爆肝一周——PYTHON 算法基础
Posted 纵横千里,捭阖四方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爆肝一周——PYTHON 算法基础相关的知识,希望对你有一定的参考价值。
国庆期间整理了一篇文章《C/C++ 算法基础》没想到竟然是最近被阅读次数最多的,可见,大部分人还是希望有个扎实的语言基础功底。今天我们就来整理一个python版本的。
如果要真正掌握算法,必须要写代码的,那这时候就必须选择一门语言来进行,而具体的语言其实无所谓 ,C、C++、Java、Python,go甚至javascript、VB都可以,关键是自己要用的熟悉,面试时候能用就可以。同样,由于我们不是语言课程,因此我们主要介绍与算法密切相关的技术问题。后面将继续整理《Java算法基础》,创作不易,如果喜欢,就关注我一下吧!

本文很多内容参考自某top2大学的数据课程讲义,在这里表示感谢。
目录
我们首先要在电脑安装Python环境,这个网上材料一堆,不再赘述。其中Python2和Python3是有比较大差异的,不过我建议你都装上,这样很多代码调试起来更方面。Python 是一种现代化的、易学的、面向对象的编程语言。它拥有一系列强大的内置数据类型和易操作的控制命令。因为Python是一种解释型语言,通过浏览描述交互式会话的方式,你可以很轻松地对它进行复查。打开终端,在解释器显示你熟悉的“>>>”提示并评估你给出的Python结构。如图1.1:

显示了提示,输出(print)函数,结果以及下一个提示。
1. 核心数据类型
我们说过,Python 支持面向对象的编程范式。这意味着Python把数据当做问题解决过程的重点。在Python 里,和很多其他面向对象的编程语言一样,我们定义“类”(class)去描述数据的外观(状态)和功能(行为)。“类”类似于抽象数据类型,“类”的用户只能看到数据项的状态和行为。数据项在面向对象的范式里被称为对象(objects)。对象是类的一个实例。
1.1.python计算
我们将通过讲述Python 中的基本数据类型开始我们的学习。Python 拥有两个主要的内嵌的有关数值的类,用以记录整数和浮点数。这两个Python中的类被称作int和float。而标准的算术运算符,如+,-,*,/和**(乘方),在使用时,可以通过使用括号来改变其运算顺序。其它的一些非常有用的运算符还有取模,用%实现,和地板除,用//实现。注意如果两个整数相除,其数学上的结果是浮点数,而在Python 中,整数类型的除法运算后只显示商的整数部分,截去了它的小数部分。我们可以测试一下:
print(2+3*4)
print((2+3)*4)
print(2**10)
print(6/3)
print(7/3)
print(7//3)
print(7%3)
print(3/6)
print(3//6)
print(3%6)
print(2**100)Python 中用以表达布尔数据类型的bool类,在表达真值的时候非常有用。对于布尔对象,状态 变量的可能值为True 或者False,标准的布尔运算符为and , or, not。我们可以测试一下:
>>> True
True
>>> False
False
>>> False or True
True
>>> not (False or True)
False
>>> True and True
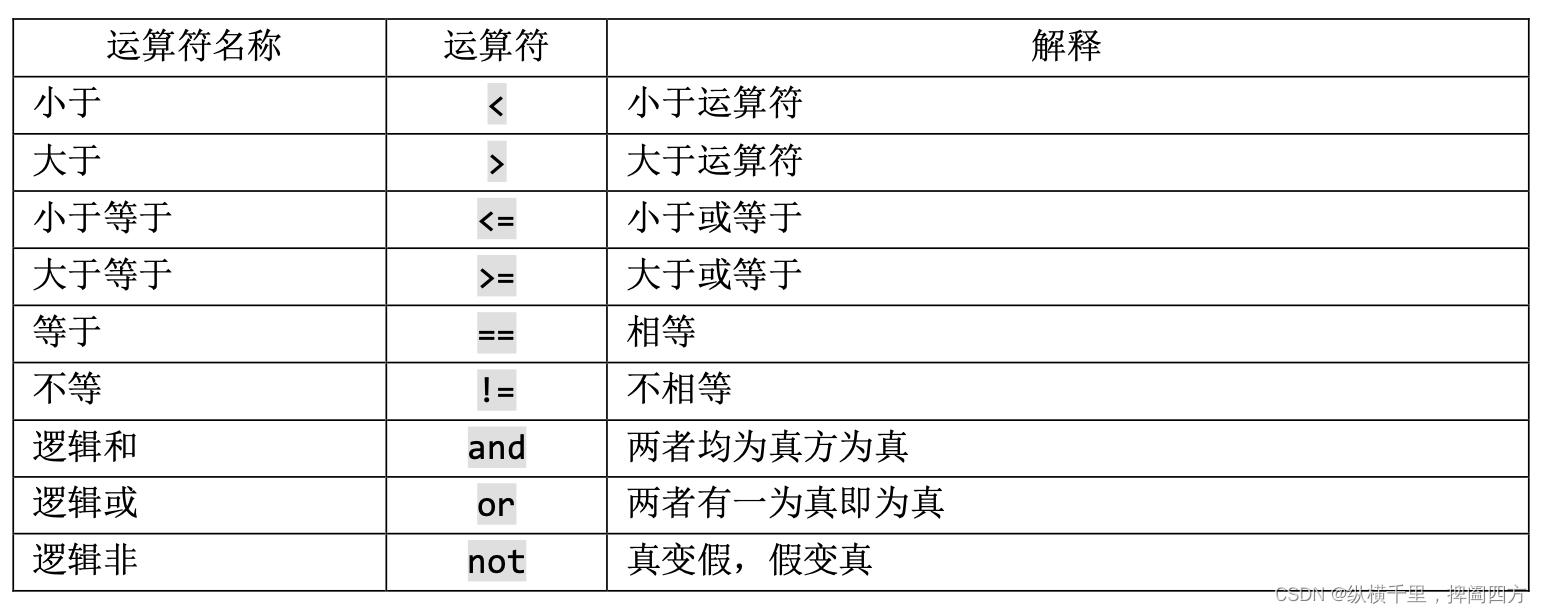
True布尔型的数据对象常常也被用作比较运算例如等于(==),大于(>)的结果表示。此外,关系运算符和逻辑运算符可以被组合起来解决更复杂的逻辑问题。下图中展示了关系算子与逻辑运算符,并在其后对其作用进行了举例说明。如下图1.2所示。
测试:
print(5==10)
print(10 > 5)
print((5 >= 1) and (5 <= 10))标识符就是程序语言中被用来表示名称的符号。在Python 中,标识符以字母或下划线(_)作为开始,大小写敏感,并且可以是任意长度。需要注意的是在命名的时候应该选择有意义的名称, 这样才能使你的程序变得更加容易阅读和理解。
在Python 中,当一个名字第一次被用在了赋值语句的左边时,一个变量就随之产生了。赋值语句提供了联系标识符与值的途径。变量会持有一个对数据的引用,而并不是数据本身。参见下面的 测试:
先输入:
>>> theSum = 0
再输入:
>>> theSum
输出结果:
0
先输入:
>>> theSum = theSum + 1
再输入:
>>> theSum
输出结果:
1
先输入:
>>> theSum = True
再输入:
>>> theSum
输出结果:
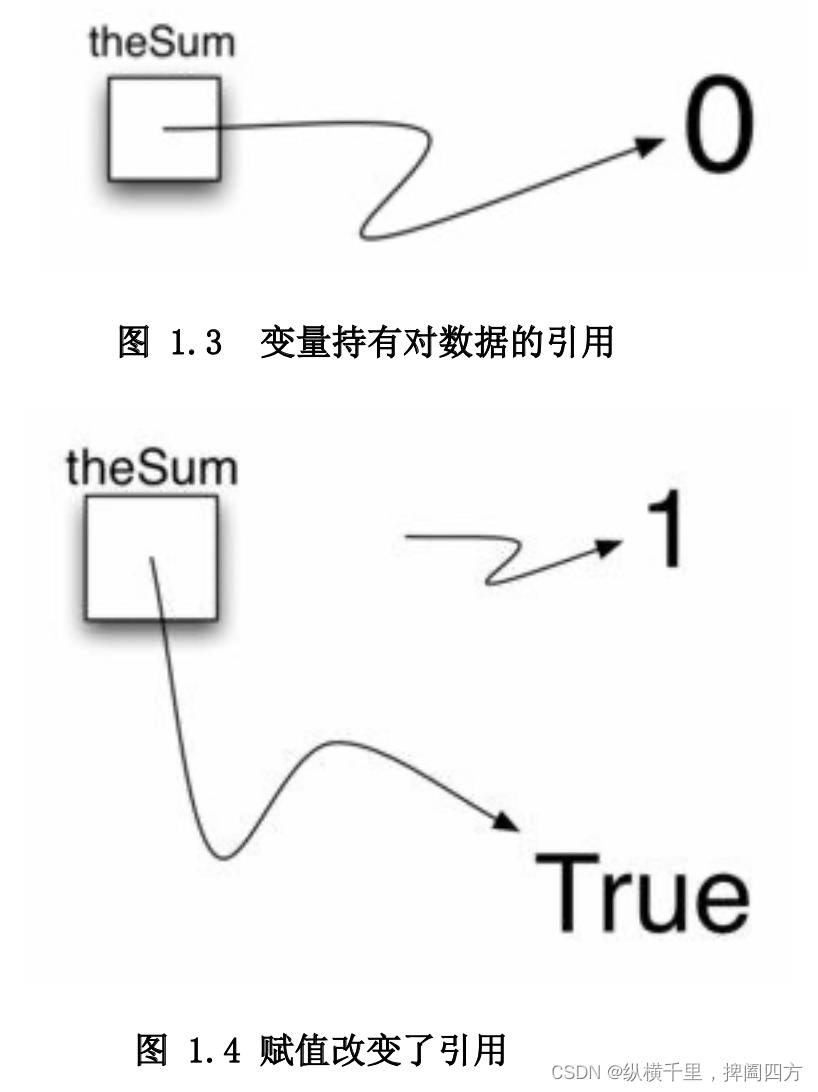
