《PostgreSQL面试题集锦》学习与回答
Posted Hehuyi_In
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《PostgreSQL面试题集锦》学习与回答相关的知识,希望对你有一定的参考价值。
新计划每天做一两道查漏补缺~ 以下题目来自:
1. MVCC 实现机制以及和Oracle的差异
MVCC:
多版本并发控制,核心作用:使得读写操作不相互阻塞,提升并发性能。
实现原理:通常有2种实现方法:
- 写新数据时,把旧数据存入其他位置(如oracle的回滚段、sqlserver的tempdb)。当读数据时,读的是快照的旧数据。
- 写新数据时,旧数据不删除,直接插入新数据。以pg为代表,在元组头中引入xmin,xmax,cid,ctid,t_infomask几个字段,并结合commitlog,snapshot来进行可见性判断。
以pg为例:
- 插入数据:xmin为执行插入的事务号,xmax为0
- 删除数据:xmin不变,xmax为执行删除的事务号
- 更新数据:相当于删除+插入
- 同一事务执行多个DML语句,cid会递增,表示执行了几条命令
与Oracle的差异:由于实现原理不同,两者优缺点也基本相反
pg优点
- 由于不用另外写回滚数据,DML效率高
- 回滚可以立即完成 为什么PostgreSQL的回滚是瞬间完成的?_51CTO博客_postgresql 回滚
- 不会有ora-1555快照过旧、undo表空间不够等问题
pg缺点
- 旧数据存储在数据文件中,会有表膨胀的问题,因此需要引入vacuum机制
- 事务ID递增,需要处理事务回卷问题,因此又要引入freeze机制。
pg事务篇(一)—— 事务与多版本并发控制MVCC_Hehuyi_In的博客-CSDN博客_pg 事务
2. 为什么会有表膨胀及表膨胀的危害
为什么会有表膨胀
从原理来说:
pg旧数据存储在数据文件中,并不立刻清理,只是标记为无效。这些旧数据如果不能及时清理,业务表和数据文件会越来越大,引发表膨胀。
从具体场景来说:哪些情况会导致旧数据不能及时清理
- 未开启autovacuum或者禁用了track_counts参数
- autovacuum过慢(例如IO问题、触发阈值不合理、执行周期不合理、配置了延迟触发,worker过于忙碌等)
- 大事务或者DML量过大,产生死元组速度快于清理
- 长事务,包括pg_dump和pg_dumpall,默认会以可重复读级别开启事务
- 慢查询(包括增删改查和DDL)
- 游标未关闭
- 复制槽 + hot_standby_feedback + 备库大查询,会导致主库可以vacuum的xmin很小
表膨胀的危害
- 表和数据文件占用空间持续增长
- 查询表时要扫描的数据块可能增多,查询速度变慢
- 需要用vacuum full处理(如果不用其他插件),vacuum full会获取表的8级锁,阻塞对表的所有操作,影响业务。并且最大会占有原来磁盘空间的两倍,可能打爆磁盘空间。
对应前面具体场景,如何避免表膨胀
- 开启autovacuum,启用track_counts参数
- 保证autovacuum性能:
- 将数据库迁移至高性能存储
- 合理的触发阈值(autovacuum_vacuum_threshold和autovacuum_vacuum_scale_factor)
- 合理的执行周期 autovacuum_naptime
- 性能足够时,关闭延迟设置 autovacuum_vacuum_cost_delay
- 合理的工作进程数和内存(autovacuum_max_workers和autovacuum_work_mem)
- 应用程序设计时,尽量避免如下:
- 过于频繁的DML操作
- 慢SQL(包括增删改查和DDL在内的所有的SQL)
- 大事务、长事务
- 打开游标后不关闭
- 在不必要的场景使用已提交读以上隔离级别
- 对大库执行pg_dump进行逻辑备份(隐式repeatable read隔离级别的全库备份)
- 设置idle_in_transaction_session_timeout,控制长事务的存活时间
- 设置old_snapshot_threshold参数,强制删除为过老的事务快照保留的dead元组(这会导致长事务读取已被删除的tuple时出错)。
- 对于大表,建议使用分区,可以加快vacuum的速度
如何处理表膨胀
- vacuum full,cluster
- 重建表(手动,或者pg_reorg,pg_repack)
参考:揭开表膨胀的神秘面纱
3. 长事务的危害以及如何溯源长事务
长事务的危害
小事务但长期不提交:
- 如果前面执行过DML语句,会锁定相关数据,阻塞后面语句
- 阻塞create index(也包括 concurrently)
- 大量死元组无法vacuum,导致表膨胀
- 大量事务id无法冻结
- WAL无法及时清理,占用空间大
- 占用连接数
- 开启old_snapshot_threshold后,长事务可能导致索引失效
- 搭配子事务容易使性能急剧下降
- 逻辑复制下会阻塞复制槽的创建
大事务:除上面外可能还有
- 出现较大范围锁表
- WAL大量增加
- 主从出现延迟
溯源
什么样的事务才会是有危害的长事务?
