联邦学习+区块链FLchain: Federated Learning via MEC-enabled Blockchain Network
Posted WuwuwuwH_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习+区块链FLchain: Federated Learning via MEC-enabled Blockchain Network相关的知识,希望对你有一定的参考价值。
文章目录
论文地址:https://ieeexplore.ieee.org/document/8892848
1. Introduction
传统的联邦学习中,移动设备根据本地的数据样本进行本地模型的更新,并将其发送至中央服务器。中央服务器将接收到的模型更新进行聚合,并更新全局模型。移动设备获取更新后的全局模型,进而进行本地模型的下一次更新。这种方式存在弊端,数据存储以及数据计算依赖于中央服务器的可靠性。区块链是一种按时间顺序、去中心化、可追溯且不可变的账本技术。以区块链替换中心服务器是解决上述问题的有效方案。区块链和联邦学习的结合实现了一种实用的高鲁棒性的去中心化模型训练方案,保证了用户数据的隐私性。训练好的模型参数能够安全地存储在区块链中,对未经授权的访问和恶意行为具有万无一失的抵抗能力。此外,区块链还能够安全地保存模型的来源和时序信息。
2. Preliminaries and Definition
A. Channel Fabric引入了信道(channel)的概念,用于实现至少两个peer之间的隔离通信。只有与信道相关联的peer才有权在信道内读取、提交和验证交易。每个信道都有一个单独的账本。在FLchain中,对于每个全局模型,都会创建一个带有创世块的新信道,存储特定的分类账。创世块存储了全局学习模型的初始权重、权重的维度、超参数、激活函数和偏置。
B. Global Model State Trie 类似于以太坊中追踪账户状态的“Account State Trie”,文章提出了“Global Model State Trie”来追踪FLchain中全局模型的权重。每个channel都有自己的Global Model State Trie,以键值对的方式存储权重(key:权重位置,vlaue:权重系数)。权重系数与区块的生成同步更新。在达成共识后,Global Model State Trie为全局模型提供更新的权重系数。
3. System Model
FLchain的架构如 F i g . 1 Fig.1 Fig.1所示,包含移动终端和边缘设备。移动终端基于本地数据计算本地模型更新。边缘设备具有两种功能:首先,为网络资源受限的移动终端提供网络资源。其次,作为FLchain区块链网络中的节点。

每个全局模型 M j M_j Mj在单独的信道中进行训练。FLchain中可用的信道集合表示为 C = 1 , 2 , 3 , . . . , C n C = \\1,2,3,...,C_n\\ C=1,2,3,...,Cn。 C n C_n Cn表示FLchain中可用信道的数量, D j D_j Dj表示信道 j j j中注册设备的数量。由边缘设备组成的区块链网络将来自用户设备的本地模型更新以区块的形式存储在特定信道的独立区块链上。区块链网络还计算并安全地将全局模型更新储存在Merkle Patricia Tree上的特定信道账本中。
4. Blockchain operations in FLchain
A l g o r i t h m 1 Algorithm \\ 1 Algorithm 1展示了针对信道 j j j的FLchain操作。 F i g . 3 Fig.3 Fig.3展示了通道 j j j中设备 i i i的FLchain的操作流程图。


