二战MySQL数据库升华篇
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二战MySQL数据库升华篇相关的知识,希望对你有一定的参考价值。
mysql入门系列——第二篇
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于三大数据库深入讲解专栏:《三大数据库深入讲解》
- 🔥🔥热门专栏推荐:《Django框架从入门到实战》、《爬虫从入门到精通系列教程》、《爬虫高级》、《前端系列教程》、《tornado一条龙+一个完整版项目》。
- 📝📝本专栏面向广大程序猿,为的是大家入门并精通开发python项目常用的三大数据库:MySql,Redis,MongoDB。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
1.筛选条件:
(1)比较运算符:
| 运算符 | 含义 |
|---|---|
| = | 等于(注意:不是==) |
| >= | 大于等于 |
| !=或<> | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
知识点补给站:
关于IS NULL和IS NOT NULL如何使用?
select * from tb_name where 字段名 IS NULL;
查询tb_name表中指定字段名为空的所有数据。
(2)逻辑运算符:
| 运算符 | 含义 |
|---|---|
| AND | 与 |
| OR | 或 |
| NOT | 非 |
(3)其他操作:
1.排序:
select name1 from tb2_name order by tb3_name [asc/desc];
-
第一个name是指定查询的数据,即显示出来的数据;
-
第二个tb2_name是表的名字;
-
第三个tb3_name是表中排序的那一列的字段; (一般都是数字排序,如果是字母,按首字母顺序排序)
-
asc是正序(默认,不输入也是正序);desc(descend降序排列)是倒序。
2.限制:
select name1 from tb_name limit start,count;
-
第一个name1是指定查询的数据,即显示出来的数据;
-
第二个tb_name表的名字;
-
第三个start是限制的表中开始的行数,count是要显示出来的行的个数。(表中行数以0开始。如果start没有数据,默认从第零行开始)
拓展:
带条件的限制(where):
select name1 from tb_name where 条件语句 limit start,count;
- 会从name1中筛选出符合where的且满足限制条件start,count的数据。
3.去重:
select distinct name1 from tb_name;
-
第一个name1是指定查询的数据,即显示出来的数据。这是指定去重的数据。
-
第二个tb_name是表名。
注意:
如果name1是*,则把整张表里行中一模一样的去重;如果name1是字段名,则把对应的字段值里一样的去重.
4.模糊查询: (like ‘%’)
-
任意多个字符: %
模糊查询和范围查询都是和where一起用。 -
任意一个字符:_
