Android开源实战:手把手带你实现一个简单好用的搜索框(含历史搜索记录)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android开源实战:手把手带你实现一个简单好用的搜索框(含历史搜索记录)相关的知识,希望对你有一定的参考价值。
参考技术A一款 封装了 历史搜索记录功能 & 样式 的 android 自定义搜索框
根据场景,梳理出来的功能业务流程图如下:
根据功能的业务流程图,得出功能需求如下
下面,将根据功能需求给出特定的技术解决方案
下面将给出详细的功能逻辑
分析1:EditText_Clear.java
对于含有一键清空功能 & 更多自定义样式的EditText自定义控件 具体请看我的另外一个简单 & 好用的开源组件: Android自定义EditText:手把手教你做一款含一键删除&自定义样式的SuperEditText
分析2:SearchListView.java
分析3: search_layout.xml
分析4:ICallBack.java、bCallBack.java
分析5:SearchView.java
分析1:RccordSQLiteOpenHelper.java
分析2:SearchView.java
不定期分享关于 安卓开发 的干货,追求 短、平、快 ,但 却不缺深度 。
CenterNet2实战:手把手带你实现使用CenterNet2训练自定义数据集
1、CenterNet2 介绍
论文地址:https://arxiv.org/abs/2103.07461
GitHub地址:https://github.com/xingyizhou/CenterNet2
CenterNet的原作者提出了一个概率性的两阶段检测器, 这种解释激发了强大的第一阶段的使用,该阶段学习估计对象可能性而不是最大化召回。 然后将这些可能性与来自第二阶段的分类分数相结合,以产生最终检测的原则概率分数。 概率两级检测器比一级或两级检测器更快、更准确,作者将其命名为CenterNet2。CenterNet2包含多个模型,COCO成绩最高达到56.4mPA,超越了ScaledYOLOV4,成为现阶段最强的物体检测模型。

这个模型是在Detectron2上开发的,版本是2.3。如果是初次使用需要了解一下Detectron2。
2、Detectron2介绍
Detectron2 前身就是鼎鼎大名的 Detectron,其实Detectron可以说是Facebook第一代检测工具箱。Detectron2 不仅支持 Detectron已有的目标检测、实例分割、姿态估计等任务,还支持语义分割和全景分割。
优点如下:
基于PyTorch:PyTorch可以提供更直观的命令式编程模型,开发者可以更快的进行迭代模型设计和实验。
模块化、可扩展:从Detectron2开始,Facebook引入了模块化设计,允许用户将自定义模块插入目标检测系统的几乎任何部分。这意味着许多新的研究项目和核心Detectron2库可以完全分开。其可扩展性也使得Detectron2更加灵活。
支持语义分割和全景分割。
实现质量:从头开始重写推出的Detectron2,使得能够重新审视低级设计决策并解决了原始Detectron中的几个实现问题。
速度和可扩展性:Detectron2比原始Detectron更快,而且可以更加方便进行GPU服务器的分布式训练。
Detectron2go:新增了将模型产品化部署的软件实现,包括标准的内部数据训练工作流实现、模型压缩量化、模型转化等。
总之,我们使用Detectron2很方便的实现模型的训练、测试以及模型转换。所以现在很多的新模型都是在Detectron2开发。
3、搭建CenterNet2 测试环境
我本地环境:
操作系统:win10、Cuda11.0。
3.1 创建虚拟环境
创建虚拟环境,并激活环境。
conda create --name centernet2 python=3.7
activate centernet2
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
3.2 安装apex
APEX是英伟达开源的,完美支持PyTorch框架,用于改变数据格式来减小模型显存占用的工具。其中最有价值的是amp(Automatic Mixed Precision),将模型的大部分操作都用Float16数据类型测试,一些特别操作仍然使用Float32。并且用户仅仅通过三行代码即可完美将自己的训练代码迁移到该模型。实验证明,使用Float16作为大部分操作的数据类型,并没有降低参数,在一些实验中,反而由于可以增大Batch size,带来精度上的提升,以及训练速度上的提升。
3.2.1 下载apex
网址 https://github.com/NVIDIA/apex,下载到本地文件夹。解压后进入到apex的目录安装依赖。在执行命令;
cd C:\\Users\\WH\\Downloads\\apex-master #进入apex目录
pip install -r requirements.txt
3.2.2 安装apex
依赖安装完后,打开cmd,cd进入到刚刚下载完的apex-master路径下,运行:
python setup.py install
然后跑了一堆东西,最后是这样的:

安装完成!
