100天精通Python(可视化篇)——第82天:matplotlib绘制不同种类炫酷散点图参数说明+代码实战(二维散点图三维散点图散点图矩阵)
Posted 袁袁袁袁满
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了100天精通Python(可视化篇)——第82天:matplotlib绘制不同种类炫酷散点图参数说明+代码实战(二维散点图三维散点图散点图矩阵)相关的知识,希望对你有一定的参考价值。
文章目录
专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等

0. 前言
散点图(Scatterplot)是一种数据可视化图,用于将两个或更多维度的数据图像化,用不同大小和形状的点表示各自的数据集。它们通常用于表示两个变量之间的相互关系,并在分析异常值时非常有用。散点图的性质使其能够探究两个变量之间的关联性,还可以制作回归线或非线性回归图来查看数据之间的趋势。
特点:散点图提供了相当强大的数据可视化功能,它允许我们研究变量之间的关联性、可视化显著性空间、挖掘任何趋势或模式以及识别异常情况。
应用场景:散点图可用于研究由两个或更多变量组成的多元统计分析。它们通常用于计算两个变量之间的相关性,有助于发现事物间的联系。举例而言,我们可以用散点图来研究婴儿出生体重与出生时期长度之间的联系,以及哪些市场因素(如季节性变化、价格变化等)可能影响销售额等等。
1. 参数说明
matplotlib绘制散点图的函数是scatter(),以下是函数代码和参数说明大全:
import matplotlib.pyplot as plt
plt.scatter(x,
y,
s=None,
c=None,
marker=None,
cmap=None,
norm=None,
vmin=None,
vmax=None,
alpha=None,
linewidths=None,
edgecolors=None,
plotnonfinite=False,
data=None,
**kwargs
)
参数说明:
x, y:散点图的x和y坐标数据,可以是数组、列表或者Series类型。
s:散点的大小。可以是一个标量,也可以是与x、y等长度相���的数组。
c:散点的颜色。可以是一个表示颜色的字符串,也可以是一个与x、y等长度相同的数组。
marker:散点的形状。可以是一个表示形状的字符串,例如'o'、'+'、'x'等,也可以是一个自定义的MarkerStyle对象。
cmap:颜色映射。如果c参数是一个数组,则可以使用cmap参数指定颜色映射,例如'viridis'、'cool'等。
norm:颜色映射的归一化方式。可以是matplotlib.colors.Normalize对象,也可以是自定义的归一化函数。
vmin, vmax:颜色映射的最小值和最大值。
alpha:散点的透明度。可以是一个标量,也可以是与x、y等长度相同的数组。
linewidths:散点的边框宽度。
edgecolors:散点的边框颜色。
label:散点的标签,用于在图例中显示。
zorder:散点的层级,用于控制散点的绘制顺序。
hatch:散点的填充样式。
picker:指定散点的选中方式,例如'pick_event'表示使用pick事件选中散点。
plotnonfinite:指定是否绘制非有限数据。
data:散点的数据源。
**kwargs:其他可选参数,例如color、size、facecolors等。
以上是scatter()函数的参数说明,可以根据需要灵活使用。