A. Initialization 为每个新的全局模型的训练创建一个新的信道。初始权重参数和其他必要的配置被设置并存储在创世块中。 j j j表示信道, M j M_j Mj表示信道 j j j中所训练的全局模型。FLchain能够应用到任何模型的训练,文中考虑模型 M j M_j Mj为线性回归模型。 D j D_j Dj表示与信道 j j j相关联的设备集合。 S i , j S_i,j Si,j信道 j j j中设备 i i i所拥有的样本集合。 S j = ⋃ i ∈ D j S i , j S_j=\\bigcup_i\\in D_j S_i,j Sj=⋃i∈DjSi,j,表示信道 j j j中所有设备的总样本集合, ∣ S j ∣ = N S , j \\left | S_j \\right | =N_S,j ∣Sj∣=NS,j,表示信道 j j j中总样本数量。学习目标为基于全部样本 s z ∈ S j s_z \\in S_j sz∈Sj, s z s_z sz= x z \\x_z xz, y z y_z yz 最小化损失函数 L ( ω ) L(\\omega ) L(ω),最佳权重参数为 ω j ∗ \\omega_j^* ωj∗。 ω j \\omega_j ωj为 d d d维列向量,表示信道 j j j的全局模型权重向量。全局迭代t=0时的初步权重参数是从预定范围内随机选择的。全局权重参数: ω j ( 0 ) \\omega_j(0) ωj(0),设备 i i i的本地权重参数 ω i , j ( 0 ) \\omega_i,j(0) ωi,j(0)。

B. Channel Inquiry 当一个设备 i i i想加入FLchain的特定信道时,首先需要进行信道查询;随后,可用信道的列表 C C C由区块链网络发送给移动设备。
C. Channel Selection 当设备 i i i想加入某个特定的全局模型训练时会进行信道查询。一旦拥有可访问的信道列表 C C C,便可针对特定的全局模型选择相关的信道 c i c_i ci。设备 i i i选择的频道 c i c_i ci使用 j j j表示。
D. Device Registration 如果设备 i i i还没有注册,设备需要为其事先选定的信道注册。注册完毕后,设备会被分配私钥和公钥,通过这些私钥和公钥便可以向信道提交其修订的本地模型权重。 P r i i , j Pri_i,j Prii,j和 P u b i , j Pub_i,j Pubi,j表示为信道 j j j中设备 i i i所分配的私钥和公钥。
E. Local Model Update 在完成设备注册或收到计算本地模型下一次更新的通知后,设备通过其相关的边缘节点从区块链网络下载最新的全局模型参数
ω
j
(
t
−
1
)
\\omega_j(t-1)
ωj(t−1)。
t
t
t表示当前全局模型迭代,需要在信道
j
j
j中计算(不同的信道迭代次数可能不同)。对于每个全局模型迭代
t
t
t,设备
D
i
D_i
Di的局部模型更新
V
V
V个epochs。在本地模型的epoch
v
v
v,设备
i
i
i的本地模型通过stochastic variance reduced gradient(SVRG)更新。
η
>
0
\\eta >0
η>0为step-size,在
V
V
V个本地epochs后可得
ω
i
,
j
(
t
)
=
ω
i
,
j
V
(
t
)
\\omega_i,j(t)= \\omega_i,j^V(t)
ωi,j(t)=ωi,jV(t)。本地模型更新
ω
i
,
j
(
t
)
\\omega_i,j(t)
ωi,j(t)由设备
i
i
i决定,并以交易的形式转发给区块链网络。
t
r
a
n
s
i
,
j
(
t
)
trans_i,j(t)
transi,j(t)表示信道
j
j
j中设备
i
i
i在第
t
t
t轮迭代中生成的交易,由设备的私钥
P
r
i
i
,
j
Pri_i,j
Prii,j签名。交易数据包括
(
ω
i
,
j
(
t
)
,
▽
l
z
(
ω
j
(
t
)
)
s
z
∈
S
i
,
j
)
(\\omega_i,j(t),\\\\bigtriangledown l_z(\\omega_j(t))\\_s_z \\in S_i,j)
(ωi,j(t),▽l群体智能中的联邦学习算法综述---简笔记(除安全类)
群体智能中的联邦学习算法简述
[1]杨强,童咏昕,王晏晟,范力欣,王薇,陈雷,王魏,康焱.群体智能中的联邦学习算法综述[J].智能科学与技术学报,2022,4(01):29-44.
