傻白入门芯片设计,指令集架构微架构处理器内核
Posted 好啊啊啊啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了傻白入门芯片设计,指令集架构微架构处理器内核相关的知识,希望对你有一定的参考价值。
早期计算机出现时,软件的编写都是直接面向硬件系统的,即使是同一计算机公司的不同计算机产品,它们的软件都是不能通用的,这个时代的软件和硬件紧密的耦合在一起,不可分离。
IBM为了让自己的一系列计算机能使用相同的软件,免去重复编写软件的痛苦,在它的System/360计算机中引入了ISA(Instruction SetArchitecture,指令集体系结构)的概念,将编程所需要了解的硬件信息从硬件系统中抽象出来,这样软件人员就可以面向ISA进行编程,开发出的软件不经过修改就可以应用在其他ISA架构的系统上。
ISA用来描述编程时用到的抽象机器,而非这种机器的具体实现。从编程人员的角度来看,ISA包括一套指令集和一些寄存器,程序员知道它们就可以编写程序。在PC领域,Intel和AMD 的处理器都是基于x86指令集,因此我们不用担心换了更高性能的CPU,软件不能用,而手机上的程序不能在电脑上用,这是因为手机上的程序绝大部分是基于ARM指令集的。
- 指令集架构:指令集主要是指CPU硬件和软件之间的接口描述,它本质上是一段二进制机器码,指令集作为CPU和编译器的设计规范和参考标准主要用来定义指令的各种操作、操作数的类型、寄存器的分配、地址的格式等。
- 微架构:指处理器的内部结构和功能,它包括了指令集架构,但还包括了处理器的其他组成部分,如缓存、寄存器和总线等
- 处理器架构:处理器架构(Processor Architecture)是指处理器的总体设计,包括了处理器的功能、特性、指令集架构和微架构等。
- 处理器内核:是在硬件层面按照指令集的设计规范,把它实现出来,可以把内核当作指令集的实物化,但是硬件的设计方案各有不同,所以同一个版本的指令集可能也有不同版本的内核。
目录
一、概述
ISA的出现,是处理器领域的一件大事,处理器的外部呈现和内部实现可以分离开来。处理器被分为3个层次,如下图(左)所示:

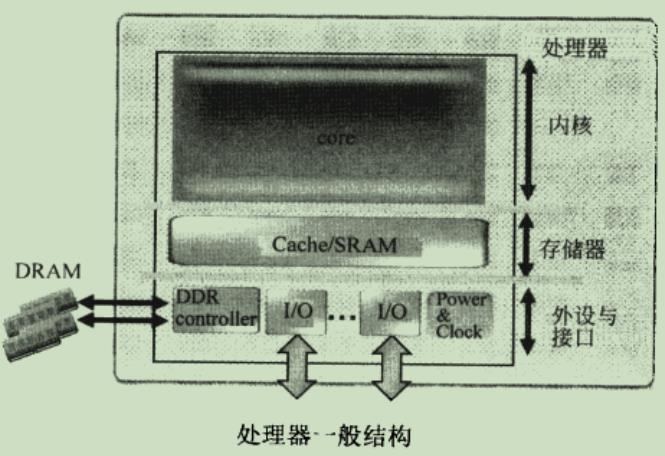
图(右)描述了处理的物理结构,包括3大部分:内核、存储器、外设与接口
SA常被简称为Architecture(架构),是处理器的一个抽象描述,ISA在处理器中的实现,被称为Microarchitecture(微架构),同样是x86的Architecture,Intel和 AMD各自使用不同的 Microarchitecture。Microarchitecture通常也可以认为等同于内核(core),一个处理器除了内核外,也还有很多其他的东西。例如:IO (Input/Output)、电源、时钟等,同样一种微架构可以出多种型号的处理器。
二、指令集架构
(1)指令集
指令集主要是指CPU硬件和软件之间的接口描述,它本质上是一段二进制机器码,CPU只能识别机器码,但是机器码是一串无意义的字符串,程序员很难看看懂这些语句,用它来开发软件,所以后面就发明了汇编语言,汇编语言本质上跟机器码一一对应的,现在有很多不同版本的汇编语言,本质上就是有不同的指令集,指令集可以简单的分为复杂指令集和精简指令集。最近比较火的RISC-V,也是指令集的一种。指令集作为CPU和编译器的设计规范和参考标准主要用来定义指令的各种操作、操作数的类型、寄存器的分配、地址的格式等。指令集也不是—成不变的也会随着应用需求的推动不断迭代更新,不断扩充新的指令。例如ARM指令集从最初的ARMV1发展到目前的ARMV8,一直在不断地发展不断添加新的指令。