2. 两主特征:二维散点图
**二维散点图是一种用于展示二维数据点分布情况的图表类型。**它将每个数据点表示为平面上的一个点,通常使用不同的符号或颜色来区分不同的数据类别或属性。二维散点图可以用于分析数据的聚集性、离散程度、异常点等特征,是数据可视化中常用的一种方法。
1)普通散点图
首先,我们使用 NumPy 库生成了两个长度为 50 的随机数组 x 和 y。然后,我们使用 matplotlib 的 scatter() 函数绘制散点图。最后,我们使用 show() 函数显示图像。
import matplotlib.pyplot as plt
import numpy as np
# 生成数据
x = np.random.rand(50)
y = np.random.rand(50)
# 绘制散点图
plt.scatter(x, y)
# 显示图像
plt.show()
运行结果:

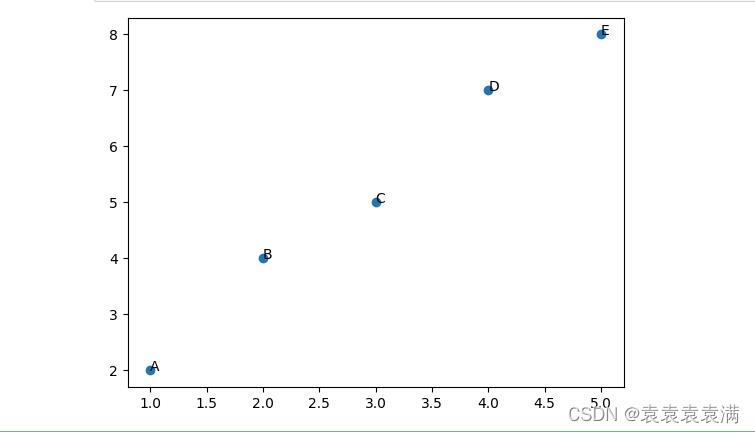
2)文字标签散点图
首先,使用scatter函数绘制散点图,将x轴和y轴的数据传递给它。然后,使用text函数添加标签。text函数需要传递标签的x和y坐标,以及标签的文本。这个散点图展示了一些数据点,每个点都有一个标签。通过这个图,我们可以很容易地看出每个点的位置和标签,更直观地理解数据。下面是一个示例代码:
import matplotlib.pyplot as plt
# 数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 5, 7, 8]
labels = ['A', 'B', 'C', 'D', 'E']
# 绘制散点图
plt.scatter(x, y)
# 添加标签
for i, label in enumerate(labels):
plt.text(x[i], y[i], label)
# 显示图形
plt.show()
运行结果:
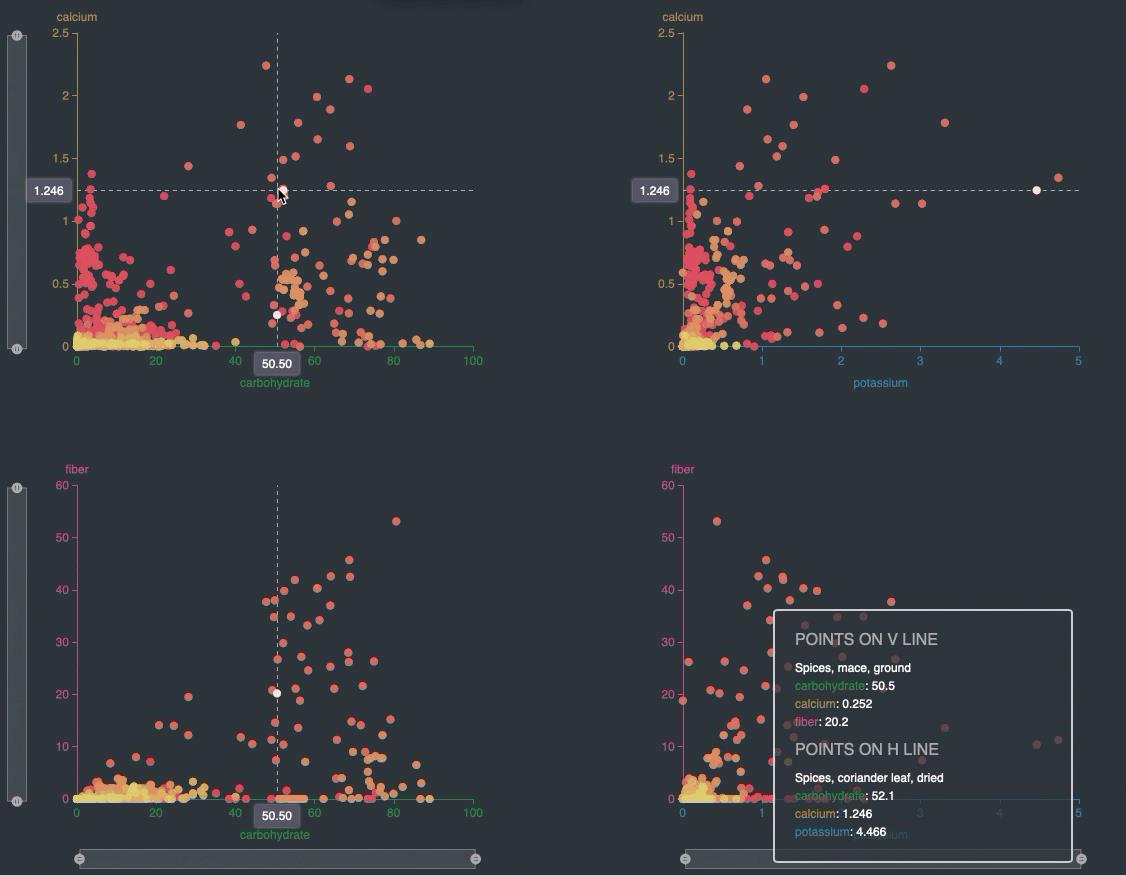
3)带颜色映射的散点图
首先使用numpy.random.randn函数生成500个生成随机数据样本,每个样本有2个特征。同时,使用numpy.random.randn函数生成500个特征值。
- 绘制带颜色映射的散点图:使用matplotlib.pyplot.subplots函数创建一个子图,并使用scatter函数绘制散点图。其中,c参数指定颜色映射的值,cmap参数指定颜色映射的颜色范围。同时,使用grid函数添加网格线,使用set_xlabel和set_ylabel函数设置坐标轴标签。
- 添加颜色条:使用legend_elements函数生成颜色条,使用legend函数添加颜色条并设置标题和位置。
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
n_samples = 500
x = np.random.randn(n_samples, 2)
colors = np.random.randn(n_samples)
# 绘制带颜色映射的散点图
fig, ax = plt.subplots(figsize=(8, 8))
scatter = ax.scatter(x[:, 0], x[:, 1], c=colors, cmap='cool')
ax.grid(True)
ax.set_xlabel('X')
ax.set_ylabel('Y')
