如何通过Tesseract开源OCR引擎创建Android OCR应用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何通过Tesseract开源OCR引擎创建Android OCR应用相关的知识,希望对你有一定的参考价值。
Tesseract是图盲,默认情况下只能看得懂未压缩的TIFF图像,如果直接用tesseract处理其它格式的图片,会报错如下:Tesseract Open Source OCR Engine
name_to_image_type:Error:Unrecognized image type:code.jpg
IMAGE::read_header:Error:Can’t read this image type:code.jpg
tesseract:Error:Read of file failed:code.jpg
所以需要用ImageMagick来转换图片格式,ImageMagick (TM) 是一个免费的创建、编辑、合成图片的软件。它可以读取、转换、写入多种格式的图片。图片切割、颜色替换、各种效果的应用,图片的旋转、组合,文本,直线,多边形,椭圆,曲线,附加到图片伸展旋转。ImageMagick是免费软件:全部源码开放,可以自由使用,复制,修改,发布。它遵守GPL许可协议。它可以运行于大多数的操作系统。ImageMagick的大多数功能的使用都来源于命令行工具。通常来说,它可以支持以下程序语言: Perl, C, C++, Python, php, Ruby, Java;现成的ImageMagick接口(PerlMagick, Magick++, PythonMagick, MagickWand for PHP, RubyMagick, and JMagick)是可利用的。这使得自动的动态的修改创建图片变为可能。ImageMagick支持至少90种图片格式: A, ART, AVI, AVS, B, BIE, BMP, BMP2, BMP3, C, CACHE, CAPTION, CIN, CIP, CLIP, CLIPBOARD, CMYK, CMYKA, CUR, CUT, DCM, DCX, DNG, DOT, DPS, DPX, EMF, EPDF, EPI, EPS, EPS2, EPS3, EPSF, EPSI, EPT, EPT2, EPT3, FAX, FITS, FPX, FRACTAL, G, G3, GIF, GIF87, GRADIENT, GRAY, HDF, HISTOGRAM, HTM, html, ICB, ICO, ICON, JBG, JBIG, JNG, JP2, JPC, JPEG, JPG, JPX, K, LABEL, M, M2V, MAP, MAT, MATTE, MIFF, MNG, MONO, MPC, MPEG, MPG, MSL, MTV, MVG, NULL, O, OTB, P7, PAL, PALM, PATTERN, PBM, PCD, PCDS, PCL, PCT, PCX, PDB, PDF, PFA, PFB, PGM, PGX, PICON, PICT, PIX, PJPEG, PLASMA, PNG, PNG24, PNG32, PNG8, PNM, PPM, PREVIEW, PS, PS2, PS3, PSD, PTIF, PWP, R, RAS, RGB, RGBA, RGBO, RLA, RLE, SCR, SCT, SFW, SGI, SHTML, STEGANO, SUN, SVG, SVGZ, TEXT, TGA, TIF, TIFF, TILE, TIM, TTC, TTF, TXT, UIL, UYVY, VDA, VICAR, VID, VIFF, VST, WBMP, WMF, WMFWIN32, WMZ, WPG, X, XBM, XC, XCF, XPM, XV, XWD, Y, YCbCr, YCbCrA, YUV,
ImageMagick .NET的相关项目:
Use MagickNet to convert, compose, and edit images from Windows .NET.
ImageMagickApp is a .NET application written in C# that utilizes the ImageMagick command line to allow conversion of multiple image formats to different formats.
假设需要识别的图片验证码为code.jpg,我们需要做的只有两步:
d:\ImageMagick\convert.exe -compress none -depth 8 -alpha off ./code.gif ./code.tif
D:\\tesseract\\tesseract.exe ./code.tif ./result
结果就在文本文件./result.txt里面了,tesseract会自动地在./result后面添加上后缀名.txt。然后再对两个命令做点解释。
convert.exe:ImageMagick套件的一部分,负责图片格式转换,各个参数的意义如下:
-compress none:转换后的图片不要压缩,如果没有加这一项,后续tesseract处理的时候会报错:read_tif_image:Error:Illegal image format:Compression
-depth 8:设置转换后图像的色深为8位,也就是bpp为8。如果没有此参数,后果如下:
Tesseract Open Source OCR Engine
check_legal_image_size:Error:Only 1,2,4,5,6,8 bpp are supported:16
Segmentation fault
-alpha off:在转换后的图像中不要添加alpha图层。如果没有此参数,后果同上。
紧跟着就是待转换的图片的文件名,最后是转换后的图片的文件名。 参考技术A Tesseract是图盲,默认情况下只能看得懂未压缩的TIFF图像,如果直接用tesseract处理其它格式的图片,会报错如下:
Tesseract Open Source OCR Engine
name_to_image_type:Error:Unrecognized image type:code.jpg
IMAGE::read_header:Error:Can’t read this image type:code.jpg
tesseract:Error:Read of file failed:code.jpg
所以我们需要用ImageMagick来转换图片格式,ImageMagick (TM) 是一个免费的创建、编辑、合成图片的软件。它可以读取、转换、写入多种格式的图片。图片切割、颜色替换、各种效果的应用,图片的旋转、组合,文本,直线,多边形,椭圆,曲线,附加到图片伸展旋转。ImageMagick是免费软件:全部源码开放,可以自由使用,复制,修改,发布。它遵守GPL许可协议。它可以运行于大多数的操作系统。ImageMagick的大多数功能的使用都来源于命令行工具。通常来说,它可以支持以下程序语言: Perl, C, C++, Python, PHP, Ruby, Java;现成的ImageMagick接口(PerlMagick, Magick++, PythonMagick, MagickWand for PHP, RubyMagick, and JMagick)是可利用的。这使得自动的动态的修改创建图片变为可能。ImageMagick支持至少90种图片格式: A, ART, AVI, AVS, B, BIE, BMP, BMP2, BMP3, C, CACHE, CAPTION, CIN, CIP, CLIP, CLIPBOARD, CMYK, CMYKA, CUR, CUT, DCM, DCX, DNG, DOT, DPS, DPX, EMF, EPDF, EPI, EPS, EPS2, EPS3, EPSF, EPSI, EPT, EPT2, EPT3, FAX, FITS, FPX, FRACTAL, G, G3, GIF, GIF87, GRADIENT, GRAY, HDF, HISTOGRAM, HTM, HTML, ICB, ICO, ICON, JBG, JBIG, JNG, JP2, JPC, JPEG, JPG, JPX, K, LABEL, M, M2V, MAP, MAT, MATTE, MIFF, MNG, MONO, MPC, MPEG, MPG, MSL, MTV, MVG, NULL, O, OTB, P7, PAL, PALM, PATTERN, PBM, PCD, PCDS, PCL, PCT, PCX, PDB, PDF, PFA, PFB, PGM, PGX, PICON, PICT, PIX, PJPEG, PLASMA, PNG, PNG24, PNG32, PNG8, PNM, PPM, PREVIEW, PS, PS2, PS3, PSD, PTIF, PWP, R, RAS, RGB, RGBA, RGBO, RLA, RLE, SCR, SCT, SFW, SGI, SHTML, STEGANO, SUN, SVG, SVGZ, TEXT, TGA, TIF, TIFF, TILE, TIM, TTC, TTF, TXT, UIL, UYVY, VDA, VICAR, VID, VIFF, VST, WBMP, WMF, WMFWIN32, WMZ, WPG, X, XBM, XC, XCF, XPM, XV, XWD, Y, YCbCr, YCbCrA, YUV,
ImageMagick .NET的相关项目:
Use MagickNet to convert, compose, and edit images from Windows .NET.
ImageMagickApp is a .NET application written in C# that utilizes the ImageMagick command line to allow conversion of multiple image formats to different formats.
假设需要识别的图片验证码为code.jpg,我们需要做的只有两步:
d:\ImageMagick\convert.exe -compress none -depth 8 -alpha off ./code.gif ./code.tif
D:\\tesseract\\tesseract.exe ./code.tif ./result
结果就在文本文件./result.txt里面了,tesseract会自动地在./result后面添加上后缀名.txt。然后再对两个命令做点解释。
convert.exe:ImageMagick套件的一部分,负责图片格式转换,各个参数的意义如下:
-compress none:转换后的图片不要压缩,如果没有加这一项,后续tesseract处理的时候会报错:read_tif_image:Error:Illegal image format:Compression
-depth 8:设置转换后图像的色深为8位,也就是bpp为8。如果没有此参数,后果如下:
Tesseract Open Source OCR Engine
check_legal_image_size:Error:Only 1,2,4,5,6,8 bpp are supported:16
Segmentation fault
-alpha off:在转换后的图像中不要添加alpha图层。如果没有此参数,后果同上。
紧跟着就是待转换的图片的文件名,最后是转换后的图片的文件名。本回答被提问者和网友采纳
开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源、免费的OCR引擎,能够支持中文十分难得。虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了。