(2)架构
架构主要是指某一个处理器所使用的具体指令集,比如说m6ull,他是基于ArmV7架构的,就是指它是使用armV7指令集,在大部分场合,架构等于指令集。
(3)指令集架构
ISA常被简称为Architecture(架构),指令集架构是计算机体系架构的一部分。指令集是一个很虚的东西,是一个标准规范。例如我们的交通规则,红灯停、绿灯行、黄灯亮了等—等,只有行人和司机都去遵守这套交通规则我们的交通系统才能有条不紊地运行下去。指令集也一样,芯片工程师在设计CPU时也要以指令集中规定的指令格式为标准实现不同的译码电路来支持指令集各种指令的运行。指令集最终的实现就是微架构,就是CPU内部的各种译码和执行电路。
编译器厂商在研发编译器工具或IDE时,也要以指令集为标准将我们编写的C语言高级程序转换为指令集中规定的各种机器指令。为什么我们编写的高级程序经过编译后可以直接在CPU上运行呢?就是因为CPU设计者和编译器开发者遵循的是同一个指令集标准,“编译器最终编译生成的指令”都是CPU硬件电路支持运行的指令,每一种不同架构的CPU一般都需要配套一个对应的编译器。
三、微架构
微架构(Microarchitecture)是指处理器的内部结构和功能,它包括了指令集架构,但还包括了处理器的其他组成部分,如缓存、寄存器和总线等。因此,微架构比指令集架构更加全面。可以把微架构看作是一个处理器的“骨架”,它定义了处理器的逻辑构造和功能,而指令集架构则是微架构的一部分,它规定了处理器能够执行的指令集。微架构定义了处理器的逻辑构造和功能,以及如何通过硬件电路实现这些功能。因此,一个相同的指令集可以由不同形式的电路实现,从而形成不同的微架构(集成电路工程师在设计处理器时,会按照指令集规定的指令,设计具体的译码和运算电路来支持这些指令的运行)。不同的微架构可能具有不同的性能和特性,并且可能适用于不同的应用场景。例如,对于同一个指令集,一个微架构可能更适用于高性能的计算,而另一个微架构则更适用于低功耗的设备。
在设计一个微架构时,一般需要考虑很多问题:处理器是否支持分支预测,单发射还是多发射,顺序执行还是乱序执行?流水线需要多少级?主频需要多高?Cache需要多大?需要几级Cache?根据不同的配置选项,我们可以基于一套指令集设计出不同的微架构。以ARMV7指令集为例,基于该套指令集,面向高性能、低功耗等不同的币场定位,ARM公司设计出了CoItex-A7、Cortex-A8、CortexA9、Co1texˉA15、CortexˉAl7等不同的微架构。
四、处理器架构
处理器架构(Processor Architecture)是指处理器的总体设计,包括了处理器的功能、特性、指令集架构和微架构等。它定义了处理器的整体特性和功能,以及处理器的各个部分如何协同工作以实现这些功能。
处理器架构是处理器设计的基础,它为软件开发人员提供了一个统一的接口,使得他们可以为处理器开发应用程序。处理器架构还为硬件开发人员提供了一个参考模型,帮助他们设计出符合架构要求的处理器。处理器架构的设计决定了处理器的性能、能效比和可扩展性等方面的重要特性。