# 添加颜色条
legend1 = ax.legend(*scatter.legend_elements(),
loc="upper right", title="Values")
ax.add_artist(legend1)
plt.show()
运行结果:

4)ArcGIS散点图
ArcGIS散点图是一种常见的数据可视化方式,可以帮助我们更好地理解数据之间的关系。使用matplotlib可以轻松绘制出漂亮的ArcGIS散点图,并且可以对图像进行进一步的解释。下面是一个简单的例子,展示如何使用matplotlib绘制ArcGIS散点图:
import matplotlib.pyplot as plt
import numpy as np
# 生成随机数据
x = np.random.rand(100)
y = np.random.rand(100)
z = np.random.rand(100) * 100
# 绘制散点图
plt.figure(figsize=(8, 6))
plt.scatter(x, y, c=z, cmap='cool', alpha=0.8)
# 添加标题和标签
plt.title('ArcGIS Scatter Plot')
plt.xlabel('X')
plt.ylabel('Y')
plt.colorbar()
plt.show()
运行结果:

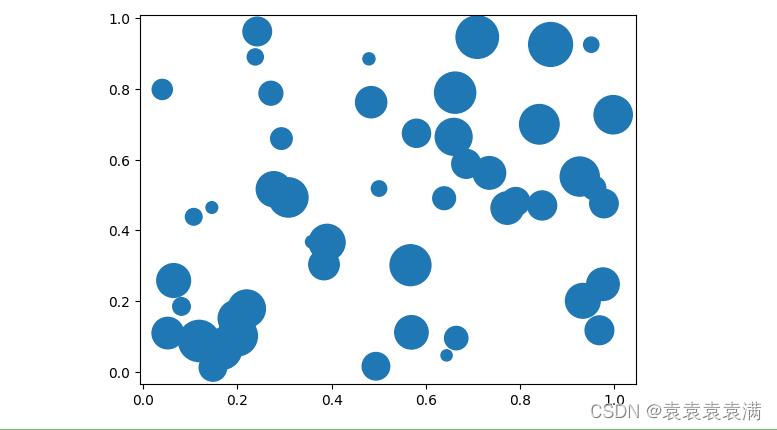
5)气泡图
气泡图是一种散点图,其中每个数据点用一个圆圈表示,并且圆圈的大小表示第三个变量的值。气泡图通常用于显示多个变量之间的关系。我们使用 NumPy 库生成了三个长度为 50 的随机数组 x、y 和 z,其中 z 表示圆圈的大小。然后,我们使用 scatter() 函数绘制气泡图,并将 z 用作圆圈的大小。最后,我们使用 show() 函数显示图像。
import matplotlib.pyplot as plt
import numpy as np
# 生成数据
x = np.random.rand(50)
y = np.random.rand(50)
z = np.random.rand(50) * 1000
# 绘制气泡图
plt.scatter(x, y, s=z)
# 显示图像
plt.show()
运行结果:
6)分类散点图
我们使用 numpy 库生成了两组长度为 50 的随机数组 x1、y1 和 x2、y2。然后,我们使用 plt.scatter() 函数绘制两组散点图,并添加标签。接着,我们使用 plt.legend() 函数添加图例。最后,我们使用 plt.xlabel()、plt.ylabel() 和 plt.title() 函数添加标签和标题。最终,我们使用 plt.show() 函数显示图像。
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x1 = np.random.rand(50)
y1 = np.random.rand(50)
x2 = np.random.rand(50)
y2 = np.random.rand(50) + 1
# 绘制散点图
plt.scatter(x1, y1, label='Group 1')
plt.scatter(x2, y2, label='Group 2')
# 添加图例
plt.legend()
# 添加标签和标题
plt.xlabel('x')
plt.ylabel('y')