True赋值语句theSum = 0 创建了一个名为theSum 的变量,并且使该变量持有对数据对象0的引用 (见下图1.3)。一般来说(如第二个例子),赋值语句的右半部分会经过求值运算,并把对最终结果的引用派给左边的标识符。在我们的例子中,变量及以theSum指向的数据的类型本来是整型,如果数据类型变了(见图1.4)比如上面例子里被赋了一个Bool 型的值True,那么变量类型也改变(即theSum也为不ool型)。这就说明,在Python 中,如果赋值的数据类型变了,那么变量的类型也会跟着改变。赋值语句改变的是变量所执的引用,这是Python极其灵活的一个特征,所以一个变量可 以指向许多种类型的数据。
1.2 集合数据类型
除了数值和布尔这两个类,Python还拥有一系列的强大的内嵌的数据容器。列表,字符串和元组都是有序容器,并且在结构上大致相似,但是分别拥有一些在应用中需要去好好理解的特别的属性。字典和集合则都是无序容器。
一个列表是包含零个或多个对Python 中数据的引用的有序容器。列表用方括号括起,里面的每个数据用逗号隔开。空的列表是[]。列表是异质的,这意味着列表中的数据不必要同一个类,并且列表可以像下面展示的那样被派给一个变量。第一个例子展示了列表中Python 数据的多种多样。
>>> [1,3,True,6.5]
[1, 3, True, 6.5]
>>> myList = [1,3,True,6.5]
>>> myList
[1, 3, True, 6.5]注意到当Python中给一个列表赋值后,这个列表会被返回。那么为了记录下这个列表以备后 用,我们应该将它的引用值传给一个变量。
因为列表是有序的,所以它支持一系列也可以被用在任何Python 中的序列的运算符。表1.2展 示并给出了它们的作用:
对任何Python序列均有用的运算符如下:
| 名称 | 运算符 | 含义 |
| 索引 | [] | 指向序列中的第一个元素 |
| 连接 | + | 组合序列 |
| 重复 | * | 重复该序列 |
| 是否在其中 | in | 查询该元素是否在序列中 |
| 长度 | len | 获取序列长度 |
| 切片 | [:] | 切片操作 |
考虑到列表(序列)从0开始数起,切片操作myList[1:3],会返回从下标为1到下标为3(但不 包含3)的项目。
有时,你想要创建一个列表。这个任务可以用重复操作来快速完成。例如:
>>> myList = [0] * 6
>>> myList
[0, 0, 0, 0, 0, 0]顺便再说一件有关重复操作非常重要的事,就是重复运算的结果是对序列中数据的引用的重 复。这个可以在如下的展示中得到体现:
myList = [1,2,3,4]
A = [myList]*3 print(A)
myList[2]=45
print(A)变量A持有三份对原始名为mylist的序列的引用。注意在对mylist中的元素进行改变后,这种改变体现在了A中。
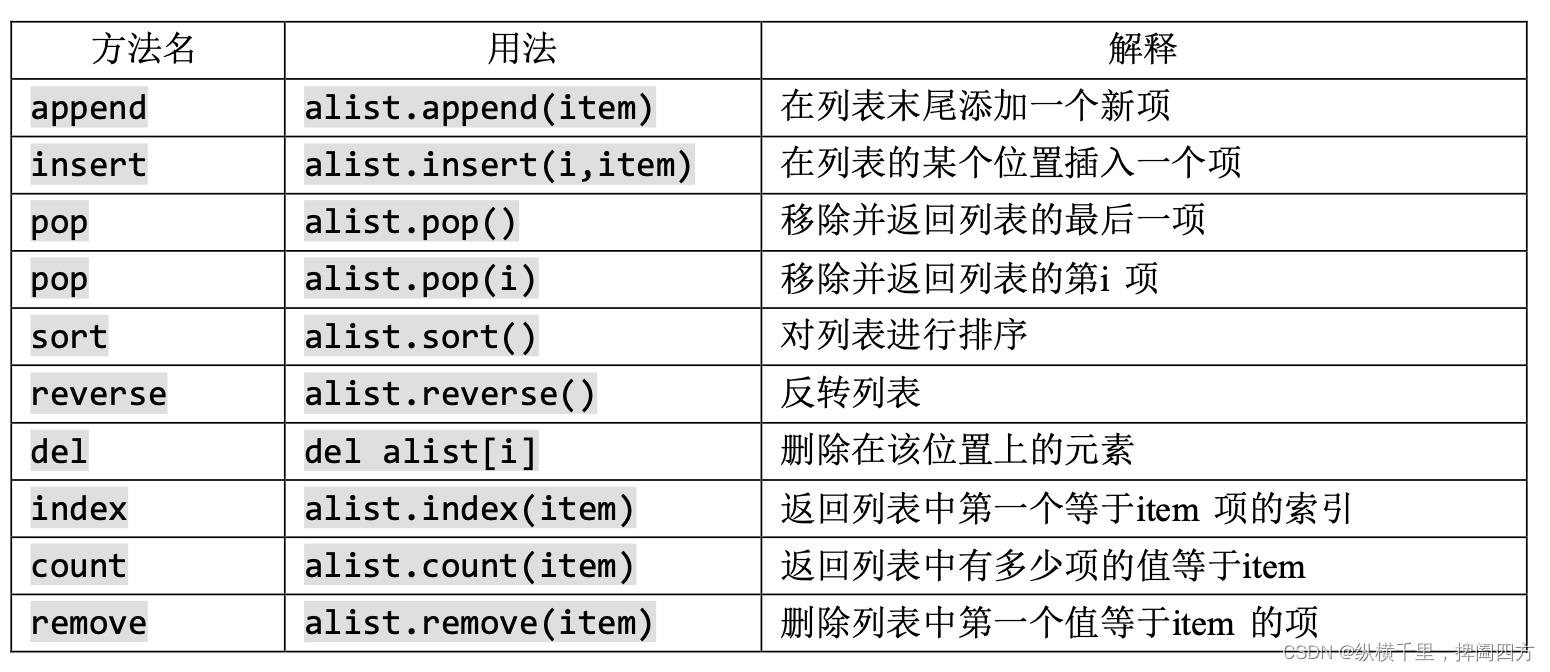
列表提供了一系列的用来构建数据结构的方法。下表提供了一个总结,关于它们的用法在之后的例子中呈现:
我们看几个使用的例子:
myList = [1024, 3, True, 6.5]
myList.append(False)
print(myList)
myList.insert(2,4.5)
print(myList)
print(myList.pop())
print(myList)
print(myList.pop(1))
print(myList)
你可以看到一些方法,例如pop,返回了一个值并且同时修改了列表。其他的,像reverse,只是 修改了列表没有返回值,pop默认处理最后一项,但也可以返回一个指定的元素并把它删去。使用这 些类函数时,要注意下标也是从0开始的。你也会注意到熟悉的“.”符号,它用于让这个对象调用某个 方法。myList.append(False)可以读作“使对象myList去执行append方法函数并给它一个值False”。就连 最简单的例如整数的数据体以这个方式都可以调用方法函数。
>>> (54).__add__(21)
75
>>>如上,我们让整数54执行名为“add”的方法函数(在Python中被称作__add__)然后将21作为值给 add,结果就是它们的和75。当然我们一般写54+21。我们会在这节后面讲解更多关于方法的知识。
还有一个python中的与list相关的常用功能那就是range。range 产生了一个有顺序的对象,这个 对象可以表示一个序列。在使用list里的功能时,可以将range对象里的值视为一个列表。下面是关于 它的阐释:
>>> range(10)
range(0, 10)
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(5,10)
range(5, 10)
>>> list(range(5,10))
