Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using GAT(2020)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using GAT(2020)相关的知识,希望对你有一定的参考价值。
文章目录
论文名称
Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using Graph Attention Neural Network by Xuefeng Bai, Pengbo Liu, Y ue Zhang
论文摘要

这篇论文主要的任务是方面级的情感预测:给定一个句子,然后预测文本里的某个词的情感是正向(positive)或是负向(negative)或是中立(netural)。
例如:“I like the food here, but the service is terrible.” 里面的food是positive,service则是negative。
摘要说明GAT模型用于依存树会有较好的效果,但是但是并没有考虑到依存树边的标签,为了解决这个问题,文章提出了一种RGAT模型,能够考虑依存树边的标签(当作图中的关系),实验结果证明有不错的效果。
主要内容
引言
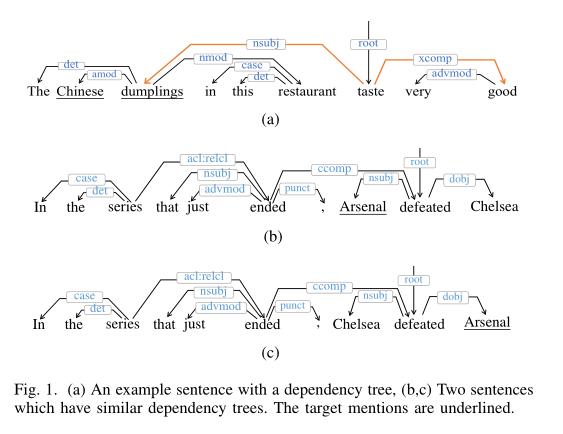
为什么要用依存树呢?
文章给出解释例如(a)中,good是修饰Chinese dumplings的,假设我们要预测Chinese dumplings的情感,在句子原结构中发现good其实里它隔了好几个词,但是在依存树中,他们之间就隔了一个词,换句话说,就是依存树中,大部分修饰词会和我们需要预测的词离得很近,因此方便语义的传递,从而达到比较好的效果。
这篇文章的RGAT解决了什么问题呢?
我们看(b)、(c)两句话,可以看出,这两句话就是最后两个人物换了位置,对于依存树,如果不考虑标签,那么两个依存树是完全一样的,但是对于人物的情感却是完全相反的,因此,使用将依存标签考虑进去,即使用RGAT,就能够将这个问题解决。
数据定义

文章的训练实例由三个部分构成:
T代表的是目标词(我们需要进行预测的方面词)长度为m;
S代表的就是完整的句子的词,长度为n;
G代表一个依存图由(V,A,R)来表示
V代表所有的节点(词),A代表邻接矩阵,R代表依存标签矩阵。
模型方法
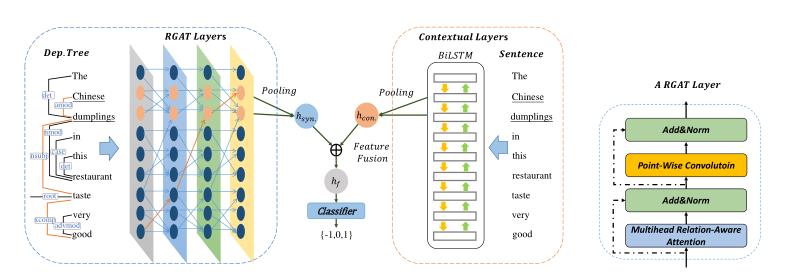
简单来说,这篇文章的模型方法的思路就是,用RGAT编码依存树结构,用BiLSTM或Bert编码句子信息,然后二者信息进行融合,最终预测出结果。
Contextual Encoder(上下文编码器)
文章使用了两种.
一种是BiLSTM:

根据前人经验,这里的BiLSTM使用了GloVe预训练词向量初始化,加了POS(词性标注)的信息embedding以及词的位置信息embedding,因此一共是三个embedding,最后进行拼接操作得出最终的词向量作为BiLSTM的输入,对句子进行编码。

BiLSTM前后两个方向编码的隐藏层进行凭借,最终得到BiLSTM句子编码的表示。
另一种就是bert来编码。

bert也是预训练模型,基于transformer,已经很多实验都证明了bert能够显著提升下游任务,因此用bert来对句子进行编码一直是个不错的选择。

说明使用bert编码时,这里是将句子+目标词的形式输入bert,然后得到这些词的向量表示,最后得到句子的编码表示,是一个768维的向量。
Relational Graph Attention Network(关系图注意网络)
RAGT就是在GAT的基础上考虑了关系,即将图的边特征也考虑进去了。
首先GAT的更新公式如下:

使用多头注意力机制,计算出邻居节点的特征注意力权重然后进行隐藏层的更新。
节点的注意力权重计算方式如下:

除此之外,作者还在注意力层后加入了PCT层

类似的,考虑关系的注意力权重计算如下:

(8)是节点之间的注意力权重计算方式
(9)则是类似的考虑节点和关系的注意力权重的计算方式
计算出两种注意力权重之后得出一个总的权重:

那么我们就能够得到最后的更新公式:
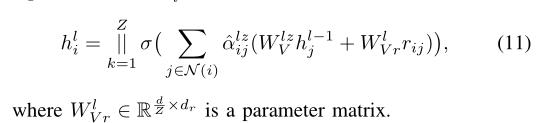
Pooling and Feature Fusion(特征融合)

