Chaya大数据架构综合实践课程学习 ——— Openresty安装
Posted ExcellentChaya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Chaya大数据架构综合实践课程学习 ——— Openresty安装相关的知识,希望对你有一定的参考价值。
使用环境:VMWare 15.5 Centos 7 虚拟机
MobaXterm_Portable_v22.0
一、下载Openresty相关依赖
##下载Openresty依赖
yum install readline-devel pcre-devel openssl-devel gcc
##下载Openresty仓库yum源
wget https://openresty.org/package/centos/openresty.repo
##移动到yum源
mv openresty.repo /etc/yum.repos.d/
##更新yum源
yum check-update
##查看软件可用版本
yum list openresty --showduplicates
##安装Openresty源
yum install -y openresty
##测试安装正确
openresty -v
##默认安装位置
##/usr/local/openresty二、Nginx相关配置
编写nginx.conf配置文件 位置:/opt/openresty/conf/nginx.conf(需要手动创建)
ps: 可直接使用下方代码一步创建,此截图看起来比较繁琐但是是谨慎的看看当前文件夹是否有其他文件避免后面步骤出线错误
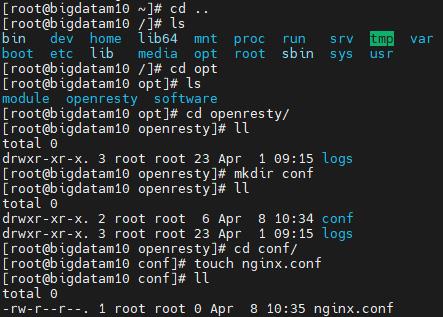
手动创建nginx.conf代码
touch /opt/openresty/conf/nginx.confnginx.conf内容如下:
#nginx.conf
#nginx
user root root;
#work进程数,
worker_processes 4;
# 错误日志路径,和日志级别
#需要先手动创建error.log文件,不然后面执行命令时会报错
error_log /opt/openresty/logs/nginx_error.log error;
# nginx pid文件
pid /opt/openresty/logs/nginx.pid;
# 单个worker最大打开的文件描述符个数
worker_rlimit_nofile 65535;
events
#使用epoll模型
use epoll;
#单个worker进程允许的最多连接数
worker_connections 65535;
http
#mime.types 和当前文件在同一个目录下,要先提前创建,不然报错显示没有此文件
include mime.types;
default_type application/octet-stream;
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml;
gzip_vary on;
underscores_in_headers on;
log_format main escape=json '"timestamp": "$time_local",'
'"remote_addr": "$remote_addr",'
'"referer": "$http_referer",'
'"request": "$request",'
'"statu": "$status",'
'"byte": "$body_bytes_sent",'
'"agen": "$http_user_agent",'
'"x_forwarde": "$http_x_forwarded_for",'
'"up_addr": "$upstream_addr",'
'"up_host": "$upstream_http_host",'
'"up_resp_time": "$upstream_response_time",'
'"request_time": "$request_time"';
#定义我们数据采集的日志格式
log_format format_userlogs '$logdata';
open_log_file_cache max=1000 inactive=60s;
keepalive_timeout 0;
client_max_body_size 20m;
include /opt/openresty/conf/vhost/*.conf;
记得要先创建此文件中的error.log和mime.types以及nginx.pid文件,不然后面执行命令时会报错显示没有此文件
touch /opt/openresty/logs/nginx_error.log
touch /opt/openresty/conf/mime.types
touch /opt/openresty/logs/nginx.pid如果后面重启openresty出现了问题,请记得子nginx.pid中输入nginx的端口号,这里设置为8802(也就是仅仅在nginx.pid中输入:8802)
三、服务应用配置
用户自定义配置文件userlogs.conf 位置:/opt/openresty/conf/vhost/userlogs.conf(也是需要自己去创建此文件)