3.3 安装fvcore
fvcore库的简介
fvcore是一个轻量级的核心库,它提供了在各种计算机视觉框架(如Detectron2)中共享的最常见和最基本的功能。这个库基于Python 3.6+和PyTorch。这个库中的所有组件都经过了类型注释、测试和基准测试。Facebook 的人工智能实验室即FAIR的计算机视觉组负责维护这个库。
github地址:https://github.com/facebookresearch/fvcore
执行命令
conda install -c fvcore -c iopath -c conda-forge fvcore
3.4 安装其他的库
安装pycocotools
pip install pycocotools
安装cv2
pip install opencv-python
安装 antlr4
pip install antlr4-python3-runtime
安装future
pip install future
安装protobuf
pip install protobuf
安装absl
pip install absl-py
3.5 编译CenterNet2
进入CenterNet2目录,目录根据自己的实际情况更改
cd D:\\CenterNet2-master
编译
python setup.py install
4、测试环境
新建imgs和imgout文件夹,imgs文件夹存放待测试的图片。
图片如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ymnqnmPL-1632828249507)(https://gitee.com/wanghao1090220084/images/raw/master/img/image-20210928095744639.png)]
下载模型“CenterNet2_R50_1x.pth”(注:作者将模型放到谷歌的网盘上,这个国内访问不了,如果不能下载,关注我的公众号获取连接。),将其放到“projects/CenterNet2”目录下面。
执行命令:
python projects/CenterNet2/demo.py --config-file projects/CenterNet2/configs/CenterNet2_R50_1x.yaml --input imgs/ --output imgout --opts MODEL.WEIGHTS projects/CenterNet2/CenterNet2_R50_1x.pth
运行结果:

能够运行demo说明环境已经没有问题了。
5、制作数据集
本次采用的数据集是Labelme标注的数据集,地址:链接:https://pan.baidu.com/s/1nxo9-NpNWKK4PwDZqwKxGQ 提取码:kp4e,需要将其转为COCO格式的数据集。转换代码如下:
新建labelme2coco.py
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
REQUIRE_MASK = False
labels = {'aircraft': 1, 'oiltank': 2}
class labelme2coco(object):
def __init__(self, labelme_json=[], save_json_path='./new.json'):
'''
:param labelme_json: the list of all labelme json file paths
:param save_json_path: the path to save new json
'''
self.labelme_json = labelme_json
self.save_json_path = save_json_path
self.images = []
self.categories = []
self.annotations = []
# self.data_coco = {}
self.label = []
self.annID = 1
self.height = 0
self.width = 0
self.require_mask = REQUIRE_MASK
self.save_json()
def data_transfer(self):
for num, json_file in enumerate(self.labelme_json):
if not json_file == self.save_json_path:
with open(json_file, 'r') as fp:
data = json.load(fp)
self.images.append(self.image(data, num))
for shapes in data['shapes']:
print("label is ")
print(shapes['label'])
label = shapes['label']
# if label[1] not in self.label:
if label not in self.label:
print("find new category: ")
self.categories.append(self.categorie(label))
print(self.categories)
# self.label.append(label[1])
self.label.append(label)
points = shapes['points']
self.annotations.append(self.annotation(points, label, num))
self.annID += 1
def image(self, data, num):
image = {}
img = utils.img_b64_to_arr(data['imageData'])
height, width = img.shape[:2]
img = None
image['height'] = height
image['width'] = width
image['id'] = num + 1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height = height
self.width = width
return image
def categorie(self, label):
categorie = {}
categorie['supercategory'] = label
# categorie['supercategory'] = label
categorie['id'] = labels[label] # 0 默认为背景
categorie['name'] = label
return categorie
def annotation(self, points, label, num):
