Redis深度历险:核心原理和技术实现(原理篇)
Posted 光光-Leo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis深度历险:核心原理和技术实现(原理篇)相关的知识,希望对你有一定的参考价值。
目录
欢迎关注微信公众号“江湖喵的修炼秘籍”
一、鞭辟入里–IO多路复用模型
Redis是单线程的!
1.Redis是单线程的 为什么还这么快?
并不是说单线程就一定慢,多线程就一定快。
第一 Redis是基于纯内存的操作 速度非常快
第二 因为Redis是单线程的 单线程的操作避免了频繁的线程上下文的切换的开销。
第三 redis采用的是非阻塞IO多路复用程序去管理多个socket 效率很高
2.IO模型
补充一点书中没有的内容
Java的IO模型可以分为五种,江湖中曾有一段鲜为人知的往事对此进行了演绎。
“江湖喵”本喵看书看饿了,于是去一家肉夹馍店买肉夹馍吃。
a.阻塞IO模型
我(用户线程)去买肉夹馍(获取数据)时,付了钱(建立链接 提交请求)后,服务员(内核)会看看大厨有没有做好,没做好的话就会等大厨做,我此时饥肠辘辘,咽着口水盯着后厨干等着(阻塞)。
大厨肉夹馍做好后,服务员把肉夹馍交给我(内核态到用户态),我开心的边走边吃了(解除阻塞)。
这就是典型的阻塞型IO.
阻塞IO模型最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。
当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。
当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除 block 状态。典型的阻塞 IO 模型的例子为:data = socket.read();如果数据没有就绪,就会一直阻塞在 read 方法。

b.非阻塞IO模型
我付了钱点了一份肉夹馍,服务员看大厨没做好(数据未准备好)就跟我说还没做好,我就坐到一边去打斗地主。然后每隔两分钟跑过来问一下好没好,没好的时候就回去继续打斗地主,直到大厨把肉夹馍做好,交给我。
这就是非阻塞IO模型。当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。所以事实上,在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO不会交出 CPU,而会一直占用 CPU,这样会导致 CPU 占用率非常高。

c.多路复用IO模型
排了很长的队后终于轮到我点餐了,我点了一份肉夹馍付了钱,服务员交给我一张小票,上边有一个排队号。后厨做好后就会在喇叭里喊对应的号来取餐,所以我只要等喊我的号就可以了。

1、redis内部存在一个多路复用器,用来管理多个socket,监听对应的网络事件。
2、在监听到对应的事件后,将具体将事件压入到内存队列中。
3、内存队列的消费者是一个【文件事件分派器】,就是根据不同的事件选择不同的处理器去处理。 如果是一个客户端发送请求建立连接的事件,那么就选择【连接应答处理器】建立连接并将对应socket的对应事件(AE_READABLE)和【命令请求处理器】绑定。 接下来,如果该socke再发送对应的数据,触发事件(AE_READABLE),同样经过分派器选择对应的处理器,比如要set就选择【命令请求处理器】从socket中读取对应的数据并操作。 最终将该socket的AE_WRITEABLE事件跟【命令回复处理器】绑定起来。 那么最后,该客户端准备好了,可以收回复的时候,又会触发AE_WRITEABLE事件,这个时候分派器就直接分配【命令回复处理器】,去回复客户端对应的请求。 这三个处理器,从上到下进行绑定,完成一次交互。
4、为什么说Redis是单线程的呢?因为以上那些模块都是叫做【文件事件处理器】,这组件是以单线程运行的,通过IO多路复用程序去轮训多个socket。

