数据结构哪些是四种常见的逻辑结构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构哪些是四种常见的逻辑结构相关的知识,希望对你有一定的参考价值。
四种常见的逻辑结构:
1、集合结构
数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
2、线性结构
数据结构中的元素存在一对一的相互关系
3、树形结构
数据结构中的元素存在一对多的相互关系
4、图形结构
数据结构中的元素存在多对多的相互关系
扩展资料:
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
数据的逻辑结构:指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后件关系,而与他们在计算机中的存储位置无关。
数据的物理结构是数据结构在计算机中的表示(又称映像),它包括数据元素的机内表示和关系的机内表示。由于具体实现的方法有顺序、链接、索引、散列等多种,所以,一种数据结构可表示成一种或多种存储结构。
参考资料来源:百度百科-数据结构
参考技术A数据结构四种常见的逻辑结构:
1、集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
2、线性结构:数据结构中的元素存在一对一的相互关系;
3、树形结构:数据结构中的元素存在一对多的相互关系;
4、图形结构:数据结构中的元素存在多对多的相互关系。
扩展资料
逻辑结构分为两种:
线性结构和非线性结构(集合、树、网)。
线性结构:有且只有一个开始结点和一个终端结点,并且所有结点都最多只有一个直接前驱和一个直接后继。
例如:线性表,典型的线性表有:顺序表、链表、栈(顺序栈、链栈)和队列(顺序队列、链队列)。它们共同的特点就是数据之间的线性关系,除了头结点和尾结点之外,每个结点都有唯一的前驱和唯一的后继,也就是所谓的一对一的关系。
非线性结构:对应于线性结构,非线性结构也就是每个结点可以有不止一个直接前驱和直接后继。常见的非线性结构包括:树(二叉树)、图(网)等。
参考资料:百度百科-数据结构
数据结构四种常见的逻辑结构:集合、线性结构、树形结构、图形结构。
数据的逻辑结构:指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后件关系,而与他们在计算机中的存储位置无关。逻辑结构包括:
1、集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
2、线性结构:数据结构中的元素存在一对一的相互关系;
3、树形结构:数据结构中的元素存在一对多的相互关系;
4、图形结构:数据结构中的元素存在多对多的相互关系。
扩展资料:
1、线性结构包括数组、链表、栈以及队列
(1)数组:在程序设计中,为了处理方便, 把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的集合称为数组。
在C语言中, 数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别。
(2)链表:链表是一种物理存储单元上非连续、非顺序的存储结构,它既可以表示线性结构,也可以用于表示非线性结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
(3)栈:栈是只能在某一端插入和删除的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
(4)队列:一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。
队列是按照“先进先出”或“后进后出”的原则组织数据的。队列中没有元素时,称为空队列。
2、树是包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。
(2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
3、图形结构
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
参考资料:百度百科-数据结构
参考技术C4种常见的逻辑结构:指数据之间的相互关系。
1、集合结构:集合结构的集合中任何两个数据元素之间都没有逻辑关系,组织形式松散。
2、线性结构:数据结构中线性结构指的是数据元素之间存在着“一对一”的线性关系的数据结构。
3、树状结构:树状结构是一个或多个节点的有限集合。
4、网络结构:网络结构是指通信系统的整体设计,它为网络硬件、软件、协议、存取控制和拓扑提供标准。它广泛采用的是国际标准化组织(ISO)在1979年提出的开放系统互连的参考模型。
扩展资料:
逻辑结构与数据结构的关系:
逻辑结构指的是数据间的关系,而存储结构是逻辑结构的存储映像。通俗的讲,可以将存储结构理解为逻辑结构用计算机语言的实现。常见的存储结构有顺序存储、链式存储、索引存储以及散列存储(哈希表)。
1、顺序存储:把逻辑上相邻的节点存储在物理位置上相邻的存储单元中,结点之间的逻辑关系由存储单元的邻接关系来体现。由此得到的存储结构为顺序存储结构,通常顺序存储结构是借助于数组来描述的。优点:节省空间,可以实现随机存取;缺点:插入、删除时需要移动元素,效率低。
2、链式存储:在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。特点是元素在物理上可以不相邻,所以每个数据元素包括了一个数据域和一个指针域,数据域用来存放数据,而指针域用来指向其后继结点的位置。
参考资料:百度百科-逻辑结构
参考技术D1.数据4种逻辑结构:
(1)集合结构:数据元素之间没有任何关系。
(2)线性结构:数据元素之间定义了线性关系。1对1。
(3)树形结构:数据元素之间定义了层次关系。1对多。
(4)图状结构:数据元素之间定义了网状关系。多对多。
2.(1)集合结构。集合任何两数据元素间都没逻辑关系,组织形式松散。
(2)线性结构。线性结构 结点按逻辑关系依排列形锁链。
(3)树形结构。树形结构具支、层特性,其形态点象自界树。
(4)图状结构。图状结构结点按逻辑关系互相缠绕,任何两结点都邻接。
扩展资料:
1.数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
