Java for循环嵌套for循环,你需要懂的代码性能优化技巧
Posted 小目标青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java for循环嵌套for循环,你需要懂的代码性能优化技巧相关的知识,希望对你有一定的参考价值。
前言
本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。
所以还是想拿出来说下。
正文
是个什么场景呢?
就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。
我们结合实例代码来看看。
场景示例:
比如我们现在拿到两个list 数据 ,
一个是 User List 集合 ;
另一个是 UserMemo List集合;
我们需要遍历 User List ,然后根据 userId 从 UserMemo List 里面取出 对应这个userId 的 content 值,做数据处理。
代码 User.java :
import lombok.Data;
@Data
public class User
private Long userId;
private String name;
代码 UserMemo.java :
import lombok.Data;
@Data
public class UserMemo
private Long userId;
private String content;
模拟 数据集合 :
5W 条 user 数据 , 3W条 userMemo数据
public static List<User> getUserTestList()
List<User> users = new ArrayList<>();
for (int i = 1; i <= 50000; i++)
User user = new User();
user.setName(UUID.randomUUID().toString());
user.setUserId((long) i);
users.add(user);
return users;
public static List<UserMemo> getUserMemoTestList()
List<UserMemo> userMemos = new ArrayList<>();
for (int i = 30000; i >= 1; i--)
UserMemo userMemo = new UserMemo();
userMemo.setContent(UUID.randomUUID().toString());
userMemo.setUserId((long) i);
userMemos.add(userMemo);
return userMemos;
先看平时大家不注意的时候可能会这样去写代码处理 :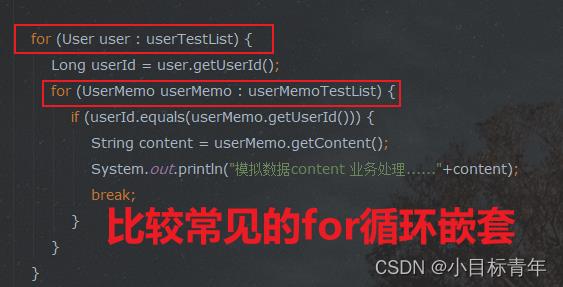
ps: 其实数据量小的话,其实没多大性能差别,不过我们还是需要知道一些技巧点。
代码:
public static void main(String[] args)
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList)
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList)
if (userId.equals(userMemo.getUserId()))
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
我们来看看 这时候的一个耗时情况 :
相当于迭代了 5W * 3W 次
可以看到用时 是 26857毫秒

其实到这,插入个题外点,如果说每个userId 在 UserMemo List 里面 都是只有一条数据的场景。
for (User user : userTestList)
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList)
if (userId.equals(userMemo.getUserId()))
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
单从这段代码有没有问题 ,有没有优化点。
显然是有的, 因为当我们从内循环UserMemo List里面找到匹配数据的时候, 没有做其他操作了。
这样 内for循环会继续下,直到跑完再进行下一轮整体循环。
所以,仅针对这种情形,1对1的或者说我们只需要找到一个匹配项,处理完后我们 应该使用 break 。
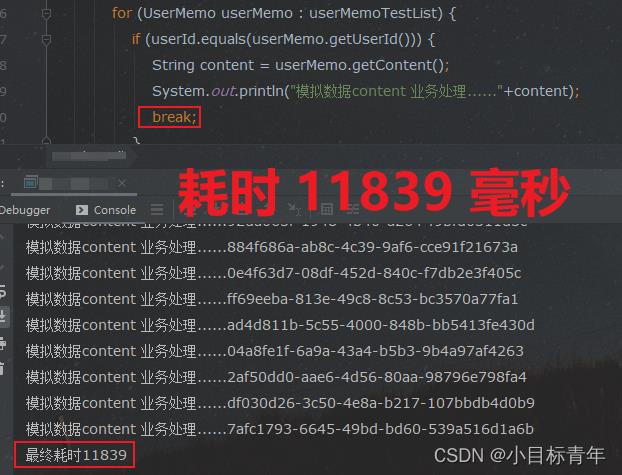
我们来看看 加上 break 的一个耗时情况 :

代码:
public static void main(String[] args)
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList)
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList)
if (userId.equals(userMemo.getUserId()))
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
break;
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
耗时情况:
可以看到 从 2W 多毫秒 变成了 1W 多毫秒, 这个break 加的很OK。
回到我们刚才, 平时需要for 循环 里面再 for 循环 这种方式,可以看到耗时是 2万6千多毫秒。
那如果场景更复杂一定, 是for 循环里面 for循环 多个或者, for循环里面还有一层for 循环 ,那这样代码耗时真的非常恐怖。
那么接下来这个技巧点是 使用map 去优化 :
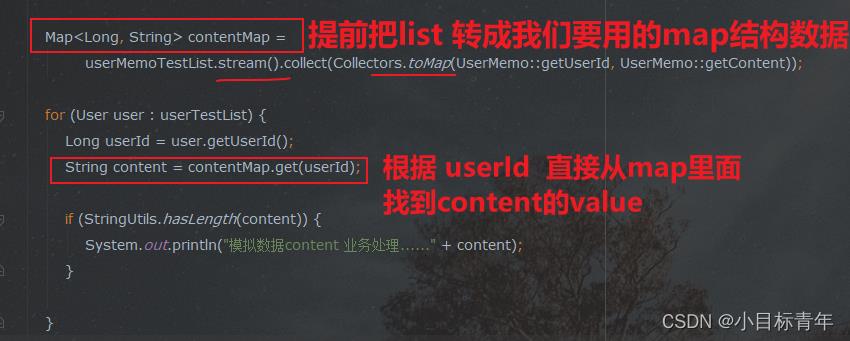
代码:
public static void main(String[] args)
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
//使用stream() 记得一定要判空 这里没列出来,大家自己注意
Map<Long, String> contentMap =
userMemoTestList.stream().collect(Collectors.toMap(UserMemo::getUserId, UserMemo::getContent));
for (User user : userTestList)
Long userId = user.getUserId();
String content = contentMap.get(userId);
if (StringUtils.hasLength(content))
System.out.println("模拟数据content 业务处理......" + content);
stopWatch.stop();
System.out.println("最终耗时" + stopWatch.getTotalTimeMillis());
看看耗时:

为什么 这么显著的效果 ?
这其实就是时间复杂度,
for循环嵌套for循环,
就好比 循环每一个 user ,拿出 userId
需要在里面的循环从 userMemo list集合里面 按顺序去开盲盒匹配,
拿出第一个,看看userId ,拿出第二个,看看userId ,一直找匹配的。
而我们提前对 userMemo list集合 做一次 遍历,转存储在map里面 。
map的取值效率 在多数的情况下是能维持接近 O(1) 的 , 毕竟数据结构摆着,数组加链表。
相当于拿到userId 想去开盲盒的时候, 根据userId 这个key hash完能直接找到数组里面的索引标记位, 如果底下没链表(有的话O(logN)),直接取出来就完事了。
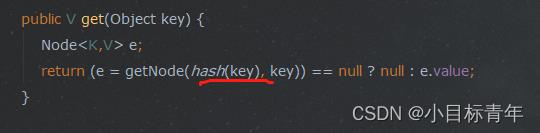
然后补充一个getNode的代码注释 :
/**
* Implements Map.get and related methods.
* 这是个 Map.get 的实现 方法
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
// final 写死了 无法更改 返回 Node 传入查找的 hash 值 和 key键
final Node<K,V> getNode(int hash, Object key)
// tab 还是 哈希表
// first 哈希表找的链表红黑树对应的 头结点
// e 代表当前节点
// k 代表当前的 key
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 赋值 并过滤 哈希表 空的长度不够的 对应位置没存数据的 都直接 return null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null)
// 头结点就 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 头结点不匹配 没找到就 就用 next 找
if ((e = first.next) != null)
// 是不是红黑树 的
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 红黑树就直接 调用 红黑树内查找
// 不为空或者没找到就do while 循环
do
// 当前节点 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
while ((e = e.next) != null);
return null;
=按照目前以JDK8 的hash算法,起hash冲突的情况是非常非常少见了。
最恶劣的情况,只有当 全部key 都冲突, 全都分配到一个桶里面去都占用一个位置 ,这时候就是O(n),这种情景不需要去考虑。
好了,该篇就到这。
java中for嵌套for循环的详细讲解?
参考技术A就是 一个执行循序问题,先执行外面的循环:
1 for(int i=0;i<10;i++)
2 for(int j=0;j<3;j++)
3 System.out.print("i*j="+i*j);
4
5
6 ....
....
当开始循环的时候,i=0,然后继续运行,j=0,输出i*j=0
此时循环从j=1,i仍旧为0 , j的值为2
输出结果为i*j=0,此时j++,j的值为2
循环从j=2,i仍旧为0 ,输出结果为i*j=0
当j=3,不满足j<3跳出内部for循环,执行外部for循环第二行代码,此时i++,i的值变为1
循环i=1, j=0时,结果为i*j=0
i=1,j=1 结果为i*j=1;
;;;;;;
;;;;;
当i循环到9,j=2是,输出循环结果为i*j=18
当i=10,不满足i<10,跳出外部循环,执行第6行
我只是拿一个例子给你讲解的,我像这样比给你讲解概念好理解。
一,在for循环中,循环控制变量的初始化和修改都放在语句头部分,形式较简洁,且特别适用于循环次数已知的情况。在while循环中,循环控制变量的初始化一般放在while语句之前,循环控制变量的修改一般放在循环体中,形式上不如for语句简洁,但它比较适用于循环次数不易预知的情况(用某一条件控制循环)。
二,foreach不是一个关键词,它指的是一种java里的循环方式,顾名思义代表对于每一个,表示每次给你要遍历的东西生成一个降维对象,然后访问。
比如说for(a:b),b是你要遍历的东西,每次循坏都会生成一个b的子集a,a是你自己命名的一个元素,在这个for里我们访问的就是这个a,每次循环都会访问一个新的a。
三,看你图里的代码,balances是二维数组,假设看成一个矩阵,我们需要一行一行遍历它,那么double[] row就是这个矩阵每行的意思。回到代码,for(double[] row:balances)就是指对于balances的每行row,同样的道理for(double b:row)的意思是对于每行row里的每个元素b,因为row是一维的数组,对它降维就是单个元素了。其中的row和b都是由你自己命名的,爱起什么名就起什么名,起完了名就可以在循环体里直接用了。遍历顺序就是顺序遍历,从前到后,跟你用i++,j++一样。
这种写法的好处在于,一是不需要管遍历的次数,二是你定义的子元素可以直接用,看起来比a[i]、a[j]方便。
以上是关于Java for循环嵌套for循环,你需要懂的代码性能优化技巧的主要内容,如果未能解决你的问题,请参考以下文章