[5, 6, 7, 8, 9]
>>> list(range(5,10,2))
[5, 7, 9]
>>> list(range(10,1,-1))
[10, 9, 8, 7, 6, 5, 4, 3, 2]
>>>对象 range 代表了一个整数的序列。默认会从 0 开始。如果你提供更多的参数,它可以从特定的 点开始和结束,甚至可以跳过一些数。在第一个例子中,range(10), 这个序列从 0 开始到 10 却不包 含 10。在第二个例子中,range(5,10) 从 5 开始到 10 却不包含 10,range(5,10,2)与上述例子类 似,但是每两个数之间相差 2(不包含 10)。
字符串是可以储存零个或多个字母,数字,或其他符号的有序容器。我们称字母,数字和其他 的符号为字符。字符串的值用引号(单引号和双引号都可以,但不能混用)与标识符区分。
>>> "David"
'David'
>>> myName = "David"
>>> myName[3]
'i'
>>> myName*2 'DavidDavid'
>>> len(myName)
5
>>>因为字符串是序列,所以所有之前提及的对序列的操作都适用。另外,字符串也有它的一系列 方法,一部分被展现在下表里,例如:
| 方法名 | 方法名 | 功能 |
| center | astring.center(w) | 返回一个字符串,w 长度,原字符串居中 |
| count | astring.count(item) | 返回原字符串中出现item 的次数 |
| ljust | astring.ljust(w) | 返回一个字符串,w 长度,原字符串居左 |
| lower | astring.lower() | 返回一个字符串,全部小写 |
| rjust | astring.rjust(w) | 返回一个字符串,w 长度,原字符串居右 |
| find | astring.find(item) | 查询item,返回第一个匹配的索引位置 |
| split | astring.split(schar) | 以schar 为分隔符,将原字符串分割,返回一个 列表 |
字符串和列表之间最大的区别就是列表可以被修改而字符串不能。这被称作可变性。列表是可变的,字符串是不可变的。比如,你可以通过赋值和索引改变一个列表中的元素,而对于字符串这 种操作是不允许的。
>>> myList
[1, 3, True, 6.5]
>>> myList[0]=2**10
>>> myList
[1024, 3, True, 6.5]
>>>
>>> myName
'David'
>>> myName[0]='X'
Traceback (most recent call last):
File "<pyshell#84>", line 1, in -toplevel- myName[0]='X'
TypeError: object doesn't support item assignment
>>>元组 tuple 和列表 list 类似,也是异质数据序列容器,区别是,tuple 不可改变其中数据,就像字符串。元表不可被修改。元表表示为用圆括号括起的,用逗号隔开的一系列值。当然,作为一个序列,它也适用于上述的关于序列的运算符,例如 :
>>> myTuple = (2,True,4.96) >>> myTuple
(2, True, 4.96)
>>> len(myTuple)
3
>>> myTuple[0]
2
>>> myTuple * 3
(2, True, 4.96, 2, True, 4.96, 2, True, 4.96)
>>> myTuple[0:2]
(2, True)
>>>但是,如果你试图改变元组里的一个元素,马上就会报错。注意有关 error 的消息中会包含问题的位置和原因。
>>> myTuple[1]=False Traceback (most recent call last):
File "<pyshell#137>", line 1, in -toplevel- myTuple[1]=False
TypeError: object doesn't support item assignment
>>>集合是 0 个或多个数据的无序散列容器。集合不允许出现重复元素,表示为花括号括起的、用逗号隔开的一系列值。空的集合表示为 set()。集合是异质的,并且集合是可变的。例如:
>>> 3,6,"cat",4.5,False
False, 4.5, 3, 6, 'cat'
>>> mySet = 3,6,"cat",4.5,False >>> mySet
False, 4.5, 3, 6, 'cat'尽管集合是无序的,它仍然支持一些与之前所示的其他容器相类似的操作,下表总结了这些操作, 并且之后给出了如何使用这些操作的具体例子:
| 运算 | 举例 | 解释 |
