C语言,如何实现搜索内存数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言,如何实现搜索内存数据相关的知识,希望对你有一定的参考价值。
我大概知道要使用openprocess ReadProcessMemory ,但是具体要怎么搜索内存数据呢,既然要在内存中搜那么ReadProcessMemory函数第二参数的起始位置应该在哪,用什么类型数据装读到的内容 一次读多大数据?并且读取完一段数据之后 下一段的内存该如何去搜索?
一般的讲,内存里边虽然说有*G的空间,但有些地方只是挂名存在,实际上是不存在的,所以访问了就会出错,所以就要判断内存是不是为有效地址,就要用到VirtualQuery获取指定内存属性, 根据属性来判断能不能进行读取,
如果能读取就从调用VirtualQuery中得到的内存信息minfo中获取当前内存地址的有效区域的大小,然后再进行读取. 你可以用VC调试来看看,不能访问的内存就用?号来表示.由于搜所内存是一种运算量庞大的工作,所以,在对比处理要作速度优化处理. 如果数据大于4字节,请用 long 的数据格式来作对比运算, long 是 char 的处理速度的三倍以上,(个人测试的) 用long处理前端数据,再用 char 作收尾工作. 这是对比处理了.流程就有以下:
判断地址的有效性->定好搜所范围->进行对比->输出结果.
StartAdd 开始地址
EndAdd 结束地址
Data 查找的数据
DataSize 数据大小
void *FindMemory(DWORD StartAdd,DWORD EndAdd,void *Data,DWORD DataSize)
MEMORY_BASIC_INFORMATION minfo;
DWORD rt;
while(StartAdd<EndAdd)
::VirtualQuery((void*)StartAdd,&minfo,sizeof(MEMORY_BASIC_INFORMATION));
if(minfo.AllocationProtect)
if(minfo.State==MEM_COMMIT||minfo.State==MEM_FREE)
char *s=(char*)StartAdd,*e=s+minfo.RegionSize;
for(;s<e&&s+DataSize<=e;s++)
if(memcmp(s,Data,DataSize)==0)
return s;
StartAdd=(DWORD)minfo.BaseAddress+minfo.RegionSize;
return 0;
参考技术A 那就要看你要搜索什么数据了,若是数字,一般是4字节。内存中可能是这样的:
00110011
那你就每4字节搜一次:
0011 0110 1100 1001 0011
其他的如字符串等就麻烦了。
望采纳。 参考技术B 那就要看你要搜索什么数据了,若是数字,一般是4字节。内存中可能是这样的:
00110011
那你就每4字节搜一次:
0011 0110 1100 1001 0011
其他的如字符串等就麻烦了。
望采纳。追问
可是我不知道其他程序的内存其实位置啊 难道从位置0开始搜索? 如果是搜索4字节 那之后呢 ,内存的位置就变成了0X00000004?在这个位置继续在搜索4个字节?
C语言整型在内存中的存储
数据类型介绍
C语言中的类型有整形,浮点型,构造类型,指针类型和空类型。
类型的意义主要有两点:
1.决定了使用这个类型所开辟内存的大小(大小决定了使用范围)。
2.决定了如何看待内存空间的视角
整型
char:
unsigned char
signed char
int:
unsigned int
signed int
short:
unsigned short (int)
signed short (int)
long:
unsigned long (int)
signed long (int)
整型在内存中的存储
一个变量的创建在内存中是要开辟一片空间的,而空间的大小根据不同的类型而不同。那么,整型在内存中是怎么存储的?
我们先来看一段代码:
int main()
{
int a = 10;
int b = -10;
return 0;
}
对这段代码调试一下,在对a和b赋值后,看一下a和b的二进制序列在内存是如何存储的:
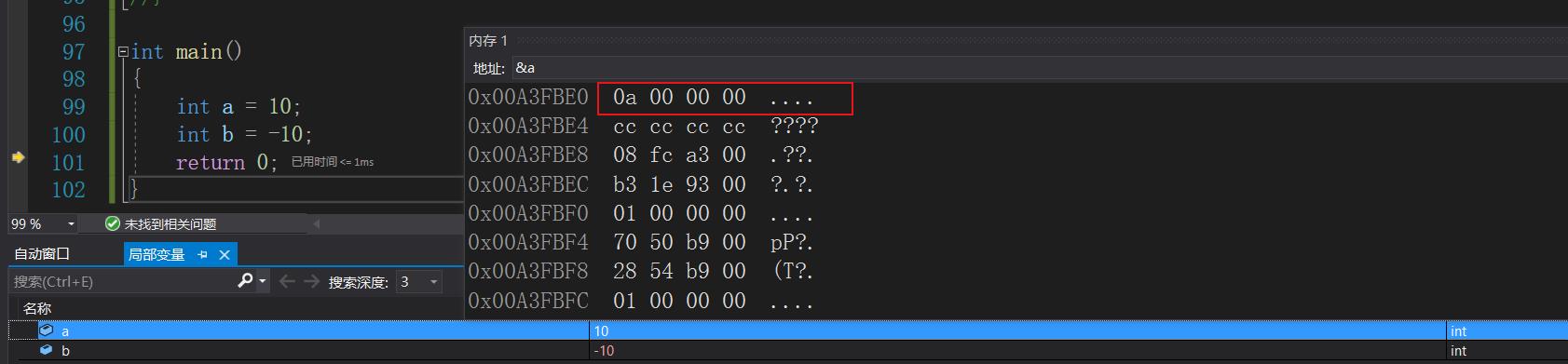
首先来看a变量的二进制序列在内存中的存储:可以看出a在内存中的二进制序列是0a 00 00 00,这是十六进制的形式,我们知道10的二进制序列为:
00000000000000000000000000001010,转换为十六进制是00 00 00 0a
这里介绍一下负数的二进制存储:
对有符号数来说,其二进制有原码,反码和补码三种形式,而整型在计算器中是以补码的形式存储的,三者之间存在转换关系,原码为一个数直接转化为二进制,反码为原码保留符号位不变,其他位按位取反,补码位反码+1
比如 -1,
原码:10000000000000000000000000000001,(最前面的1为符号位,符号位为0,即为正数,为1则为负数)
反码:1111111111111111111111111111111111110,(符号位1不变,其他位按位取反)
原码:1111111111111111111111111111111111111,(反码加一)
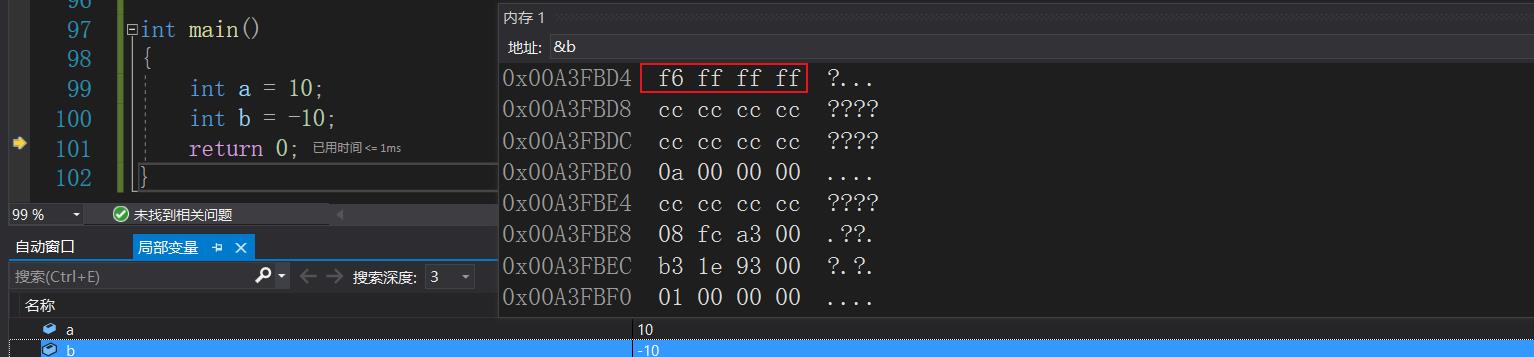
我们再看看b的二进制序列再内存中的存储:b在内存中存储的序列是
f6 ff ff ff, b = -10,而-10的二进制序列为:11111111111111111111111111110110,转换为十六进制即为:
ff ff ff f6
可以看到,整型在内存中的存储好像是顺序颠倒了过来,这是为什么呢?
大小端介绍
这里来介绍一下大端(存储)模式和小端(存储)模式。
大端(存储)模式:是指数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中。
小端(存储)模式:是指数据的高位存储在内存的低地址中,而数据的高位保存在内存的高地址中。
这是什么意思呢?举个例子:

而我们的x86结构是小端(存储)模式,因此在内存中会出现颠倒的现象。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小
端模式刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
代码实现判断当前机器的字节序
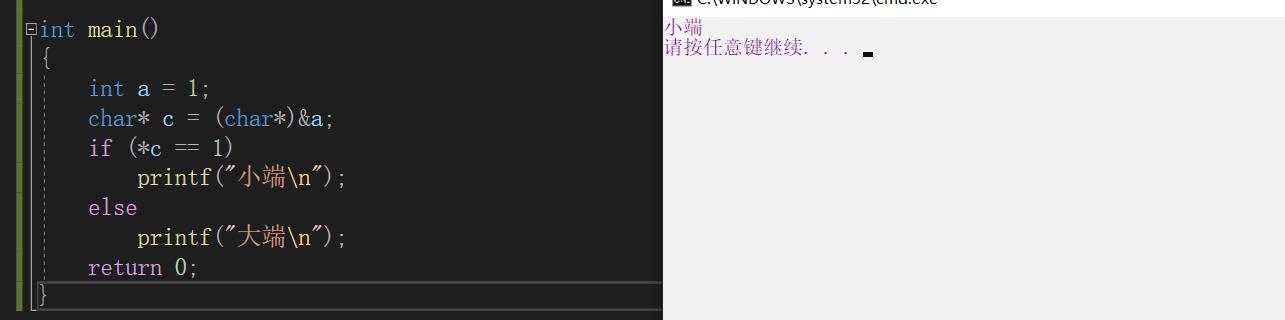
思路很简单,只需要通过char*型的指针取出一个数的地址并解引用,判断其为大端还是小端。以1为例,若解引用后为1,则为小端,反之为大端。
代码实现:
int main()
{
int a = 1;
char* c = (char*)&a;
if (*c == 1)
printf("小端\\n");
else
printf("大端\\n");
return 0;
}
实现效果:
【总结】
整形在内存中有大端和小端两种存储方式,不同的处理器模式不同,而我们使用的x86结构是小端存储。
以上是关于C语言,如何实现搜索内存数据的主要内容,如果未能解决你的问题,请参考以下文章