五、处理器内核
在不同领域里表达的是不同的东西,是指一个东西的核心部分,具体是什么,要看你指的是什么东西。
- 在操作系统领域,内核指的是操作系统的核心部分。通常包括中断处理、任务管理、调度等功能,同时又有微内核、宏内核、混合内核等分类。
- 在浏览器领域,内核一般是指浏览器的渲染引擎,也是浏览器的核心部分,比如是webkit还是IE等等。你说的UC内核,指的是浏览器领域的内核概念。
- CPU领域,处理器内核:是芯片内部的核心单元模块,是在硬件层面按照指令集的设计规范,把它实现出来,可以把内核当作指令集的实物化,但是硬件的设计方案各有不同,所以同一个版本的指令集可能也有不同版本的内核,我们经常说的cotex-m3,cotex-m4,cotex-A7等等就是属于内核层面的概念。早期CPU只有一个核,但是随着技术的发展现在也出现了包含多个核的CPU。
内核是一种软件,它实现了指令集中定义的指令的功能。当内核运行在计算机的处理器上时,它会被转换成二进制代码,并且被处理器读取并执行。这时,内核就会“实物化”为计算机的硬件。但是,内核本身仍然是一种软件,它的实现方式与硬件无关。内核的功能可以通过不同的硬件设计方案来实现,从而形成不同的微架构。但无论采用哪种微架构,内核本身仍然是一种软件,并不是硬件。
现在举个简单的例子,ARM公司就是一个设计指令集架构的公司,一些芯片生产公司购买ARM公司的授权来生产芯片就相当于是在生产微架构。做嵌入式工作的都知道,经常在芯片的datasheet里面看到说该芯片是基于ARM某某内核,这里的内核指的是指令集架构。
注意:datasheet是指数据手册,电子元器件或者芯片的数据手册,一般由厂家编写,格式一般为PDF,内容为电子元件或者芯片的各项参数,电性参数,物理参数,甚至制造材料,使用建议等,内容形式一般为说明文字,各种特性曲线,图表,数据表等。
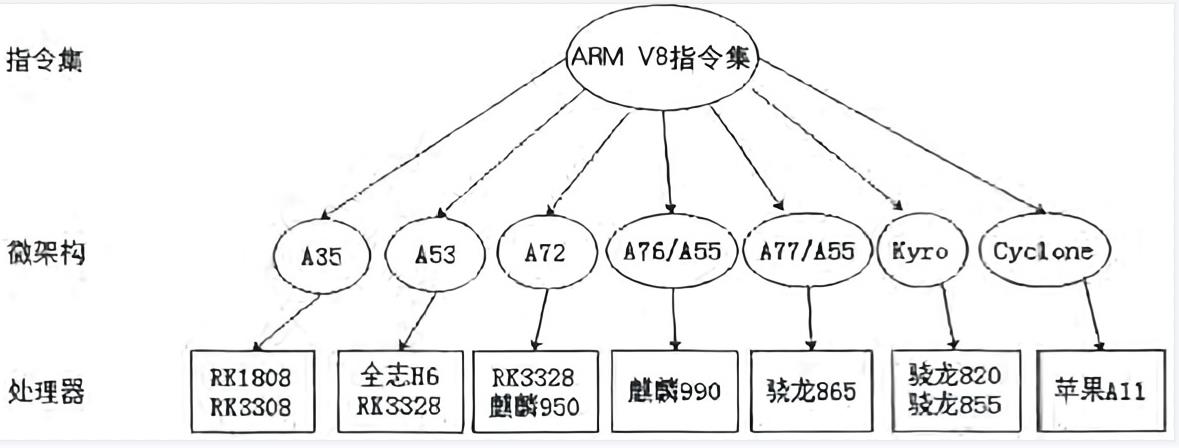
以ARMV8指令集生态为例,说明指令集、微架构、处理器之间的关系,如下图:
六、总结
通俗的说,Architecture是处理器的外表,Microarchitecture是处理器的内心。Architecture是设计规范,定义处理器能做什么,Microarchitecture是设计实现,描述处理器是怎么实现功能的,物理实现是具体的实现过程,可以用20nm的集成电路工艺实现处理器,也可以用40nm的工艺实现,可以用电子实现(电子计算机),也可以用量子实现(量子计算机)。
如果用软件开发的流程来和处理器进行对比,那么Architecture就好比需求,Microarchitecture好比设计,物理实现好比真正的代码。
参考资料:
书籍《大话处理器》
(9条消息) 通俗来理解 ARM芯片内核,架构,指令集,软核和硬核之间的关系_howards~~~的博客-CSDN博客_芯片内核是什么意思
(10条消息) 指令集架构、微架构、处理器架构、CPU架构、内核_qqssss121dfd的博客-CSDN博客
芯片设计“花招”已耍完?无指令集架构颠覆旧套路

日前,英伟达在GTC大会上发布了最新一代GPU H100,采用台积电4nm工艺,集成了800亿个晶体管。3月初,苹果发布了M1 Ultra芯片,更是集成了高达1140亿个晶体管。显然,头部厂商都在推进现有芯片设计和制造技术的极限,但问题是,当这些“花招”用完后怎么办?
