大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?相关的知识,希望对你有一定的参考价值。
大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?
大家知道,在生产环境的大数据集群中,在向资源管理器YARN提交作业时,我们一般会将作业提交到管理员指定的队列去执行,以利用 YARN 队列的资源隔离性确保作业能够获得足够的资源进行执行,从而确保SLA。
1 CDH 中如何指定 HIVE 作业执行时的 YARN 队列?
在以往的的大数据平台 CDH中:
- YARN 默认使用的资源调度器是公平调度器
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler; - HIVE 作业一般也是使用 hive on mr或hive on spark 执行引擎;
- 处于安全考量,一般推荐HIVE使用kerberos认证和sentry授权,此时要求关闭hive 代理功能,即hive.server2.enable.doAs=false;
此时为确保不同业务用户的 HIVE 作业提交到不同的 YARN 队列中,一般有两种选择:
- 在提交作业前手动指定队列,一般是通过 set mapreduce.job.queuename/mapred.job.queue.name/mapred.job.queuename = xxx 手工指定;(mapreduce.job.queuename is the new parameter name; mapred.job.queuename is changed to mapred.job.queue.name in hive-3.0.0 by HIVE-17584, and picked up by cdh in 2.1.1-cdh6.3.2)
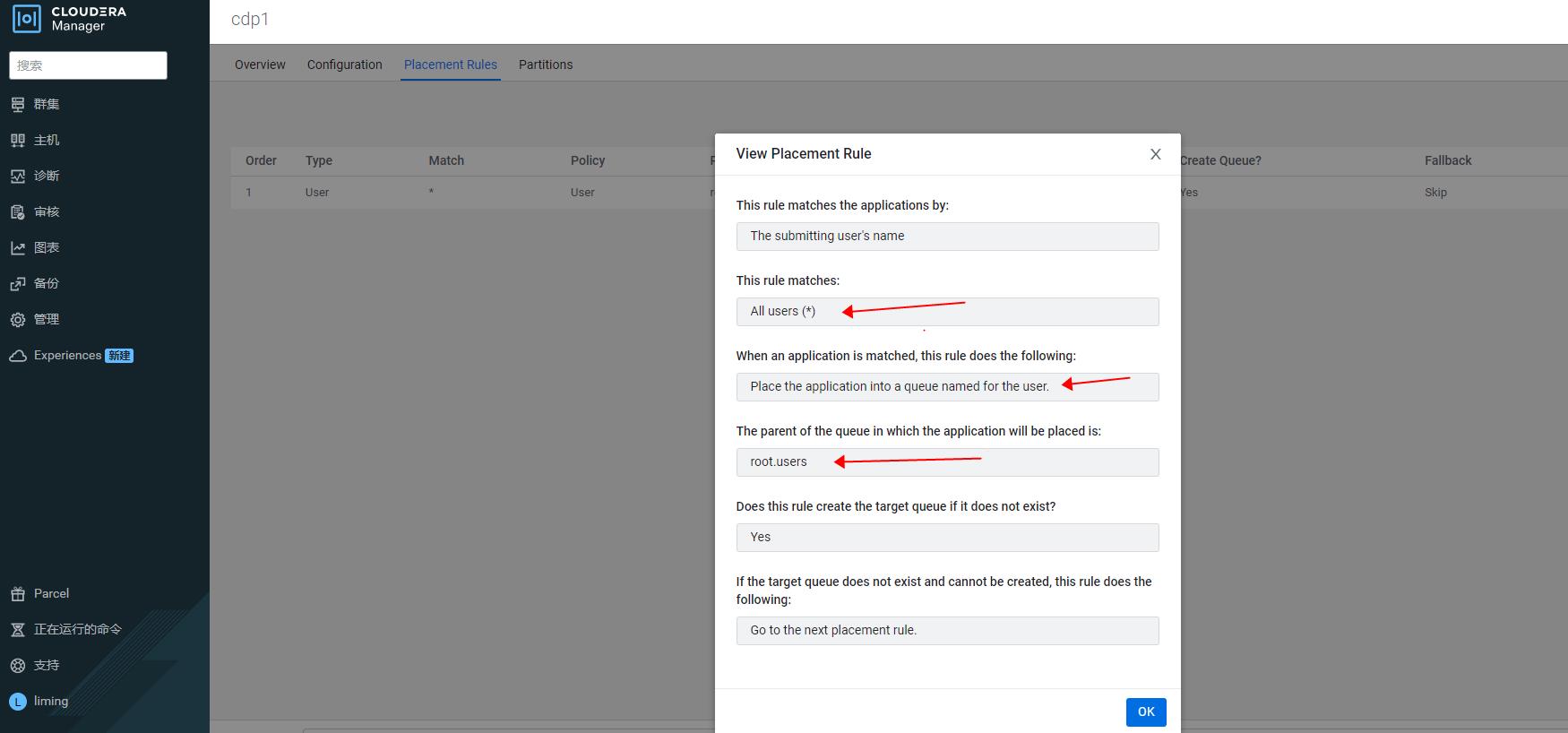
- 在 CDH 服务端"动态资源池配置"中配置"放置规则",指定使用基于用户名匹配到的指定队列(一般是 root.users.[username]);
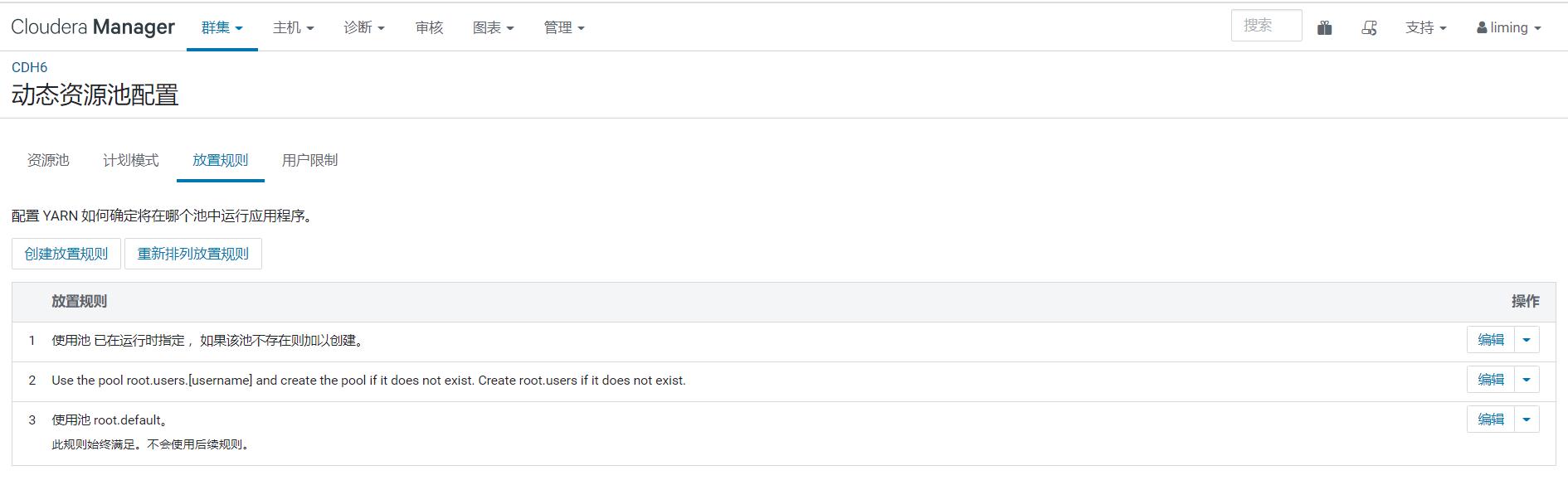
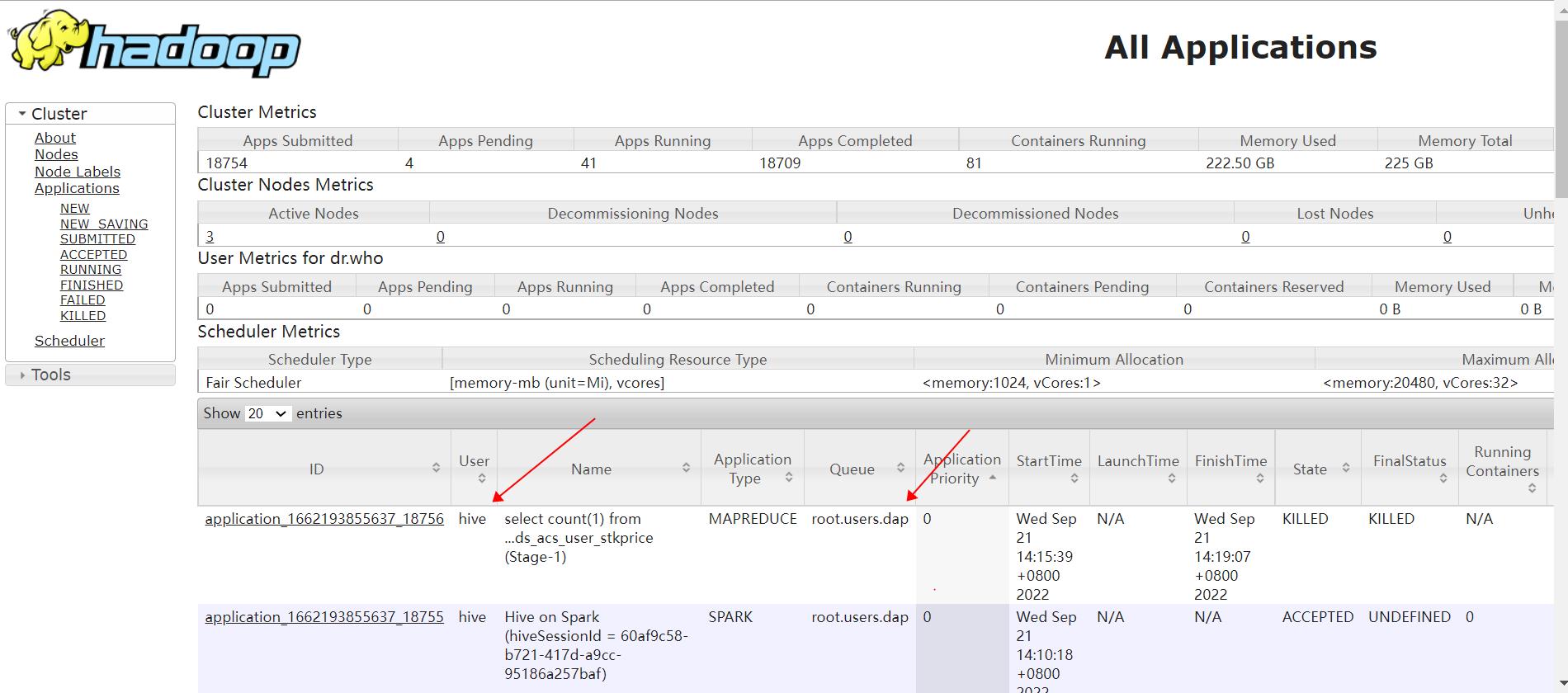
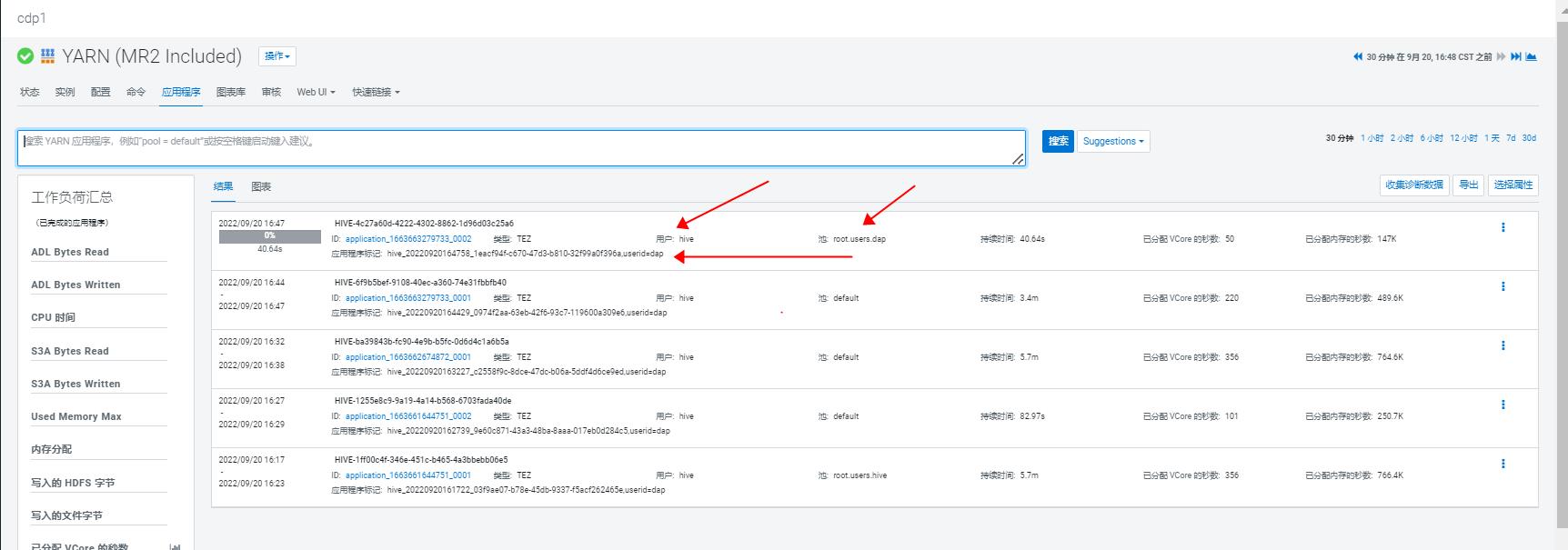
