spark安装测试
Posted 海绵不老
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark安装测试相关的知识,希望对你有一定的参考价值。
spark安装测试
spark安装测试
-
解压安装:
把安装包上传到/opt/soft下, 并解压到/opt/module/目录下 tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module 然后复制刚刚解压得到的目录, 并命名为spark-local: cp -r spark-2.1.1-bin-hadoop2.7 spark-local -
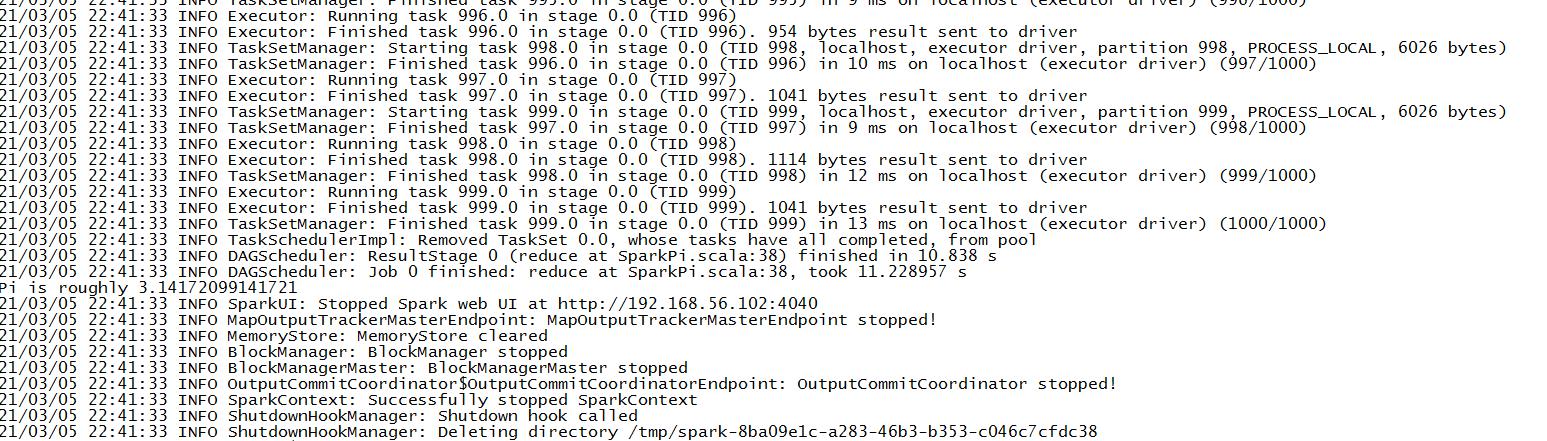
运行官方求PI的案例:
bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master local[2]
./examples/jars/spark-examples_2.11-2.1.1.jar 100
注意:
•如果你的shell是使用的zsh, 则需要把local[2]加上引号:‘local[2]’
•使用spark-submit来发布应用程序.
•语法:
./bin/spark-submit
–class
–master
–deploy-mode
–conf =
… # other options
[application-arguments]
––master 指定 master 的地址,默认为local. 表示在本机运行.
––class 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
•–deploy-mode 是否发布你的驱动到 worker节点(cluster 模式) 或者作为一个本地客户端 (client 模式) (default: client)
•–conf: 任意的 Spark 配置属性, 格式key=value. 如果值包含空格,可以加引号"key=value"
•application-jar: 打包好的应用 jar,包含依赖. 这个 URL 在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
•application-arguments: 传给main()方法的参数
•–executor-memory 1G 指定每个executor可用内存为1G
•–total-executor-cores 6 指定所有executor使用的cpu核数为6个
•–executor-cores 表示每个executor使用的 cpu 的核数
spark-shell使用
Spark-shell 是 Spark 给我们提供的交互式命令窗口(类似于 Scala 的 REPL)
本案例在 Spark-shell 中使用 Spark 来统计文件中各个单词的数量.
步骤1: 创建 2 个文本文件
mkdir input
cd input
touch a.txt
touch b.txt
分别在 a.txt 和 b.txt 内输入一些单词.