在面向AI负载的新锐芯片创业企业里,SambaNova和Tenstorrent都足够引人注目,他们都可以视作为数据流架构专门设计的软硬件系统。据公开资料,他们都十分强调编译器软件的重要性,虽然硬件是重配置的,但重配置方案却是编译器完成的,其中最核心的问题是解决placement和routing问题,看上去他们都解决得不错。
其实,在这两家企业之前已经有“先烈”公司Wave Computing走过这条路,但不幸没有走通。其实所有这些努力背后可以追溯到VLIW。Wave Computing破产之后,CEO Peter Foley东山再起,在Ascenium公司继续向VLIW架构冲锋,看上去他信心满满,的确该到通关的境地了。
作者|Timothy Prickett Morgan
翻译|刘晓祯、张雨珊、胡燕君、徐晨阳、沈佳丽、周亚坤
在任何架构中总有一些必不可少的、基础性的且毋庸置疑的功能。直到某个聪明的架构设计师出现,才告诉我们情况并非如此。建筑物和桥梁是这样,系统及其处理器同样也是如此。这就是为什么我们用同一个词“架构设计师”来描述设计宏观和微观结构的人。
Ascenium公司的联合创始人兼CEO Peter Foley就是这样一位架构师,该公司刚刚在2021年A轮融资中筹集到1600万美元。Foley和他带领的Ascenium团队想摒弃现代CPU中的很多架构,从头开始开发Foley所谓的由软件定义的、可连续重配置的处理器。Foley说,之所以有必要拆解处理器,再以一种全然不同的新方式构建它,是因为当前CPU的架构技巧已经用完了。
先介绍下Foley,再谈Ascenium公司正在开发的Aptos处理器架构,以及它将如何撼动CPU市场。
Foley涉猎广泛、见识极深,这使他走到了今天这一步。他先在莱斯大学获得了电子工程学士学位,之后在加州大学伯克利分校获得硕士学位。在伯克利时,Foley与David Patterson(Google Brain团队成员)和Alvin Despain(美国电气工程师,曾任Acorn Technologies联合创始人兼CTO)一起用Smalltalk语言做RISC(SOAR)芯片项目。
毕业后,Foley加入苹果公司开始研发Mac和Mac II电脑中的各种芯片,1987年,他成为研发“牛顿个人数字助理机(PDA)”的四个原始成员之一。PDA是iPad平板电脑的前身,但当时还没人知道。值得一提的是,Foley负责开发用于PAD的“Hobbit”处理器。离开苹果后,他加入了第三方GPU供应商SuperMac,之后在Chromatic Research公司开发可编程的VLIW和SIMD媒体处理加速器。
Foley在风投公司Benchmark Capital做了一段时间的入驻企业家,然后创立了nBand Communications,并创造了软件定义的宽带无线广播(类似于WiMAX,而不是5G,说实话,在多数地方这更像是4.1G)。
然后,他在Predicant Biosciences公司做了近四年的工程副总裁,该公司开发了用于扫描血液蛋白中是否有癌症的诊断设备。之后,他在风投公司Tallwood做了近四年的驻校执行官。
经历这一切之后,特别是在2009年12月,Foley意识到加速计算前景黯淡,就成立了人工智能芯片创业公司Wave Computing并担任CEO。值得注意的是,Foley离开了Wave Computing,数年间,这家公司通过复杂的交易把技术授权给中国企业,还收购了MIPS芯片公司。而MIPS芯片公司自从硅图公司(SGI, Silicon Graphics)十几年前将其分离出来之后,就在不停被转手。最后,Wave Computing在2020年4月不得不申请破产重组。