| 属于关系 | in | 判断一个元素是否属于这个集合 |
| 元素数目 | len | 返回值是集合中元素的数目 |
| |(并集) | 集合 A | 集合B | 返回一个新集合,这个集合是集合A,B 的并集 |
| &(交集) | 集合 A & 集合B | 返回一个新集合,这个集合只有集合A,B 共有的 元素,是集合A,B 的交集 |
| - | 集合 A – 集合B | 返回一个新集合,这个集合是集合A 除去A 与B 共有的元素(A-(A∩B)) |
| <= | 集合 A <= 集合B | 判断集合A 中的所有元素是否都在集合B 中,返 回布尔值 True 或者False |
>>> mySet
False, 4.5, 3, 6, 'cat'
>>> len(mySet)
5
>>> False in mySet True
>>> "dog" in mySet False
>>>集合提供了许多方法,用于实现一些数学操作,下表大致列举了一些这样的函数,之后也有 一些使用实例。注意,union, intersection, issubset 和 difference 这些函数的功能也可用上述 在表五中出现的运算符代替。
| 函数名 | 使用方法 | 说明 |
| union | A.union(B) | 集合A,B 的并集 |
| intersection | A.intersection(B) | 集合A,B 的交集 |
| difference | A.difference(B) | 就是(A-(A∩B)) |
| issubset | A.issubset(B) | A是否为B的子集 |
| add | A.add(item) | 将item加到A中 |
| remove | A.remove(item) | 从A中移除item |
使用的例子:
>>> mySet
False, 4.5, 3, 6, 'cat'
>>> yourSet = 99,3,100
>>> mySet.union(yourSet)
False, 4.5, 3, 100, 6, 'cat', 99
>>> mySet | yourSet
False, 4.5, 3, 100, 6, 'cat', 99
>>> mySet.intersection(yourSet) 3
>>> mySet & yourSet
3
>>> mySet.difference(yourSet)
False, 4.5, 6, 'cat'
>>> mySet - yourSet
False, 4.5, 6, 'cat'
>>> 3,100.issubset(yourSet)
True
>>> 3,100<=yourSet
True
>>> mySet.add("house")
>>> mySet
False, 4.5, 3, 6, 'house', 'cat'
>>> mySet.remove(4.5)
>>> mySet
False, 3, 6, 'house', 'cat'
>>> mySet.pop()
False
>>> mySet
3, 6, 'house', 'cat'
>>> mySet.clear()
>>> mySet
set()
>>>介绍的最后一种 Python 的数据类型是字典,字典是由许多对相互之间有联系的元素组成的, 每对都包含一个键(key)和一个值(value)。这种元素对被称为键值对,一般记作键:值(key: value)。字典的表示方法是,大括号内若干对键值对排列在一起,它们之间用逗号隔开。 举个例子:
>>> capitals = 'Iowa':'DesMoines','Wisconsin':'Madison'
>>> capitals
'Wisconsin': 'Madison', 'Iowa': 'DesMoines'
>>>我们可以通过元素的键来获取它的值,也可以添加另外的键值对来改动字典。“通过键来获取值”这一操作的语法和从序列中读取元素的操作差不多,只不过后者是通过序列下标来获取,而前者是通过键获取。添加新元素也是类似的,序列中添加一个新元素,要增加 一个下标,而字典则是增加一个键值对。
>>> capitals = 'Iowa':'DesMoines','Wisconsin':'Madison'
>>> print(capitals['Iowa']) DesMoines
>>> capitals['Utah']='SaltLakeCity'
>>> print(capitals)
'Wisconsin': 'Madison', 'Utah': 'SaltLakeCity', 'Iowa': 'DesMoines'
>>> capitals['California']='Sacramento' >>> print(len(capitals))
4
>>> for k in capitals:
print(capitals[k]," is the capital of ", k)
('Madison', ' is the capital of ', 'Wisconsin') ('SaltLakeCity', ' is the capital of ', 'Utah') ('DesMoines', ' is the capital of ', 'Iowa') ('Sacramento', ' is the capital of ', 'California')切记,字典型对于键(key)的存储是没有特定的顺序的,如上例中,第一个添加的键值对
( )被放在了字典中的第一个位置,而第二个添加的键值对
( )被放在了最后一个位置。关于键的摆放位置实际上是和“散列 法”这一概念有关,这会在第四章中详细论述。在上例中我们也展示了 length 函数,它和之前几 种数据类型一样, 可以用来求字典中所含键值对的数目。
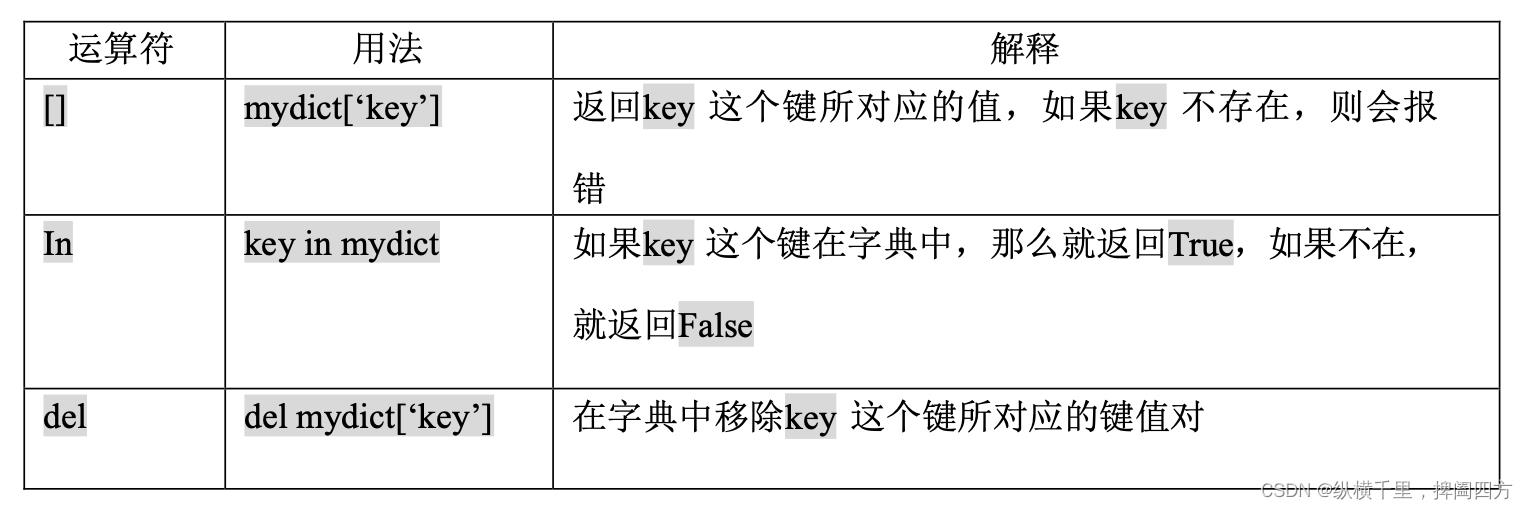
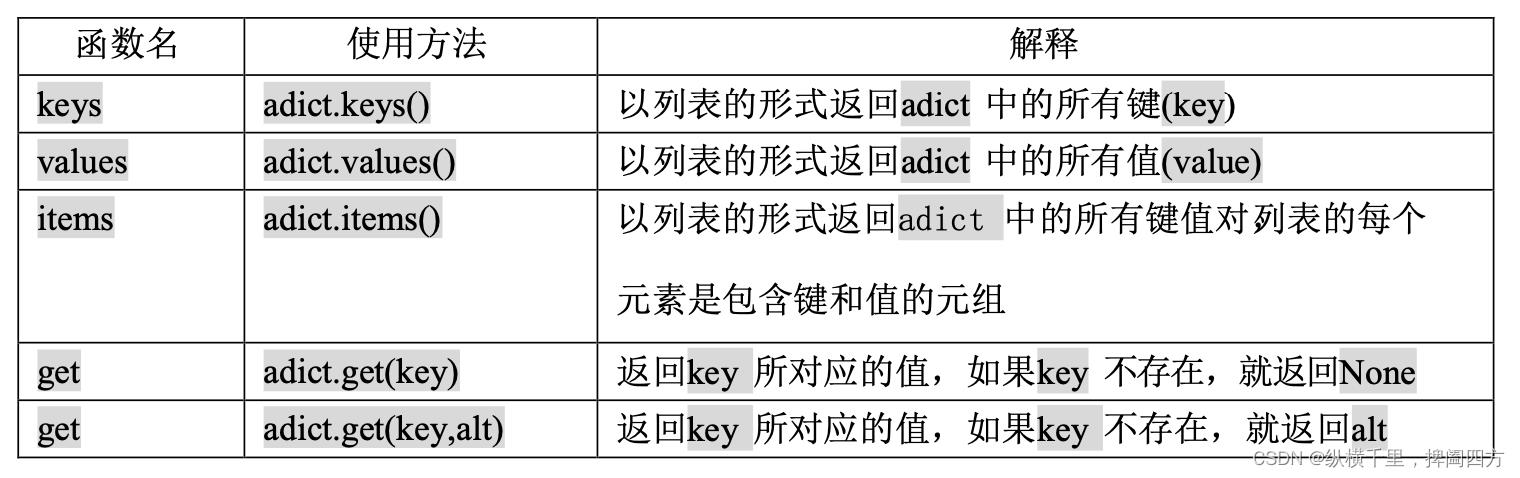
字典可以通过函数和运算符来操作。表 1.7 和表 1.8 分别给出了字典中所能使用的运算符, 以及具有类似功能的函数,之后的一段代码给出了它们的实际操作。key,value 和 item 这三个函数分别能够给出字典中所有的键、值、键值对,然后你可以用 list 函数把它们得到的结果转变为列 表。get 函数有两种不同的用法。第一种,如果查找的 key 不在字典中,它就会返回 None;第二 种,加入一个可选参数,如果查找的 key 不在字典中,就返回一个特定的值。Python 中字典运算符操作如下:
使用举例:
>>> phoneext='david':1410,'brad':1137
>>> phoneext
'brad': 1137, 'david': 1410
>>> phoneext.keys()
dict_keys(['brad', 'david'])
>>> list(phoneext.keys())
['brad', 'david']
>>> phoneext.values()
dict_values([1137, 1410])
>>> list(phoneext.values())
[1137, 1410]
>>> phoneext.items()
dict_items([('brad', 1137), ('david', 1410)])
>>> list(phoneext.items())
[('brad', 1137), ('david', 1410)]
>>> phoneext.get("kent")
>>> phoneext.get("kent","NO ENTRY")
'NO ENTRY'
>>>Python 中字典的函数如下:
2 控制逻辑
就像我们前面所说的,算法中有两个重要的控制结构:迭代和选择。Python 支持它们的不同形式,操作者可以选择对于所给问题最有用的表述。
对于迭代结构,Python 提供了一个 while 语句和 for 语句。while 语句可以在循环条件为真的 情况下一直重复循环体。例如:
>>> counter = 1
>>> while counter <= 5:
... print("Hello, world")
... counter = counter + 1
Hello, world
Hello, world
Hello, world
Hello, world
Hello, world重复输出“Hello world”5 次。循环条件在每次循环开始时均会判断,如果判断结果为真,循 环主体将执行。由于强制缩进的格式,我们可以很容易看清楚 Python 中的 while 循环结构。
while 循环语句是一个非常常见的迭代结构,我们将会在很多不同的算法中使用到。在很多情 况下,一个复合条件可以控制迭代结构 。例如 :
while counter <= 10 and not done:
....这段代码中,语句的主体只有在所有的条件都满足的情况下才会执行。变量 counter 的值必须小于或等于10 并且变量 done(布尔型)必须是 False(not False 就是 True),因此真+真=真。
这种类型的结构在各种情况下非常有用。另外一个迭代结构 for 语句可以和许多 Python 容器共同使用。只要这个容器是一个序列容器,for 语句可以遍历该容器的所有元素。例如:
for item in [1,3,6,2,5]:
... print(item)
...
1
3
6
2
5item 依次分配列表中的每个值[1,3,6,2,5]。然后执行迭代的主体。这适用于任何容器(列表、 元组和字符串)。
for 语句的作用是明确迭代值的范围,例如:
>>> for item in range(5):
... print(item**2)
...