通过前面两步,我们已经获得了句子信息编码和句子依存树的编码了,这一步就是要将二者的信息进行融合。融合的方法就如(13)、(14)所示。
The Classifier(分类)

(15)就是融合句子信息和依存树信息的隐藏层接一个全连接层变成预测类别的维度,然后进行softmax选择最大的预测概率作为样本的预测类别,然后损失函数用的就是交叉熵函数。
实验结果
训练曲线
实验结果肯定是好。
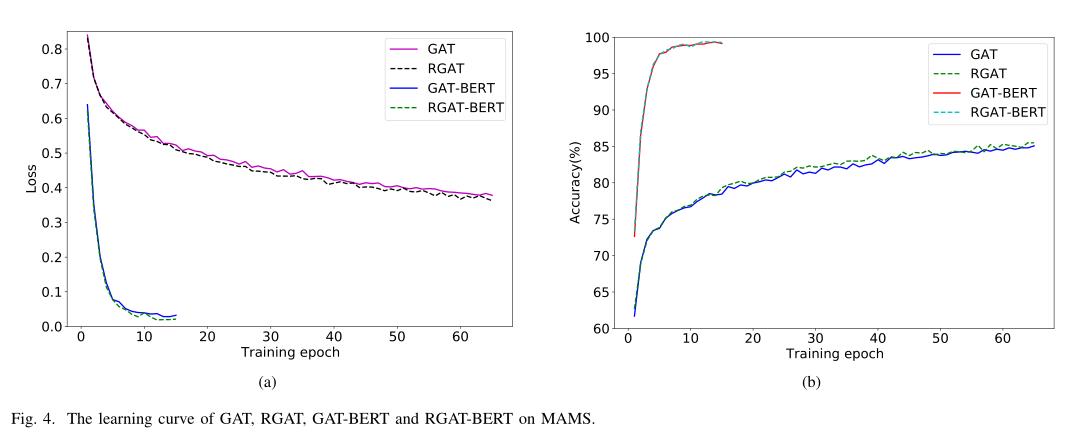
可视化展现RGAT模型训练的loss曲线和acc曲线的优势。
依存标签是必要的
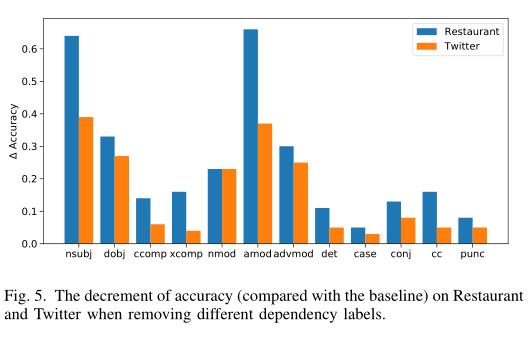
移除标签准确率下降的图
说明依存标签是有用的。
关系注意力权重是必要的
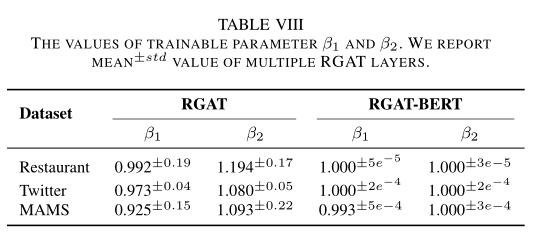
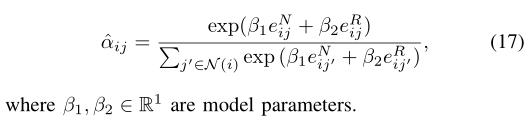
β1和β2都接近1说明两种注意力权重是同等重要的。
模型深度的合理性
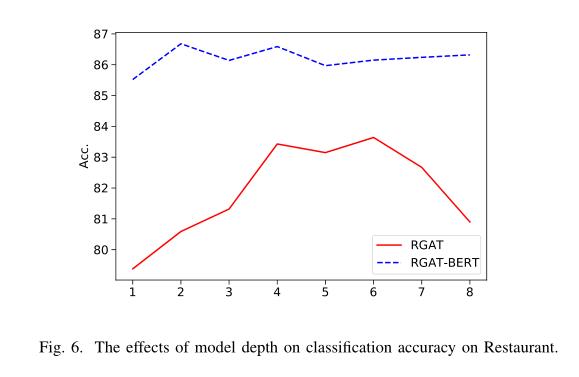
这里考虑的层数不同,从1到8不等。对于RGAT,初始精度较低,然后随着深度的增加而增加,在6层时达到83.55的最佳分数。因为与目标相关的情感词可能与目标提及有许多距离,这意味着需要多层节点通信才能将信息从相关上下文传递到目标提及。与RGA T相比,RGA T-BERT在两层中更快地达到最佳精度(86.68),这可能是因为BERT中包含的隐含语法允许更快的信息传播。
总结
这篇文章使用RGAT对句子的依存树进行编码,获取了依存结构信息,然后使用bert对句子进行语义的编码,获得了句子的语义信息,然后将二者融合,得到最终的句子表示,进行分类,得到目标词的预测结果,取得了不错的效果。不仅如此,作者还在各个方面分析了实验参数的合理性,考虑关系的必要性等。
参考
Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using Graph Attention Neural Network
,Xuefeng Bai, Pengbo Liu, Yue Zhang
以上是关于Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using GAT(2020)的主要内容,如果未能解决你的问题,请参考以下文章