相比于阻塞IO模型,多路复用只是多了一个select/poll/epoll函数。select函数会不断地轮询自己所负责的文件描述符/套接字的到达状态,当某个套接字就绪时,就对这个套接字进行处理。select负责轮询等待,recvfrom负责拷贝。当用户进程调用该select,select会监听所有注册好的IO,如果所有IO都没注册好,调用进程就阻塞。
对于客户端来说,一般感受不到阻塞,因为请求来了,可以用放到线程池里执行;但对于执行select的操作系统而言,是阻塞的,需要阻塞地等待某个套接字变为可读。
IO多路复用其实是阻塞在select,poll,epoll这类系统调用上的,复用的是执行select,poll,epoll的线程。
d.信号驱动IO模型
懒得下楼,直接点了个外卖,外卖送到的时候会给我打电话,我去取,在此之前我可以接着看书。
在信号驱动 IO 模型中,当用户线程发起一个 IO 请求操作,会给对应的 socket 注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用 IO 读写操作来进行实际的 IO 请求操作。
该模型分为两个阶段:
数据准备阶段:未阻塞,当数据准备完成之后,会主动的通知用户进程数据已经准备完成,对用户进程做一个回调。
数据拷贝阶段:阻塞用户进程,等待数据拷贝
e.异步IO模型
同样点外卖,外卖不仅会直接送到我手边,而且还会以高科技手段直接转换成营养物质注射到胃部,全程不需要我干任何事情,我可以同步的看书。
在异步 IO 模型中,当用户线程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个 asynchronous read 之后,它会立刻返回,说明 read 请求已经成功发起了,因此不会对用户线程产生任何 block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它 read 操作完成了。也就说用户线程完全不需要实际的整个 IO 操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示 IO 操作已经完成,可以直接去使用数据了。
3.定时任务
Redis还有定时任务的功能,如果线程阻塞在select调用上,将无法准时调度。
Redis的定时任务会记录在”最小堆“中,最快要执行的任务在堆的上方,每个循环周期中都会将最小堆中已经到期的任务进行执行,同时将下一次最快要执行的任务的时间记录下来,这个就是执行select的timeout时间。
二、交头接耳–通讯协议
Redis使用的协议是Redis 序列化协议RESP(Redis Serialization Protocol),这是一种直观的文本协议。
Redis协议传输的数据结构有五种最小结构单元,每个最小单元都以\\r\\n结尾。
1、单行字符串 以 + 符号开头。
2、多行字符串 以 $ 符号开头,后跟字符串长度。
3、整数值 以 : 符号开头,后跟整数的字符串形式。
4、错误消息 以 - 符号开头。5、数组 以 * 号开头,后跟数组的长度。
比如set name miao指令,对应的协议内容是一个字符串*3\\r\\n$3\\r\\nset\\r\\n$4\\r\\name\\r\\n$4\\r\\miao\\r\\n,把回车换行符去掉,如下
*3
$3
set
$4
name
$4
miao
三、未雨绸缪 --持久化
Redis的持久化是为了防止数据丢失而对数据进行持久化保存,持久化方式可以分为RDB和AOF.
RDB
RDB方式是存储内存快照。
RDB操作是定时执行的,由于Redis是单线程的,并且生成快照文件是一个耗时的操作,为了避免对Redis的读写产生影响,Redis使用操作系统的COW(COPY ON WRITE)机制来实现快照持久化。
在进行RDB操作时,会调用 glibc 的函数 fork 产生一个子进程,由子进程进行快照持久化,父进程继续处理用户请求。子进程创建的瞬间,是和父进程共享数据的,但是由于父进程需要不停对数据进行修改,这时会使用操作系统的COW机制对数据段页面进行分离,一个数据段包含多个数据页,当父进程对某一个数据页进行修改时,会复制出一个新的数据页,然后对复制出的数据页进行修改,而子进程仍然读老的数据页,而这个数据页的内容是和fork出子进程的时点的瞬时数据。
AOF
AOF日志存储的时对Redis内存数据进行变更的指令记录进行顺序存储,遭遇突发宕机时,只需要顺序执行AOF日志中的指令即可恢复。
AOF瘦身:
当Redis运行很长时间后,对应的AOF日志也会越来越带,导致后续的数据恢复时间也会变长,所以Redis提供了AOF日志瘦身操作。
Redis通过bgrewriteaof进行瘦身,原理时fork出一个子进程,将fork时间的内存数据转换成Redis指令生成一个新的AOF文件,然后把操作期间的增量指令添加到文件末尾,作为新的AOF日志文件。
fsync:
Redis的数据是在内存中,AOF日志是存储在磁盘中,如果Redis宕机时,数据还没来得及刷到磁盘中,就会导致数据丢失。
Linux 的 glibc 提供了 fsync(int fd)函数可以将指定文件的内容强制从内核缓存刷到磁盘。只要 Redis 进程实时调用 fsync 函数就可以保证 aof 日志不丢失。但是fsync很慢,如果每执行一个指令刷一次,严重影响性能,所以Redis一般每1s执行一次(可配置)。
混合持久化
RDB和AOF各有优缺点,RDB文件恢复快,但是由于是定时生成快照,会丢失大量数据,一般不会使用;而AOF由于需要对操作指令进行重放,所以恢复慢。
Redis4.0提供了混合持久化,即恢复数据时,先恢复RDB文件中的数据,然后再执行AOF文件中从RDB持久化之后的增量指令。
四、雷厉风行 – 管道
Redis的管道不是服务端提供的技术,而是客户端提供的技术,目的是将多个请求打包成一个请求,降低网络数据包来回传送的时间损耗。
对于多个请求,普遍的请求方式是如下图所示
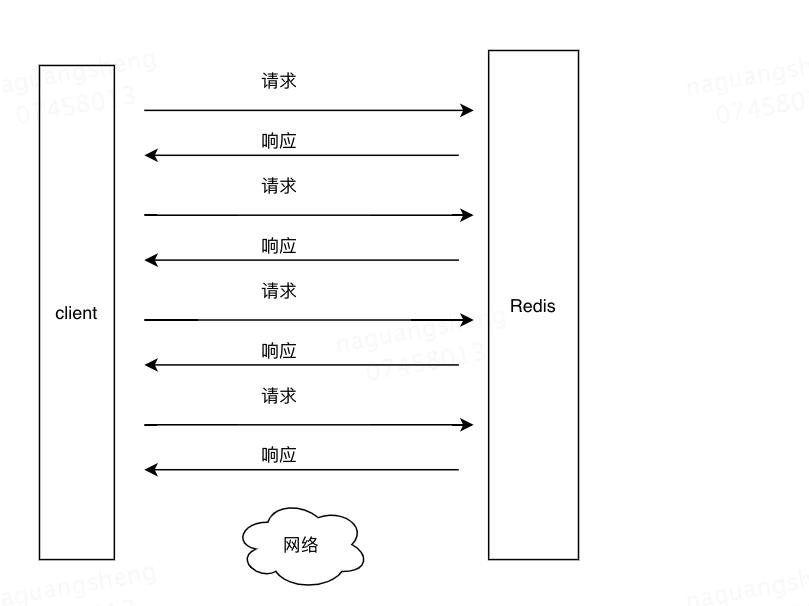
使用pipeline管道技术后,请求过程如下,pipeline适合同时有大量redis操作的场景