准确来说,Foley是在2016年6月离开的Wave Computing,并开始经营自己的咨询业务,直到2019年6月,他以CEO的身份加入于2018年3月成立的Ascenium公司。
Ascenium公司获得了900万美元的天使轮融资和1600万美元的A轮融资。投资方Stavanger Ventures AS是一家风投公司,由挪威企业家Espen Fjogstad运营,他创立的公司曾被eBay和谷歌收购,还有多家公司在奥斯陆证券交易所上市;其中有几家公司是做储层建模(reservoir modeling)的,期间在北海石油热潮中派上了用场。自20世纪70年代末起,北海石油热潮为英国和挪威的经济注入了新的活力(油价在升高,技术也在发展,而海上钻探石油是经济型的)。
据了解,Ascenium最早成立于2005年之前,当时它的创始人兼CTO Robert Mykland在Hot Chips会议上做了一个演讲
(https://llvm.org/ProjectsWithLLVM/Ascenium.pdf)。该公司已获得九项专利,在诉讼频发的半导体领域,这些专利很有用。Ascenium目前的实体公司成立于2019年6月,致力于充分利用和发展Foley、Oyvind Harboe和Tore Bastiansen的研究成果。
“牛顿个人数字助理机(PDA)”当时领先于时代,依据摩尔定律,在芯片和网络的发展迎头赶上后,我们才真正有了PDA。类似地,也许我们必须等到摩尔定律终结后,才能去思考Robert Mykland(Ascenium的CTO)早在16年前就提倡的观点。
在了解背景信息后,我们与Foley聊了Ascenium正在研发的处理器,它并没有如我们熟知的那样有一个指令集,而是试图通过Aptos处理器重新定义软件编译器和底层硬件之间的接口。Aptos处理器是一个由64位计算单元组成的可编程阵列。下面是一个大概的结构图,有点模糊,因为Ascenium目前还比较神秘。

以下是与Foley的对话。
1
摒弃旧传统的“无指令集架构”
Timothy Prickett Morgan:我好像看到的是一个没有指令集架构的处理器。我看了两遍,然后摇摇头说,这是个什么东西?它成功地引起了我的注意。
Peter Foley:我之前在Tallwood时,老板Dado Banatao说过,如今市场巨大、尚未复苏,对于创新来讲,时机已经成熟。我们的使命就是,带着完全不同的新事物进入这个巨大的市场。
我们认为它必须是完全不同的架构,如果你一直在同一个沙盒里遵守同一套规则——就是说指令集架构,你得有串行指令流进入带有深层管道的乱序发射处理器(out-of-order issue machine)——我就不细说了,如果你遵守这些规则,就赢不了。看看那些ARM牺牲品:Calxeda,Cavium,Broadcom等等。
TPM:确实有很多牺牲品,价值几十亿美元的牺牲品。
Peter Foley:高通公司已经尝试过两次,他们仍在努力。在单核、单线程的SPECint上击败Intel很困难,这才是人们真正关心的问题。
TPM:AMD正在做这件事。
Peter Foley:是的,但AMD仍然用的是X86架构,而且他们有许可证。AMD现在可以说是在某种程度上打败了Intel,但这很大程度上与Intel在晶圆厂选择的失误有关,而AMD使用的是台积电(TSMC),因此他们在一段时间内有节点优势。
TPM:我最近写了一篇文章,还没发表,我说AMD史上最好的消息就是GlobalFoundries(半导体晶圆代工厂商)搞砸了14纳米技术,但IBM把自己的微电子部门卖给了GlobalFoundries,这起到了作用,然后10纳米确实搞砸了。因为在那之后,AMD不得不采用台积电的7纳米制程,同时Intel在10纳米上遇到了大问题。AMD总能设计出优质的芯片,但Intel的晶圆代工问题影响太大了。