pg_stat_activity视图中 backend_xid或backend_xmin字段非空的事务。单纯begin tran; 不提交并不会有问题,因为它并没有真正申请事务id和获取快照。
backend_xid:已申请的事务号(virtualxid不算),从申请事务号开始持续到事务结束。
backend_xmin:进程快照xmin,表示在快照创建时最旧的未提交事务id(实际上就是Transaction Horizon)
因此监控语句需要加上这两个条件
select count(*) from pg_stat_activity where state <> 'idle'
and (backend_xid is not null or backend_xmin is not null)
and now()-xact_start > interval '3600 sec'::interval;参考:
https://foucus.blog.csdn.net/article/details/123230865
4. 子事务的危害和注意事项
如何产生子事务
- savepoint
- pl/pgsql 中的BEGIN / EXCEPTION WHEN .. / END代码块
- PL/Python代码中的plpy.subtransaction()
子事务的危害
- 加速事务id消耗,增加事务id回卷风险:每个savepoint都会消耗一个事务id
- 增加内存占用:每个savepoint消耗8K的会话本地内存(CurTransactionContext)
- 子事务SLRU溢出(Subtrans SLRU overflow):本质上这是由于子事务嵌套过深、或者子事务日志过大,SLRU缓存中不再能放下,这会导致大量缓存miss,进而导致大量磁盘IO,因为pg需要从磁盘去读取子事务信息。典型特征是出现SubtransControlLock等待事件(13版本开始重命名为SubtransSLRU)。
子事务溢出分为以下两种情况:
① 每个会话最多可容纳 64个(源码为PGPROC_MAX_CACHED_SUBXIDS参数)未中止的子事务。如果超过,则快照被标记为suboverflowed,这种快照无法包括可见性判断需要的所有数据,因此pg有时不得不读取pg_subtrans目录文件,会造成性能急剧下降。
② 主库上的子事务(不要求超过64,高并发时即使1个也可能)和长事务的组合可能会造成备库性能急剧下降甚至不可用,这个问题只发生在备库上。从根本上说,问题的发生是因为副本在创建快照和检查元组可见性时的行为与主副本不同。问题2的主要特征:
- A. 在主库:使用到了子事务(不要求超过64),对一些记录进行更新;有一个正在运行的长事务;这里的"长"取决于系统中XID的增长:比如说,如果你有 1k TPS 递增的 XID,那么问题可能会在几十秒后出现,所以"长" = "几十秒长",如果 你有 10k TPS,"长"可能意味着"几秒钟长"。所以在某些系统中,一个常规的慢查询也可能变成这样一个令人头疼的事务
- B. 在备库:查询的元组被主库的子事务修改了
- Multixact IDs的不当使用:将SELECT .. FOR UPDATE和子事务结合,情况会变得十分糟糕
SELECT [some row] FOR UPDATE;
SAVEPOINT save;
UPDATE [the same row];wait_event/wait_event_type组合上:
- LWLock:MultiXactMemberControlLock
- LWLock:MultiXactOffsetControlLock
- LWLock:multixact_member
- LwLock:multixact_offset
- 子事务+逻辑复制,可能产生大量小文件,导致walsender hang
注意事项
- 尽量避免使用子事务,尤其在高并发场景下
- 单会话打开的子事务数不要超过64,并发数越多,这个数字会越小
- 如果有备库,要避免长事务+子事务,txid增长越快,能容忍的长事务时间越短
- 避免SELECT .. FOR UPDATE和子事务结合
- 做好事务id增长、db年龄、长事务、等待事件的监控
参考
5. 表结构变更哪些操作是非online的
- pg 11前,新增带default值的列
- 所有版本,新增volatile default值的列(例如now())
- 改短列长度
- 改列类型(二进制兼容类型不需要rewrite table,但需要rewrite index,例如将 VARCHAR 转换为 TEXT)
另外补充非表结构变更,但是非online的操作:
- 修改表空间(alter table set tablespace)
- SET LOGGED | UNLOGGED
- cluster
- vacuum full
- SET/RESET storage_parameter:可能会rewrite,与设置的参数有关
简单的验证方法是看操作后pg_class中的relfilenode值是否改变。
alter table的部分online操作是指不用rewrite table,而不是不需要获取8级锁。如果表正在执行一个大查询,对它执行新增字段也会被阻塞,同时阻塞后面该表所有语句。
alter table 这部分源码在 tablecmds.c,简单看了下:
ATController -> ATRewriteTables -> ATRewriteTable
AlterTableGetLockLevel 中有各种操作使用的锁级别
switch (cmd->subtype)
/*
* These subcommands rewrite the heap, so require full locks.
*/
case AT_AddColumn: /* may rewrite heap, in some cases and visible
* to SELECT */
case AT_SetTableSpace: /* must rewrite heap */
case AT_AlterColumnType: /* must rewrite heap */
cmd_lockmode = AccessExclusiveLock;case AT_SetLogged: /* SET LOGGED */
...
/* force rewrite if necessary; see comment in ATRewriteTables */
if (tab->chgPersistence)
tab->rewrite |= AT_REWRITE_ALTER_PERSISTENCE;
tab->newrelpersistence = RELPERSISTENCE_PERMANENT;
pass = AT_PASS_MISC;
break;
case AT_SetUnLogged: /* SET UNLOGGED */
...
/* force rewrite if necessary; see comment in ATRewriteTables */
if (tab->chgPersistence)
tab->rewrite |= AT_REWRITE_ALTER_PERSISTENCE;
tab->newrelpersistence = RELPERSISTENCE_UNLOGGED;
pass = AT_PASS_MISC;
break;参考:
PostgreSQL: Documentation: 14: ALTER TABLE
That Guy From Delhi: What Postgres SQL causes a Table Rewrite?
6. 物理备份需要注意什么(pg_start_backup)
备份完成后务必记得执行pg_stop_backup关闭备份状态。
pg_start_backup函数会启动force full page write,备份期间对页的修改会将整页写入WAL日志,导致WAL量暴增。如果忘记关闭会导致磁盘空间快速增加、dml性能下降、从库要应用的日志过多可能出现主从延迟,另外可能影响服务器IO性能。
推荐使用pg_basebackup或者pg_rman等集成工具,自动执行start和stop
7. 逻辑备份是如何确保一致性的
备份前会启动一个事务,9.1版本开始默认隔离级别为REPEATABLE READ(之前为SERIALIZABLE),这样可以在整个备份期间使用事务开启时的快照,导出的所有表读取的都是该时间点的数据。如果加 --serializable-deferrable 参数,则使用的是可串行化隔离级别。
另外逻辑备份会对表加1级锁,避免备份过程中表结构被改变或者表被drop、truncate等。
以下代码在pg_dump.c 的 setup_connection 函数中
/*
* Start transaction-snapshot mode transaction to dump consistent data.
