源码级注解
Posted walidake
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码级注解相关的知识,希望对你有一定的参考价值。
请看前言
上一篇文章我们说到运行时框架是在虚拟机运行程序时使用反射技术搭建的框架;而源码级框架是在javac编译源码时,生成框架代码或文件。源码级别框架发生过程是在编译期间,并不会过多影响到运行效率。因此,android等对效率性能要求较高的平台一般使用源码级别注解来搭建。
注解处理器
注解处理器是一个在javac中的,用来编译时扫描和处理的注解的工具。
一个注解的注解处理器,以Java代码(或者编译过的字节码)作为输入,生成文件(通常是.java文件)作为输出。这具体的含义什么呢?你可以生成Java代码!
生成的Java代码是在新的.java文件中,所以你并不能修改已存在的Java类,例如向已有的类中添加方法。并且这些生成的Java文件,会同其他普通的手动编写的Java源代码一样被javac编译。
写代码之前
在开始写代码之前,我们需要了解一个叫AbstractProcessor的类。AbstractProcessor(虚处理器),是注解处理器核心API。注解处理器需要继承于AbstractProcessor,如下所示:
public class MyProcessor extends AbstractProcessor
// 这个方法主要是获取工具类,有Elements, Types和Filer等。后面会提到
@Override
public synchronized void init(ProcessingEnvironment env)
// 相当于main(),写处理的过程
// annotations是getSupportedAnnotationTypes()的子集
// env代表这一轮扫描后的结果,返回true则表示消费完此次扫描,此轮扫描注解结束
@Override
public boolean process(Set<? extends TypeElement> annoations, RoundEnvironment env)
// 在这里定义你的注解处理器注册到哪些注解上
@Override
public Set<String> getSupportedAnnotationTypes()
// 用来指定你使用的Java版本。通常这里返回SourceVersion.latestSupported()
@Override
public SourceVersion getSupportedSourceVersion()
Java 7,我们可以使用注解来代替getSupportedAnnotationTypes()和getSupportedSourceVersion()。但是因为兼容原因(特别针对Android平台),建议使用重载getSupportedAnnotationTypes()和getSupportedSourceVersion()的方式。
@SupportedSourceVersion(SourceVersion.latestSupported())
@SupportedAnnotationTypes(
// 合法注解全名的集合
)
public class MyProcessor extends AbstractProcessor
@Override
public synchronized void init(ProcessingEnvironment env)
@Override
public boolean process(Set<? extends TypeElement> annoations, RoundEnvironment env)
值得一提
注解处理器是运行它自己的虚拟机JVM中。javac启动一个完整Java虚拟机来运行注解处理器。这意味着我们可以使用任何你在其他java应用中使用的的东西。可以使用依赖注入工具(Dagger等),或者其他想要的类库。
自定义注解处理器
在自定义前,问一个问题,怎么注册Processor到javac中?