五、开源节流 – 小对象压缩
ziplist
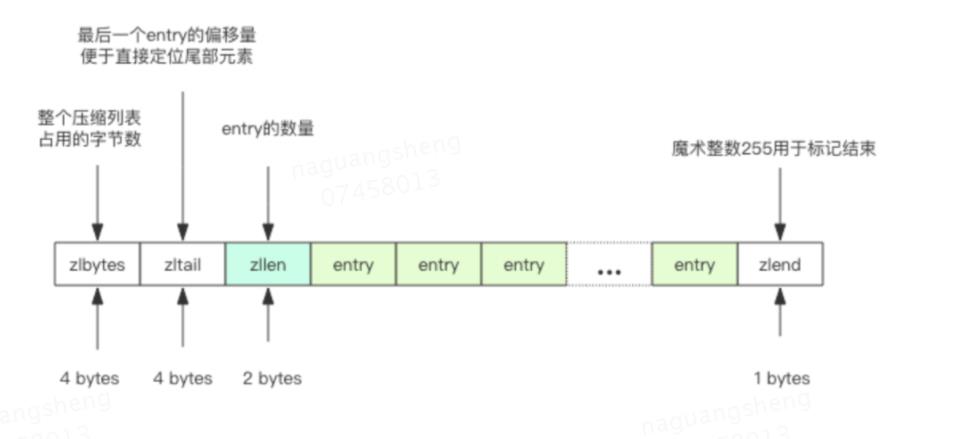
Redis 如果使用 32bit 进行编译,内部所有数据结构所使用的指针空间占用会少一半。如果 Redis 内部管理的集合数据结构很小,它会使用紧凑存储形式压缩存储,Redis 的 ziplist 是一个紧凑的字节数组结构,每个元素之间都是紧挨着的。
内存回收机制
Redis 并不总是可以将空闲内存立即归还给操作系统,原因是操作系统回收内存是以页为单位,如果这个页上只要有一个 key还在使用,那么它就不能被回收。Redis 虽然无法保证立即回收已经删除的 key 的内存,但是它会重用那些尚未回收的空闲内存。
六、有备无患 – 主从同步
CAP原理
Consistent ,一致性Availability ,可用性Partition tolerance ,分区容忍性
最终一致
Redis 的主从数据是异步同步的,所以分布式的 Redis 系统并不满足「一致性」要求。当客户端在 Redis 的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务,所以 Redis 满足「可用性」。
Redis 保证「最终一致性」,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态将保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,一旦网络恢复,从节点会采用多种策略努力追赶上落后的数据,继续尽力保持和主节点一致。
同步方式
主从同步的方式有点类似持久化方式中的混合持久化。
salve第一连上来时候,先ping一下主节点,然后发对应的请求。master会生成当前所有数据的RDB文件,然后这个过程中新写的数据就放在缓存中。 master写完RDB后就一次性发给slave。发完之后再慢慢将之前新缓存的数据一点点异步发给slave(同步指令)。 slave收到数据后也会先写入本地磁盘,然后再读到内存中。 正常情况下,就是主节点来一条数据,那么给客户端返回确认,就发给slave。
无磁盘化
在master向slave同步数据的时候,要不要写rdb文件,默认是无磁盘化的,就是写在内存中,直接发给slave,可以打开,也就是先写RDB再发给slave。
以上是关于Redis深度历险:核心原理和技术实现(原理篇)的主要内容,如果未能解决你的问题,请参考以下文章