(仅用于个人笔记,并未有修改, 阅读原文更佳)
介绍
介绍群体智能与联邦学习的关系,从隐私、精度与效率 3 个角度讨论了联邦学习算法优化技术,由于方向只关注精度与效率。联邦学习框架分类中心化、去中心化和半中心化。联邦学习算法模型包括线性模型、树模型和神经网络模型。
联邦学习: 以谷歌为例,大规模群体移动设备用户想仅通过传递模型梯度或加密后的梯度来实现联合模型的构建,联邦学习场景中的个体也从个人推广到企业或机构,在各自数据都不离开本地的前提下,弥补各自数据的短板,联合构建智能模型,实现互利共赢。

群体智能与联邦学习的关系
(1)相似性
20 世纪 90 年代由维克托·莱瑟(Victor Lesser)教授创立的多智体系统领域是群体智能的代表性传统领域 [9],而联邦学习本身也可被视为一个多智体系统,有研究工作就结合多智体系统和与博弈论相关的技术来解决联邦学习中的激励建模等 [10] 问题。
群体智能中的众包,是指把复杂的任务分解成简单的任务交给广大互联网用户来完成,与联邦学习思想与其不谋而合,在隐私保护、激励机制、质量控制等多个方面都借助或延伸了传统众包中的相关方法。
面向多方的机器学习方法,如联合学习(joint learning)[13]、多任务学习(multitask learning)[14-15]、分布式机器学习(distributed machine learning)[16] 等,这类方法由于涉及多方共同构建智能应用,也常被划入群体智能范畴,其研究的分布式大规模数据场景与联邦学习类似,其多方协作学习的方法对于联邦学习的研究也有一定启发作用。
(2)独特性
联邦学习是当前群体智能领域解决隐私限制下大规模协同学习问题的重要方法,其旨在在各参与方所拥有的原始数据不离开本地的情况下,通过传输安全处理后的数据或中间结果,达到隐私保护要求下集成多方数据训练模型的效果,因此对数据或模型隐私安全的关注是许多其他群体智能领域未曾考虑的,也是其核心的技术特点之一。
联邦学习中参与学习的多方自治,从而导致计算设备异构、数据异质(即非独立同分布)等挑战,在这些挑战下,模型的精度与可用性大大降低,同时过大的计算与通信开销也使得算法难以落地,因此需要针对性的优化方法。
联邦学习框架分类
中心化联邦
存在一个协调构建群体学习模型的中心服务器,其余联邦参与方可以在中心服务器进行模型聚合、模型分发、收敛判定等联邦模型训练的基础操作。

半中心化联邦
基于聚类划分的联邦学习(clustered federated learning)[17-18]、基于层次划分的联邦学习(hierarchical federated learning)。
(1)基于聚类划分的联邦学习主要考虑参与方具有不同的任务,并通过全局模型来优化本地模型的情景,其通过推断参与方的任务类型进行聚类划分,然后使用多个聚类中心聚合各方模型,通过聚类划分能够避免不相关的联邦参与方之间相互干扰,提升联合构建的群体模型的精度。
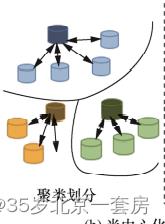
【1】Ghosh A 等人 [19] 较早研究了在多中心群体结构场景下的联邦学习算法,其假设所有 N 个联邦参与方的模型适用于 K 类任务,即存在 K 个聚类中心
【2】Sattler F 等人 [17] 提出了类似的联邦学习框架,其不明确计算各参与方之间的距离(相似度),而是通过评估不同聚类所提升的本地模型准确度,来确定各个联邦参与方具体归属于哪一个类别。
(2)基于层次划分的联邦学习则主要考虑如何降低无线网络中的通信时延,其先在中间层节点进行局部模型聚合,避免所有参与方直接与远程中心服务器进行长距离通信,从而能够有效降低参与方的总体通信开销。
在移动网络中,由于链接距离不同,所有联邦成员参与方均直接与中心服务器相互传输数据通常容易导致较高的通信成本 [18]。为了解决上述问题,Abad M S H 等人 [18] 提出了基于层次划分的联邦学习框架,通过划分层级并选择区域中心降低通信时延。