我们需要编译产生一个类似这样的.jar文件。(注解处理器代码实现+可扩展应用程序)
MyProcessor.jar
- com
- example
- MyProcessor.class
- META-INF
- services
- javax.annotation.processing.Processor
打包进MyProcessor.jar中的javax.annotation.processing.Processor的内容是注解处理器的合法的全名列表。(不明白可搜索“可扩展应用程序”)
com.example.MyProcessor
值得为人称道的是,Google老大哥提供了auto-service.jar,极大简化了我们的打包操作。我们可以用它生成META-INF/services/javax.annotation.processing.Processor文件。是的,我们可以在注解处理器中使用注解,只需要一个@AutoService。后面会使用到。
不说废话
场景:我们要帮一个动物学家的朋友完成观察动物的报告。于是我们写了一个Animal接口,然后实现了Bird,Dog,Fish。因为目前只观察到了这几种。学过设计模式的朋友会把它们抽取出来,做一个工厂类,这种思路是很好的。但是,假设我们只会简单工厂模式,就if..else..那种。那这时候我们添加一个动物,就需要在工厂自动生成对应的if语句来生成相应实例。
于是,我们想到说使用注解处理器的方法来在编译时自动生成有关代码。
我们可以自定义注解如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.SOURCE)
public @interface Factory
// Animal接口实现类
Class<?> type();
String id();
有了工厂注解后,我们先不急着放在Animal接口实现类上面。我们先实现注解处理器。
@AutoService(Processor.class)
public class FactoryProcessor extends AbstractProcessor
前面我们提到过@AutoService注解,加了此注解,可以自动生成services下的文件。因此,我们不需要手动编写service,只需要关注注解处理器代码逻辑即可。
我们需要一些工具类,在代码中添加并在init()方法对其进行初始化。
private Filer filer;
private Messager messager;
private Types typeUtils;
private Elements elementUtils;
@Override
public synchronized void init(ProcessingEnvironment processingEnv)
super.init(processingEnv);
typeUtils = processingEnv.getTypeUtils();
elementUtils = processingEnv.getElementUtils();
filer = processingEnv.getFiler();
messager = processingEnv.getMessager();
接着,重载getSupportedAnnotationTypes(),getSupportedSourceVersion()获取注解支持,以及源码编译版本支持。
@Override
public Set getSupportedAnnotationTypes()
Set annotataions = new LinkedHashSet();
annotataions.add(Factory.class.getCanonicalName());
return annotataions;
@Override
public SourceVersion getSupportedSourceVersion()
return SourceVersion.latestSupported();
Elements和TypeMirrors
需要你对工具类的用途大概有个印象。
| 工具类 | 用途 |
|---|---|
| Elements | 用来处理Element的工具类 |
| Types | 用来处理TypeMirror的工具类 |
| Filer | 使用Filer你可以创建文件 |
需要注意
在注解处理的过程中,我们扫描所有的Java源文件。源代码的每一个部分都是一个特定类型的Element。它只是结构化的文本,不是可运行的,可以像你认识Xml一样的方式认识Element。例如说:
package com.example; // PackageElement
public class Foo // TypeElement
private int a; // VariableElement
private Foo other; // VariableElement
public Foo () // ExecuteableElement
public void setA ( // ExecuteableElement
int newA // TypeElement
)
因此,我们可以像Xml那样定位到某个元素。
举例来说,假如你有一个代表public class Foo类的TypeElement元素,你可以遍历它的孩子,如下:
TypeElement fooClass = ... ;
for (Element e : fooClass.getEnclosedElements()) // iterate over children
Element parent = e.getEnclosingElement(); // parent == fooClass
可以从上面看出来,Element代表的是源代码。TypeElement代表的是源代码中的类型元素,例如类。然而,TypeElement并不包含类本身的信息。你可以从TypeElement中获取类的名字,但是你获取不到类的信息,例如它的父类。类信息需要通过TypeMirror获取。你可以通过调用elements.asType()获取元素的TypeMirror。
搜索@Factory注解
开始处理process()的逻辑,在其中添加这样一段:
for (Element annotatedElement:roundEnv.getElementsAnnotatedWith(Factory.class))
目的是遍历所有被注解了@Factory的元素,而我们知道TypeElement可能是class,也可能是其他,那么我们在循环中需要加以判断:
if (annotatedElement.getKind() != ElementKind.CLASS)
throw new Exception(
"Only classes can be annotated with @%s");
// 确认为ElementKind.CLASS,强制转换为TypeElement
TypeElement typeElement = (TypeElement) annotatedElement;
为什么我们使用.getKind()而不是.instanceof()?
首先,instanceof是检查对象和类的关系的方法。其次,接口(interface)类型也是TypeElement。所以不采用.instanceof()的做法。
优雅的错误处理
可能上面的代码给你造成一种错觉,就是我直接跑出了异常。事实上不是的,上面的代码我写在try..catch..块中,并且使用
messager.printMessage(Diagnostic.Kind.ERROR, String.format(msg, args), e);
来处理异常。这是一种优雅的错误处理方式。
为什么说是一种优雅的错误处理方式?