*/
ExecuteSqlStatement(AH, "BEGIN");
// pg 9.1版本及以上,默认为REPEATABLE READ隔离级别;9.1以下默认为SERIALIZABLE隔离级别
if (AH->remoteVersion >= 90100)
if (dopt->serializable_deferrable && AH->sync_snapshot_id == NULL)
ExecuteSqlStatement(AH,
"SET TRANSACTION ISOLATION LEVEL "
"SERIALIZABLE, READ ONLY, DEFERRABLE");
else
ExecuteSqlStatement(AH,
"SET TRANSACTION ISOLATION LEVEL "
"REPEATABLE READ, READ ONLY");
else
ExecuteSqlStatement(AH,
"SET TRANSACTION ISOLATION LEVEL "
"SERIALIZABLE, READ ONLY");
以下代码在pg_dump.c 的 getTables 函数中
/*
* Read-lock target tables to make sure they aren't DROPPED or altered
* in schema before we get around to dumping them.
*
* We only need to lock the table for certain components; see
* pg_dump.h
*/
if (tblinfo[i].dobj.dump &&
(tblinfo[i].relkind == RELKIND_RELATION ||
tblinfo->relkind == RELKIND_PARTITIONED_TABLE) &&
(tblinfo[i].dobj.dump & DUMP_COMPONENTS_REQUIRING_LOCK))
resetPQExpBuffer(query);
appendPQExpBuffer(query,
"LOCK TABLE %s IN ACCESS SHARE MODE",
fmtQualifiedDumpable(&tblinfo[i]));
ExecuteSqlStatement(fout, query->data);
参考:
pg_dump一致性备份以及cache lookup failed错误的原因分析_weixin_33835690的博客-CSDN博客
PostgreSQL backup and recovery - online logical backup & recovery-阿里云开发者社区
8. WAL 堆积的原因有哪些
不能清理
- 主库大事务、长事务、包括pg_dump,pg_dumpall导出
- 未开启归档,或归档命令执行失败(命令报错、目录不存在等)
select * from pg_stat_archiver;- 复制槽失效
- max_wal_size,wal_keep_size(pg 13前为wal_keep_segment)设置过大
清理慢
- 归档效率低,默认单进程归档,pg_BackRest可以实现多进程归档;归档目录IO性能过差
- 设置了复制槽且备库接收/应用WAL慢
产生速度过快
- 主库DML量过大,产生WAL日志过多
- 过于频繁的检查点,配合全页写机制可能会雪上加霜。当启用全页写时,pg会在每个检查点之后、每个页面第一次发生变更时,将整页写入WAL日志。
- 物理备份期间,强制启用全页写。只要页发生变化,就会将整页写入WAL日志(不管是不是第一次,也不管有没有检查点)。因此,它写入的量是更大的。
- 忘记执行pg_stop_backup关闭备份状态
- archive_timeout 参数设置过小导致频繁产生新WAL文件
9. 长连接的危害是什么
- 连接数堆积,可能超过 max_connections
- 连接数越多,进程调度和管理越复杂,pg性能会线性下降(pg 14对此进行了优化,但依然不建议过多)
- 无法及时释放内存,甚至遇到过导致oom的情况
- 空闲过长可能会被防火墙或者DB超时中断,导致应用报错
10. infomask 标志位的作用是什么
核心作用:提升元组可见性判断效率
pg事务篇(三)—— 事务状态与Hint Bits(t_infomask)_Hehuyi_In的博客-CSDN博客_pg事务篇(三)
11. 空值是如何存储的以及索引是否存储空值
索引是否存储空值
BTree 索引存储空值(SQL Server也存,Oracle不存),在官方文档也有提到
Also,an IS NULL or IS NOT NULL condition on an index column can be used with a B-Tree index。
空值是如何存储的
在pg元组头数据中,有一个t_bits 的数组,用于存储空值位图。当元组中没有null值的时候,t_bits可以被认为是空的,当元组有null值的列时,t_bits使用一个bit来表示列是否为null。
可以使用pageinspact工具来观察null是如何存储的
select lp,t_infomask,t_bits,t_data from heap_page_items(get_raw_page('t', 0));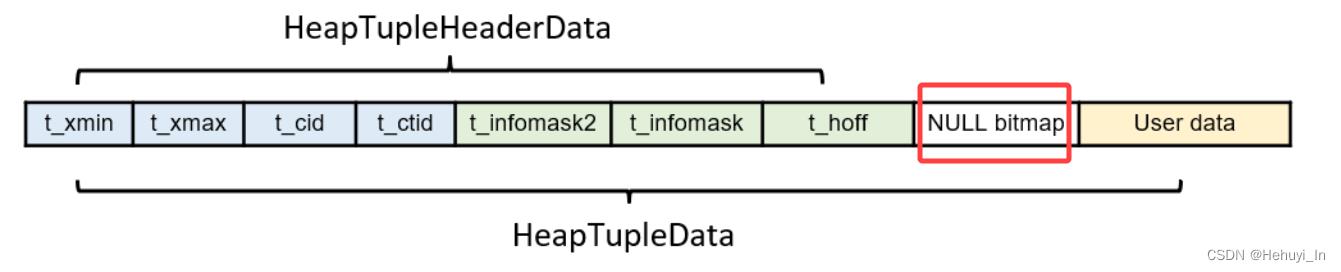
struct HeapTupleHeaderData
...
uint16 t_infomask; /* various flag bits, see below */
...