例子:
select name1 from tb_name where name like 'h%';
-
查询表中满足name为h开头的对应name1字段下的字段值。
-
如果’h%'换为’h_'则只能查询以h开头且h后面只有一个字符的name。
-
如果’h%‘换为’%h%'则只能查询name中间有h的任意name
5.范围查询:
- 连续范围:between a and b
a <= value <= b(包括a和b)
例子:
select name1 from tb_name where id between a and b;
- 查询表中id在a和b之间的(包括a和b)name1字段下的字段值。
- 间隔范围:in()
括号里可以写任意值,包括表里没有的也不会报错,只查询括号里指定的值
例子:
select name1 from tb_name where id in (1,7);
- 只查询表中的id为1和7的对应name1字段下的字段值,里面可以写表里没有的也不会报错 。
2.聚合与分组(重点哦!):
数据表准备(为了讲解更容易理解,会配套上实操演示效果):

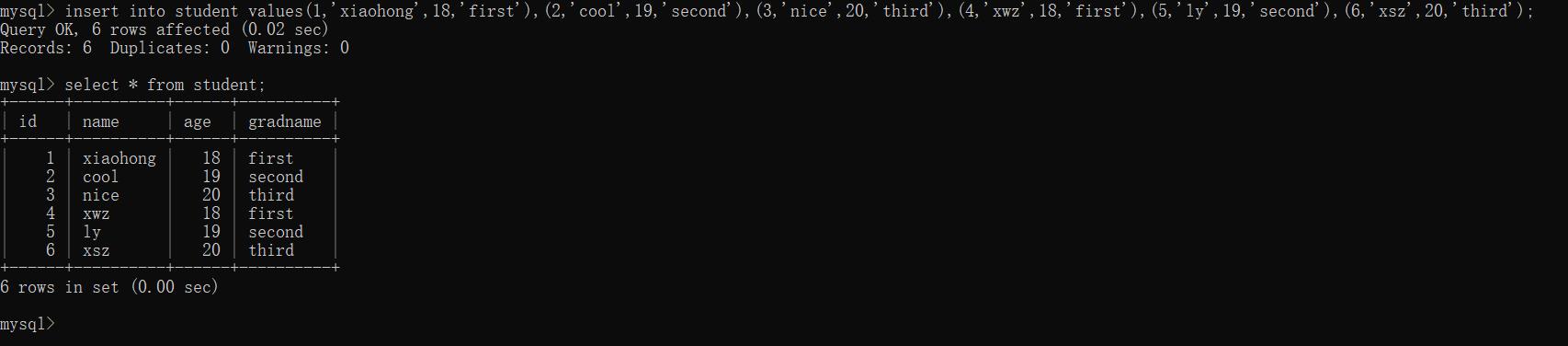
(1)常用聚合函数:
| 聚合函数 | 作用 |
|---|---|
| count(column) | 统计个数 |
| sum(column) | 求和 |
| max(column) | 最大值 |
| avg(column) | 平均值 |
| min(column) | 最小值 |
| group_concat(column) | 列出字段全部值 |
用法:
select 聚合函数(字段) from 表;
(其实你也可能感觉到了,这些聚合函数单独使用没啥子实际作用,其实聚合函数一般都是和分组结合使用才能发挥其作用哦~)
重点:
select group_concat(字段) from 表;
- 列出指定字段的全部值 (在分组后可以列出每组指定字段的所有值。

(2)分组查询:
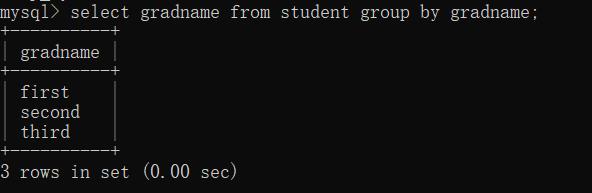
select 字段 from 表 group by 字段;
(注意:这里的两个字段必须一致,否则会报错)
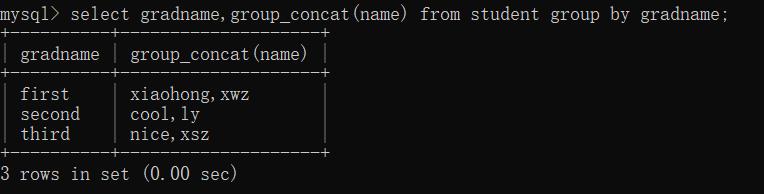
select 字段,count(*) from 表 group by 字段;
配合聚合函数使用,例如—显示count,即个数。
| 注意:在分组的情况下,只能够出现分组字段(即分组的那个字段)和聚合字段,其他的字段没有意义,会报错! |
小注意:
如果要加入where筛选,where语句要放在分组查询grou by的前面哦~
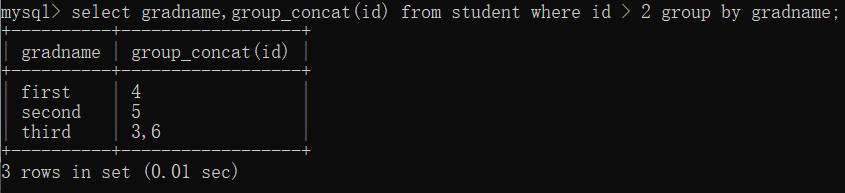
(3)聚合筛选:(having)
select 字段1 from 表名 group by 字段1,字段2 having 字段2>=80;
(加having条件表达式,可以对输出的结果做出限制。是不是想到了where,别急,我也想到了~)

假如说一个查询语句中同时包含了别名(as),聚合函数, where, having那么他们的执行顺序是:
- 先是执行:where 这次是在整个表的前提下筛选