0
1
4
9
16
>>>该语句将会执行输出功能 5 次。函数将会返回一系列对象范围代表序列(0,1,2,3,4,),每个值 将分配给变量,然后将其平方后输出。
迭代结构另外一个非常有用的功能是处理字符串的字符。下面的代码片段遍历字符串的每个字 符,并且将字符都添加到列表。结果是含有所有字母的单词的一个列表。
wordlist = ['cat','dog','rabbit']
letterlist = [ ]
for aword in wordlist:
for aletter in aword:
letterlist.append(aletter)
print(letterlist)选择语句允许程序员提出问题,然后根据结果执行不同的操作。大多数编程语言提供了两种形 式的有用的结构:if else 和 if。下面是一个简单的二元选择使用 if-else 语句的例子。
if n<0:
print("Sorry, value is negative")
else:
print(math.sqrt(n))在这个例子中, n 用于检查是否小于零。如果是,输出一个句子,指出它是负的。如果不是, 则执行 else 子句,计算平方根。
选择结构,与任何控制结构一样可以嵌套,根据得到的结果可以决定是否问下一个问题。例 如,假设 score 是一个变量,记录对计算机科学进行测试的得分。
if score >= 90:
print('A')
else:
if score >=80:
print('B')
else:
if score >= 70:
print('C')
else:
if score >= 60:
print('D')
else:
print('F')这个片段将通过输出字母将分数进行分类。如果比分是大于或等于 90,输出 A。如果没有 (else),下一个判断将会进行。如果比分大于或等于 80,即它必须在 80 年和 89 之间,否则第一 个判断有误。此时输出 B。我们可以看到 Python 缩进模式有助于理解 if 和 else 之间的 联系, 无需任何额外的语法元素。
另一种实现嵌套的表述使用 elif 作为关键字。else 和 if 结合,消除了额外的嵌套。最后的 else 仍然是必要的。 因为有可能以上条件均不成立。
if score >= 90:
print('A')
elif score >=80:
print('B')
elif score >= 70:
print('C')
elif score >= 60:
print('D')
else:
print('F')Python 中也有一个单向选择结构,if 语句。if 语句中,如果条件为真,则执行操作。如果条 件为假,仅执行后面的语句。例如,下面的代码片段首先检查变量 n 的值是否为负。 如果是,则其 由绝对值函数修改它的值。无论如何,下一句代码是计算平方根。
if n<0:
n = abs(n)
print(math.sqrt(n))在列表中,存在一种替代方法使用迭代和选择结构创建列表。这被称为列表解析。列表解析可 以让你创建基于某些处理或选择条件的列表。例如,如果我们想创建的小于 10 的整数的完全平方 的列表,我们可以使用 for 语句:
>>> sqlist=[]
>>> for x in range(1,11):
sqlist.append(x*x)
>>> sqlist
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>>使用列表解析,我们可以一步完成:
>>> sqlist=[x*x for x in range(1,11)]
>>> sqlist
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>>在 for 结构中,变量 x 取从 1 到 10(不包括 10)的整数值。 计算 x * x 的值后,将结果添 加到新 建的列表中。列表解析中也可以使用选择语句,以便只有某些项目进行运算并添加到新的列 表中。例如:
>>> sqlist=[x*x for x in range(1,11) if x%2 != 0]
>>> sqlist
[1, 9, 25, 49, 81]
>>>这个列表解析语句建立了一个仅含有 1 到 10 以内奇数的完全平方的列表,任何支持迭代运算 的序列都可以在列表解析中被用来构造一个新的列表。
>>>[ch.upper() for ch in 'comprehension' if ch not in 'aeiou']
['C', 'M', 'P', 'R', 'H', 'N', 'S', 'N']
>>>3 方法和类
方法和类的好处有很多,最为明显的有两个:封装和复用。我们在工程开发中很多工作都是围绕这个问题展开的,不过在算法中,我们只要知道如何使用方法,并且能设计简单的类就可以了。
3.1 方法
一般情况下,我们可以通过定义 一个函数隐藏任何计算的详细步骤。一个函数定义需要一个名字,一组参数,和函数主体。它也可 以返回一个确定值。例如,下面定义一个返回输入值平方的简单函数。
>>> def square(n):
... return n**2
...
>>> square(3)
9
>>> square(square(3))
81
>>>此函数语法的定义包括名称函数名称 square 和形式参数组合列表。在以上函数中,n 是唯一的 形式参数,这表明 square 函数只需要输入一个数据即可运行。函数主体计算 n 平方的结果,并返回 这个值。我们可以通过在 Python 环境中调用 square 函数来计算它。给 square 函数传递一个实际 参数值,在上述例子中,我们把 3 这个实际数值传给了函数。注意,调用 square 函数返回的值可 以被其他操作进行使用。
我们可以通过使用“牛顿法”实现我们自己的平方根函数。用牛顿法逼近平方根计算,使结果 收敛于正确的值。等式 newguess= 1/2 *(oldguess+ N / oldguess)取一个值 n,重复地执行以上 等式,每一次等式计算结果 newguess 变成下一次迭代的 oldguess 带入进行计算。这里使用的初值为 n/2。代码 1 中有这样一个函数,它接受一个值 n,并返回做 20 次重复计算之后的值。同样,牛顿 法的具体步骤被隐藏在函数定义内,用户不必知道该函数为达到预计目的是如何实现这个功能的。 代码 1 还说明#字符是作为注释标记使用的。#后的任何字符都被忽略。
