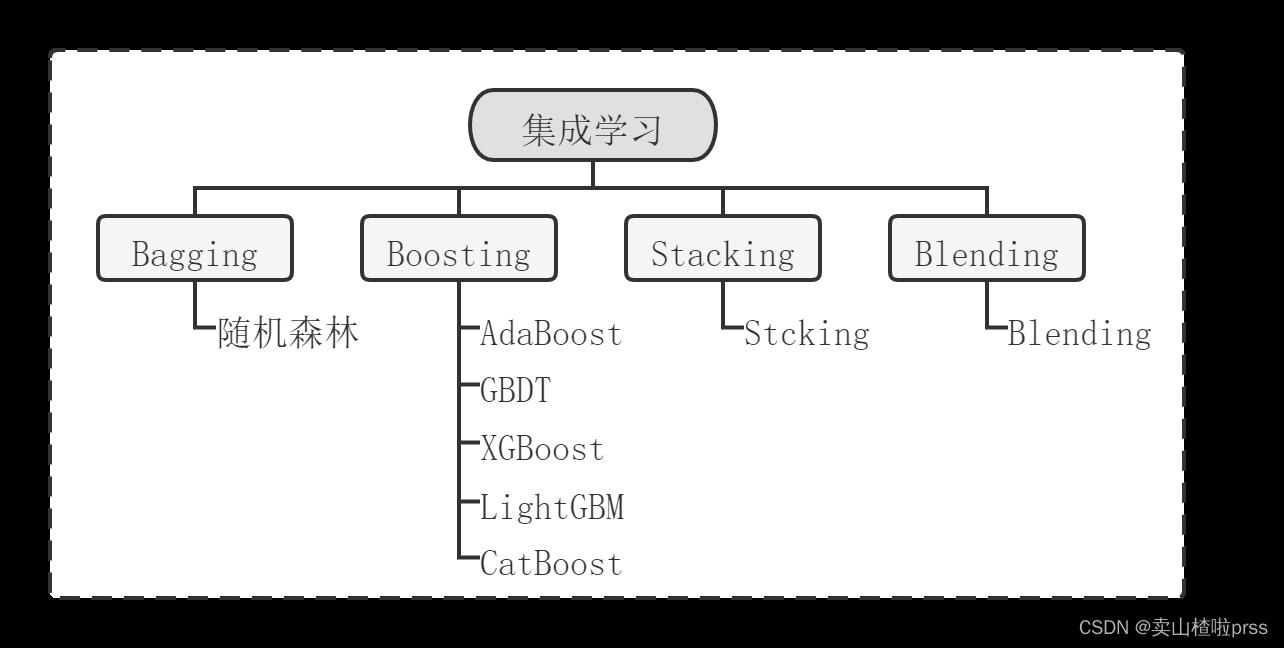
关于集成学习算法的概述(BaggingBoostingStackingBlending)
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于集成学习算法的概述(BaggingBoostingStackingBlending)相关的知识,希望对你有一定的参考价值。
近几年,集成学习(Ensemble Learning)在国内外研究以及数据科学竞赛中被广泛提及和应用,它是通过某种结合策略将多个单一模型结合起来得到一个强模型,这个强模型通常比单一模型有更强的性能。目前,集成学习模型的分类主要是根据个体学习器之间的关系进行区分,常用集成学习框架包括:Bagging、Boosting以及Stacking。
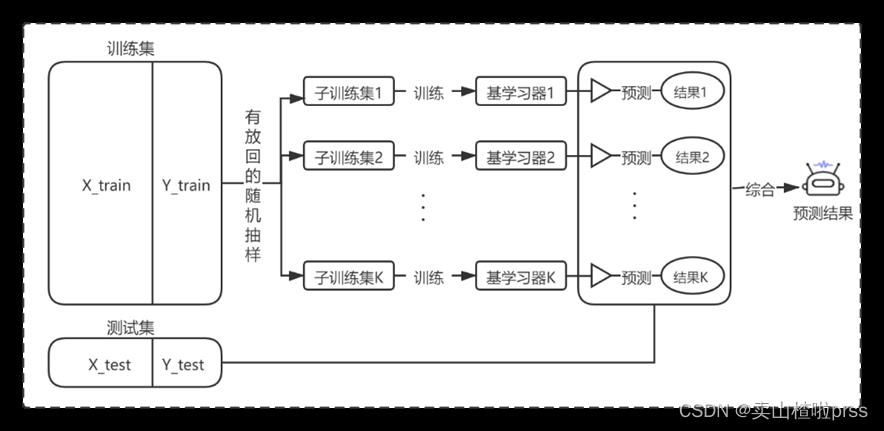
(1)Bagging算法
(1)Bagging算法也称为袋装法,其基本思想是将多个弱学习器通过并行的方式进行训练,然后再将所有训练好弱学习器通过集成策略组合为一个强学习器。这种方式可以实现以高偏差换取低方差,从而减小模型的整体误差。Bagging算法流程图如下:
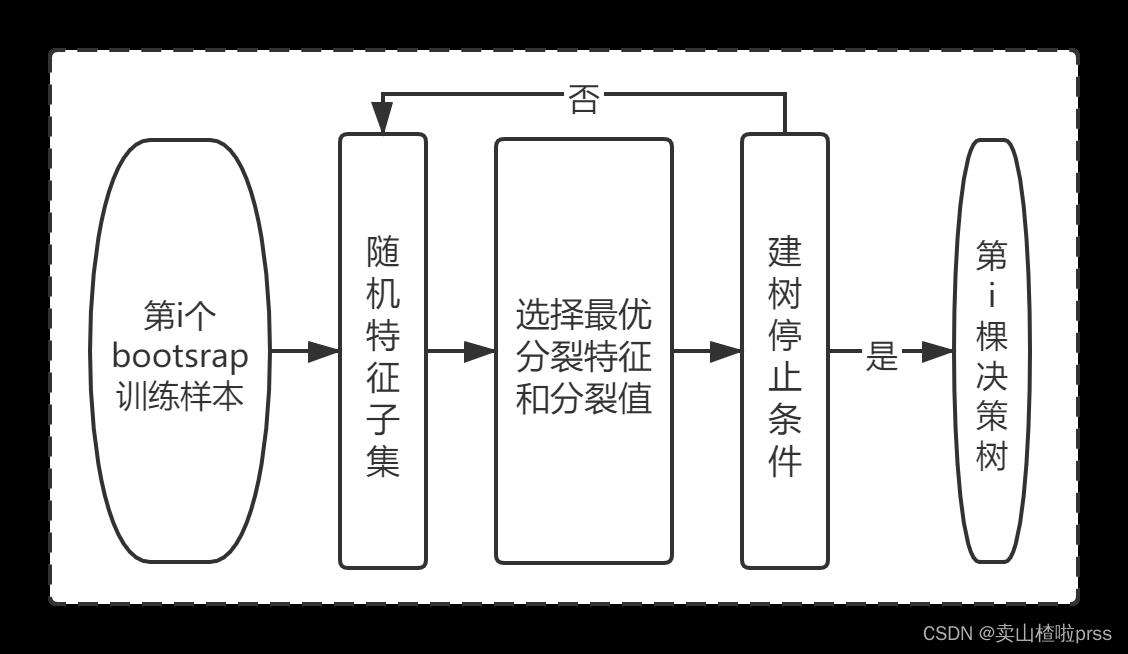
以随机森林为例
随机森林(Random Forests)是以决策树作为基分类器的一种Bagging集成学习方法,其基本思想是将多棵决策树独立并行训练后利用集成策略(投票或平均)来输出最终结果,其中每棵决策树均是在原始训练集中随机选择样本、随机选择特征构建而成。具体步骤如下:

单个树建立流程
随机森林具有许多优点,例如随机森林可以不进行交叉验证操作,即由于随机森林是通过自助式的随机抽取样本来构建决策树,所以每个决策树的生成都会有一部分的样本未参与,把这部分样本视作第i棵决策树的袋外样本(OOB),并使用第i棵训练好的决策树模型进行预测,最后得到随机森林的袋外错误率(误分样本数占样本总数的比例),以此来评价随机森林的效果,从而达到交叉验证的效果。但是随机森林也存在一定的不足,如在小样本数据时,往往表现不佳;在处理回归问题时效果不如分类;当数据的噪音太大,模型结果易出现过拟合。
不过总体来说,随机森林是一个非常优秀的数据挖掘算法,在实际落地中应用广泛。