plt.title('Grouped Scatter Plot')
# 显示图像
plt.show()
运行结果:

7)线性拟合散点图
线性拟合散点图是一种常见的数据可视化方式,用于表示两个变量之间的关系。其中,横轴表示自变量,纵轴表示因变量,每个点代表一组数据。通过对散点进行线性拟合,可以得到一条直线,该直线能够较好地拟合数据点,反映出自变量和因变量之间的趋势关系。
线性拟合散点图广泛应用于科学研究、商业分析等领域。通过观察散点图,我们可以发现自变量和因变量之间的关系是否存在,以及关系的强度和方向。通过线性拟合,我们可以更加准确地描述这种关系,预测未来的趋势和结果,并作出相应的决策。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 生成数据
x = np.random.rand(50)
y = 2 * x + 1 + np.random.randn(50) * 0.2
# 绘制散点图
plt.scatter(x, y)
# 计算线性回归的斜率、截距和 R-squared 值
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
# 绘制拟合直线
plt.plot(x, slope * x + intercept, color='r')
# 添加标签和标题
plt.xlabel('x')
plt.ylabel('y')
plt.title('Linear Regression')
# 显示图像
plt.show()
运行结果:

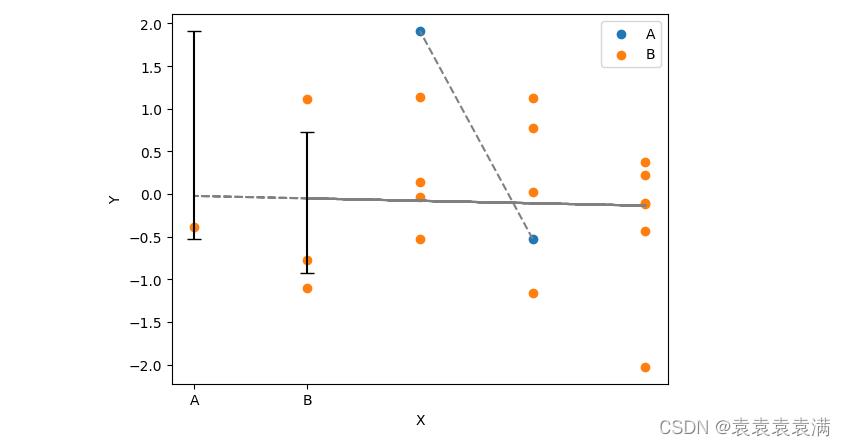
8)分类+线性拟合散点图
分类+线性拟合散点图是一种常见的数据可视化方式,可以用来展示两个变量之间的关系:
import matplotlib.pyplot as plt
import numpy as np
# 生成随机数据
np.random.seed(42)
x = np.random.randint(1, 6, size=20)
y = np.random.normal(0, 1, size=20)
group = np.random.choice(['A', 'B'], size=20)
# 计算每组的均值和标准差
groups = np.unique(group)
means = [np.mean(y[group == g]) for g in groups]
stds = [np.std(y[group == g]) for g in groups]
# 绘图
fig, ax = plt.subplots()
for g in groups:
ax.scatter(x[group == g], y[group == g], label=g)
# 添加线性拟合
for g in groups:
x_g = x[group == g]
y_g = y[group == g]
z = np.polyfit(x_g, y_g, 1)
p = np.poly1d(z)
ax.plot(x_g, p(x_g), '--', color='gray')
# 添加误差线
ax.errorbar(np.arange(1, len(groups)+1), means, yerr=stds, fmt='none', color='black', capsize=5)
# 设置图形属性
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_xticks(np.arange(1, len(groups)+1))
