Federated Learning: 问题与优化算法
Posted 张雨石
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Federated Learning: 问题与优化算法相关的知识,希望对你有一定的参考价值。
工作原因,听到和使用Federated Learning框架很多,但是对框架内的算法和架构了解不够细致,特读论文以记之。
这个系列计划要写的文章包括:
Overall
Federated Learning, 中文翻译是联合学习,或者很多人翻译成联邦学习,是一种在移动端训练模型的框架。
不知为何,翻译成联邦学习总让我有点笑场,就像one-hot编码被翻译成独热编码一样。难不成以后还有帝国学习,共和国学习? 下面只说联合学习。
正常的机器学习/深度学习模型都是在服务器端直接访问数据进行训练,但在实际的场景中,有很多情况下数据是不在服务器端的:
- 隐私内容: 比如商业数据,比如用户在输入法中直接输入的数据。
- 数据量大: 不太适合把所有数据都log到服务器上。
联合学习就是为了应对这种场景而生的。
联合学习
联合学习把数据和算法解耦合。在模型的训练中,首先把服务器把模型当前状态发送给移动端,移动端利用当前的模型状态和本地数据去进行计算,然后把梯度传送给服务器端,服务器端再去汇合不同设备上传回的梯度去进行模型的更新。
这样的训练看着很直观,但是相对于数据直接在服务器端来说,有如下问题:
- 数据并非独立同分布的。如果数据在服务器端,那么可以通过shuffle来让数据分布均匀,但是每一台device上,数据是有很强的bias的。
- 数据不均衡。有的设备上数据量很大,有的则很少。
- 大规模分布式。参加训练的设备相对于设备上的平均样本数来说要大的多。
- 有限通信。带宽很宝贵,因此训练过程中要尽可能的减少服务器和设备交流的次数。
除了这些之外,还有一些问题不在本文的讨论之中,但确也是非常实际的:
- 客户端数据在随时发生变化。
- device的可达性和数据的分布有一种复杂的相关关系,比如,时区的原因,美式英语的用户和英式英语的用户在不同的时间上线参与训练。
- device不返回梯度或者返回损坏的梯度。
为了解决上述的问题,联合学习采用的是可控环境下的同步式训练:
- 假设一共有K个客户端参与联合学习
- 每次选择C%的在线客户端。
- 做这个选择是为了提高效率和减少错误率。
- 服务器端发送模型当前状态给选中的客户端。