Peter Foley:你说得对。架构微调,再投入几十亿个晶体管,这些都是次要的。然而,摩尔定律和Dennard缩放比例定律并不匹配,因为这些架构非常复杂,必须投入几十亿个晶体管,才能提高5%、10%、20%的性能。问题是这样一来温度就太高了,你要么调小时钟,要么关掉部分模具——然后就有了暗硅问题。
TPM:我一直在说把时钟调小,让内存和CPU回到接近相位的状态,因为你在大部分时间都只是在旋转时钟来等待。所以还不如慢一点,不要等待。为了在GPU上运行,我们必须并行化代码,所以要让CPU看起来像GPU,并通过这种方式提高其处理能力。
Peter Foley:英伟达的Ampere GPU也有这个问题。它们发热比较厉害,即使时钟较慢,也有400瓦,这意味着Ampere不能在PCI板上使用,而要重新设计,使其适合300瓦的PCI-Express。
TPM:所以,我认为这为Ascenium试图做的事情奠定了基础。
Peter Foley:我们正在做的事情将是非常不同的。这个想法是让我们重新定义编译器和硬件之间的划分(partitioning),它建立在50年前使用ISA的IBM大型机以及后来的RISC机器上。
当时,你有一个三阶段或五阶段的流水线,编译器能处理的东西比较有限,因为你没有太多的马力。但这在当时似乎是一个很好的分工了。问题是,这种API划分已经变得非常陈旧,50年后的今天,随着计算能力的提高,以及我提到的Dennard缩放比例定律和将晶体管放在一个乱序架构中的问题,这种划分已经不能真正发挥作用。
现在是重新思考的时候了,我们应该摒弃与旧ISA相关的所有内容:深层流水线、乱序、重新排序、重命名、转发、运行时分支预测,把这些东西通通丢掉。
TPM:那还剩下什么呢?你刚刚说要丢掉的东西,基本上就是我所理解的一切了。
Peter Foley:我们现在有一些关键的推动因素了,一个是现在有大量的马力用于编译器。所以你可以让更复杂的编译器做更多的工作,因为有足够的马力来做。
另一个驱动因素是,如果你打算使用一种基于阵列的方法,直接由编译器进行极细粒度的控制的话,这就有点像你把一个容量庞大的微码放到基于阵列的机器里,那么你使用的编译器通常是一维的。会生成一串指令流,然后你会把指令发给硬件,硬件必须提取所有的并行,完成所有事。与此相反,我们说要让编译器完成大量的工作,深入地了解整个程序,并且进行更加复杂的优化。现在的编译器是5D编译器,它需要做2D布局、2D布线以及调度,所以还有更多工作要做。
因为我们瞄准的市场是数据中心,所以可以一直重新编译。我们可以花15分钟到半个小时进行编译,然后在数据中心运行1000万次,并收获能耗回报。从对能耗的全面关注来看,这种计算方式也发生了变化。
因此,值得一试的是能否花更多时间在一个非常复杂的2D计算阵列上,这个阵列由一个有巨大容量微码的编译器直接控制。如果能节省5%或10%的功耗,这就是值得的。如果你能做到的话,超大规模企业将竭力邀请你接入他们的数据中心。
说到Ascenium的Aptos处理器和我们的办法,其实还有一个关键的驱动因素。我一直都在深究这个问题,这也是我为这家公司所做的一点贡献。我意识到了这一点,并且认为这的确会对Ascenium当前的工作产生一定的影响。
一家名为Tabula的公司也遇到了类似的问题。他们在软件工作时遇到了真正的难题,结果还是在他们做第二次还是第三次尝试时引入了约束求解器,这才解决。Tabula使用基于SAT求解器的方法来编译后端。我们在Wave Computing时也采取了同样的办法,后来我又把这项技术带到了Ascenium。
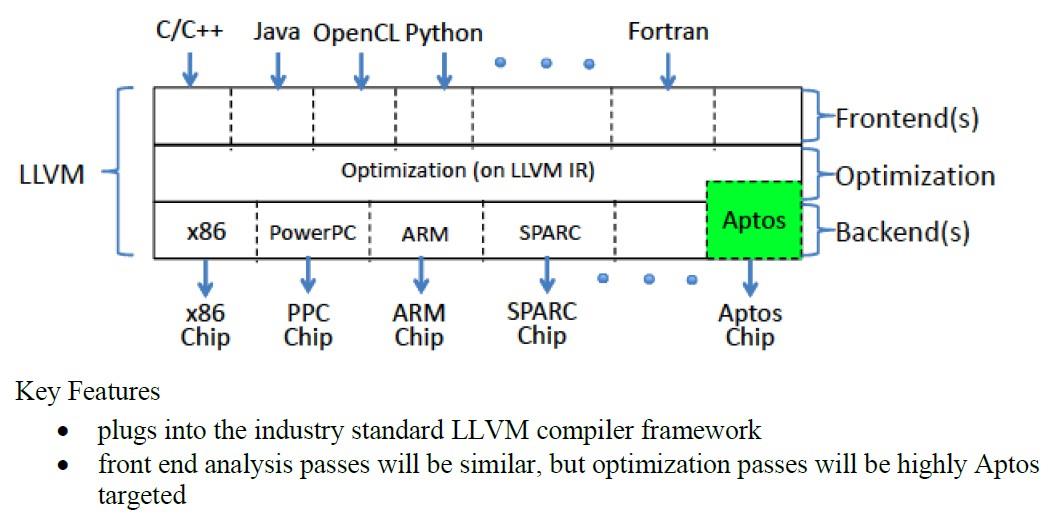