(2)Boosting算法
(2)Boosting算法也称为提升法,其主要思想是将多个弱学习器通过串行的方式进行训练,然后将所有弱学习器集成为一个强学习器。在Boosting算法中每个弱学习器之间并不独立,即第一个弱学习器在学习的时候对每个样本出现的权重均视为等同,而当下一个弱学习器学习时会计算上一个弱学习器的训练误差,重新更新每个样本的权重(把被错分的样本权重调高,增加样本的出现几率)。具体的,Boosting算法流程图如下:
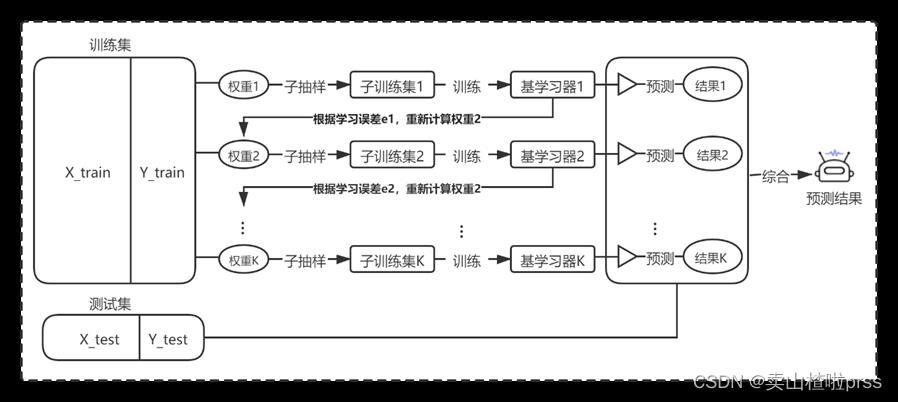
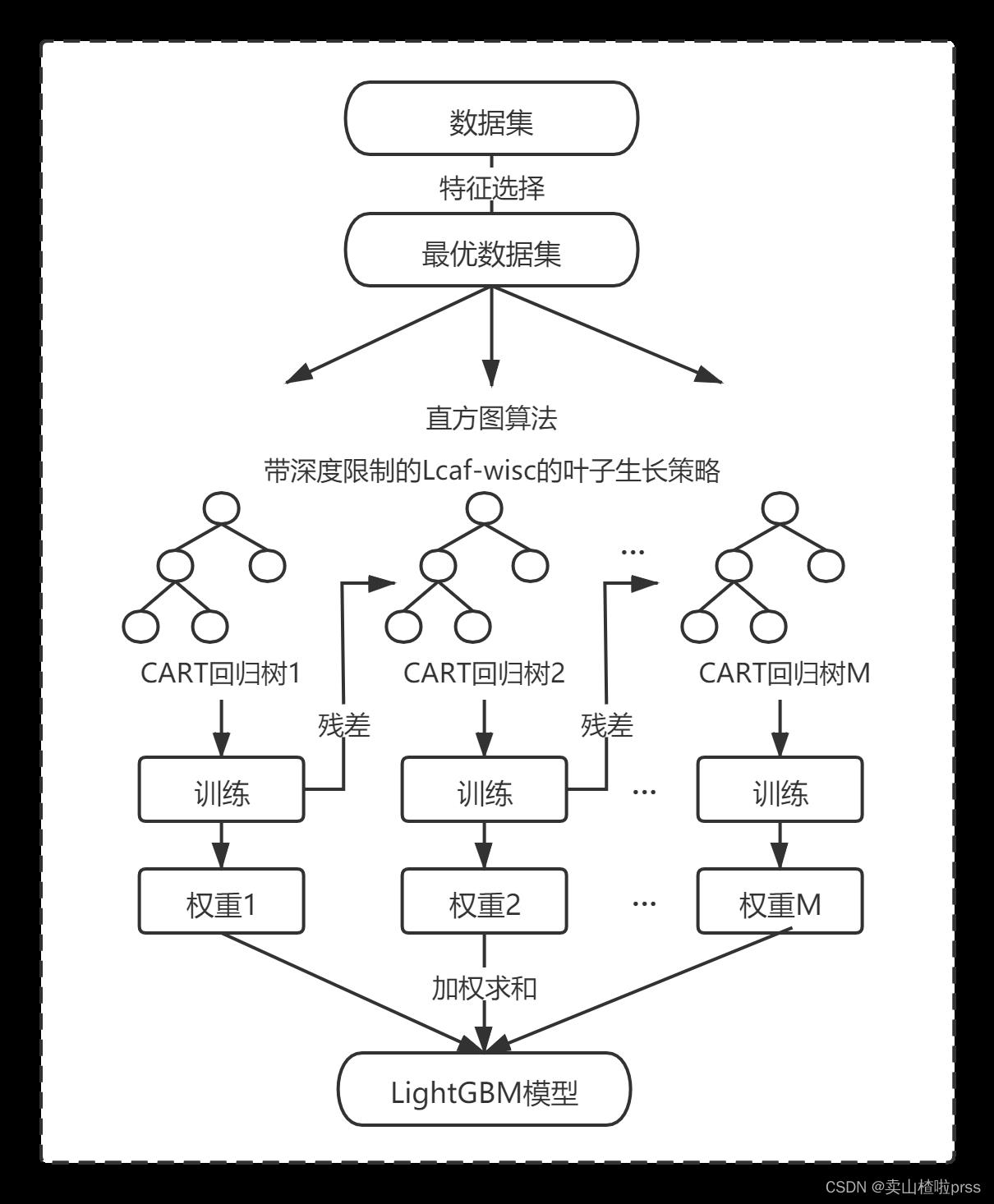
例如LIghtGBM算法
(3)Stacking算法和Blending算法
可转到:
关于融合模型的一些简单整理(Stacking、Blending)
参考文献:
基于E-LightGBM算法的5G套餐潜在客户识别研究[D],2022
以上是关于关于集成学习算法的概述(BaggingBoostingStackingBlending)的主要内容,如果未能解决你的问题,请参考以下文章