ax.set_xticklabels(groups)
ax.legend()
plt.show()
解释:
首先,我们使用numpy生成了一些随机数据,包括20个x值、20个y值和20个分组(A或B)。
然后,我们计算了每个分组的均值和标准差,以便后面添加误差线。
接着,我们创建了一个matplotlib图形对象,包括一个坐标轴对象ax。
我们使用循环遍历每个分组,将它们的x值和y值绘制成散点图,并添加标签。
我们使用另一个循环,为每个分组添加线性拟合线,以展示x和y之间的趋势。
最后,我们添加误差线、设置图形属性(包括x轴标签、y轴标签、x轴刻度标签、图例等),并显示图形。
这样,我们就可以使用matplotlib绘制好看的分组+线性拟合散点图了。这种图形可以让我们更直观地了解两个变量之间的关系,并展示不同分组之间的差异。
运行结果:
3. 三主特征:三维散点图
三维散点图是一种常见的数据可视化方式,用于表示三个变量之间的关系。其中,横轴、纵轴和深度轴分别表示三个变量,每个点代表一组数据。通过对散点进行可视化,可以直观地观察三个变量之间的关系,发现其中的规律和趋势。
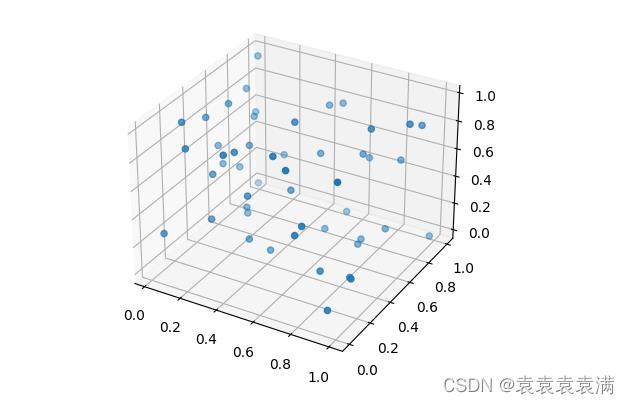
1)三维散点图
3D 散点图是一种显示三个变量之间关系的图表。每个数据点用一个点表示,并且其位置取决于三个变量的值:
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
# 生成数据
x = np.random.rand(50)
y = np.random.rand(50)
z = np.random.rand(50)
# 绘制 3D 散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z)
# 显示图像
plt.show()
运行结果:
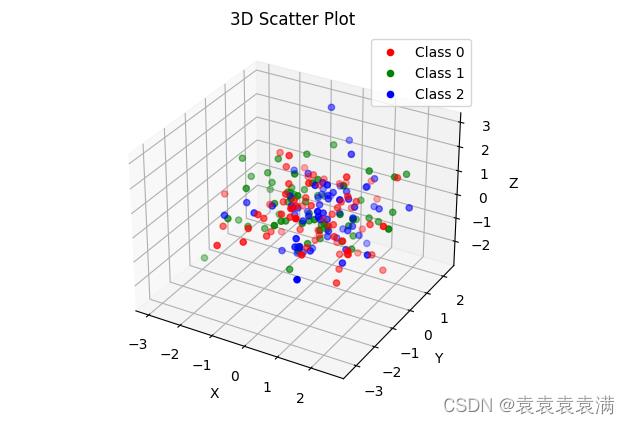
2)三维分类散点图
以下是一个基于matplotlib绘制好看的三维分类散点图的示例代码及其说明:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 生成数据
num = 200
X = np.random.randn(num, 3)
y = np.random.randint(0, 3, num)
# 创建3D图像
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 设置颜色列表
colors = ['r', 'g', 'b']
# 绘制散点图
for i in range(3):
ax.scatter(X[y==i, 0], X[y==i, 1], X[y==i, 2], c=colors[i], label='Class %d' % i)
# 设置图像标题和坐标轴标签
ax.set_title('3D Scatter Plot')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
# 添加图例
ax.legend()
# 显示图像
plt.show()
代码说明:
首先,生成200个三维数据点X和它们的类别标签y,类别标签取值为0、1、2。
然后,创建一个3D图像,其中projection参数设置为'3d'表示创建一个三维图像。定义一个颜色列表colors,用来表示不同类别的颜色。
