YOLOv5添加注意力机制的具体步骤
Posted 萝北村的枫子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv5添加注意力机制的具体步骤相关的知识,希望对你有一定的参考价值。
本文以CBAM和SE注意力机制的添加过程为例,主要介绍了向YOLOv5中添加注意力机制的具体步骤
本文在此篇博客的基础上向YOLOv5-5.0版本代码中添加注意力机制
yolov5模型训练———使用yolov5训练自己的数据集
本文主要包括以下内容
YOLOv5加入注意力机制可分为以下三个步骤:
1.common.py中加入注意力模块
2.yolo.py中增加判断条件
3.yaml文件中添加相应模块
一、CBAM注意力机制添加
(1)在common.py中添加可调用的CBAM模块
1.打开models文件夹中的common.py文件
2.将下面的CBAMC3代码复制粘贴到common.py文件中
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# 将最后的标准卷积模块改为了注意力机制提取特征
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
如下图所示,本文这里是将其粘贴到了common.py的末尾
(图片长度过长,所以截取了两张,以及记得点击保存)


(2)向yolo.py文件添加CBAMC3判断语句
1.打开models文件夹中的yolo.py文件

2.分别在218行和224行添加CBAMC3,如下图所示
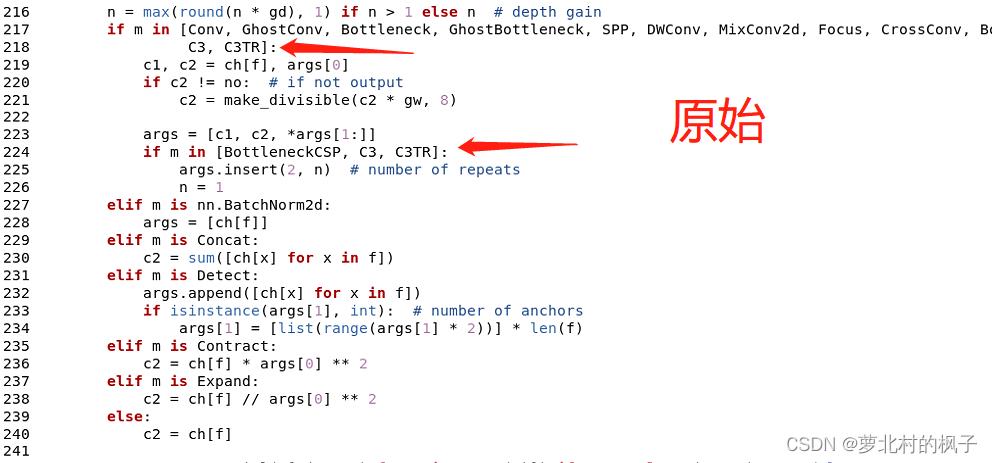

同样改完之后记得点保存
(3)修改yaml文件
注意力机制可以添加在backbone,Neck,Head等部分,大家可以在yaml文件中修改网络的结构、添加其他模块等等,接下来本文将以向主干网络(backbone)添加CBAM模块为例,本文介绍的只是其中一种添加方式
1.在yolov5-5.0工程文件夹下,找到models文件夹下的yolov5s.yaml文件

2.backbone主干网络中的4个C3模块改为CBAMC3,如下图所示:


这样我们就在yolov5s主干网络中添加了CBAM注意力机制
(在服务器上跑代码修改后,记得点击文本编辑器右上角的保存)
接下来开始训练模型,我们就可以看到CBAMC3模块已经成功添加到主干网络中了