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
;判断字段是否为空代码在 tupmacs.h
#define att_isnull(ATT, BITS) (!((BITS)[(ATT) >> 3] & (1 << ((ATT) & 0x07))))还蛮有意思的,后面找时间专门记一篇学习下
参考:
PostgreSQL记录中的null值是如何存储的 - abce - 博客园
12. 为什么需要有全页写(full_page_write)
避免两种场景下的“部分写”(数据块不一致)问题:
- 由于DB page与 OS page默认大小不一致,在pg异常宕机(或出现磁盘错误)时,数据文件中的页有可能只写入了一部分。
- 使用操作系统命令备份正在写入的数据库时,备份文件中的数据块可能不一致。
无论是崩溃恢复还是备份还原的恢复,都无法基于不一致的数据块进行。
postgresql源码学习(34)—— 事务日志⑩ - 全页写机制_pgsql 全页写_Hehuyi_In的博客-CSDN博客
13. 索引失效的各种原因
不能用
- invalid索引
可能是创建中途被取消,也可以手动置为invalid。注意这种索引虽然不能用,但还是会被更新,增加开销。
update pg_index set indisvalid=false where indexrelid='i_ii'::regclass;
- 不支持的条件类型,例如hash index不支持范围查询
- 列与索引字符集/排序规则不一致(例如表关联字段)
- 隐式转换
- 软解析使用缓存的全表扫描执行计划,后续默认不会再解析生成新执行计划
- hint固定执行计划
- 非SARG条件:
- 字段上用函数,immutable类型函数可以建函数索引
- 字段上做运算
- 非操作符条件,not in 、<> 、!= 、not like
- like左边带%(使用pg_trgm插件创建gin索引除外)
- 数据库认为索引unsafe:开启old_snapshot_threshold参数,存在HOT Broken chain
不想用
优化器认为走索引cost比全表扫描更高
- 查询/返回数据量占比过大,可以再细分几种场景:
- 很小的表,例如10行的表返回9行
- 大表,但符合条件的过多(例如字段in大量值)
- 唯一值过少(例如性别)
- 数据倾斜(例如deleted=0 10行,deleted=1 99999行)
- 统计信息过旧(包括没有统计信息),执行计划估算错误
- 关联度:列物理顺序与逻辑顺序的相关性(统计信息中的correlation字段)
- 不符合最左原则
- 重复的索引
- 优化器刺客 limit,pg会倾向于不走索引,但在符合条件的数据非常少时,可能会有严重的性能问题
参考
67-oracle数据库,有索引,但是没有被使用的N种情况,以及应对方法(上篇)
68-oracle数据库,有索引,但是没有被使用的N种情况,以及应对方法(下篇)
14. commit log 的作用
保存事务最终状态,用于在可见性判断中确定事务的运行状态(在t_infomask未设置时,会根据clog来判断事务是否提交)。
postgresql源码学习(51)—— 提交日志CLOG 原理 用途 管理函数_Hehuyi_In的博客-CSDN博客
15. 数据库的连接方式以及各自适用的场景

图片来自PGCA课程《物理连接》
16. 各种索引的适用场景(HASH/GIN/BTREE/GIST/BLOOM/BRIN)
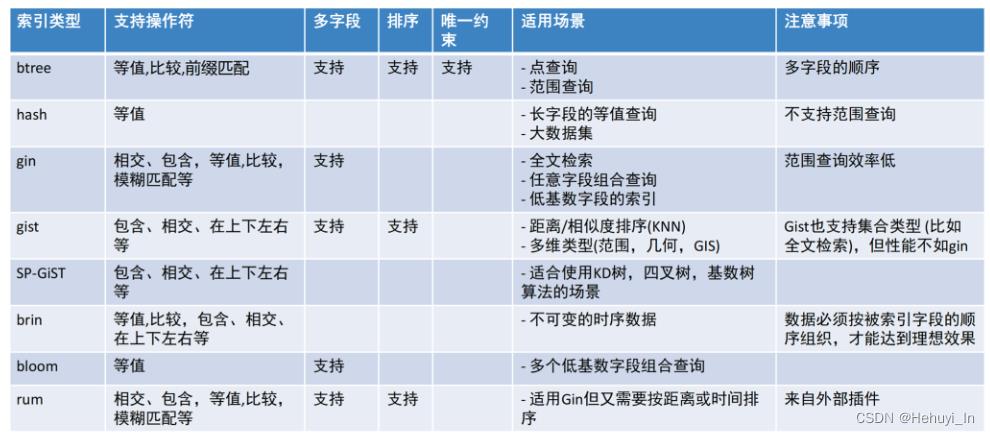
图片来自《PG DBA的一天》
17. 行锁是如何实现的,行锁是否会存储在共享内存中
pg采用元组级常规锁+xmax结合的方式实现行锁。不单纯用元组级常规锁,是为了避免事务修改行过多时,锁表急剧增大导致性能劣化,并且锁表在共享内存中的大小是有限的。因此,行锁也是不存储在内存中的。
行锁等级与兼容性
pg中通常有两种方式会用到行锁:
- 对行执行update,delete操作
- 显式指定行锁(for update,for no key update,for share,for key share)
由于pg行锁是由常规锁+xmax结合实现的,其实行锁的等级也是借助常规锁等级实现了映射。上面的四种行锁分别对应常规锁的8、7、2、1,锁之间的兼容性也一致。
xmax保存什么
通常如果只有一个事务增加行锁,那么直接将行的xmax设为事务id,并在infomask中设置对应锁类型即可。如果有多个事务对一个元组加共享锁,pg则会将多个事务组合,并为其指定唯一的MultiXactId,此时在xmax处保存的就是MultiXactId。
参考:
postgresql源码学习(十三)—— 行锁①-行锁模式与xmax_Hehuyi_In的博客-CSDN博客_postgresql锁
第28题
18. 流复制和逻辑复制的区别以及各自适用的场景
流复制和逻辑复制的区别
| 对比项 | 流复制 | 逻辑复制 |
| 引入版本 | pg 9.0 | pg 10 |
| 实现原理 | 将WAL文件传送到备库,由备库进行物理级replay | 将WAL文件传送到备库,按照配置规则解析为SQL语句并执行 |
| 数据一致性 | 高,主备库物理完全一致 | 一般,主备库物理可能一致,数据可能不一致 |
| 安装要求 | 1. 同构平台、大版本一致 2. wal_level 至少为 replica 3. 复制槽非必须 | 1. 平台和大版本可以不一致 2. wal_level = logical 3. 需要逻辑复制槽 |
| 同步范围 | 实例级,可同步所有对象的dml,ddl操作 | 表级,可同步表的dml及部分ddl操作(14版本支持truncate) |
| 同步级别 | 整个实例只能设置为同步或异步 | 可以对不同订阅单元设置不同同步级别 |
| 同步架构 | 一主多从、级联从库 | 一对多、多对一、多对多、级联 |
适用场景
流复制:
- 可靠的数据库高可用
- 可靠的数据库容灾
- 提供低延迟的只读备库
逻辑复制:
- 大版本升级
- 跨平台迁移(例如windows -> linux)
- 仅需同步数据库中部分表
- 仅部分表需要设置为同步模式,其余可为异步模式
- 备库需要执行写操作
- 多对一、多对多的数据同步
19. 流复制冲突是什么以及为什么会产生复制冲突
postgresql源码学习(48)—— 流复制冲突(备库锁阻塞与Vacuum冲突)_Hehuyi_In的博客-CSDN博客
20. 简述 PostgreSQL 中的权限体系
最常用的如下:
- instance级:pg_hba.conf,哪些服务器可以连接到数据库、认证方式
- DB级:连接、创建等
- schema级:usage、创建
- table级:增删改查、reference、truncate、trigger
- 列级:增改查、reference