接着,使用for循环遍历每个类别,对于每个类别,使用ax.scatter()方法绘制散点图。其中,X[y==i, 0]表示取出类别为i的所有数据点在X坐标轴上的值,X[y==i, 1]和X[y==i, 2]分别表示在Y和Z坐标轴上的值。c参数设置为colors[i],表示使用颜色列表中第i个颜色来绘制该类别的数据点。label参数设置为'Class %d' % i,表示在图例中显示该类别的标签。
设置图像标题和坐标轴标签,使用ax.set_title()、ax.set_xlabel()、ax.set_ylabel()和ax.set_zlabel()方法。
添加图例,使用ax.legend()方法。
显示图像,使用plt.show()方法。
这段代码可以生成一个三维分类散点图,其中不同类别的数据点用不同的颜色表示,图例中显示了每个类别的标签。可以根据需要对数据和图像进行修改,以符合具体的需求。
运行结果:
3)三维波浪分类散点图
下面代码展示了三个类别的散点图,其中每个点的颜色代表其所属的类别。我们可以看到,类别1的数据分布在x轴和y轴的中心,类别2的数据分布在x轴和y轴的右上角,类别3的数据分布在x轴和y轴的左上角。在z轴方向,所有的数据都呈现出波浪形状:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 生成三个类别的随机数据
np.random.seed(42)
n = 100
x1 = np.random.normal(0, 1, n)
y1 = np.random.normal(0, 1, n)
z1 = np.sin(np.sqrt(x1**2 + y1**2)) / (np.sqrt(x1**2 + y1**2))
x2 = np.random.normal(2, 1, n)
y2 = np.random.normal(2, 1, n)
z2 = np.sin(np.sqrt(x2**2 + y2**2)) / (np.sqrt(x2**2 + y2**2))
x3 = np.random.normal(-2, 1, n)
y3 = np.random.normal(2, 1, n)
z3 = np.sin(np.sqrt(x3**2 + y3**2)) / (np.sqrt(x3**2 + y3**2))
# 使用了正态分布和三角函数来生成数据。x1、y1、z1代表类别1的数据,x2、y2、z2代表类别2的数据,x3、y3、z3代表类别3的数据
X = np.vstack((np.hstack((x1, x2, x3)),
np.hstack((y1, y2, y3)),
np.hstack((z1, z2, z3)))).T
# 将数据合并到一个数组中,并为每个类别设置不同的颜色
colors = np.vstack((np.zeros((n, 1)), np.ones((n, 1)), np.ones((n, 1)) * 2))
# 使用3D坐标系来绘制散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=colors.ravel())
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
文章目录
每篇前言
-
以上是关于100天精通Python(可视化篇)——第82天:matplotlib绘制不同种类炫酷散点图参数说明+代码实战(二维散点图三维散点图散点图矩阵)的主要内容,如果未能解决你的问题,请参考以下文章