的副本集这种分布式架构的一些概念和操作。主要内容包括:
MongoDB副本集相关概念
MongoDB副本集环境搭建
MongoDB副本集的读写分离
MongoDB副本集的故障转移
MongoDB副本集的优点
MongoDB副本集的缺点
1.副本集相关概念
主节点。
在一个副本集中,只有唯一一个主节点。主节点可以进行数据的写操作和读操作。副本集中各个节点的增伤改等配置必须在主节点进行。
从节点。
在一个副本集中,可以有一个或者多个从节点。从节点只允许读操作,不允许写操作。在主节点宕机后,会自动在从节点中产生一个新的主节点。
仲裁者。
在一个副本集中,仲裁者节点不保存数据,既不能读数据,也不能写数据。作用仅仅限于在从从节点选举主节点时担任仲裁作用。
副本集的工作原理。
(i)副本集中的主节点的oplog集合中记录了主节点中所有引起数据变化的变更操作,包括更新和插入数据。副本集中的从节点从主节点的oplog集合中复制这些操作,从而在从节点上重现这些操作。这就是副本集的数据同步的基本原理。
(ii)在 oplog集合中的每个记录都是有一个时间戳,从节点据此判断需要更新哪些数据。主节点的local数据库中的数据不会被复制到从节点上。
(iii)对于主节点而言,这些复制操作时异步进行的,相当于MySQL数据库中的异步复制模式,即主节点在写入数据时无需等待任何从节点复制操作完成,即可进行其它数据的写入操作。
(iv)从节点第1次同步时会做完整的数据同步,后续通常只做一部分最新数据的同步工作。当时当从节点复制延迟太大时会重新进行完整的数据同步。因为oplog集合是一个固定集合,即里面的文档数量的大小是有固定的限制的,不能超过某个大小。因此,当主节点上oplog集合写满了后,会清空这个oplog集合。如果在写满oplog之前,从节点没有跟上这个速度,则无法再利用oplog进行增量复制工作,这就是需要完整的数据同步的原因。
(v)数据回滚。
在主节点宕机后自动产生了新的主节点,这时整个副本集认为这个新的主节点的数据是最新的有效数据。如果其他从节点中的数据复制进度超过了这个心的主节点的进度,那么这些从节点将会自动回滚这些超过新主节点的数据。这个操作就是Mongodb中的数据回滚。
2.副本集环境搭建
现在通过在一台机器(Centos7)上部署三个mongodb节点,从而搭建一个最简单的mongodb副本集环境。
端口27017 主节点
端口27018 从节点
端口27019 仲裁节点
假定mongodb相关软件包已经安装完毕。
(1)首先建立如下图的目录结构,其中data和log都是空目录。
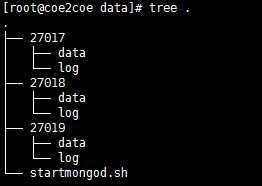
图1
建立如下所示的脚本文件,用于快速启动这3个节点。
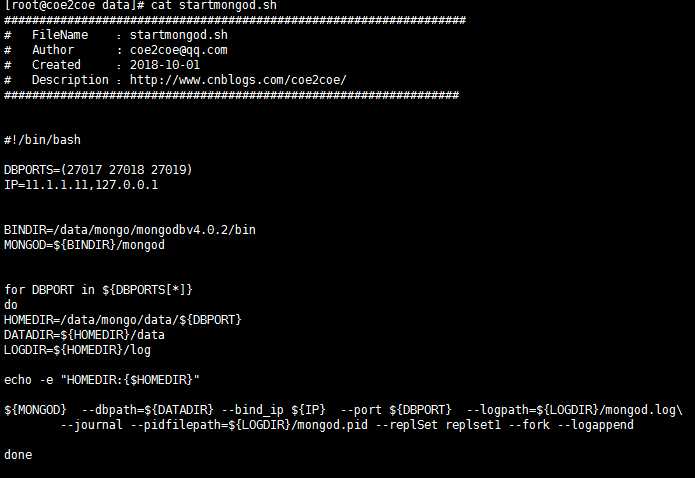
图2
启动3个节点。
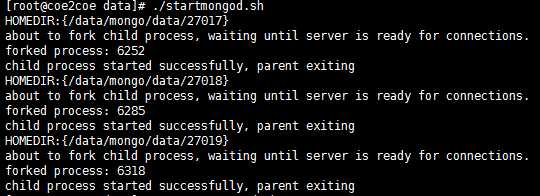
图3
配置副本集。
连接到主节点27017上,然后初始化副本集并且将另外的一个从节点27018和一个仲裁者节点27019加入到副本集中。
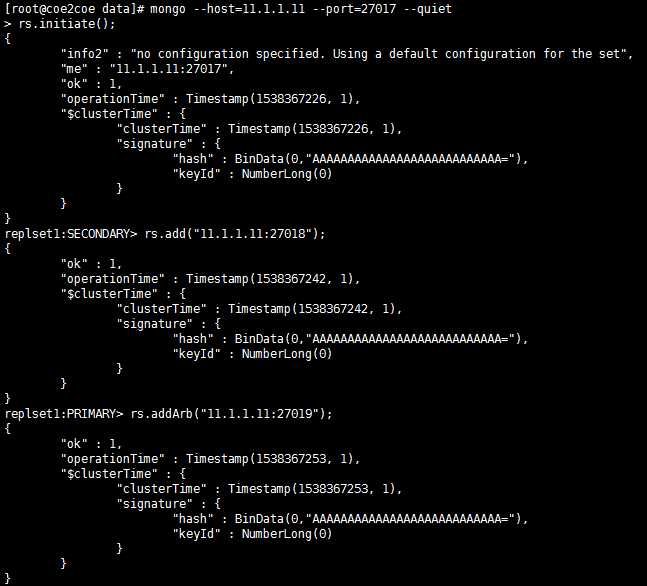
图4
查看副本集状态。
replset1:PRIMARY> rs.status();
{
"set" : "replset1",