def squareroot(n):
root = n/2 #initial guess will be 1/2 of n
for k in range(20):
root = (1/2)*(root + (n / root))
return root
>>>squareroot(9)
3.0
>>>squareroot(4563)
67.549981495186216
>>>
293.2 定义类
我们之前声明了 Python 是一种面向对象的编程语言,到目前为止我们已经用了很多内置的类来说明数据和控制的构成。但是,面向对象的编程语言一个最重要的特征是允许编程者(解决问题的人)来创造一个可以用来解决问题的数据模型的新的类。
记住我们运用抽象的数据类型来提供一个关于某种数据项目是什么样子(它的阐述)和它能做什么(它的方法)逻辑描述。通过建立类来实现一种抽象数据类型,一个编程者可以从中获得抽象过程的好处同时也提供必须的细节来将这些抽象实际运用到一个程序中。无论何时我们想实施一种抽象数据类型,我们将依靠新的类来做它。
用一个很常见的例子来展现实施一个使用者定义的类是建立一个 Fraction 类来实施抽象数据类 型。我们已经知道 Python 提供很多数字的类供我们使用。有时候,然而,可能创建一个“类似” fraction 的数据类型会更有可观性。
一个 fraction 如 3 / 5 包括两部分。上面的数字,称为分子,可以是任何整数。下面的数字, 称为分母,可以是任何大于 0 的整数(负的 fraction 有负的分子)。虽说我们可以创建一个浮点数近似任何 fraction,但在有的情况下我们还是想用分数表示一个确切的值。
对 Fration 运算符应使对 Fraction 数据对象的运算操作像任何其他的数值一样,我们需要能加,减,乘和除。我们也希望能够显示 fraction 使用标准的“分数”的形式,例如 3 / 5。此外, 所有 fraction 的运算应该以最简的形式返回结果,这样不管怎样进行计算,我们最后总是以最常见的形式得出结果。
在 Python 中,我们通过提供一个名字和设立一个方法(在语法上类似于函数定义)来定义一个新的类。举这个例子,
class Fraction:
#the methods go here为我们提供了定义方法的框架。对于所有的类而言第一步提供的都应是构造函数。构造函数中 定义了数据对象的创建方式。创建一个 Fraction 的对象,我们需要提供两块数据,分子和分母。在 Python 中,构造函数的方法经常被称作__init__(两个下划线在 init 之前和之后),如代码 1.8 所示。
class Fraction:
def __init__(self,top,bottom):
self.num = top
self.den = bottom注意,正式的参数列表包含三项(self,top,bottom)。self 是一个特殊的参数,都可以用来作为参考返回对象本身。它必须是第一个正式参数;然而,调用时它将永远不需给出一个实际参数值。如前所述,Fraction 需要两块状态数据,分子和分母。在构造函数符号 定义 Fraction 对象有一个内部的数据对象被称为 num 作为它的状态。同样, 被创造为分母。这 两个形参的值最初被分配的状态,使新的 fraction 对象知道它的起始值。
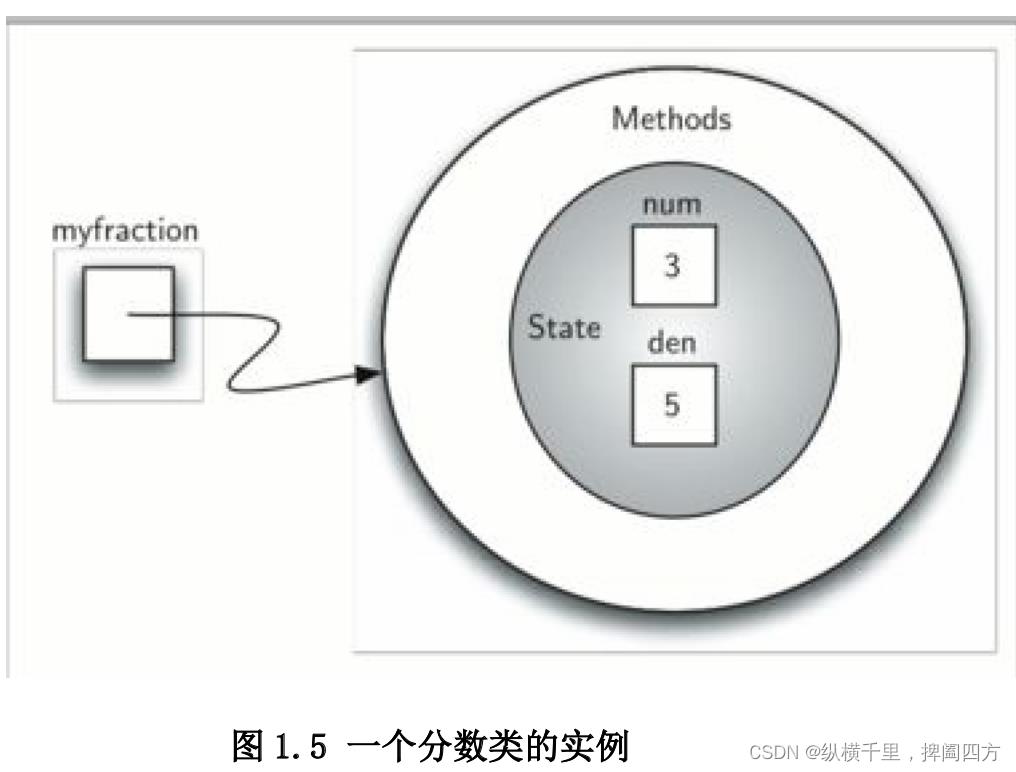
为创造一个 Fraction 类的实例,我们必须借助构造器。这会在使用类的名称和传递实际数值的时候发生(注意我们不会直接借助__init__)。例如,
myfraction = Fraction(3,5)这里创建一个对象,称为 myfraction 代表分数 3/5(五分之三)。图 1.5 显示了这个目标现 在的实现。
我们要做的下一件事是实现抽象数据类型要求的行为。首先,考虑当我们尝试打印分数对象会 发生什么。
>>> myf = Fraction(3,5)
>>> print(myf)
<__main__.Fraction instance at 0x409b1acc>fraction 对象,myf,不知道如何回应这一打印要求。打印功能要求对象转换成字符串以至于该 字符串可以输入输出。myf 唯一的选择是显示该变量中存储的实际引用(本身的地址)。这不是我们 想要的。
我们有两种方法可以解决这个问题。一个是定义一个方法称为 show 将允许 Fraction 对象将自 己作为一个字符串输出。我们可以实现这个方法,如代码 1.9 所示。如果我们之前创建的 Fraction 对象,我们可以让它 show(展示)它自己,换句话说,用适当的格式打印本身。不幸的是,这工作 一般不可完成。为了使打印正常工作,我们需要告诉 Fraction 类如何转换成一个字符串。这就是打 印功能完成任务所需要的。
def show(self):
print(self.num,"/",self.den)
>>> myf = Fraction(3,5)
>>> myf.show()
3 /5
>>> print(myf)
<__main__.Fraction instance at 0x40bce9ac> >>>在 Python 中,所有的类都有一个标准方法,但不一定都能正常工作。其中的一个__str__是一 种方法来将对象转为字符串。此方法的默认实现是返回我们已经看到的地址的字符串。我们需要做 的是将这个方法“更好”的实现。我们会说这个实现覆盖前一个,或者说它重新定义了方法的行 为。
为做到这个,我们简单地定义一个方法,名称为__str__并给它一个新的实现如代码 4 所示。这 个定义并不需要任何其他信息,除了特殊参数 self。反过来,该方法会通过转变每一块的内部状态 的数据为一个字符串,然后放置一个字符在字符串之间作为字符串关联的事物。结果字符串将在任 何一个 Fraction 对象要求转换它自己为字符串时被返回。注意这个函数使用的各种方法。
def __str__(self):
return str(self.num)+"/"+str(self.den)
>>> myf = Fraction(3,5)
>>> print(myf)
3/5
>>> print("I ate", myf, "of the pizza")
I ate 3/5 of the pizza
>>> myf.__str__()
'3/5'
>>> str(myf)
'3/5'