- 客户端进行本地计算,参与训练的数据量为B(local_batch_size),得到梯度。
- 客户端发送梯度更新给服务器。
- 服务器进行聚合和更新全局模型。
聚合梯度的公式如下,即不同client返回的梯度按照client上样本数目进行加权。这里假设数据是独立同分布的,当然,因为这个条件不成立,所以这只是一个近似。

FederatedAveraging算法
而联合学习的训练过程中,通信将会是瓶颈,因为网络传输的带宽比较小,联合学习一般设定最多占有1M/s的带宽。而由于很多device上数据较少或者有高端内核(很多设备都有GPU),所以算力反而不是问题。
而为了减少通信次数,有两种办法:
- 增大并行程度,即增大C,在每一轮训练中增加参与计算的设备。
- 但这就面临设备出错率变高的问题。
- 增大每个设备上单轮的计算,即在每一轮训练中,每台设备上可能要计算多轮累积的梯度。
- 这会遇到梯度更新不精确的问题。
- 但后面会讲到,这个问题在实验中并不存在。
因而,在论文中,比较了两种方法:
- FedSGD: 就是SGD的联合学习版本,每次训练都使用device上的所有数据作为一个batch。进行属于增大并行程度的方法,当C=1的时候,可以认为是Full-Batch训练。