annotation = {}
print(points)
x1 = points[0][0]
y1 = points[0][1]
x2 = points[1][0]
y2 = points[1][1]
contour = np.array([[x1, y1], [x2, y1], [x2, y2], [x1, y2]]) # points = [[x1, y1], [x2, y2]] for rectangle
contour = contour.astype(int)
area = cv2.contourArea(contour)
print("contour is ", contour, " area = ", area)
annotation['segmentation'] = [list(np.asarray([[x1, y1], [x2, y1], [x2, y2], [x1, y2]]).flatten())]
# [list(np.asarray(contour).flatten())]
annotation['iscrowd'] = 0
annotation['area'] = area
annotation['image_id'] = num + 1
if self.require_mask:
annotation['bbox'] = list(map(float, self.getbbox(points)))
else:
x1 = points[0][0]
y1 = points[0][1]
width = points[1][0] - x1
height = points[1][1] - y1
annotation['bbox'] = list(np.asarray([x1, y1, width, height]).flatten())
annotation['category_id'] = self.getcatid(label)
annotation['id'] = self.annID
return annotation
def getcatid(self, label):
for categorie in self.categories:
# if label[1]==categorie['name']:
if label == categorie['name']:
return categorie['id']
return -1
def getbbox(self, points):
polygons = points
mask = self.polygons_to_mask([self.height, self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
return [left_top_c, left_top_r, right_bottom_c - left_top_c, right_bottom_r - left_top_r]
def polygons_to_mask(self, img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco = {}
data_coco['images'] = self.images
data_coco['categories'] = self.categories
data_coco['annotations'] = self.annotations
return data_coco
def save_json(self):
print("in save_json")
self.data_transfer()
self.data_coco = self.data2coco()
print(self.save_json_path)
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4)
labelme_json = glob.glob('LabelmeData/*.json')
from sklearn.model_selection import train_test_split
trainval_files, test_files = train_test_split(labelme_json, test_size=0.2, random_state=55)
import os
if not os.path.exists("projects/CenterNet2/datasets/coco/annotations"):
os.makedirs("projects/CenterNet2/datasets/coco/annotations/")
if not os.path.exists("projects/CenterNet2/datasets/coco/train2017"):
os.makedirs("projects/CenterNet2/datasets/coco/train2017")
if not os.path.exists("projects/CenterNet2/datasets/coco/val2017"):
os.makedirs("projects/CenterNet2/datasets/coco/val2017")
labelme2coco(trainval_files, 'projects/CenterNet2/datasets/coco/annotations/instances_train2017.json')
labelme2coco(test_files, 'projects/CenterNet2/datasets/coco/annotations/instances_val2017.json')
import shutil
for file in trainval_files:
shutil.copy(os.path.splitext(file)[0] + ".jpg", "projects/CenterNet2/datasets/coco/train2017/")
for file in test_files:
shutil.copy(os.path.splitext(file)[0] + ".jpg", "projects/CenterNet2/datasets/coco/val2017/")
6、配置训练环境
6.1 更改预训练模型的size
在projects/CenterNet2目录,新建change_model_size.py文件
import torch
import numpy as np
import pickle
num_class = 2
pretrained_weights = torch.load('models/CenterNet2_R50_1x.pth')
pretrained_weights['iteration']=0
pretrained_weights['model']["roi_heads.box_predictor.0.cls_score.weight"].resize_(num_class+1,1024)