- 行级:创建行策略,只允许用户看某些行
PostgreSQL: Documentation: 14: 5.7. Privileges
21. 常见的高可用方案以及高可用选型及优缺点
22. syPHP 经典面试题集
这篇文章介绍的内容是关于PHP 经典面试题集 PHP 经典面试题集,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下
结合我自己面试情况,面对的一些php面试题列举出来,基本上结合自己的看法回答的,不妥的地方请大家指出去,与大家一起讨论分析,也希望能帮到正在面试的童鞋们:
1.表单提交中的Get和Post的异同点
get 请求一般用于向服务端获取数据,post 一般向服务端提交数据
get 传输的参数在 url 中,传递参数大小有限制,post 没有大小限制,
get 不安全,post 安全性比get高
get请求在服务端用Request.queryString 接受 ,post 请求在服务端用Requset.form 接受
2.HTML的base标签是干什么用的
必须写在head 中, base 标签为页面上的所有链接规定默认地址或默认目标
3.echo(),print(),print_r()的区别?
echo是PHP语句, print和print_r是函数,语句没有返回值,函数可以有返回值(即便没有用)
print() 只能打印出简单类型变量的值(如int,string)
print_r() 可以打印出复杂类型变量的值(如数组,对象)
echo 输出一个或者多个字符串
4.写一个email的正则表达式
/^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$/
5.数组[‘a’, ‘b’, ‘c’] 转换成字符串 ‘abc’
echo implode(‘’,[‘a’, ‘b’, ‘c’]);
echo join([‘a’, ‘b’, ‘c’],‘‘);
6.获取字符串’aAbB’中A首次出现的位置
$str=‘aAbB’;
echo strpos($str,"A");
7. 编写一段用最小代价实现将字符串完全反序, e.g. 将 “1234567890” 转换成 “0987654321”. (用前述你最熟悉的语言编写并标注简单注释, 不要使用函数,
$s = ‘1234567890‘;
$o = ‘‘;
$i = 0;
while(isset($s[$i]) && $s[$i] != null) {
$o = $s[$i++].$o;
}
echo $o;
8.请用递归实现一个阶乘求值算法 F(n): n=5;F(n)=5!=5*4*3*2*1=120
function F($n){
if($n==0){
return 1;
}else{
return $n* F($n-1);
}
}var_dump(F(5));
9.将字符长fang-zhi-gang 转化为驼峰法的形式:FangZhiGang
//方法一
function Fun($str){
if(isset($str) && !empty($str)){
$newStr=‘‘;
if(strpos($str,‘-‘)>0){
$strArray=explode(‘-‘,$str);
$len=count($strArray);
for ($i=0;$i<$len;$i++){
$newStr.=ucfirst($strArray[$i]);
}
}
return $newStr; }
}
//方法二function Fun($str){
$arr1=explode(‘_‘,$str);
$str = implode(‘ ‘,$arr1);
return ucwords($str);
}
var_dump(Fun("fang-zhi-gang")); //FangZhiGang
10.数组内置的排序方法有哪些?
sort($array); //数组升序排序
rsort($array); //数组降序排序
asort($array); //根据值,以升序对关联数组进行排序
ksort($array); //根据建,以升序对关联数组进行排序
arsort($array); //根据值,以降序对关联数组进行排序
krsort($array); // 根据键,以降序对关联数组进行排序
11.用PHP写出显示客户端IP与服务器IP的代码
$_SERVER["REMOTE_ADDR"]
$_SERVER["SERVER_ADDR"]
12.语句include和require的区别是什么?为避免多次包含同一文件,可用(?)语句代替它们?
require是无条件包含也就是如果一个流程里加入require,无论条件成立与否都会先执行require
include有返回值,而require没有(可能因为如此require的速度比include快)
包含文件不存在或者语法错误的时候require是致命的错误终止执行,include不是
13.session与cookie的区别?
session:储存用户访问的全局唯一变量,存储在服务器上的php指定的目录中的(session_dir)的位置进行的存放
cookie:用来存储连续訪問一个頁面时所使用,是存储在客户端,对于Cookie来说是存储在用户WIN的Temp目录中的。
两者都可通过时间来设置时间长短
14.PHP 不使用第三个变量实现交换两个变量的值
//方法一
$a.=$b;
$b=str_replace($b,"",$a);
$a=str_replace($b,"",$a);
//方法二
list($b,$a)=array($a,$b);
var_dump($a,$b);
15.写一个方法获取文件的扩展名
function get_extension($file){
//方法一
return substr(strrchr($file,‘.‘), 1);
//方法二
return end(explode(‘.‘, $file));
}echo get_extension(‘fangzhigang.png‘); //png
16.用PHP打印出前一天的时间格式是2017-3-22 22:21:21
$a= date("Y-m-d H:i:s", strtotime("-1 days"));
17.sql语句应该考虑哪些安全性
(1)防止sql注入,对特殊字符进行转义,过滤或者使用预编译sql语句绑定
(2)使用最小权限原则,特别是不要使用root账户,微不同的动作或者操作建立不同的账户
(3)当sql出错时,不要把数据库出错的信息暴露到客户端
18.优化mysql 数据库方法
(1)选取适当的字段,打字段设置为NOT NULL,在查询的时候数据库不用比较NULL;
(2)使用链接(join)代替子查询;
(3)使用联合(UNION)查询代替手动创建临时表;
(4)尽量减少使用(LIKE)关键字和通配符
(5)使用事务和外健
19.对于大流量的网站,你会采用什么方法来解决访问量?