- 然后执行:聚合函数和别名
- 最后执行:having,这次是在字段里筛选
(where比having执行要快!所以多用where)
注意:一般where写的条件筛选,都可以用having筛选表示。
小tips:最后加having class = ‘first’ 跟在前面用where都可以 ,代码执行结果一致。
但是要注意where是在整表中进行筛选;而having是在聚合及分组操作之后产生的一张虚表中进行筛选。(即Where是在聚合分组之前对数据进行筛选
having是在聚合之后再进行筛选)二者使用哪个看场景~
3.子查询:
将一个查询的结果留下来用于下一次查询 ( select 中嵌套 select )
要求:
-
嵌套在查询内部
-
必须始终出现在圆括号内
例子:
- 求出学生的平均年龄
select avg(age) from students;
- 查找出大于平均年龄的数据
select * from student where age > 19.7273;
- 将求出的平均年龄的SQL语句用于查找大于平均年龄的语句中
select * from students where age > (select avg(age) from students);
4.连接查询:
再创建一个表,结合上面创建的那张表演示效果:

(1)内连接(inner join)
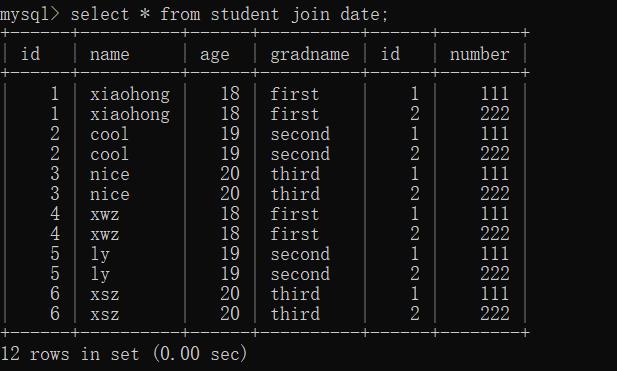
- 无条件内连接:
无条件内连接,又名交叉连接/笛卡尔连接,第一张表中的每一项会和另一张表的每一项依次组合
select * from 表1 [inner] join 表2;
inner可写可不写,没影响。
比如第一张表有6条数据,第二张表有2条数据,那么内连接查询则有12条数据,第一张表的每一条数据分别和第二张表的两张数据组合。
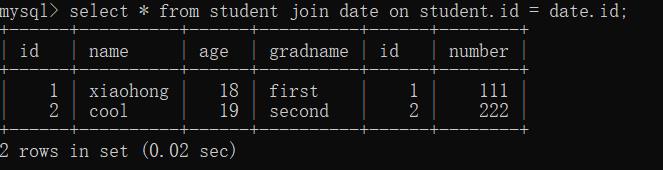
- 有条件内连接:
在无条件内链接的基础上,加上一个on子句,当连接的时候,筛选出那些有实际意义的记录来进行组合
select * from 表1 inner join 表2 on 条件
(比如:表1.id = 表2.id);
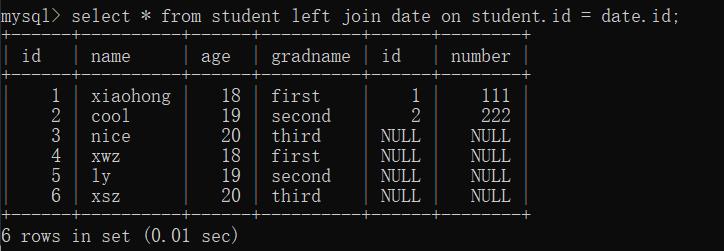
(2)外连接( left / right join )
- 左外连接: (以左表为基准)
两张表做连接的时候,在连接条件不匹配的时候留下左表中的数据,而右表中的数据以NULL填充
select * from 表1 left join 表2 on 条件;
条件里面可以写 表1.字段=表2.字段。
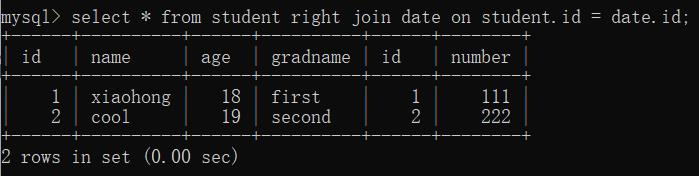
- 右外连接: (以右表为基准)
对两张表做连接的时候,在连接条件不匹配的时候留下右表中的数据,而左表中的数据以NULL填充
select * from 表1 right join 表2 on 条件;
拓展:
三连接:
select * from 表1 left join 表2 on 条件1 left join 表3 on 条件2;
表1和表2,然后和表3连接,表1是主表。
以上是关于二战MySQL数据库升华篇的主要内容,如果未能解决你的问题,请参考以下文章