根据地理位置与时延大小,将联邦节点(参与方)划分为 3 级,自底向上依次为:① 数据节点(worker),具有本地数据的联邦学习参与方;② 中间节点(cluster head),负责聚合部分数据节点的训练结果;③ 模型节点(model owner),负责聚合中间节点的局部模型,并获得最终的联邦模型。
去中心化联邦(未涉及区块链等隐私的研究,所以未总结)
去中心化群体组织结构允许联邦参与方中不存在聚合各方模型的协调者。因此,需要设计模型聚合的联邦网络,其核心在于设计支持模型聚合的对等网络(peer-to-peer network)。

精度优化
泛化性优化
多客户端协作产生在具体任务上拥有较强泛化能力的机器学习模型,其能够使各客户端在保障数据安全的前提下协同训练机器学习模型,实现数据拥有方可以共享数据价值而不共享数据本身。
为了减小数据异质性对模型性能的影响,谷歌研究院的 Mcmahan H B 等人 [2] 首先提出了 FedAvg 算法。在混合分布上训练,设置权重,为客户端对应的数据规模比例。然而这样产生的模型将偏向持有较大数据量的客户端,从而对模型的泛化性能造成影响。
Mohri M 等人 [49] 提出了不可知联邦学习(agnostic federated learning)框架,用于分析数据异质场景下联邦学习的泛化性能。对于多客户端分布 ,不可知联邦学习在所有可能的测试分布上构建模型,其中权重 λ 属于 N 维单纯形 ΔN ,基于权重 λ i λ_i λi 与样本比例 N i / N N_ i/N Ni/N 之间的偏度以及拉德马赫尔(Rademacher)复杂度给出了不可知联邦学习的泛化误差界。不可知联邦学习通过求解对应的最小最大(minmax)优化问题,能够产生在任意目标分布上性能鲁棒的全局模型。然而对于分布与全局分布差异较大的客户端来说,单一的全局模型在该客户端上的性能通常较差。Mansour Y 等人 [50] 提出 3 种能够为客户端定制个性化模型的方法,分别为客户端聚类、数据插值以及模型插值,并给出了相应的泛化误差界;Deng Y 等人 [51] 又针对客户端的模型插值进行改进,提出了一种自适应泛化误差界的学习方法。
收敛性优化
异质数据还会影响联邦学习的训练效率,导致模型收敛速度降低。在联邦学习的每一轮模型训练中,中央服务器都需要聚合并发送客户端的模型参数,因此客户端之间分布的偏移将影响联邦模型的收敛速率。Li T 等人 [52] 的研究表明,当参与者的数据分布与平均分布之间存在较大偏差时,FedAvg 算法的收敛速率会大幅下降。
Karimireddy S P 等人 [53] 借助控制变量纠正 FedAvg 算法在处理非独立同分布数据时产生的客户端偏移现象,并从理论上证明了所提随机控制平均(stochastic controlled averaging for federated learning SCAFFOLD)方法具有更高的收敛速率。SCAFFOLD 方法仅考虑降低通信代价,模型精度无法得到很好的保证。Rothchild D 等人 [54] 提出了基于略图的联邦梯度下降方法 FetchSGD,试图解决因客户端参与的稀疏性导致收敛速率缓慢的难题,并从理论上证明在保证一定泛化性能的前提下,FetchSGD 方法能够通过压缩梯度降低通信代价,从而提高收敛速率;Hamer J 等人 [55] 基于集成学习的思想提出了高效的 FedBoost(federated boosting)方法,并针对密度估计这一特定任务,从理论上分析了 FedBoost 的泛化误差界。尽管 Rothchild D 等人 [54] 和 Hamer J 等人 [55] 的工作在模型性能以及训练效率方面有较好的提升,但这些方法在一定程度上增加了模型复杂度,为方法的实际部署带来了困难。
效率优化
Haddadpour F 等人 [59] 针对同质和异质的联邦学习分别提出了周期性压缩算法——带压缩的联邦平均(federated averaging with compression,FedCOM)与带压缩和局部梯度跟踪的联邦平均 (federated averaging with compression and local gradient tracking,FedCOMGATE),并给出了在非凸、强凸等不同假设下的算法收敛界。