(1)首先确认服务器硬件是否满足支持当前的流量;
(2)优化数据库的访问;
(3)禁止外部盗链;
(4)控制大文件下载;
(5)使用不同的主机分流;
(6)使用流量分析统计;
20.mysql_fetch_row() 和mysql_fetch_array之间有什么区别?
这两个函数,返回的都是一个数组,区别就是第一个函数返回的数组是只包含值,我们只能$row[0],$row[1],这样以数组下标来读取数据,
而MySQL_fetch_array()返回的数组既包含第一种,也包含键值对的形式,我们可以这样读取数据,(假如数据库的字段是 username,passwd):$row[‘username‘]$row[‘passwd‘]
21.MySQL的几个概念:主键,外键,索引,唯一索引
主键(primary key) 能够唯一标识表中某一行的属性或属性组。一个表只能有一个主键,但可以有多个候选索引。主键常常与外键构成参照完整性约束,防止出现数据不一致。主键可以保证记录的唯一和主键域非空,数据库管理系统对于主键自动生成唯一索引,所以主键也是一个特殊的索引。
外键(foreign key) 是用于建立和加强两个表数据之间的链接的一列或多列。外键约束主要用来维护两个表之间数据的一致性。简言之,表的外键就是另一表的主键,外键将两表联系起来。一般情况下,要删除一张表中的主键必须首先要确保其它表中的没有相同外键(即该表中的主键没有一个外键和它相关联)。
索引(index) 是用来快速地寻找那些具有特定值的记录。主要是为了检索的方便,是为了加快访问速度, 按一定的规则创建的,一般起到排序作用。所谓唯一性索引,这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。
总结:
主键一定是唯一性索引,唯一性索引并不一定就是主键。
一个表中可以有多个唯一性索引,但只能有一个主键。
主键列不允许空值,而唯一性索引列允许空值。
主键可以被其他字段作外键引用,而索引不能作为外键引用。
22.mysql数据库引擎有哪些?
MyISAM、 ISAM、HEAP、InnoDB、BDB、CVS...
23.谈谈你对 mysql 引擎中的MyISAM与InnoDB的区别理解?
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持已经外部键等高级数据库功能。
以下是一些细节和具体实现的差别:
MyISAM与InnoDB的区别是什么?
1、 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
2、 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
9、 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。
10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
11、 外键
MyISAM:不支持
InnoDB:支持
通过上述的分析,基本上可以考虑使用InnoDB来替代MyISAM引擎了,原因是InnoDB自身很多良好的特点,比如事务支持、存储 过程、视图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。
24. redis 和 memache 缓存的区别
总结一:
1.数据类型
Redis数据类型丰富,支持set list等类型
memcache支持简单数据类型,需要客户端自己处理复杂对象
2.持久性
redis支持数据落地持久化存储
memcache不支持数据持久存储
3.分布式存储
redis支持master-slave复制模式
memcache可以使用一致性hash做分布式
value大小不同
memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
4.数据一致性不同
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
5.cpu利用
redis单线程模型只能使用一个cpu,可以开启多个redis进程
总结二:
1.Redis中,并不是所有的数据都一直存储在内存中的,这是和Memcached相比一个最大的区别。
2.Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3.Redis支持数据的备份,即master-slave模式的数据备份。
4.Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
我个人认为最本质的不同是Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcached只是简单的K/V缓存
总结三:
redis和memecache的不同在于:
1、存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性。
2、数据支持类型:
redis在数据支持上要比memecache多的多。
3、使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同:
redis目前官方只支持Linux 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
memcache只能当做缓存,cache
redis的内容是可以落地的,就是说跟MongoDB有些类似,然后redis也可以作为缓存,并且可以设置master-slave
25.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列。
drop table table1 create table table1(
a int,
b int,
c int ) insert into table1 values(22,24,23)
select * from table1
select (case when a>b then a else b end),(case when b>c then b else c end) from table1
select (case when a>b then a
when a>c then a
when b>c then b else c
end) from table1
26.安装Linux系统中,用netconfig程序对网络进行配置,要输入哪些内容?
会让用户输入主机名、域名、域名服务器、IP地址、网关地址和子网掩码等必要信息
27. PHP 如何写接口给人家调用?
public function authenticationApi($data,$url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
//输出格式可以转为数组形式的json格式
$tmpInfo = curl_exec($ch);
curl_close($ch);
return $tmpInfo;
}
28.用PHP header()函数实现页面404错误提示功能
Header("HTTP/1.1 404 Not Found");
29.heredoc结构及用法
echo <<<EOT
<html>
<head><title>主页</title></head>
<body>主页内容</body>
</html>
EOT;
注意:结束标识符所在的行不能包含任何其它字符除";"
30.nowdoc结构及用法
$str = <<<‘EOD‘
Example of string
spanning multiple lines
using nowdoc syntax.
EOD;
31.javascript 判断弹出窗口是否被屏蔽程序代码
var wroxWin = window.open("http://www.111cn.net", "_blank");if (wroxWin == null) {
alert("糟糕!弹出窗口被屏蔽了");}
32. php序列化和反序列化用的函数
serialize() 序列化
unserialize() 反序列化
33. 利用下表结构,写出发贴数最多的十个人名字的SQL语句(members(id,username,posts,pass,email)
select memebers.username from members group by posts desc limit 10
34,.以Apache模块的方式安装PHP,在文件http.conf中首先要用语句(?)动态装载PHP模块,然后再用语句(?)使得Apache把所有扩展名为php的文件都作为PHP脚本处理。
1.LoadModule php5_module "c:/php/php5apache2.dll")
2.AddType application/x-httpd-php .php
35.数据库中的事务是什么?