步骤2: 打开 Spark-shell
bin/spark-shell
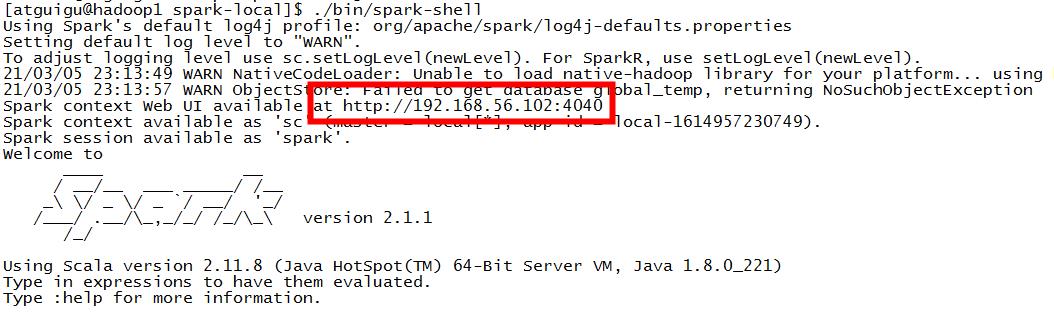
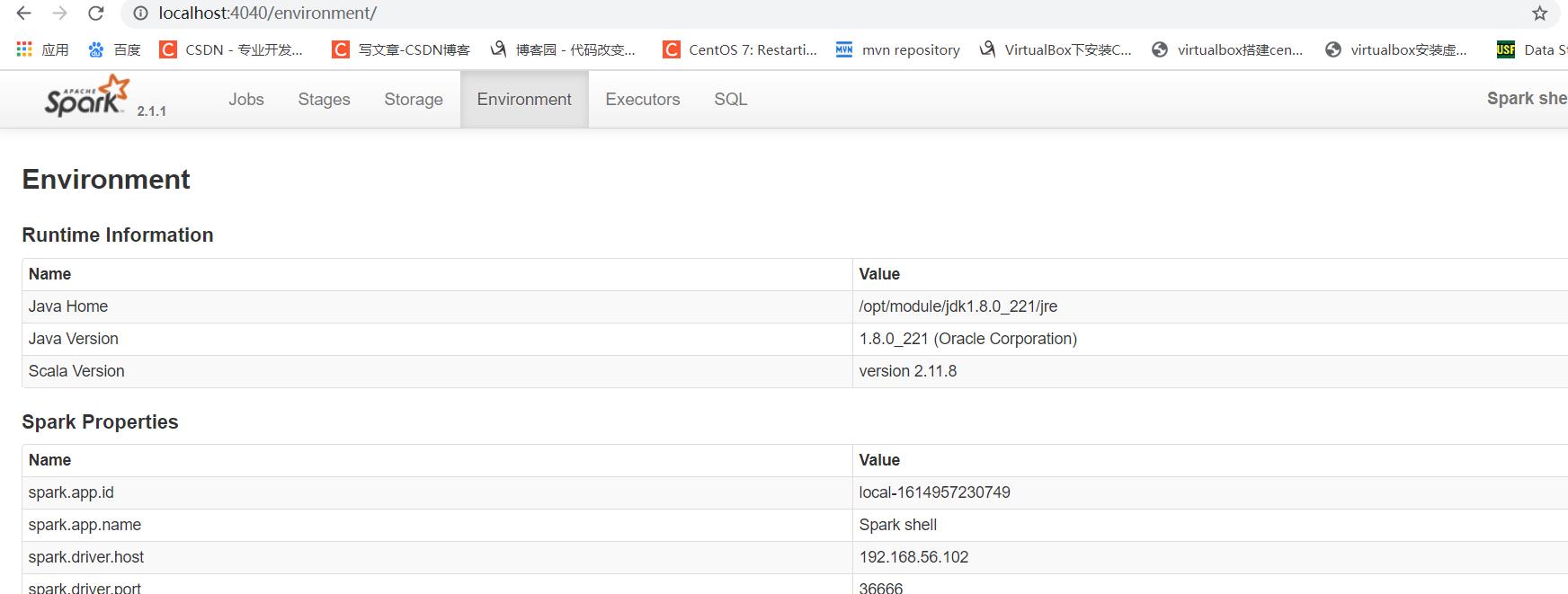
步骤3: 查看进程和通过 web 查看应用程序运行情况
sc.textFile(“input/”).flatMap(.split(" ")).map((, 1)).reduceByKey(_ + _).collect
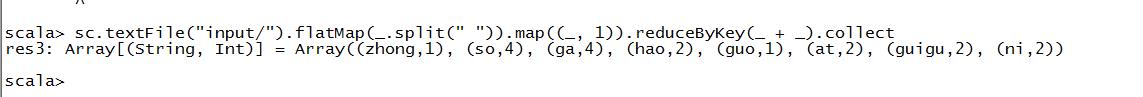

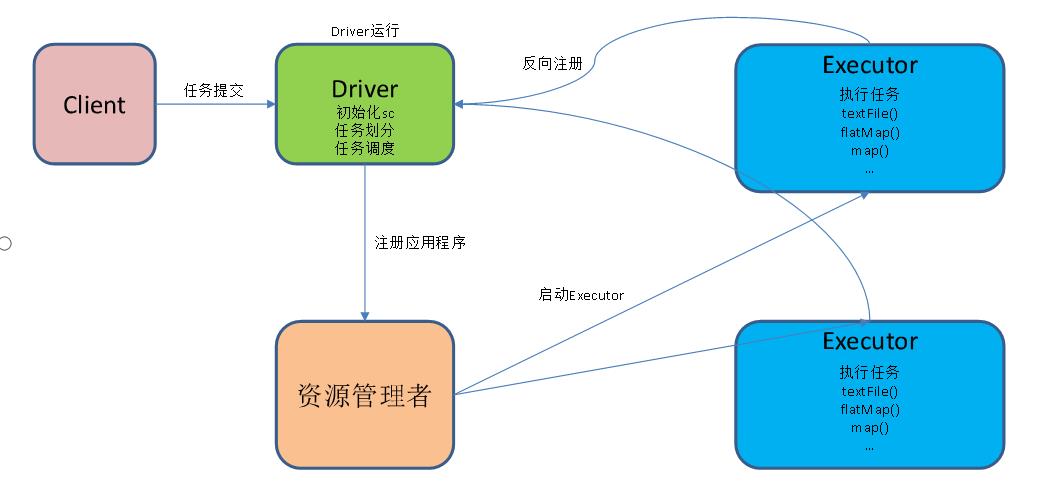
提交流程分析

1.textFile(“input”):读取本地文件input文件夹数据;
2.flatMap(.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
3.map((,1)):对每一个元素操作,将单词映射为元组;
4.reduceByKey(+):按照key将值进行聚合,相加;
5.collect:将数据收集到Driver端展示。
以上是关于spark安装测试的主要内容,如果未能解决你的问题,请参考以下文章