- FederatedAveraging: 基于FedSGD,但是在device上可以训练多步累积梯度,属于增大每个设备上单轮的运算。
- 除了上面提到的K、C、B三个参数外,增加一个参数E,代表在device上每轮训练执行的计算的次数。所以当B=全部,E=1的时候,FederatedAveraging与FedSGD等价。
算法流程如下图所示:

模型混合
经过FederatedAveraging学到的模型,有点类似于模型混合。因为模型在每个device上经过多步训练之后可能会变得很不一样。
而在通用的模型混合问题中,最基本的要求就是模型的初始化要一致。如下图所示,不同方式初始化的模型做平均会得到差的结果(左图),而相同的则是得到好的结果(右图)。
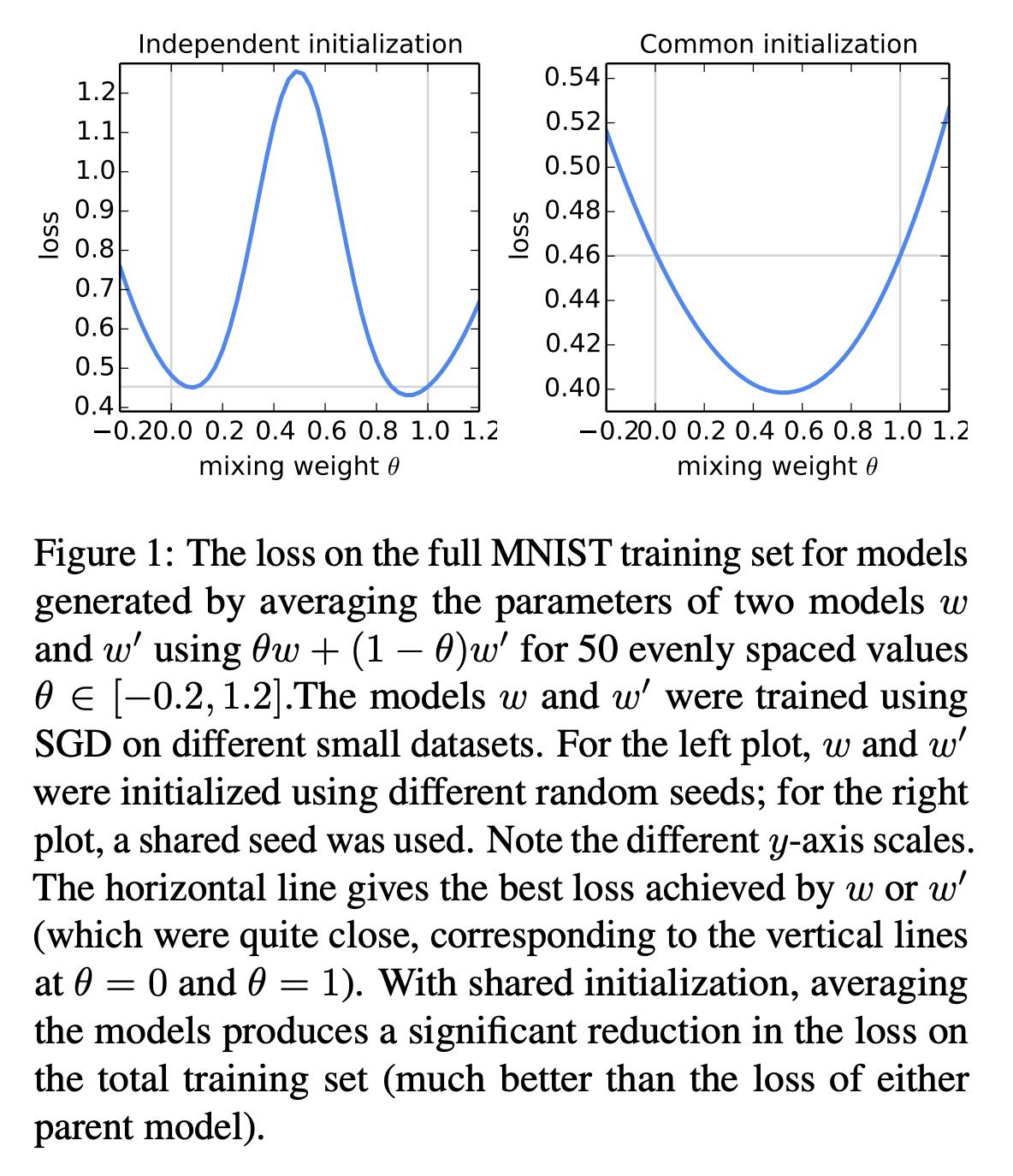 # 实验
# 实验
增大客户端数目
首先使用MNIST做了一个模拟实验,实验分为IID和NON-IID数据集+不同的E/B参数。
MNIST一共十个类别,IID数据集是将数据集混排后随即分到100个客户端上,而NON-IID则是在每个客户端上只有2类的数据集,数据集都是均衡分布在各个客户端上的。