touch /opt/openresty/conf/vhost/userlogs.conf编写userlogs.conf内容:
#userlogs.conf
server
listen 8802 default_server;
lua_need_request_body on;
client_max_body_size 5M;
client_body_buffer_size 5M;
location /data/userlogs
set $logdata '';
content_by_lua_block
-- cjson模块
local cjson = require "cjson"
-- 读取请求体信息
ngx.req.read_body()
-- 请求体信息存放到 body_data变量中
local body_data = ngx.req.get_body_data()
-- 如果请求体为空,返回错误
if body_data == nil then
ngx.say([["code":500,"msg":"req body nil"]])
return
end
-- 定义当前时间
local current_time = ngx.now()*1000
-- 定义一个字典(存放请求参数)
local data=
data["ctime"] = current_time
-- 将增加的信息编码为json
local meta = cjson.encode(data)
-- 将body_data数据进行编码处理(若需要使用节点信息则增加meta数据)
--local req = ngx.encode_base64(meta) .. "-" .. ngx.unescape_uri(body_data)
local req = ngx.unescape_uri(body_data)
-- 将数据赋值给我们定义的nginx变量logdata(定义的log_format就使用)
ngx.var.logdata = req
ngx.say([["code":200,"msg":"ok"]])
access_log logs/userlogs.log format_userlogs;
四、Nginx服务启动
##测试配置格式正确 -p 指定openresty的配置目录
openresty -p /opt/openresty/ -t
##服务启动 -p 指定openresty的配置目录
openresty -p /opt/openresty/
##服务启动测试
##端口查看
netstat -antp |grep 8802
或者
lsof -i:8802
##进程查看
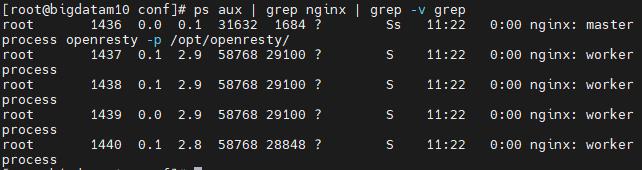
ps aux | grep nginx | grep -v grep
##服务停止
openresty -p /opt/openresty/ -s stop
##在服务未停止时重启
openresty -p /opt/openresty/ -s reload我的效果图:



五、Hello World界面尝试
如果已经完成了上面的安装步骤,可以直接进行下方链接的 Hello World实例 进行练习
OpenResty 使用介绍 | 菜鸟教程 (runoob.com) https://www.runoob.com/w3cnote/openresty-intro.html注意: 由于我使用的是虚拟机,所以不能直接通过本地win系统的浏览器输入http://localhost:9000/ 查看虚拟机的的内容。如果想要通过本机浏览器查看虚拟机OpenResty的页面内容,在本地浏览器中输入:http://[虚拟机的IP]:9000/
https://www.runoob.com/w3cnote/openresty-intro.html注意: 由于我使用的是虚拟机,所以不能直接通过本地win系统的浏览器输入http://localhost:9000/ 查看虚拟机的的内容。如果想要通过本机浏览器查看虚拟机OpenResty的页面内容,在本地浏览器中输入:http://[虚拟机的IP]:9000/
大数据-学习实践-5企业级解决方案
大数据-学习实践-5企业级解决方案
(大数据系列)
文章目录
1知识点
- 小文件问题
- 小文件存储计算
- 数据倾斜
- YARN
- Hadoop官方
2具体内容
2.1小文件问题
MapReduce框架针对大数据文件设计,小文件处理效率低下,消耗内存资源
- 每个小文件在NameNode都会占用150字节的内存,每个小文件都是一个block
- 一个block产生一个inputsplit,产生一个Map任务
- 同时启动多个map任务消耗性能,影响MapReduce执行效率
2.1.1 SequenceFile
- SequenceFile是二进制文件,直接将<k,v>对序列化到文件
- 对小文件进行文件合并:文件名为k,文件内容为v,序列化到大文件
- 但需要合并文件的过程,文件大且合并后的文件不便查看,需要遍历查看每个小文件
- 读、写试验
- SequenceFile在hdfs上合并为一个文件
2.1.2 MapFile
- 排序后的MapFile,包括index和data
- index为文件的数据索引,记录每个record的key值,并保存该record在文件中的偏移位