在传统Java应用中我们可能就抛出一个Exception。如果你在process()中抛出一个异常,那么运行注解处理器的JVM将会崩溃(就像其他Java应用一样)。而使用我们注解处理器的第三方开发者将会从javac中得到非常难懂的出错信息,因为它包含自定义注解处理器的堆栈跟踪(Stacktace)信息。因此,注解处理器就有一个Messager类,它能够打印非常优美的错误信息。除此之外,你还可以链接到出错的元素。在像IntelliJ这种现代的IDE(集成开发环境)中,第三方开发者可以直接点击错误信息,IDE将会直接跳转到第三方开发者项目的出错的源文件的相应的行。当然,这里需要之前初始化好的Messager对象。
接下来,我们会希望有一个类能解析typeElement并保存信息。
public class FactoryAnnotatedClass
private TypeElement annotatedClassElement;
private String qualifiedSuperClassName;
private String simpleTypeName;
private String id;
public FactoryAnnotatedClass(TypeElement classElement)
throws IllegalArgumentException
this.annotatedClassElement = classElement;
Factory annotation = classElement.getAnnotation(Factory.class);
id = annotation.id();
if (id == null || "".equals(id))
throw new IllegalArgumentException(
String.format(
"id() in @%s for class %s is null or empty! that's not allowed",
Factory.class.getSimpleName(), classElement
.getQualifiedName().toString()));
try
// 这个类已经被编译
Class使用自定义好的注解处理器
使用Maven编译。把annotation.jar和processor.jar放到builpath中,javac会自动检查和读取javax.annotation.processing.Processor中的内容,并且注册MyProcessor作为注解处理器。
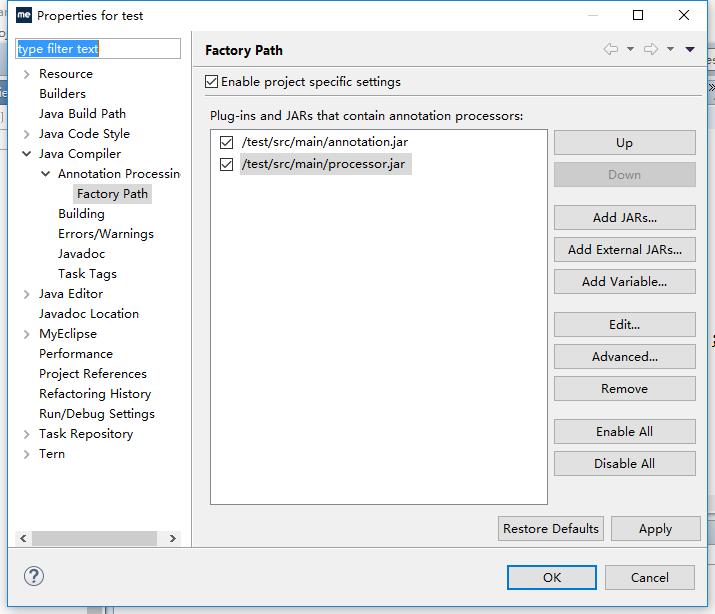
为什么要分别打包?
在开发过程中,第三方开放着仅仅需要processor产生需要的代码,而并不希望它跟随源代码一起打包。因此,一起打包不合适!