pretrained_weights['model']["roi_heads.box_predictor.0.cls_score.bias"].resize_(num_class+1)
pretrained_weights['model']["roi_heads.box_predictor.1.cls_score.weight"].resize_(num_class+1,1024)
pretrained_weights['model']["roi_heads.box_predictor.1.cls_score.bias"].resize_(num_class+1)
pretrained_weights['model']["roi_heads.box_predictor.2.cls_score.weight"].resize_(num_class+1,1024)
pretrained_weights['model']["roi_heads.box_predictor.2.cls_score.bias"].resize_(num_class+1)
torch.save(pretrained_weights, "models/CenterNet2_%d.pth"%num_class)
这个文件的目的是修改模型输出的size,numclass按照本次打算训练的数据集的类别设置。
6.2 修改config参数
路径:“detectron2/engine/defaults.py”
–config-file:模型的配置文件,CenterNet2的模型配置文件放在“projects/CenterNet2/configs”下面。名字和预训练模型对应。
parser.add_argument("--config-file", default="./configs/CenterNet2_DLA-BiFPN-P3_4x.yaml", metavar="FILE", help="path to config file")
resume 是否再次,训练,如果设置为true,则接着上次训练的结果训练。所以第一次训练不用设置。
parser.add_argument(
"--resume",
action="store_true",
help="Whether to attempt to resume from the checkpoint directory. "
"See documentation of `DefaultTrainer.resume_or_load()` for what it means.",
)
–num-gpus,gpu的个数,如果只有一个设置为1,如果有多个,可以自己设置想用的个数。
parser.add_argument("--num-gpus", type=int, default=1, help="number of gpus *per machine*")
opts指的是yaml文件的参数。
上面的参数可以设置,也可以不设置,设置之后可以直接运行不用再考虑设置参数,如果不设置每次训练的时候配置一次参数。
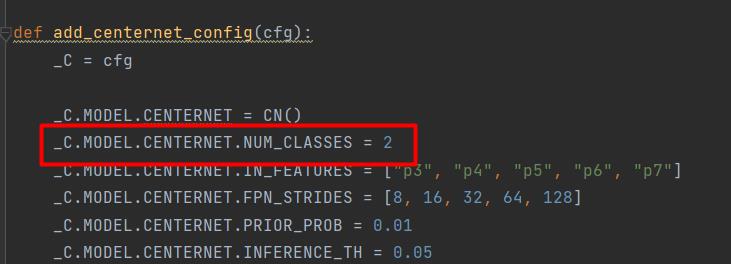
修改类别,文件路径“projects/CenterNet2/centernet/config.py”,
_C.MODEL.CENTERNET.NUM_CLASSES = 2
修改yaml文件参数
Base-CenterNet2.yaml中修改预训练模型的路径。
WEIGHTS: "CenterNet2_2.pth"
BASE_LR:设置学习率。
STEPS:设置训练多少步之后调整学习率。
MAX_ITER:最大迭代次数。
CHECKPOINT_PERIOD:设置迭代多少次保存一次模型
BASE_LR: 0.01
STEPS: (10000, 50000)
MAX_ITER: 100000
CHECKPOINT_PERIOD: 5000
在设置上面的参数时要注意,如果选择用CenterNet2_R50_1x.yaml,里面没有参数,则在Base-CenterNet2.yaml中设置,如果选用其他的,例如CenterNet2_DLA-BiFPN-P3_4x.yaml,这些参数需要在CenterNet2_DLA-BiFPN-P3_4x.yaml改。
6.3 修改train_net.py
主要修改该setup函数,增加数据集注册。
NUM_CLASSES=2
def setup(args):
"""
Create configs and perform basic setups.
"""
register_coco_instances("train", {}, "datasets/coco/annotations/instances_train2017.json",
"datasets/coco/train2017")
register_coco_instances("test", {}, "datasets/coco/annotations/instances_val2017.json",
"datasets/coco/val2017")
cfg = get_cfg()
add_centernet_config(cfg)
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.DATASETS.TRAIN = ("train",)
cfg.DATASETS.TEST = ("test",)
cfg.MODEL.CENTERNET.NUM_CLASSES = NUM_CLASSES
cfg.MODEL.ROI_HEADS.NUM_CLASSES = NUM_CLASSES
if '/auto' in cfg.OUTPUT_DIR:
file_name = os.path.basename(args.config_file)[:-5]
cfg.OUTPUT_DIR = cfg.OUTPUT_DIR.replace('/auto', '/{}'.format(file_name))
logger.info('OUTPUT_DIR: {}'.format(cfg.OUTPUT_DIR))
cfg.freeze()
default_setup(cfg, args)
return cfg
还要修改detectron2/engine/launch.py,在launch函数下面增加一句
dist.init_process_group('gloo', init_method='file://tmp/somefile', rank=0, world_size=1)
如下图:

这句话的作用是初始化分布式训练,因为我们没有使用分布式,所以没有初始化,但是不初始化就会报错,所以加上这句。
7、训练
两种启动方式:
第一种,命令行:进入“projects/CenterNet2/”目录下,执行:
python train_net.py
第二种,直接在pycharm 直接运行train_net.py.