事务就是一系列的操作,这些操作完成一项任务。只要这些操作里有一个操作没有成功,事务就操作失败,发生回滚事件。即撤消前面的操作,这样可以保证数据的一致性。而且可以把操作暂时放在缓存里,等所有操作都成功有提交数据库,这样保证费时的操作都是有效操作。
36.apche 和 nginx 的优缺
nginx轻量级,比apache占用更少的内存及资源,抗并发,nginx处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能。apache 相对于nginx 的优点:rewrite比nginx 的rewrite 强大,少bug,稳定。(需要性能用nginx,求稳定就apache)。
37.求两个日期的差数,例如2007-2-5 ~ 2007-3-6 的日期差数
// 方法一:用DateTime类
$day1 = ‘2003-09-16‘;
$day2 = ‘2011-11-23‘;
$d1 = new dateTime($day1);
$d2 = new dateTime($day2);
echo $d1->diff($d2)->days;
// 方法二,用时间戳计算
echo (strtotime($day2) - strtotime($day1))/(24*3600);
38.下面的代码用来做什么?请解释。$date=‘08/26/2003‘;
print ereg_replace("([0-9]+)/([0-9]+)/([0-9]+)","\2/\1/\3",$date);
这是把一个日期从 MM/DD/YYYY 的格式转为 DD/MM/YYYY 格式。我的一个好朋友告诉我可以把这个正规表达式拆解为以下的语句,对于如此简单的表示是来说其实无须拆解,纯粹为了解说的方便:
// 对应一个或更多 0-9,后面紧随一个斜号$regExpression = "([0-9]+)/";
// 应一个或更多 0-9,后面紧随另一个斜号$regExpression .= "([0-9]+)/";
// 再次对应一个或更多 0-9$regExpression .= "([0-9]+)";至于 \2/\1/\3 则是用来对应括号,第一个括号对的是月份
39.在PHP中,当前脚本的名称(不包括路径和查询字符串)记录在预定义变量(?)中;而链接到当前页面的URL记录在预定义变量(?)中。
(1) echo $_SERVER[‘PHP_SELF‘];
(2) echo $_SERVER["HTTP_REFERER"];
40.一个函数的参数不能是对变量的引用,除非在php.ini中把(?)设为on.
allow_call_time_pass_reference
今天就先写到这里吧!在后期的面试中遇到不同的面试题我会不定期更新
希望此文会给大家带来帮助,觉写的不错的,对你有帮助中的请动动你的手关注我和点赞分享,祝愿正在找工作的你,能找一份满意的工作。祝你新的旅途愉快!
以上就是PHP 经典面试题集的详细内容
相关推荐:
阿里面试官三年经验PHP程序员知识点汇总,学会你就是下一个阿里人!
以上是关于《PostgreSQL面试题集锦》学习与回答的主要内容,如果未能解决你的问题,请参考以下文章
/^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$/echo implode(‘’,[‘a’, ‘b’, ‘c’]);
echo join([‘a’, ‘b’, ‘c’],‘‘);$str=‘aAbB’;
echo strpos($str,"A");$s = ‘1234567890‘;
$o = ‘‘;
$i = 0;
while(isset($s[$i]) && $s[$i] != null) {
$o = $s[$i++].$o;
}
echo $o;function F($n){
if($n==0){
return 1;
}else{
return $n* F($n-1);
}
}var_dump(F(5));//方法一
function Fun($str){
if(isset($str) && !empty($str)){
$newStr=‘‘;
if(strpos($str,‘-‘)>0){
$strArray=explode(‘-‘,$str);
$len=count($strArray);
for ($i=0;$i<$len;$i++){
$newStr.=ucfirst($strArray[$i]);
}
}
return $newStr; }
}
//方法二function Fun($str){
$arr1=explode(‘_‘,$str);
$str = implode(‘ ‘,$arr1);
return ucwords($str);
}
var_dump(Fun("fang-zhi-gang")); //FangZhiGangsort($array); //数组升序排序
rsort($array); //数组降序排序
asort($array); //根据值,以升序对关联数组进行排序
ksort($array); //根据建,以升序对关联数组进行排序
arsort($array); //根据值,以降序对关联数组进行排序
krsort($array); // 根据键,以降序对关联数组进行排序$_SERVER["REMOTE_ADDR"]
$_SERVER["SERVER_ADDR"]require是无条件包含也就是如果一个流程里加入require,无论条件成立与否都会先执行require
include有返回值,而require没有(可能因为如此require的速度比include快)
包含文件不存在或者语法错误的时候require是致命的错误终止执行,include不是
session:储存用户访问的全局唯一变量,存储在服务器上的php指定的目录中的(session_dir)的位置进行的存放
cookie:用来存储连续訪問一个頁面时所使用,是存储在客户端,对于Cookie来说是存储在用户WIN的Temp目录中的。
两者都可通过时间来设置时间长短//方法一
$a.=$b;
$b=str_replace($b,"",$a);
$a=str_replace($b,"",$a);
//方法二
list($b,$a)=array($a,$b);
var_dump($a,$b);function get_extension($file){
//方法一
return substr(strrchr($file,‘.‘), 1);
//方法二
return end(explode(‘.‘, $file));
}echo get_extension(‘fangzhigang.png‘); //png$a= date("Y-m-d H:i:s", strtotime("-1 days")); (1)防止sql注入,对特殊字符进行转义,过滤或者使用预编译sql语句绑定
(2)使用最小权限原则,特别是不要使用root账户,微不同的动作或者操作建立不同的账户
(3)当sql出错时,不要把数据库出错的信息暴露到客户端(1)选取适当的字段,打字段设置为NOT NULL,在查询的时候数据库不用比较NULL;
(2)使用链接(join)代替子查询;
(3)使用联合(UNION)查询代替手动创建临时表;
(4)尽量减少使用(LIKE)关键字和通配符
(5)使用事务和外健(1)首先确认服务器硬件是否满足支持当前的流量;
(2)优化数据库的访问;
(3)禁止外部盗链;
(4)控制大文件下载;
(5)使用不同的主机分流;
(6)使用流量分析统计;这两个函数,返回的都是一个数组,区别就是第一个函数返回的数组是只包含值,我们只能$row[0],$row[1],这样以数组下标来读取数据,
而MySQL_fetch_array()返回的数组既包含第一种,也包含键值对的形式,我们可以这样读取数据,(假如数据库的字段是 username,passwd):$row[‘username‘]$row[‘passwd‘]主键(primary key) 能够唯一标识表中某一行的属性或属性组。一个表只能有一个主键,但可以有多个候选索引。主键常常与外键构成参照完整性约束,防止出现数据不一致。主键可以保证记录的唯一和主键域非空,数据库管理系统对于主键自动生成唯一索引,所以主键也是一个特殊的索引。
外键(foreign key) 是用于建立和加强两个表数据之间的链接的一列或多列。外键约束主要用来维护两个表之间数据的一致性。简言之,表的外键就是另一表的主键,外键将两表联系起来。一般情况下,要删除一张表中的主键必须首先要确保其它表中的没有相同外键(即该表中的主键没有一个外键和它相关联)。
索引(index) 是用来快速地寻找那些具有特定值的记录。主要是为了检索的方便,是为了加快访问速度, 按一定的规则创建的,一般起到排序作用。所谓唯一性索引,这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。
总结:
主键一定是唯一性索引,唯一性索引并不一定就是主键。
一个表中可以有多个唯一性索引,但只能有一个主键。
主键列不允许空值,而唯一性索引列允许空值。
主键可以被其他字段作外键引用,而索引不能作为外键引用。MyISAM、 ISAM、HEAP、InnoDB、BDB、CVS...InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持已经外部键等高级数据库功能。
以下是一些细节和具体实现的差别:
MyISAM与InnoDB的区别是什么?