>>>我们可以为我们的新 Fraction 类装载许多其他的方法。一些最重要的是基本的算术运算。我们 希望能够创建两个分数对象然后他们加在一起使用标准的“+”符号。在这一点上,如果我们试图直 接相加两个分数,则会得到如下:
>>> f1 = Fraction(1,4)
>>> f2 = Fraction(1,2)
>>> f1+f2
Traceback (most recent call last):
File "<pyshell#173>", line 1, in -toplevelf1+ f2
TypeError: unsupported operand type(s) for +: 'instance' and 'instance'
>>>如果你仔细看看错误,你会看到错误是“+”号运算无法被当成运算符理解。
我们可以通过提供 Fraction 类重写方法解决这个问题。在 Python 中,这种方法被称为 __add__,它需要两个参数。第一,self,这个总是需要的,第二是在另一个被操作数的表达。例如,
f1.__add__(f2)会要求 Fraction 对象 f1 来将 f2 加到到本身。这可以写为标准的符号格式,f1 + f2。
两部分必须有相同分母来相加。最简单的方法来确保他们具有相同的分母是简单地使用两分母 的公倍数作为一个共同的分母,a / b + c / d =ad/ bd + cb/bd =(ad + cb)/ bd 的实现如代 码 1.11 所示。此外,函数返回一个新的分子和分母的分数总和对象。我们可以通过写一个标准的分 数算术表达式使用此方法,分配加法结果,然后打印我们需要的结果。
def __add__(self,otherfraction):
newnum = self.num*otherfraction.den + self.den*otherfraction.num
newden = self.den * otherfraction.den
return Fraction(newnum,newden)
>>> f1=Fraction(1,4)
>>> f2=Fraction(1,2)
>>> f3=f1+f2
>>> print(f3) 6/8
>>>方法“__add__”达到了我们的目的,但结果并不完美。6/8 的确是对的,但是它并不是最简分数。最好的答案应该是 3/4。为了保证运算结果为最简分数,我们需要一个辅助函数来识别并化简分 数。这个函数需要能够找到分子分母的最大公因数,然后我们就可以将分子分母同时除以最大公因 数,得到最简分数答案。
最著名的寻找最大公因数的方法是欧几里得算法,我们将在第 8 节对其做具体讨论。欧几里得算法规定:对于两个整数 m 和 n,如果 n 能整除 m,那么就将 n 除以 m 的结果作为新的 n,如果 n 不能再整除 m,那么最大公因数就是 n 或者 m 被 n 整除的余数。在这里简要地给出一个以迭代法实 现的示例(请参见动态代码 1.12)。注意这个最大公因数的算法只适用于分母是正数的情况。因为 我们可以把负分数的负号归结于分子,所以这种算法还是比较实用的。
def gcd(m,n):
while m%n != 0:
oldm = m
34
oldn = n
m = oldn
n = oldm%oldn
return n
print gcd(20,10)函数来化简分数式。为了使所求分数为最简分数形式,令分子、分母同时除以它们的最大公约 数。如对于 6/8 这个分数,最大公约数是 2。我们分数线上下同时除以 2 就得到了一个“新的分 数”,3/4(请参见第 6 节)。
def __add__(self,otherfraction):
newnum = self.num*otherfraction.den + self.den*otherfraction.num
newden = self.den * otherfraction.den
common = gcd(newnum,newden)
return Fraction(newnum//common,newden//common)
>>> f1=Fraction(1,4)
>>> f2=Fraction(1,2)
>>> f3=f1+f2
>>> print(f3) 3/4
>>>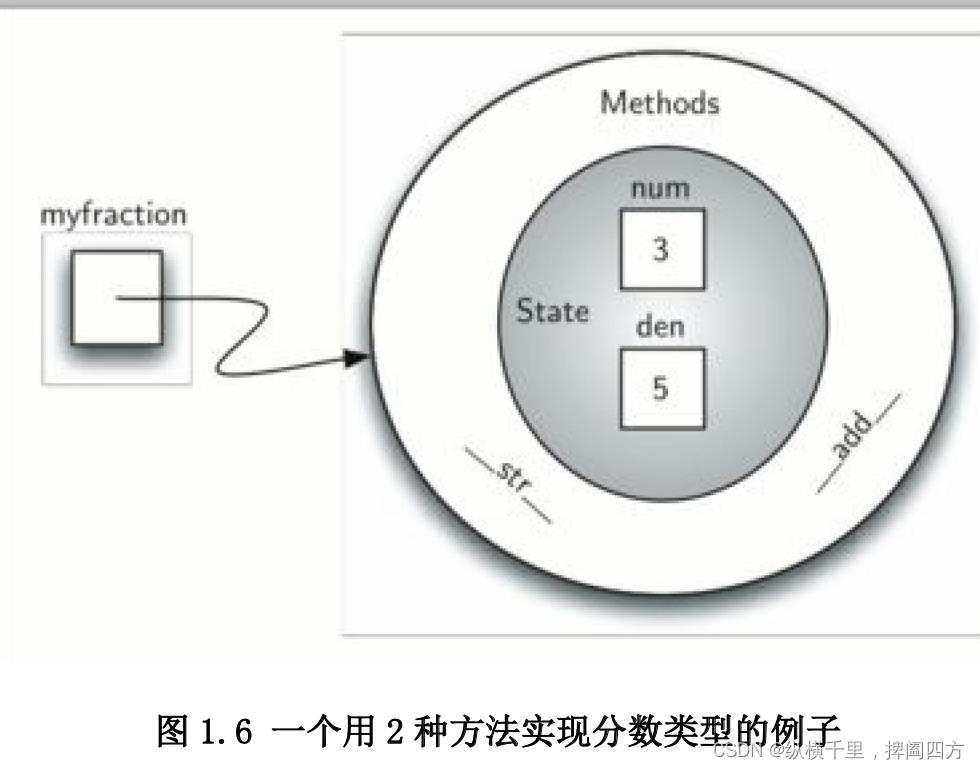
对于分数对象,现在有 2 个非常有用的方法,如图 1.6。我们需要在我们的示例函数类中包含一 个可以使两个分数相互比较的方法组。假设我们有两个分数对象,他们分别是 f1 和 f2,仅当 f1 与 f2 指向的是同一对象时(f1==f2)才为真命题,两个不同的对象即使含有相同的分子和分母,在这 个实现中也不相等。这个现象被称为浅相等(见图 1.7)。
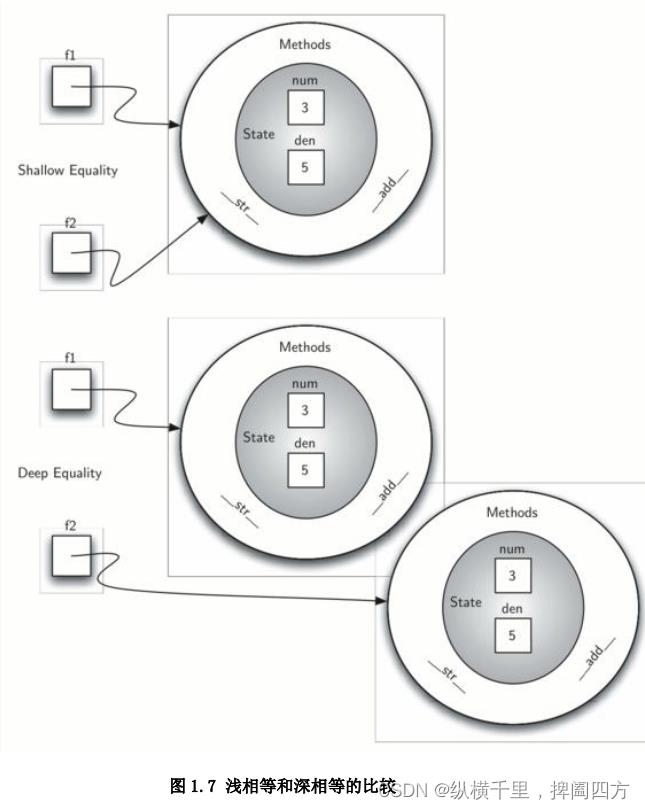
我们可以通过重建_eq_方法来建立深相等(见图 1.7)——即一种数值上相等,却并不一定是相 同指向的相等方式。_eq_方法是另一种在很多类中均可用的标准方法。_eq_方法比较两个对象,若 它们在数值上相等就返回真值,否则就返回假值。
在分数类中,我们通过再一次将两个分数放在同一条件下,再比较他们的分母(通分)的方法 实现_eq_方法(见代码)。需要指出的是,还有其他的相关运算子是可以被重构的。比如, _le_方法可以判定“小于等于”。
def __eq__(self, other):
firstnum = self.num * other.den
secondnum = other.num * self.den
return firstnum == secondnum直到这里,完整的分数类已经在动态代码 2 中呈现了。剩下的算法和相关方法将作为训练留给 读者。
3.总结
本文我们梳理了在算法中经常用的python功能,Python是一门强大的,而同时又易于使用的面向对象的程序设计语言; 列表,元组和字符串都是Python内置的有序集合,字典和集合是数据的无序集合;这些都是算法中非常常用的问题。
而方法和类方面,我们不需要谈太多,而且我建议平时练习算法的时候,要尽量减少定义的方法数,减少过多的复用,同时避免使用复杂的类结构。为什么呢?因为面试的时候,是要求短时间内将代码写出来并且要运行的,平时调复用接口多了,你可能会连个普通的getLength()都不知道怎么办。所以我们要将将代码写的尽量简介、清晰、好记、好写,不要装*。
以上是关于爆肝一周——PYTHON 算法基础的主要内容,如果未能解决你的问题,请参考以下文章