如果你是一个Android的开发者,你肯定听说过65k个方法的限制(即在一个.dex文件中,只能寻址65000个方法)。如果你在FactoryProcessor中使用guava,并且把注解和处理器打包在一个包中,这样的话,Android APK安装包中不只是包含FactoryProcessor的代码,而也包含了整个guava的代码。Guava有大约20000个方法。所以分开注解和处理器是非常有意义的。
补充Animal的实现类:
@Factory(id = "bird", type = Animal.class)
public class Bird implements Animal
@Override
public void doSomething()
System.out.println("fly");
写main()方法入口:
public static void main(String[] args)
new AnimalFactory().create("dog").doSomething();
打开AnimalFactory,
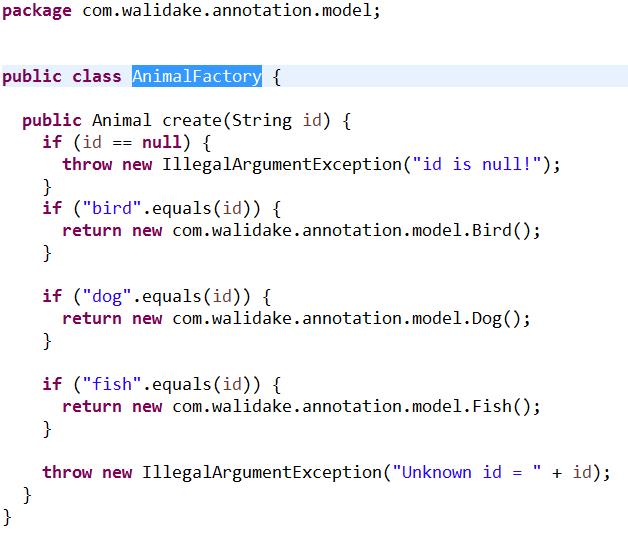
生成的代码符合我们的预期要求。成功!
说说题外话
如果你是一个Android的开发者,你应该非常熟悉一个叫做ButterKnife的注解处理器。在ButterKnife中,你使用@InjectView注解Android的View。ButterKnifeProcessor生成一个MyActivity$$ViewInjector,但是在ButterKnife你不需要手动调用new MyActivity$$ViewInjector()实例化一个ButterKnife注入的对象,而是使用Butterknife.inject(activity)。ButterKnife内部使用反射机制来实例化MyActivity$$ViewInjector()对象:
try
Class<?> injector = Class.forName(clsName + "$$ViewInjector");
catch (ClassNotFoundException e) ...
上一篇文章我们提到反射影响性能,使用注解处理来生成本地代码,会不会导致很多的反射性能的问题?
的确,反射机制的性能确实是一个问题。然而它并不需要手动去创建对象,确实提高了开发者的开发速度。ButterKnife中有一个哈希表HashMap来缓存实例化过的对象。所以MyActivity$$ViewInjector只是使用反射机制实例化一次,第二次需要MyActivity$$ViewInjector的时候,就直接冲哈希表中获得。
FragmentArgs非常类似于ButterKnife。它使用反射机制来创建对象,而不需要开发者手动来做这些。FragmentArgs在处理注解的时候生成一个特别的查找表类(其实就是一种哈希表),所以整个FragmentArgs库只是在第一次使用的时候,执行一次反射调用(一旦整个Class.forName()的Fragemnt的参数对象被创建),后面的都是本地代码运行了。
而如果你使用过Realm的话,你也能发现类似的细节。
总结
注解处理器是一个强大的工具,为第三方开发者提供了巨大的便捷性。我也想提醒的是,注解处理器可以做到比我上面提到例子复杂很多的事情。
另外,如果你决定在其他类使用ElementUtils, TypeUtils和Messager,你就必须把他们作为参数传进去。可以使用Dagger(一个依赖注入库)来解决这个问题。这在上面也有提到。
对了,我也找到一个使用gradle构建注解处理器的例子。需要的朋友也可以参考一下。地址如下:
http://blog.csdn.net/ucxiii/article/details/52025005
那么,关于注解的模块到此就讲完了。如果有疑问的小伙伴可以在评论区下面留言。
(以上内容参考总结自很多文章,感谢互联网给了我一个学习的平台~)
项目地址:https://github.com/walidake/Annotation_Processor
(已更正部分问题:2016-9-5)
以上是关于源码级注解的主要内容,如果未能解决你的问题,请参考以下文章