"date" : ISODate("2018-10-01T04:14:17.567Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
}
},
"lastStableCheckpointTimestamp" : Timestamp(1538367228, 4),
"members" : [
{
"_id" : 0,
"name" : "11.1.1.11:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 260,
"optime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-10-01T04:14:13Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1538367226, 2),
"electionDate" : ISODate("2018-10-01T04:13:46Z"),
"configVersion" : 3,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "11.1.1.11:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 14,
"optime" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1538367253, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2018-10-01T04:14:13Z"),
"optimeDurableDate" : ISODate("2018-10-01T04:14:13Z"),
"lastHeartbeat" : ISODate("2018-10-01T04:14:17.405Z"),
"lastHeartbeatRecv" : ISODate("2018-10-01T04:14:16.418Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "11.1.1.11:27017",
"syncSourceHost" : "11.1.1.11:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 3
},
{
"_id" : 2,
"name" : "11.1.1.11:27019",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 4,
"lastHeartbeat" : ISODate("2018-10-01T04:14:17.405Z"),
"lastHeartbeatRecv" : ISODate("2018-10-01T04:14:17.424Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"configVersion" : 3
}
],
"ok" : 1,
"operationTime" : Timestamp(1538367253, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1538367253, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
副本集中三个节点的状态应该是:
端口
节点
状态
27017
主节点
1,PRIMARY
27018
从节点
2,SECONDARY
27019
仲裁节点
7,ARBITER
3.副本集的读写分离
在Mongodb副本集中,主节点负责数据的全部写入操作,也可以读取数据。从节点只能读取数据,而仲裁节点不能读和写数据。
因此,在主节点27017上可以进行数据的读取和写入操作。
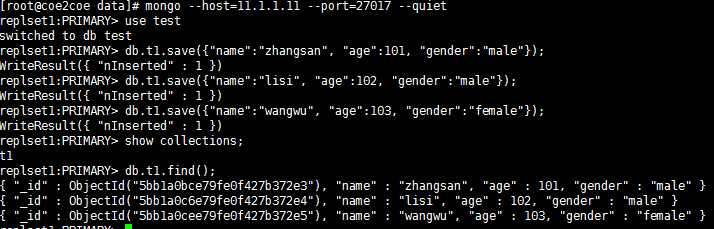
图5
但是这个时候从节点上并没有真正的成为这个副本集的正式成员。在从节点执行任何有关数据的操作将会产生一个错误:
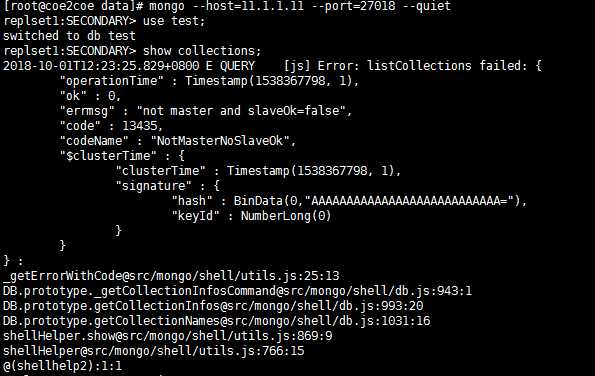
图6
只需要在从节点上执行一下这个而操作即可解决问题:

图7
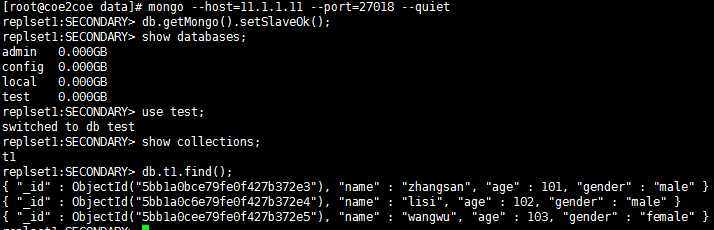
图8
在仲裁者节点上同样需要执行类似的操作,但是仲裁者节点是不保存副本集中的数据的。
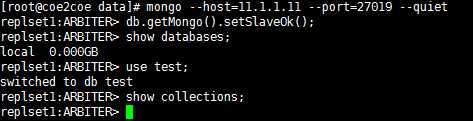
图9
在从节点或者仲裁者节点上写入数据将会失败。
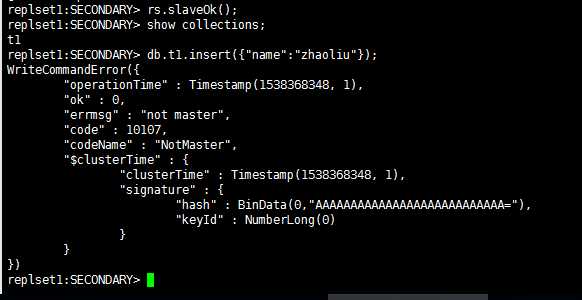
图10
4.副本集的故障转移
现在通过将副本集中的主节点27017节点停止运行来演示mongodb副本集的故障转移功能。
(1)停止主节点27017。
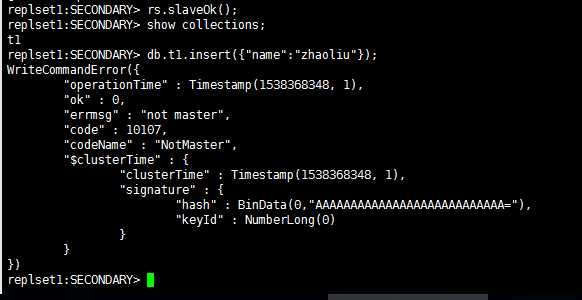 图1
图1
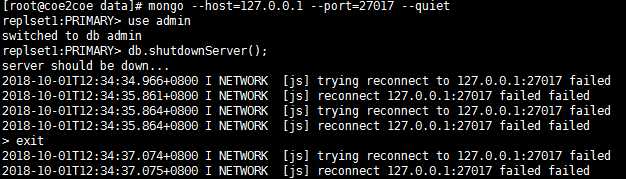
图11
查看节点状态。
此时原来的主节点27017处于不可用状态,而原来的从节点27018节点成为了新的主节点。

图12
三个节点的新状态如下所示:
端口
节点
状态
27017
主节点
8,(not reachable/healthy)
27018
从节点
1,PRIMARY
27019
仲裁节点
7,ARBITER
因为27018节点成为了新的主节点,因此可以进行写数据的操作了。
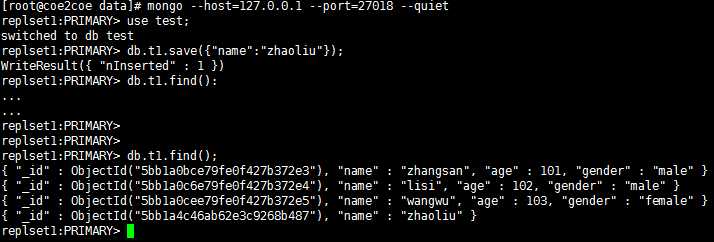
图13
在重新启动27017节点后发现这个原来的主节点成为了从节点。

图14
至此,Mongodb的副本集方式的集群部署成功。
4.副本集的优点
(1)部署简单。
Mongodb的副本集方式的集群,相对于MySQL的MHA或者MM方式的集群而言,部署方面简单,仅仅使用Mongodb官方软件的内置功能进行安装部署,不需要第三方的脚本或者软件即可完成部署。
(2)故障转移后,主节点的IP地址发生变化。因此需要客户端程序来处理这种IP变化。Mongodb的java客户端 SDK正好提供了这种功能,因此只需要将一个副本集中的主节点和全部从节点都加入到连接地址中即可自动完成这种读写分离和故障转移的功能,即不需要程序员自己写代码来检测和判断副本集中节点的状态。
Mongodb的副本集的Java SDK和Redis Cluster的Java SDK对于故障转移的自动化处理方式,都相当的人性化。
5.副本集的缺点
Mongodb的副本集方式的集群架构有如下的缺点:
(1)整个集群中只有一个主节点。因此写操作集中于某一个节点上,无法进行对写操作的负载均衡。
以上是关于MongoDB集群架构的主要内容,如果未能解决你的问题,请参考以下文章