下图中,2NN是2层全连接神经网络,CNN是一个2层的卷积网络,每层卷积之后都有一个pooling,最后是一个512的全连接层。表格中的数字代表的是达到某个准确率需要的通信次数。其中2NN部分是达到97%准确率,CNN部分是达到99%准确率。
调整C,结果从下图可以得到:
- 参与的客户端越多,速度越快。
- B=全部的时候,增多客户端,带来的提升比较小,而在B=10的时候,增多客户端,能带来显著的速度提升。
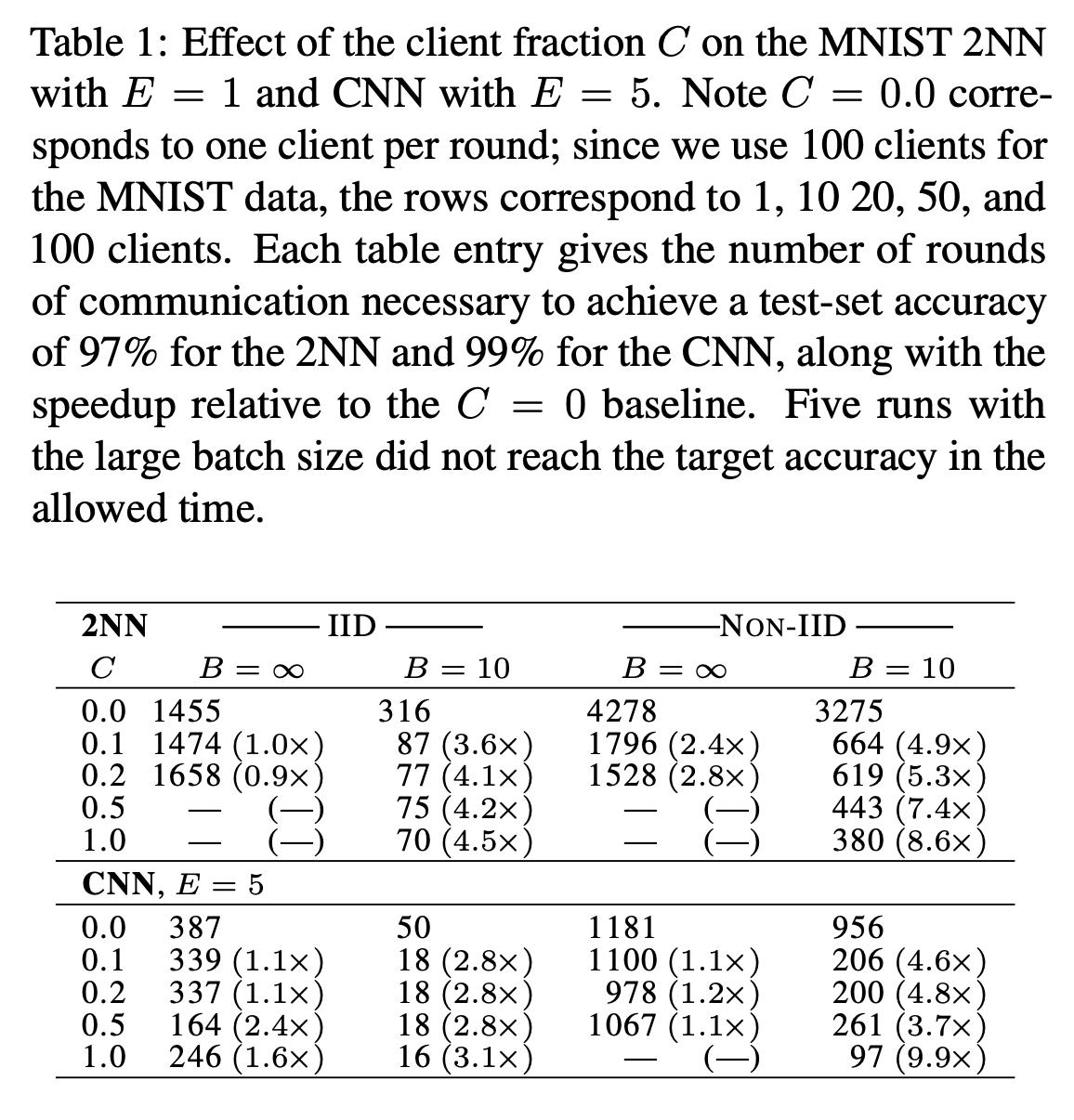
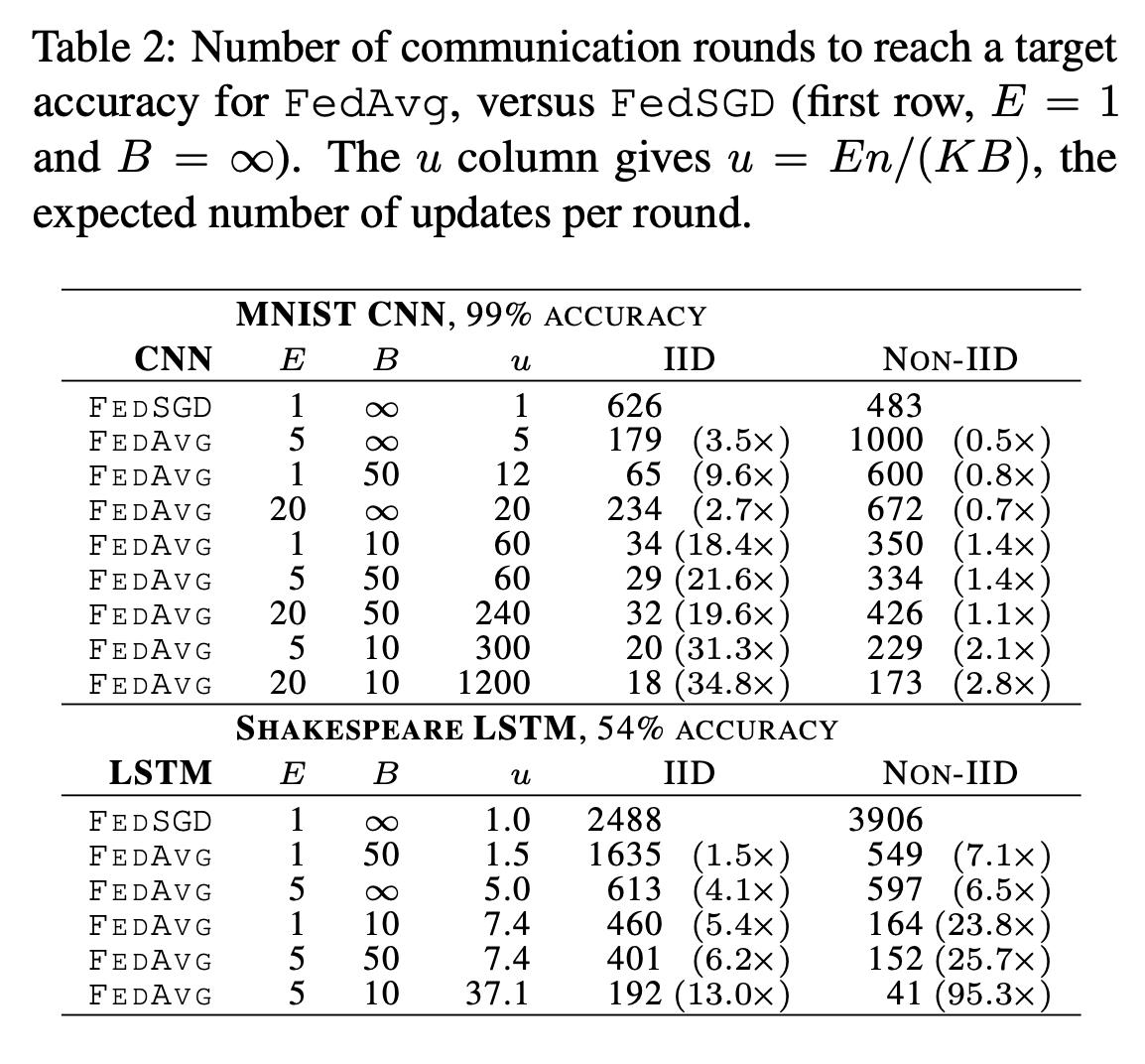
增大客户端上的计算量
保持C=0.1,增大每轮训练在device上的计算梯度的次数,即增大E,得到的实验结果如下。 其中u代表的是每轮实验梯度被计算的次数。可以看到,在IID数据上提速很大,在NON-IID上提速小,但是也能有将近三倍的提升。
同时,还做了一个LSTM语言模型上的实验,这个实验的设置跟MNIST很像,也分为IID和NON-IID,其中NON-IID是按照人物角色来分的。同时,IID是均衡数据集,NON-IID是不均衡数据集。
可以看到,在不均衡的NON-IID数据集上,FEDAVG却能带来95.3倍的提升,反而比IID均衡数据集要快。
