Elasticsearch 核心概念
Posted java叶新东老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 核心概念相关的知识,希望对你有一定的参考价值。
什么是elasticsearch
elasticsearch ,简称es,是面向文档型的nosql数据库,一条数据就是一个文档;在安装完es后会出现一行字符串you know,for search !,翻译成正文就是:“你知道的,为了搜索!”,所以es的出现就是为了搜索而生的,
前言
观看本文章需要你有关系型数据库mysql的相关知识,因为本文章会将es和mysql做一些比较,熟悉mysql之后理解起来会更容易,学习也更加快速;
1、核心概念目录表
| 概念名称 | 说明 |
|---|---|
| 索引(indices、index) | 相当于关系型数据库的库(database) |
| 类型(type) | 相当于关系型数据的表(table) |
| 文档(document) | 相当于关系型数据库的行记录(row) |
| 属性(field) | 相当于关系型数据库的字段(column) |
| 映射(mapping) | 字段的属性 |
| 分片(shards) | 将同一个索引下的数据存储在不同的文件中,类似关系型数据库的分区 |
| 分配(Allocation) | 集群和分片的分配 |
索引(index)
索引是一组相似文档的集合,可以理解一个索引就是一个目录,在这个目录下有众多文档;在新版的ES(6.0以上)中,已经去除了types的概念,所以也可以理解为索引就是一张关系型数据库的表(table);在新建索引时,索引名称必须是小写;es的精髓就是为了提高查询效率
类型 (type)
在就版本中,type可以理解为关系型数据库的表,其实在设计初期,是没有types的概念的,设计es的人为了和关系型数据库进行关联,特地加上了types的概念, 但是后来发现没有这个必要,所以在6.*版本进行弱化,也就说在6.*版本以后,一个索引下只能有一个type,而在7.*以后则去除了type的概念。
并且在存储的时候,一个索引下的所有type的数据都会存储在一个文件中,如果一个索引下有多个types,那无疑会降低搜索的效率,所以才会这么急切地要去除type
document(文档)
代表着es中一条记录,和关系型数据库的rows是一样的, 不同的是,文档的数据是以json的格式进行表示;只要你的计算机磁盘空间足够,在一个索引中,你可以存储无限多的文档
field(属性)
field 在关系型数据库中被称为字段(column),他俩之间的概念是一样的,每个field都有自己的数据类型,根据数据类型存储不同的数据,区别是关系型数据库必须先定义固定的数据类型和属性长度,而es可以不设定数据类型,在插入数据时会自动生成对应的数据类型;
mapping(映射)
mapping用来配置属性的默认值、数据类型、分析器、是否被索引等等,将一个属性用映射的方式做一些优化,可以提高检索效率和减少空间占用;
shareds (分片)
在es中, 一个索引下的数据是可以有无限大的,并且 它们都存储在一个文件中, 但是这有个问题,文件越大,就意味着搜索效率会降低,就需要将一个文件按照一定的规则拆分成多个文件;而分片就是做拆分用的,比如用户表中有10亿条数据,有各种年龄段的用户,在1 ~ 100岁之间;就可以用分片机制将 这些用户进行划分为5个片区,划分如下
- 分片1:1-20岁
- 分片2:21-40岁
- 分片3:41-60岁
- 分片4:61-80岁
- 分片5:81-100岁
es的分片和mysql的分区类型,不同的是mysql不支持分布式分区,而es支持分布式集群分片,也就是说,es允许将不同的分片划分到不同的集群节点中;
分配(Allocation)
将分片分配给节点的过程,包括分配主分片或者副本,如果是副本,还包含从主分片复制数据的过程,这个过程由master节点完成;
2、系统架构
es是支持集群部署的,默认情况下就是集群环境,只不过,如果只有只有一个主节点的话,是会有单点故障的,也就是说当主节点因为一些原因挂了,那es就无法在提供服务了;所以为了保证es的高可用,一般生产环境下都会部署多个节点,建议一主多从,当主节点宕机后,其他的子节点还可以照样提供服务,业务也不会受影响;
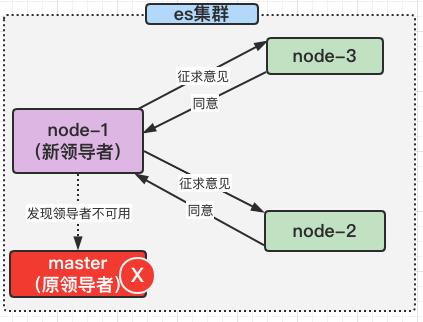
es选主过程
当es集群发现主节点不存在或者主节点不可用的情况下,就会触发重新选主的逻辑,选主算法主要有2个
- Bully算法
- Paxos算法
Bully算法
Leader选举的基本算法之一。 它假定所有节点都有一个惟一的ID,该ID对节点进行排序。 任何时候的当前Leader都是参与集群的最高id节点,

这种算法虽然简单,但是缺陷也明显,如果选出的leader处于不稳定状态,一旦负载过重会出现假死的情况。例如 Master 负载过重而假死,集群拥有第二大id 的节点被选为 新主,这时原来的 Master 恢复,再次被选为新主,然后又假死…
Paxos算法
Paxos算法的原则是任何一个节点都有可能称为主节点,以下的选主过程只是一个粗略的过程,真实的Paxos算法其实非常复杂,在这里化繁为简,也是为了方便大家理解;
- 当节点A发现主节点宕机后,向集群广播发送自己成为主节点的请求,也就是征求每个节点的意见:“我要成为老大(leader),你们同意不?”
- 当集群中的节点收到广播后,给出自己的意见,
- 当超过半数的节点都同意后,节点A就成为主节点,比如集群中有3个节点,节点A发送广播后,只要有其他任何一个节点同意了,节点A就升级成主节点,不需要全部都同意;
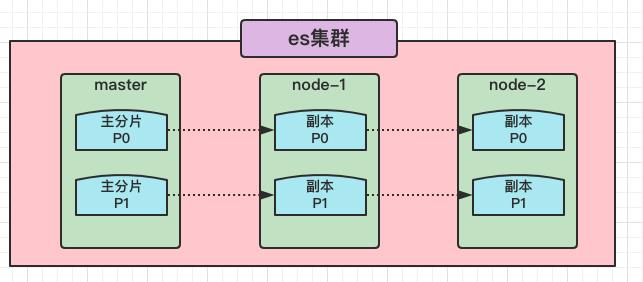
副本分片的分配方式
es的数据分为主分片和副本分片,主分片都存储在master节点中,但是副本分片都在其他的node节点上, 这是因为es要保证高可用,万一master节点挂了,其他的子节点还照样可以提供查询数据的服务;
以上是关于Elasticsearch 核心概念的主要内容,如果未能解决你的问题,请参考以下文章