我们有一个标准的LLVM编译器基础设施,外加一个新的LLVM后端,主要面向适合约束求解器的硬件。它就像一个黑匣子,如果你有一个非常简单的规则架构,都可以在一组逻辑方程中完整地描述行为,无论是在时间还是物理上,那么我们的SAT求解器可以分析、解读它,并给出数学上的最佳证明结果。
这是很难被超越的。永远不能在一个复杂、异构、无序的体系结构上使用约束求解器。算了吧,那是在浪费时间。但在我们的场景,这是可行的。
当讨论整个程序时,SAT求解器方法的数学最佳证明结果是言过其实的。从数学上,它对于代码块来说是最佳的。但对于整个程序来说,计算起来却有些棘手。
这些代码块就不得不拼接在一起。所以SAT求解器窗口贯穿整个代码,将编译后的窗口拼接在一起(这会降低效率)。因此,公司的诀窍之一就是知道如何最优地分割、编译和拼接SAT编译过的程序块。
我们的想法是使芯片的架构尽可能简单,这样把它安装到SAT求解器上后就会得到令人惊讶的、最佳的5D解决方案。这就是一场赌注:除了要跳出X86和ARM沙盒,还得有一个IP清除方法,这很重要。这又是另一个问题了:如果你试图和这些CPU架构展开角逐的话,就会撞上巨大的IP墙。一旦你开始对他们构成威胁,他们就会马上起诉你。这就是生意,对吧?
2
通过架构简化释放性能
TPM:所以这是一种做到极致的RISC吗?
Peter Foley:没错。而且我就是做这个出身的。很久之前,我在伯克利的时候,在一个芯片研究团队跟David Patterson一起研究Smalltalk语言。我的整个职业生涯几乎都在研究处理器,而且绝大部分都是RISC处理器。
TPM:我觉得这可以称得上是NISC(无指令集计算)了,因为是把RISC(精简指令集计算)做到了极致,对吧。
Peter Foley:哈哈,没错!但说实话,约束求解器现在是个热门话题,可以说席卷了整个EDA(电子设计自动化)行业。本质上,我们现在做的事情其实更属于EDA问题,而不是传统的编译问题。有点像把一个完整的Xilinx或Altera FPGA后端结合到编译器里,因为它们的很多功能和FPGA查找表结构中的放置、布线、调度是差不多的。我们做的事情和这个很像,只是我们把目标放在通用计算引擎。约束求解器现在正在很多其他地方运用,但把它用在通用计算上,是我们的创举。目前我们正在努力申请知识产权和专利等,希望取得先发优势。
TPM:所以这有点像是FPGA数据流引擎和CPU之间的东西,能不能这么理解?
Peter Foley:可以这样说。不过我们这个是通用处理器,并不像FPGA那样用查找表结构来模拟硬件的。
还有一点挺有意思的,在X86指令流里,至少50%的指令都是和数据搬运相关的移动指令,而实际运算的指令,比如加减乘之类的,大概只占20%。但在我们的处理器中,编译器可以用同一套控制字密切控制一切,也就是说,数据搬运、运算、设置文本流方向、布线等等,都可以由编译器通过阵列中的同一控制字同时控制。所以,我们的产品中不存在序列化,当指令汇入只执行搬运的架构时也不会出现阿姆达尔定律带来的缺点,因为一切都由编译器完成了。
编译器需要同时跟踪很多东西。但在典型的乱序机器中,有大批量的重命名正在执行,这是非常复杂的,需要阵列中有充足的资源来高效执行这种超大容量的分布式重命名。因此我们采用了分布式内存,并通过大量复用来减少进入典型寄存器堆(Register File)的流量,这样一来就可以实现简化。可以说,我们基本上没有处理流程,所以分支阴影(branch shadow)特别短。这就是我们的独特之处。
TPM:所以可以说,惠普和英特尔联合开发了EPIC(显式并行指令计算),然后嫁接到一个类似X86,但又不如它的东西上,就做出了Itanium(安腾)。而现在你们摒弃了惠普和英特尔的成果,只保留了EPIC的部分……
Peter Foley:我猜你下一句可能会问,这是真的吗?