- 访问MapFile时,索引文件被加载到内存,通过索引映射关系快速定位到指定Record所在文件位置
- 相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据
- MapFile在hdfs上包括2个文件,index和data
2.1.3 小文件存储计算
使用SequenceFile实现小文件存储计算
- java开发,生成SequenceFile;(人工将一堆小文件处理成一个较大文件,进行MapReduce计算)
- 开发MapReduce(借助底层),读取Sequencefile,进行分布式计算
2.2数据倾斜
- 一般不对Map任务进行改动,但为了提高效率,可增加Reduce任务,需要对数据分区
- job.getPartitionerClass()实现分区
- 当MapReduce程序执行时,大部分Reduce节点执行完毕,但有一个或几个Reduce节点运行很慢,导致整个程序处理时间变长,表现为Reduce节点卡着不动
- 倾斜不严重,可增加Reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
- 倾斜严重,要把倾斜数据打散(抽样确定哪一类,打散)
String key = words[0];
if ("5".equals(key))
//把倾斜的key打散,分成10份
key = "5" + "_" + random.nextInt(10);
2.3 YARN
2.3.1 YARN架构
- 集群资源的管理和调度,支持主从架构,主节点最多2个,从节点可多个
- ResourceManager:主节点负责集群资源分配和管理
- NodeManager:从节点负责当前机器资源管理
- YARN主要管理内存和CPU两种资源
- NodeManager启动向ResourceManager注册,注册信息包含该节点可分配的CPU和内存总量
- 默认单节点:(yarn-site.xml文件中设置)
- yarn.nodemanager.resourece.memory-mb:单节点可分配物理内存总量,默认8Mb*1024,8G
- yarn.nodemanager.resource.cpu-vcores:单节点可分配的虚拟CPU个数,默认是8
2.3.2 YARN调度器
- FIFO Scheduler 先进先出
- Capacity Scheduler FIFO Scheduler 多队列版本(常用)
- Fair Scheduler 多队列,多用户共享资源
2.3.2 YARN多资源队列配置和使用
- 增加online队列和offline队列
- 修改 capacity-scheduler.xml 文件,并同步其他节点
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>Online queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>Offline queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>
The maximum capacity of the online queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>
The maximum capacity of the offline queue.
</description>
</property>
- 重新启动
stop-all.sh
start-all.sh
- 向offline队列提交MR任务
- online队列里面运行实时任务
- offline队列里面运行离线任务
#解析命令行通过-D传递参数,添加至conf;也可修改java程序解析各参数
String[] remainingArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJobQueue.class);#必须有,否则集群执行时找不到wordCountJob这个类
#重新编译上传执行
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJobQueue -Dmapreduce.job.queue=offline /test/hello.txt /outqueue
2.4Hadoop官方文档
- 官方文档
- 在CDH中的使用
- 在HDP中的使用
-(1080端口) Ambari组件,提供web界面
2.5总结
- MapReduce
- 原理
- 计算过程
- 执行步骤
- wordcount案例
- 日志查看:开启YARN日志聚合,启动historyServer进程
- 程序扩展:去掉Reduce
- Shuffle过程
- 序列化
- Writable实现类
- 特点
- 源码分析
- InputFormat
- OutputFormat
- 性能优化
- 小文件
- 数据倾斜
- YARN
- 资源管理:内存+CPU
- 调度器:常用CapacityScheduler
3待补充
无
4Q&A
无
5code
无
6参考
- 大数据课程资料
以上是关于Chaya大数据架构综合实践课程学习 ——— Openresty安装的主要内容,如果未能解决你的问题,请参考以下文章