静态客户端选择和动态客户端选择
Chai Z 等人 [62] 提出了基于层的联邦学习(tier-based federated learning,TiFL)系统,将联邦学习参与方基于训练性能分层,在训练中依照参与者所属的层次进行选择,提高了异质场景下联邦学习的收敛速度。
Wang H 等人 [65] 通过额外训练一个深度强化学习模型在每一轮评估客户端的价值,选择当前价值最高的 K 个参与方进行联邦学习训练,但这种方法需要在联邦模型的基础上进行额外的深度模型训练,对计算资源提出了更高的要求。
模型
其中多层感知机(multi-layer perceptron,MLP)模型、卷积神经网络(convolutional neural network,CNN)模型、循环神经网络(recurrent neural network,RNN)模型是 3 个具有代表性的神经网络模型,而且已经在图像识别、自然语言处理 [79-80] 等许多领域都实现了落地应用。
神经网络
为了高效地构建联邦场景中的 CNN 模型,Wang H Y等人 [76] 对上述仅支持 MLP 模型的 PFNM 算法进一步拓展,提出了联邦学习匹配平均(federated learning with matched averaging,FedMA)算法。FedMA 算法基于神经元排列的不变性,通过匹配和平均具有相似的特征提取签名的隐藏元素(即 CNN中的通道),逐层构建全局模型。
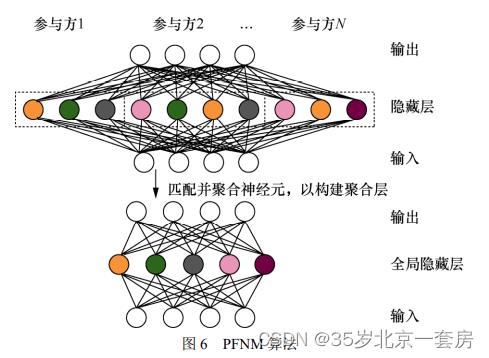
实验表明,除了在性能上领先通用型的 FedAvg 与 FedProx 等流行联邦学习框架,FedMA 同样能够有效降低联邦学习中的总体通信负担。解决大型联邦 CNN 模型在边缘设备上的计算资源不足问题,He C Y 等人 [77] 提出了基于组知识迁移训练的联邦组知识迁移(federated group knowledge transfer,FedGKT)算法。FedGKT 算法实现了一种交替最小化方法的变体,能够用于在边缘节点上训练小型 CNN,并通过知识蒸馏周期性将知识转移到中心服务器端的大型 CNN 上。
开源平台(FATE[86]、TFF(TensorFlow federated)[87]、PySyft [88]、FedML [89]、Flower [90])
开源平台的目的是为多设备部署或实验提供通信接口和隐私保护机制,这能够极大地简化联邦学习算法的编写及部署难度。大部分联邦学习平台通常不包含计算平台,而是以TensorFlow 或 PyTorch 等机器学习框架为底层计算平台,在其上实现了联邦学习接口,即将用户编写的联邦模型转换为相应的模型进行训练与推断。

(1)FATE 开源平台
FATE [86] 是由深圳前海微众银行股份有限公司开发的首个联邦学习工业级开源平台。FATE 底层由三部分组成,分别是计算、联邦、存储,其中计算模块同时适配了 TensorFlow 及 PyTorch。在底层之上,FATE 使用安全多方计算和同态加密技术构建了安全协议,支持不同种类机器学习算法的安全计算。FATE还提供了联邦学习高级 API,支持线性模型、决策树、深度学习和迁移学习等多种机器学习方法。除此之
外,FATE 还支持图形交互界面,用于联邦学习可视化、客户端集群管理与监控以及任务调度与管理。
(2)TFF 开源平台
TFF [87] 是谷歌公司开发的分布式机器学习与计算平台。以 TensorFlow 为底层计算平台,简化了开发者调用已有算法和设计新的联邦学习算法的开发难度。与 FedML 类似,TFF 将 API 分为低层 API与高层 API,具有良好的可扩展性,低层 API 提供了丰富的接口,允许研究者设计不同的联邦学习算法;高层 API 为调用库中包含的算法进行训练提供支持。同时 TFF 也支持使用 TensorFlow Privacy 中的组件对联邦学习算法进行隐私保护。
(3)PySyft 开源平台