1、 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
2、 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
9、 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。
10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
11、 外键
MyISAM:不支持
InnoDB:支持
通过上述的分析,基本上可以考虑使用InnoDB来替代MyISAM引擎了,原因是InnoDB自身很多良好的特点,比如事务支持、存储 过程、视图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。总结一:
1.数据类型
Redis数据类型丰富,支持set list等类型
memcache支持简单数据类型,需要客户端自己处理复杂对象
2.持久性
redis支持数据落地持久化存储
memcache不支持数据持久存储
3.分布式存储
redis支持master-slave复制模式
memcache可以使用一致性hash做分布式
value大小不同
memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
4.数据一致性不同
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
5.cpu利用
redis单线程模型只能使用一个cpu,可以开启多个redis进程
总结二:
1.Redis中,并不是所有的数据都一直存储在内存中的,这是和Memcached相比一个最大的区别。
2.Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3.Redis支持数据的备份,即master-slave模式的数据备份。
4.Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
我个人认为最本质的不同是Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcached只是简单的K/V缓存
总结三:
redis和memecache的不同在于:
1、存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性。
2、数据支持类型:
redis在数据支持上要比memecache多的多。
3、使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同:
redis目前官方只支持Linux 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
memcache只能当做缓存,cache
redis的内容是可以落地的,就是说跟MongoDB有些类似,然后redis也可以作为缓存,并且可以设置master-slavedrop table table1 create table table1(
a int,
b int,
c int ) insert into table1 values(22,24,23)
select * from table1
select (case when a>b then a else b end),(case when b>c then b else c end) from table1
select (case when a>b then a
when a>c then a
when b>c then b else c
end) from table1会让用户输入主机名、域名、域名服务器、IP地址、网关地址和子网掩码等必要信息public function authenticationApi($data,$url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
//输出格式可以转为数组形式的json格式
$tmpInfo = curl_exec($ch);
curl_close($ch);
return $tmpInfo;
}Header("HTTP/1.1 404 Not Found");echo <<<EOT
<html>
<head><title>主页</title></head>
<body>主页内容</body>
</html>
EOT;
注意:结束标识符所在的行不能包含任何其它字符除";"$str = <<<‘EOD‘
Example of string
spanning multiple lines
using nowdoc syntax.
EOD;var wroxWin = window.open("http://www.111cn.net", "_blank");if (wroxWin == null) {
alert("糟糕!弹出窗口被屏蔽了");}serialize() 序列化
unserialize() 反序列化select memebers.username from members group by posts desc limit 101.LoadModule php5_module "c:/php/php5apache2.dll")
2.AddType application/x-httpd-php .php事务就是一系列的操作,这些操作完成一项任务。只要这些操作里有一个操作没有成功,事务就操作失败,发生回滚事件。即撤消前面的操作,这样可以保证数据的一致性。而且可以把操作暂时放在缓存里,等所有操作都成功有提交数据库,这样保证费时的操作都是有效操作。nginx轻量级,比apache占用更少的内存及资源,抗并发,nginx处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能。apache 相对于nginx 的优点:rewrite比nginx 的rewrite 强大,少bug,稳定。(需要性能用nginx,求稳定就apache)。// 方法一:用DateTime类
$day1 = ‘2003-09-16‘;
$day2 = ‘2011-11-23‘;
$d1 = new dateTime($day1);
$d2 = new dateTime($day2);
echo $d1->diff($d2)->days;
// 方法二,用时间戳计算
echo (strtotime($day2) - strtotime($day1))/(24*3600);38.下面的代码用来做什么?请解释。$date=‘08/26/2003‘;print ereg_replace("([0-9]+)/([0-9]+)/([0-9]+)","\2/\1/\3",$date); 这是把一个日期从 MM/DD/YYYY 的格式转为 DD/MM/YYYY 格式。我的一个好朋友告诉我可以把这个正规表达式拆解为以下的语句,对于如此简单的表示是来说其实无须拆解,纯粹为了解说的方便:
// 对应一个或更多 0-9,后面紧随一个斜号$regExpression = "([0-9]+)/";
// 应一个或更多 0-9,后面紧随另一个斜号$regExpression .= "([0-9]+)/";
// 再次对应一个或更多 0-9$regExpression .= "([0-9]+)";至于 \2/\1/\3 则是用来对应括号,第一个括号对的是月份 (1) echo $_SERVER[‘PHP_SELF‘];
(2) echo $_SERVER["HTTP_REFERER"];allow_call_time_pass_reference