二、SE注意力机制添加
(步骤和CBAM相似)
(1)在common.py中添加可调用的SE模块
1.打开models文件夹中的common.py文件
2.将下面的SE代码复制粘贴到common.py文件中
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
如下图所示,本文这里是将其粘贴到了common.py的末尾
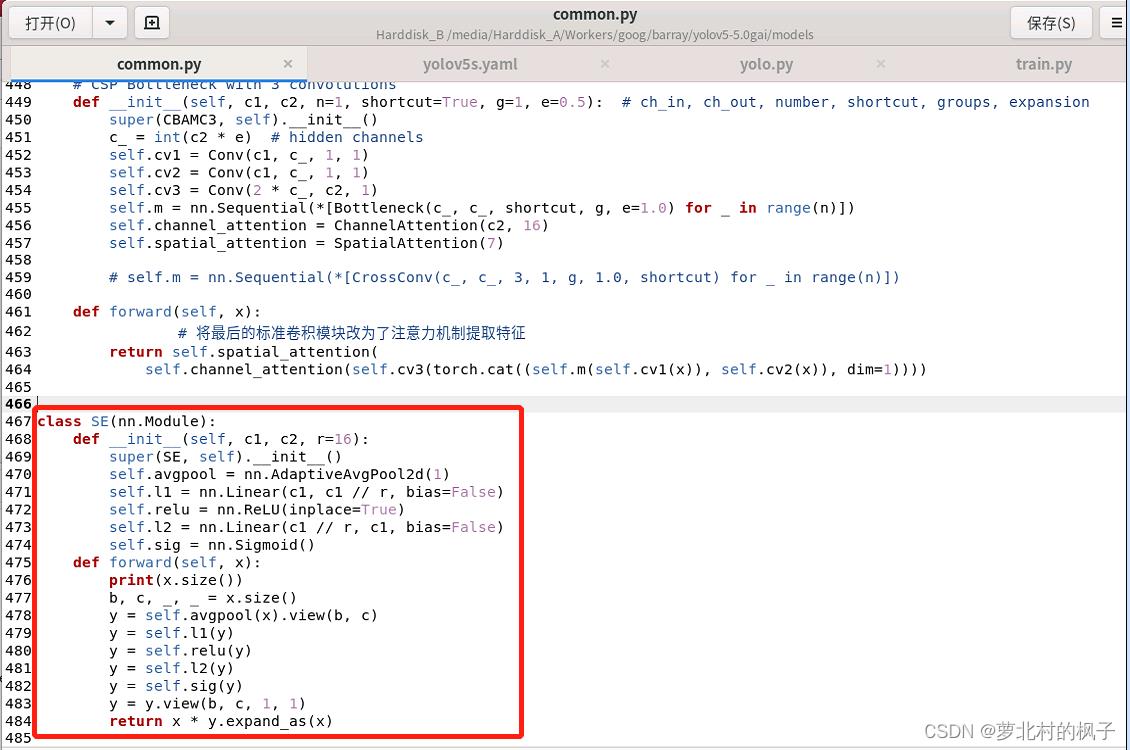
(2)向yolo.py文件添加SE判断语句
1.打开models文件夹中的yolo.py文件
2.分别在218行和224行添加SE,如下图所示


同样改完之后记得点保存
(3)修改yaml文件
注意力机制可以添加在backbone,Neck,Head等部分,大家可以在yaml文件中修改网络的结构、添加其他模块等等。与CBAM的添加过程一样,接下来本文将以向主干网络(backbone)添加SE模块为例,本文介绍的只是其中一种添加方式
1.在yolov5-5.0工程文件夹下,找到models文件夹下的yolov5s.yaml文件
2.backbone主干网络末尾添加下面的代码,如下图所示:
(注意逗号是英文,以及注意对齐)
[-1, 1, SE, [1024, 4]],

这样我们就在yolov5s主干网络中添加了SE注意力机制
(在服务器上跑代码修改后,记得点击文本编辑器右上角的保存)
接下来开始训练模型,我们就可以看到SE模块已经成功添加到主干网络中了