2.数据的逻辑结构:指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后件关系,而与他们在计算机中的存储位置无关。
参考资料:百度百科-数据结构
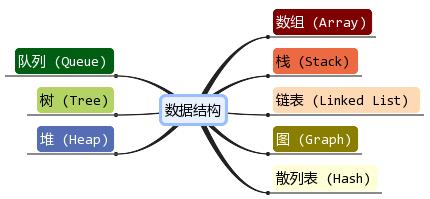
四种常见的数据结构LinkedListSet集合CollectionMap总结
四种常见的数据结构:
1.堆栈结构:
先进后出的特点。(就像弹夹一样,先进去的在后进去的低下。)
2.队列结构:
先进先出的特点。(就像安检一样,先进去的先出来)
3.数组结构:
查找元素快,但是增删元素慢
4.链表结构:
增删元素快,但是查找元素慢
LinkedList:(List接口下的一个子类,和ArrayList是同级别关系)
1.底层是链表结构
2.它的一些特有方法:
addFirst(E e) : 向集合中的开头添加元素
addLast(E e):向集合的末尾添加元素
getFirst():得到集合中的第一个元素
getLast():得到集合中的最后一个元素
removeFirst():删除集合中的第一个元素
removeLast():删除集合中的最后一个元素
pop(E e) : 从集合的最上面弹出一个元素
push():向集合的最上面添加元素
isEmpty() : 判断集合中是否有为空
3.在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。
使用的方法是:调用addFirst(E e) 方法和getFirst() 方法
Set集合(Set是一个接口,和List一样,它俩也是同级别关系)
Set集合的遍历方式只有两种,1. 增强for 2. 迭代器
Set集合特点:
唯一性,元素不重复
1.Set的子类有:
HashSet、LinkedHashSet
2.HashSet:
a.HashSet是无序的,存取顺序不一样
b.底层是哈希表结构,通常自定义对象是需要重写HashCode方法和equals方法
c.HashSet是使用HashCode方法和equals方法来保证元素唯一的
d.判断原理是:
先判断HashCode方法
相同:
不添加
不相同:判断equals方法:
不相同:添加
相同:不添加
LinkedHashSet:
1.LinkedHashSet是有序的,存取顺序是一样的
2.底层是链表+哈希表结构。
3.通过链表来保证有序。通过哈希表来保证元素的唯一。
Collection总结:
1.子类:
List、Set(两个都是接口)
List子类:
ArrayList
LinkedList
Set子类:
HashSet
LinkedHashSet
2.Collection的方法:
boolean add(Object e): 添加
void clear(): 清空
boolean remove(Object o):删除
boolean contains(Object o): 包含
boolean isEmpty():是否为空
Iterator iterator():迭代器
int size(): 集合长度
Object toArray(): 将集合存到数组中
3.迭代器:
两个方法:
hasNext():是否有下一个元素
next(): 获取下一个元素
4.List和Set的区别:
List:
有序,且可有重复元素
Set:
它是一个无序的集合(元素存与取的顺序可能不同)
不可以有重复的元素
5.List集合中的特有方法:(有角标的都是List集合中的)
void add(int index, Object element) 将指定的元素,添加到该集合中的指定位置上
Object get(int index) 返回集合中指定位置的元素。
Object remove(int index) 移除列表中指定位置的元素, 返回的是被移除的元素
Object set(int index, Object element) 用指定元素替换集合中指定位置的元素,返回值的更新前的元素
6.泛型:
好处:
提高了程序的安全性
将运行时期的异常提到的编译时期
避免了类型转换
Map:(它也是一个接口,它是和Collection同级别的,它是一个双列集合)
常用子类:
HashMap<key , value>:
泛型里存储键和值,键唯一,但是值可以重复。底层是哈希表结构,基本和HashSet集合差不多,在存储自定义对象时,需要重写HashCode方法和equals方法。无序。
LinkedHashMap:
底层是链表+哈希表结构。有序,存和取的顺序一致。
方法:
put(K,V):添加元素,相当于list集合中的add方法
get(key):得到key对应的值。
Map遍历(两种方式)
1. keySet()方法
转为Set对象,获取Map集合中的键集,存储到Set集合中
然后可使用增强for或迭代器来获取键和值都通过,键来获取值。
2. entrySet()方法
方法:
getey()
getValue()
转为entry对象,获取Map集合中的键和值的映射关系,存储到entry对象中。
然后,可以使用增强for或迭代器来获取键和值。
都通过,键来获取值。
Properties类(一般和流一块使用,它也是Map下的一个子类它是一个可以持久化的属性集。键值可以存储到集合中,也可以存储到持久化的设备(硬盘、U盘、光盘)上。键值的来源也可以是持久化的设备。
(有和流技术相结合的方法。)
1.public Object setProperty(String key, String value)调用 Map 的方法 put。
2.public Set<String> stringPropertyNames()返回此属性列表中的键集, //keyset()方法
3.public String getProperty(String key)用指定的键在此属性列表中搜索属性//get()方法
写入文件的方法:
store(Writer,”文件的描述信息”)
读取文件的方法:
load(Reader)
可变参数:
表现格式为:
数据类型... 变量名
相当于一个数组。
Collections工具类
方法
shuff()随机打乱方法
sort()排序方法,按照自然规律排序。
以上是关于数据结构哪些是四种常见的逻辑结构的主要内容,如果未能解决你的问题,请参考以下文章