文字识别可应用于许多领域,如阅读、翻译、文献资料的检索、信件和包裹的分拣、稿件的编辑和校对、大量统计报表和卡片的汇总与分析、银行支票的处理、商品发票的统计汇总、商品编码的识别、商品仓库的管理,以及水、电、煤气、房租、人身保险等费用的征收业务中的大量信用卡片的自动处理和办公室打字员工作的局部自动化等。以及文档检索,各类证件识别,方便用户快速录入信息,提高各行各业的工作效率。
Tesseract 是一款图片识别工具,可以抓取图片中的文字,可以支持多种语言(默认是英语),需要下载开源文件可以在github上下载。
源码下载地址:https://github.com/tesseract-ocr/tesseract/tree/3.02.02
Tesseract官网:https://code.google.com/p/tesseract-ocr/
C#测试程序中调用Tesseract主要代码:
测试tesseract.dll 代码:
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
var img = new Bitmap(openFileDialog1.FileName);
// var ocr = new TesseractEngine(@"C:Program Files (x86)Tesseract-OCR essdata", "eng", EngineMode.TesseractAndCube);
var ocr = new TesseractEngine("./tessdata", "chi_sim", EngineMode.TesseractOnly);
var page = ocr.Process(img);
txtResult.Text = page.GetText();
}
调用Tesseract.dll的两种方法:
方法一:
import console;
import tesseract;
var ocr = tesseract.ocr();
if( 0 != ocr.init("eng","/") ){ //初始化样本语言包
error("没有找到样本 essdataeng.traineddata");
}
//预设字符集可提升识别率,注意要一定在加载样本以后调用此函数
ocr.setVariable("tessedit_char_whitelist","0123456789")
//识别图像
var text = ocr.processPages(" est.jpg" )
console.log(text)
console.pause()
方法二:
import console;
import tesseract;
import win;
var ocr = tesseract.ocr();
if( 0 != ocr.init("eng","/" ) ){ //初始化样本语言包
var prefix = win.getenv("TESSDATA_PREFIX");
if(!#prefix) prefix = "~lib esseract.res"
error("没有找到样本 " + prefix + "eng.traineddata",2)
}
//预设字符集可提升识别率,注意要一定在加载样本以后调用此函数
ocr.setVariable("tessedit_char_whitelist","0123456789")
//获取图像像素数据
var pix = liblept.pixRead( ..io.fullpath(" est.jpg") );
ocr.setImage2( pix )
//识别图像
if( 0 != ocr.recognize() ){
console.pause(true,"识别图像出错");
return;
}
var text = ocr.getText()
console.log("识别结果",text )
liblept.pixDestroy({addr pix = pix})
console.pause();
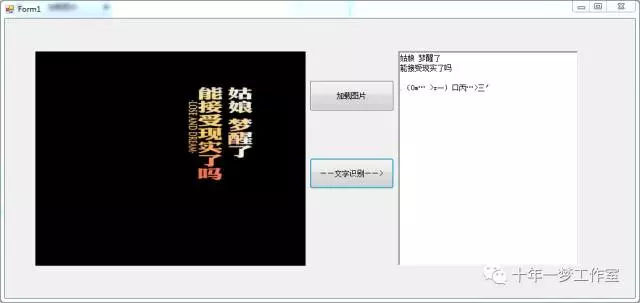
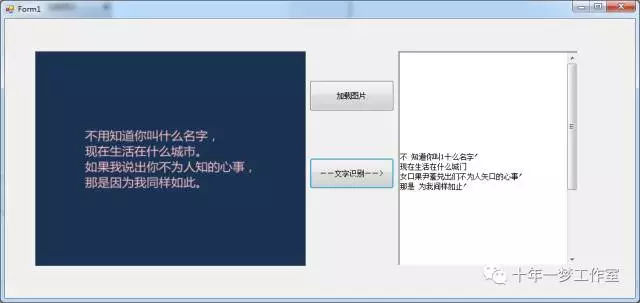
C#测试截图
开源的效果比商用的效果差不少,但是随着开源技术的进步,相信这种不需要联网的文字识别 准确率会越来越高。总有一天会让我们满意的。当然,准确率也需要通过不断的训练神经网络来提高。

神经网络训练的中文数据库
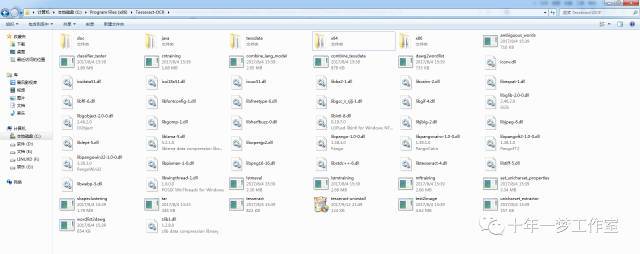
Tesseract —ocr安装后文件夹
Tessdata:存放各种文字库(chi_sim.traineddata:中文 等)
Tessseract.exe 即可以启动文件开始调用Tesseract 可以通过cmd方式调用,先cd到对应的目录,然后 输入 tesseract.exe 图片名 导出文件名(如:tesseract.exe 1.jpg 1) 就可以把和tesseract同目录的 1.jpg文件识别结果存放在 1.txt文件中。当然如果需要支持中文,需要在tessdata中添加 chi_sim.traineddata 文件,
然后 调用例子:tesseract.exe 1.jpg 1 -L chi_sim 制定是根据什么文字库进行识别。 当然图片地址可以引用全路径、输出结果也可以全路径如果只是想把Tesseract做为一个工具做文字解析,并不追求太高成功率使用者,这样即可满足需要了,直接通过CMD调用exe进行执行。
参考文献:
http://www.cnblogs.com/CleanBoy/p/4617438.html
http://blog.csdn.net/carson2005/article/details/7246090
http://blog.csdn.net/kaka20080622/article/details/50662935
http://bbs.aardio.com/forum.php?mod=viewthread&tid=12601
以上是关于如何通过Tesseract开源OCR引擎创建Android OCR应用的主要内容,如果未能解决你的问题,请参考以下文章