三、其他几种注意力机制代码
添加过程不再赘述,模仿上方CBAM和SE的添加过程即可
(1)ECA注意力机制代码
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x=x*y.expand_as(x)
return x * y.expand_as(x)
(2)CA注意力机制代码:
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
yolov5改进之加入CBAM,SE,ECA,CA,SimAM,ShuffleAttention,Criss-CrossAttention,CrissCrossAttention多种注意力机制
本文所涉及到的yolov5网络为6.1版本(6.0-6.2均适用)
yolov5加入注意力机制模块的三个标准步骤(适用于本文中的任何注意力机制)
1.common.py中加入注意力机制模块
2.yolo.py中增加对应的注意力机制关键字
3.yaml文件中添加相应模块
注:所有注意力机制的添加方法都是一致的,加入注意力机制是否有效的关键在于注意力机制添加的位置,本文提供两种常用常用方法。
注:需要下列所有注意力机制已经改好的代码版本及yaml文件(到手即用),请私聊我(免费)
目录
1.CBAM注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
# c_ = int(c2 * e) # hidden channels
# self.cv1 = Conv(c1, c_, 1, 1)
# self.cv2 = Conv(c1, c_, 1, 1)
# self.cv3 = Conv(2 * c_, c2, 1)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:'.format(out.shape))
out = self.spatial_attention(out) * out
return out以上代码需要添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加CBAM即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, CBAM):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, CBAM]:
args.insert(2, n) # number of repeats
n = 1第三步,就是最为关键的改动yaml文件了,我们以yolov5s.yaml为例进行改进,这里仅截取关键部分,未截取部分则不做改动。
第一个版本是将CBAM放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, CBAM, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将CBAM放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, CBAM, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, CBAM, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, CBAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, CBAM, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]2.SE注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加SE即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, SE):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, SE]:
args.insert(2, n) # number of repeats
n = 1第三步,就是最为关键的改动yaml文件了,我们以yolov5s.yaml为例进行改进,这里仅截取关键部分,未截取部分则不做改动。
第一个版本是将SE放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, SE, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将SE放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, SE, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, SE, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, SE, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, SE, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]3.ECA注意力注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return outECA注意力机制比较特殊,不需要改动models文件夹下的yolo.py文件,可直接使用。
第三步,就是最为关键的改动yaml文件了,我们以yolov5s.yaml为例进行改进,这里仅截取关键部分,未截取部分则不做改动。
第一个版本是将ECA放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, SE, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将ECA放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, SE, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, SE, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, SE, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, SE, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]4.CA注意力注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x= x*y.expand_as(x)
return x * y.expand_as(x)第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加SE即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, SE):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, SE]:
args.insert(2, n) # number of repeats
n = 1第一个版本是将CA放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, CA, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将CA放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, CA, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, CA, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, CA, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, CA, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]5.SimAM注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
class SimAM(torch.nn.Module):
def __init__(self, channels = None,out_channels = None, e_lambda = 1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加SimAM即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, SimAM):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, SimAM]:
args.insert(2, n) # number of repeats
n = 1第一个版本是将SimAM放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, SimAM, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将SimAM放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, SimAM, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, SimAM, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, SimAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, SimAM, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]6.ShuffleAttention注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
class ShuffleAttention(nn.Module):
def __init__(self, channel=512,reduction=16,G=8):
super().__init__()
self.G=G
self.channel=channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = torch.ones(1, channel // (2 * G), 1, 1)
self.cbias = torch.ones(1, channel // (2 * G), 1, 1)
self.sweight = torch.ones(1, channel // (2 * G), 1, 1)
self.sbias = torch.ones(1, channel // (2 * G), 1, 1)
self.sigmoid=nn.Sigmoid()
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
#group into subfeatures
x=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w
#channel_split
x_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w
#channel attention
x_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1
x_channel=self.cweight*x_channel+self.cbias #bs*G,c//(2*G),1,1
x_channel=x_0*self.sigmoid(x_channel)
#spatial attention
x_spatial=self.gn(x_1) #bs*G,c//(2*G),h,w
x_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,w
x_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w
# concatenate along channel axis
out=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,w
out=out.contiguous().view(b,-1,h,w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加ShuffleAttention即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, ShuffleAttention):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, ShuffleAttention]:
args.insert(2, n) # number of repeats
n = 1第一个版本是将ShuffleAttention放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, ShuffleAttention, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将ShuffleAttention放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, ShuffleAttention, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, ShuffleAttention, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, ShuffleAttention, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, ShuffleAttention, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]7.CrissCrossAttention注意力机制
同理,首先将下方代码添加在models文件夹下的common.py文件中,具体添加位置如果找不准可以选择common.py文件的最底端(最稳妥的做法,肯定不会错),或者C3模块后面(方便查找)。
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).repeat(H),0).unsqueeze(0).repeat(B*W,1,1).cuda()
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim, out_channels, none):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = nn.Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x第二步,需要更改models文件夹下的yolo.py文件。可以直接ctrl+F 然后查找parse_model关键字,定位到parse_model函数,你会发现有一段这样的代码
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 1我们仅需在第1行和第8行末尾添加CrissCrossAttention即可,具体做法如下
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3new, C3new2, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, CrissCrossAttention):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3new, C3new2, C3TR, C3Ghost, C3x, CrissCrossAttention]:
args.insert(2, n) # number of repeats
n = 1第一个版本是将CrissCrossAttention放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,将具有全局视野,类似于一个小transformer结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, CrissCrossAttention, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第二个版本是将CrissCrossAttention放在backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, CrissCrossAttention, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, CrissCrossAttention, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, CrissCrossAttention, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, CrissCrossAttention, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]以上是关于YOLOv5添加注意力机制的具体步骤的主要内容,如果未能解决你的问题,请参考以下文章