训练结果:
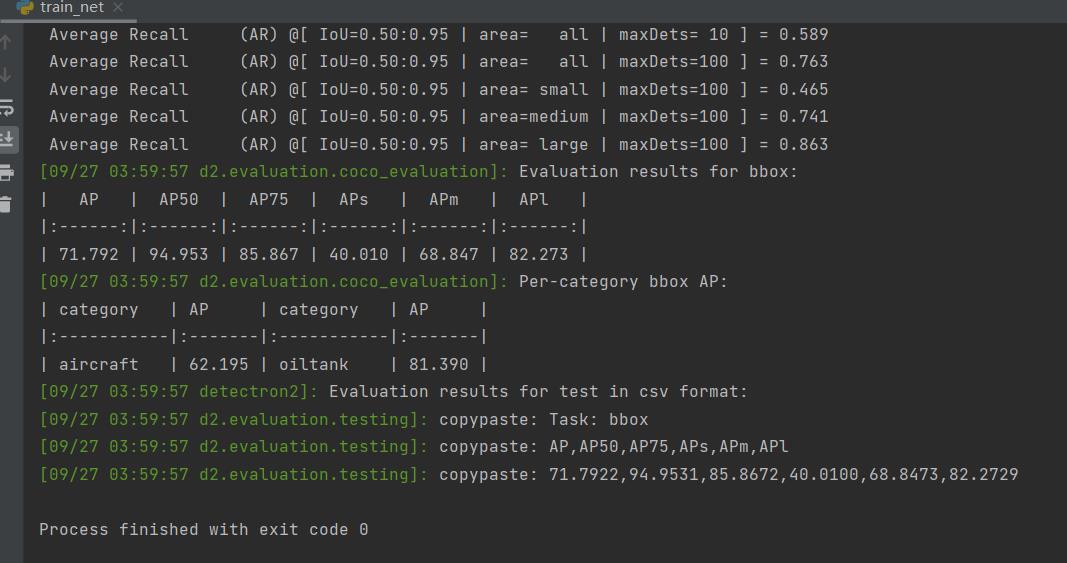
从训练结果上看,效果确实不错,不过模型很大。大约有500M

8、测试
修改projects/CenterNet2/demo.py
8.1 修改setup_cfg函数

在红框的位置增加代码,详细如下面的代码。
NUM_CLASSES=2
def setup_cfg(args):
# load config from file and command-line arguments
cfg = get_cfg()
add_centernet_config(cfg)
cfg.MODEL.CENTERNET.NUM_CLASSES = NUM_CLASSES
cfg.MODEL.ROI_HEADS.NUM_CLASSES = NUM_CLASSES
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
# Set score_threshold for builtin models
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = args.confidence_threshold
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold
if cfg.MODEL.META_ARCHITECTURE in ['ProposalNetwork', 'CenterNetDetector']:
cfg.MODEL.CENTERNET.INFERENCE_TH = args以上是关于Android开源实战:手把手带你实现一个简单好用的搜索框(含历史搜索记录)的主要内容,如果未能解决你的问题,请参考以下文章
『Python开发实战菜鸟教程』实战篇:一文带你了解人脸识别应用原理及手把手教学实现自己的人脸识别项目
『Python开发实战菜鸟教程』实战篇:一文带你了解人脸识别应用原理及手把手教学实现自己的人脸识别项目
『Python开发实战菜鸟教程』实战篇:一文带你了解人脸识别应用原理及手把手教学实现自己的人脸识别项目
『Python开发实战菜鸟教程』实战篇:一文带你了解人脸识别应用原理及手把手教学实现自己的人脸识别项目
『Python开发实战菜鸟教程』实战篇:一文带你了解人脸识别应用原理及手把手教学实现自己的人脸识别项目
微服务开发实战(spring-cloud/spring-cloud-alibaba/dubbo),一个案例,手把手带你入门