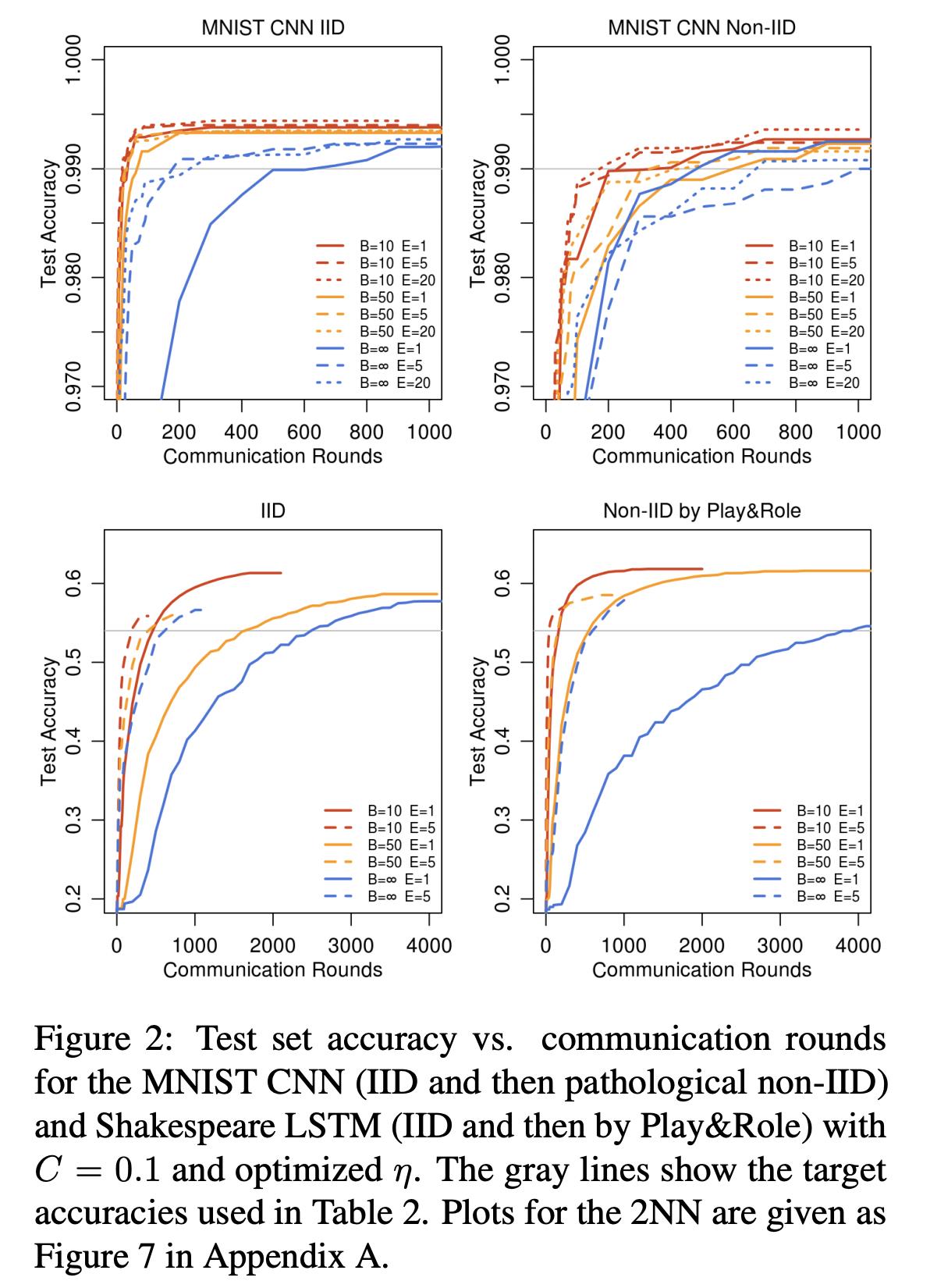
但是需要注意的是,一直增大E,结果反而会适得其反,因为会导致模型在各个客户端上发散。因为会导致模型发散。如下图所示。
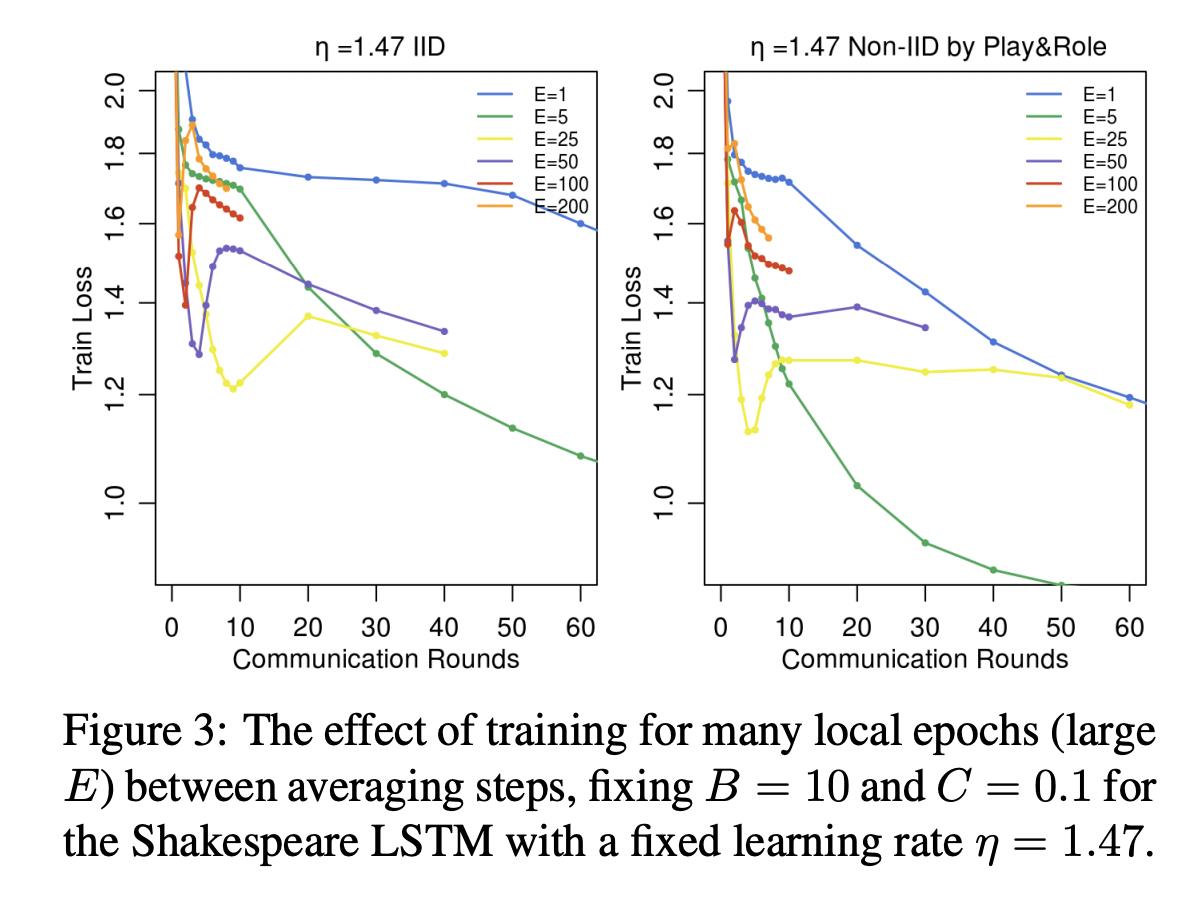
所以对于一些模型,比较好的方法是让E随着训练步数的增加而递减。这样有利于收敛。
Cifar10实验
在Cifar10上也进行了实验,这次是均衡的IID数据,结果如下图,可以看到,相对于普通的SGD,达到相同的准确率,FedSGD和FedAvg都有更少的通信次数。

大规模LSTM Next Word Prediction实验
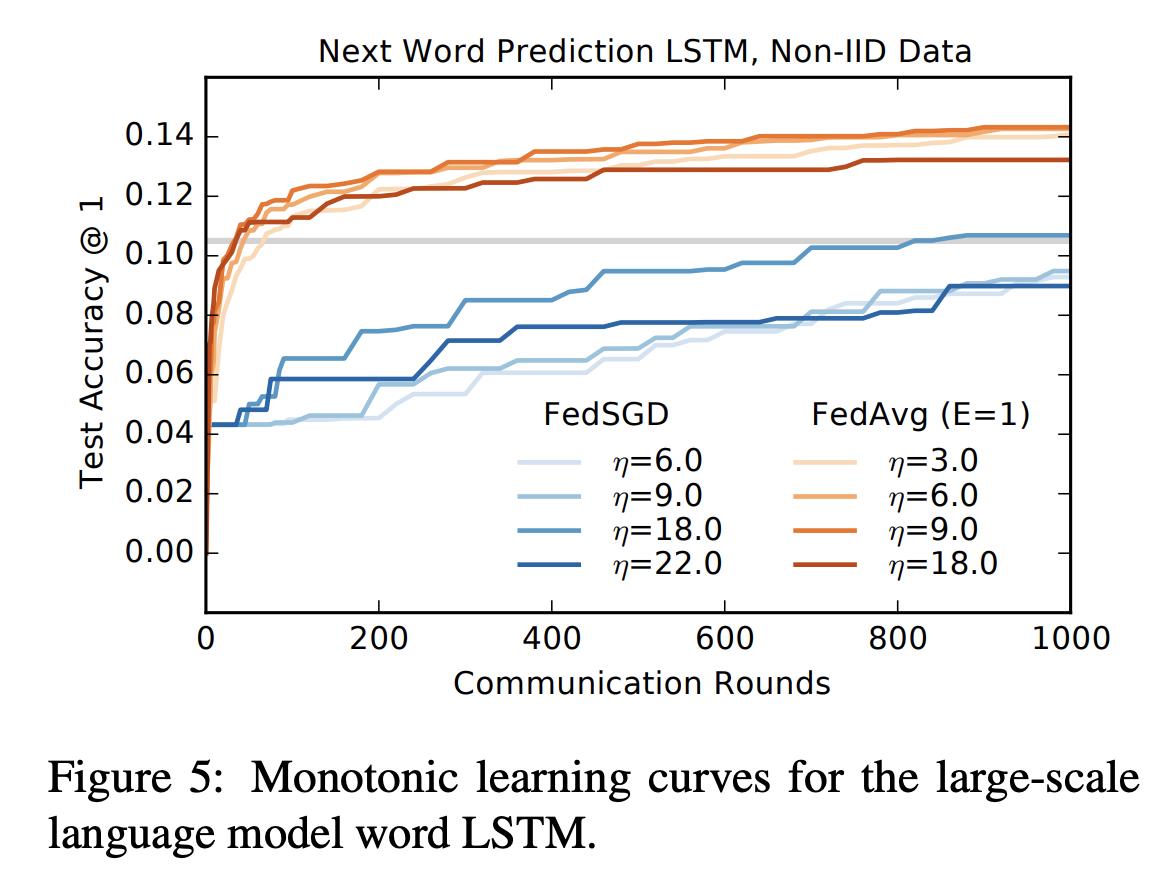
将10M个某社交网站文档分到50k个设备上,同一个作者的会被分到同一个设备上,同时每个设备限制嘴都5000个词语。LSTM词表是10k。LSTM是单层256节点。embedding是192,LSTM输入的序列长度是10。
结果如下图, FedAvg在35轮的时候就能达到SGD在服务器端的效果。同时比FedAvg快23倍。
总结与思考
作为联合学习实用化的开山之作,论文提出的FedAvg优化算法,做了很多的对比实验,实验在不同的数据集上得到的略有不同的结论。但证明了在设备端做mini-batch的是完全可行的,同时,设备端还可以多做几轮计算来积累梯度也有助于减少通信次数。
与其他的算法不同,联合学习考虑的不再是算力问题,而是通信问题,减少通信次数成了最高优先级,这点是个全新的思考方向。
勤思考, 多提问是Engineer的良好品德。
提问:
- 如果设备端只返回梯度,那么有没有可能通过梯度反推数据呢?如何避免这个问题?
- 因为手机端内存有限,所以无法训练大的模型,有没有方法可以绕过这个限制得到大模型?
回答后续公布,欢迎关注公众号【雨石记】.

参考论文
- [1]. McMahan, Brendan, et al. “Communication-efficient learning of deep networks from decentralized data.” Artificial Intelligence and Statistics. 2017.
以上是关于Federated Learning: 问题与优化算法的主要内容,如果未能解决你的问题,请参考以下文章