PySyft [88] 是由 OpenMined 组织开发的联邦学习开源平台。该开源平台实现了隐私保护与模型训练解耦,重写了 PyTorch 中张量的运算符,分布于多台设备上的数据可以通过安全求和函数轻松计算,中心化的机器学习代码也可以轻松迁移为联邦学习,而无须考虑客户端中的通信过程。该平台支持多种隐私保护方法,包括差分隐私以及安全多方计算,以保护联邦学习客户端的数据安全。
(4)FedML 开源平台
FedML 是 He C Y 等人[89]开发的联邦学习平台和基准测试库,该平台以 PyTorch 为底层计算平台,提供了灵活并且通用的接口,支持调用库中实现的基准算法(包括 FedAvg、FedProx 等),降低了研究者进行联邦学习算法实验的难度,具有较好的可扩展性。同时,该平台为非独立同分布场景提供了全面的联邦数据集,用于算法的公平比较。FedML平台同时支持单机模拟、移动设备部署与物联网设备部署 3 种计算范式。但是 FedML 中的大部分算法尚未提供与隐私保护相关的组件,开发者需要自己实现同态加密、差分隐私等方法以保护联邦学习中的数据隐私。
(5)Flower 开源平台
Flower [90] 是一个可拓展性高的联邦学习平台,同时支持本地模拟与多设备部署。联邦学习系统间通常具有较大的差异,Flower 允许根据不同的使用场景进行一系列自定义设置,以满足使用需求。该平台可以适配任何机器学习框架,不同机器学习框架具有不同的优点,开发者可根据需求自由选择,只需要实现机器学习模型参数到 Python 的数值计算库 NumPy 的转换即可适配。同时,该平台包含了部分基准测试算法,包括联邦批次正则化(federated batch normalization,FedBN)、联邦优化(federated optimization,FedOpt)等。在隐私保护方面,该平台支持使用 Pytorch 的 Opacus 库对模型进行差分隐私保护。
隐私


应用
(1)智慧交通领域应用
智慧交通系统多采用中心化系统架构,其“中心−终端”模式无可避免地带来了隐私保护问题。在交通规划方面,Liu Y 等人 [91] 提出了一种基于联合声明协议的联邦聚合算法,避免了交换原始数据,在保护车辆隐私的前提下实现了交通流量预测。Shi D Y 等人 [94] 提出了一种基于联邦计算价值函数的交通资源调度方法,该方法显著提升了出行效率和群体公平性。
(2)智慧金融领域应用
Hardy S 等人 [67] 设计了一个端到端的安全联邦逻辑回归(secure federated logistics regression,SFLR)方案,联合两个参与方对同一批样本的不同特征进行建模,并应用加法同态加密来保护模型的安全和数据的隐私。Zheng W B 等人 [95] 提出了结合度量学习的联邦学习方法来解决信用卡欺诈中的隐私保护问题,并被有效应用到金融欺诈检测中。
(3)智慧医疗领域应用
联邦学习技术被应用于智慧医疗领域,解决了电子健康记录管理、远程健康监测、医疗影像分析以及新冠肺炎防治等方面的隐私保护问题,推动了大数据驱动的智慧医疗发展。Hao M 等人 [96] 介绍了一种联合多家医院通过云计算的方式共享电子健康记录数据的联邦模型。Brisimi T S 等人 [97] 提出了一种结合联邦学习和心脏病人过往电子健康记录,预测病人未来因心脏病就医的地点,以实现稀缺医疗资源管理优化的方法。在医疗影像分析方面,联邦学习被用于解决数据异质性问题和实现隐私保护。近两年,新冠肺炎在全球范围内快速传播,面对此类突发疾病,联邦学习在快速获得大量训练数据、快速更新模型方面具有较大优势。Zhang W S 等人 [98] 提出了一种动态的联邦学习方法,用于 CT(computed tomography)影像分析和新冠肺炎核酸检测。
以上是关于联邦学习+区块链FLchain: Federated Learning via MEC-enabled Blockchain Network的主要内容,如果未能解决你的问题,请参考以下文章
014 A Peer-to-Peer Payment System for Federated Learning(FedCoin:联邦学习点对点支付系统 区块链 Shapley Value)