TPM:也不全是。你要理解一下我们,所有的AI初创公司来到我们这儿,我和Nicole(TPM的搭档)都会开他们的玩笑,这些公司的硬件都做得不错,然后侃侃而谈他们开发出来的编译器有多么厉害。他们总是先铺垫介绍一番,然后说“我们的编译器可以把这些问题统统解决”。但你所说的编译器是我目前听过最神奇的。所以,如果我持怀疑态度的话,那可能是因为我也许还不太了解……
Peter Foley:我们的投资者之所以愿意投资A轮,帮助公司进一步发展,其中一个原因是我们已经证明了自己能够在5到10分钟内编译出70万行代码,并在FPGA原型上成功运行。这正是我们这个架构让人眼前一亮的地方:它非常简单,以至于你可以在FPGA上制作原型。
TPM:更准确地说,这难道不就是把四块板组合起来模拟一块小型芯片吗?然后每块板上都配备了八个FPGA,还是最贵的那种。
Peter Foley:当然不是。不同于Paladium仿真器,我们用的只是一块中档的FPGA板,不然可就负担不起了。
我们可以运行700,000行代码,其中包括SPEC中用到的C语言标准库。我们将这些代码编译好,并在我们的FPGA测试平台上运行。FPGA测试平台并不是完整的架构,它只是整体架构的一部分,并且得出功能正确的结果。我们有大量的符号调试器和其他一些基础设施来辅助此类操作。
TPM:当它成为产品时会是什么样子呢,而你又将如何推销它?
Peter Foley:我们正尝试在两个最重要的指标上取胜。第一个是SPECint性能,我们一般通过指令/时钟(IPC)来衡量,但它其实不是一个很好的衡量标准。但我们有一个指标,即我们的每个控制字中执行的工作就相当于 X86指令。若从结果和优化的角度来评估编译器质量的话,下一步我们计划在IPCW、指令/控制字、以及IPC等值这些方面做相应调整。这一步对于超大规模的处理器来说至关重要。
TPM:你们这完全是在赌一把。
Peter Foley:另一个指标则是功耗。我们的想法是要把这两个指标都拿下,并且对此胜券在握。为了降低功耗,我们去掉了所有的晶体管。
TPM:所以,你看了一下需要拿掉多少个晶体管才行,对吗?
Peter Foley:很少,也就比X86少很多。
TPM:大概是一个数量级还是三倍?
Peter Foley:应该是一个数量级。目前也还没有定论,所以我暂不清楚详细的数字。我们花这笔钱就是为了弄清这件事。我们会将微架构具体化并且敲定下来,然后构建一些试验硅(trial silicon),并得到5纳米工具,或者其他我们所需的东西,然后去构建这个微架构并进行布局。
这是构建处理器的其中一步,要做的就是处理所有的几何图形。这一步是为了解决空间延迟和距离限制。布局决定了许多因素,这些因素又会进而影响微架构。因此,我们必须解决好这些问题,同时还要留意其他问题。一旦我们开始深入研究这些问题,就能更加自信地告诉你那个数字究竟是多少。
TPM:所以,如果要我来总结一下Aptos架构的话,那就是降低功耗、优化性能——但你却并不需要降价。
Peter Foley:是的,没错。这样我们就不必花大价钱使用ARM架构了。
(本文已获取编译授权,原文:
https://www.nextplatform.com/2021/07/12/gutting-decades-of-architecture-to-build-a-new-kind-of-processor/)
其他人都在看
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架

以上是关于傻白入门芯片设计,指令集架构微架构处理器内核的主要内容,如果未能解决你的问题,请参考以下文章