比如某业务用户dap提交的 hive 作业,在没有手动指定队列时,其使用的队列是 root.users.dap,达到了资源隔离的目的:(此时 HIVE 使用 kerberos 认证和 sentry 授权,关闭了 hive 代理功能,即 hive.server2.enable.doAs=false):
2 CDP 中默认配置下 HIVE 作业执行时的 YARN 队列?
在大数据平台 CDP 中:
- YARN 默认使用的资源调度器是容量调度器
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler; - HIVE 作业使用 hive on tez 执行引擎,不再支持 hive on mr/spark;
- 处于安全考量,一般推荐HIVE使用kerberos认证和ranger授权(cdp不再支持sentry),并要求关闭hive 代理功能,即hive.server2.enable.doAs=false;
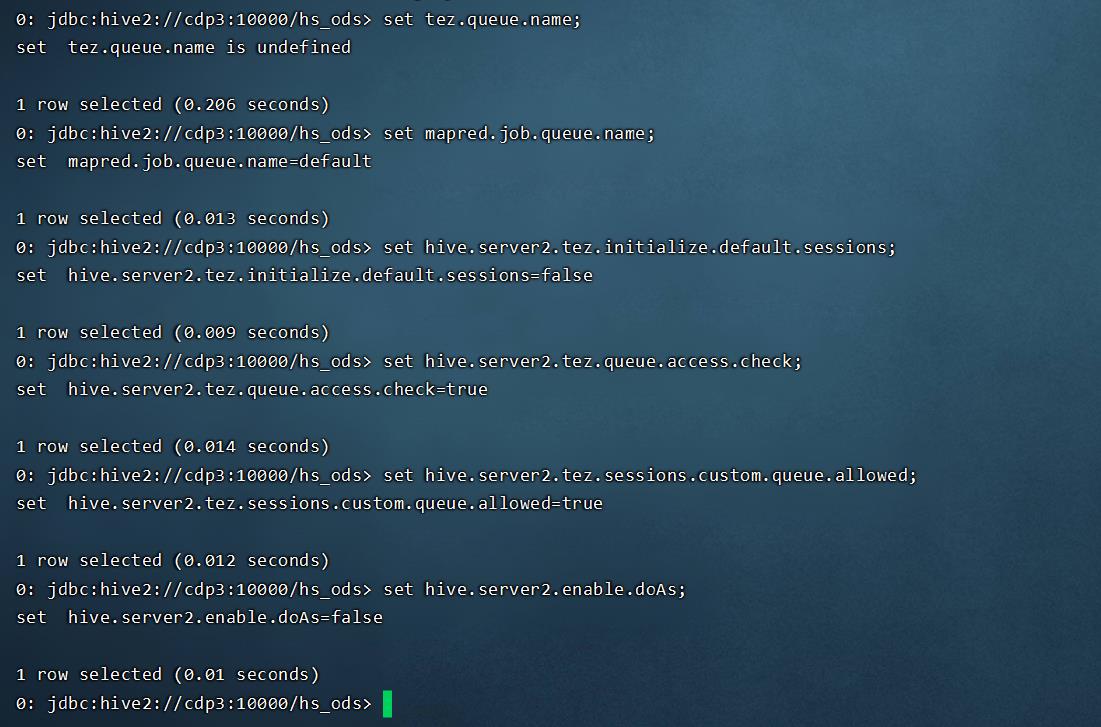
此时在没有手动指定队列时,所有 HIVE 作业执行时的 YARN 队列,是 default 或 root.users.hive,并不能达到资源隔离的目的:
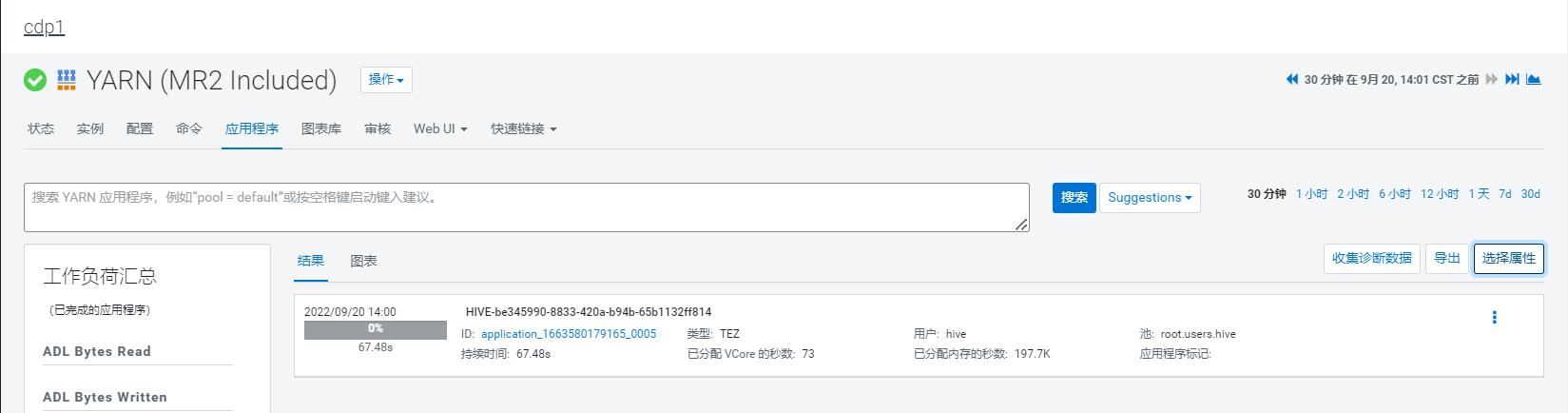
此时有以下几点需要注意:
- 当没有配置放置规则时,hive作业使用的是default 队列;
- 当如下配置放置规则时,hive作业使用的是root.users.hive;
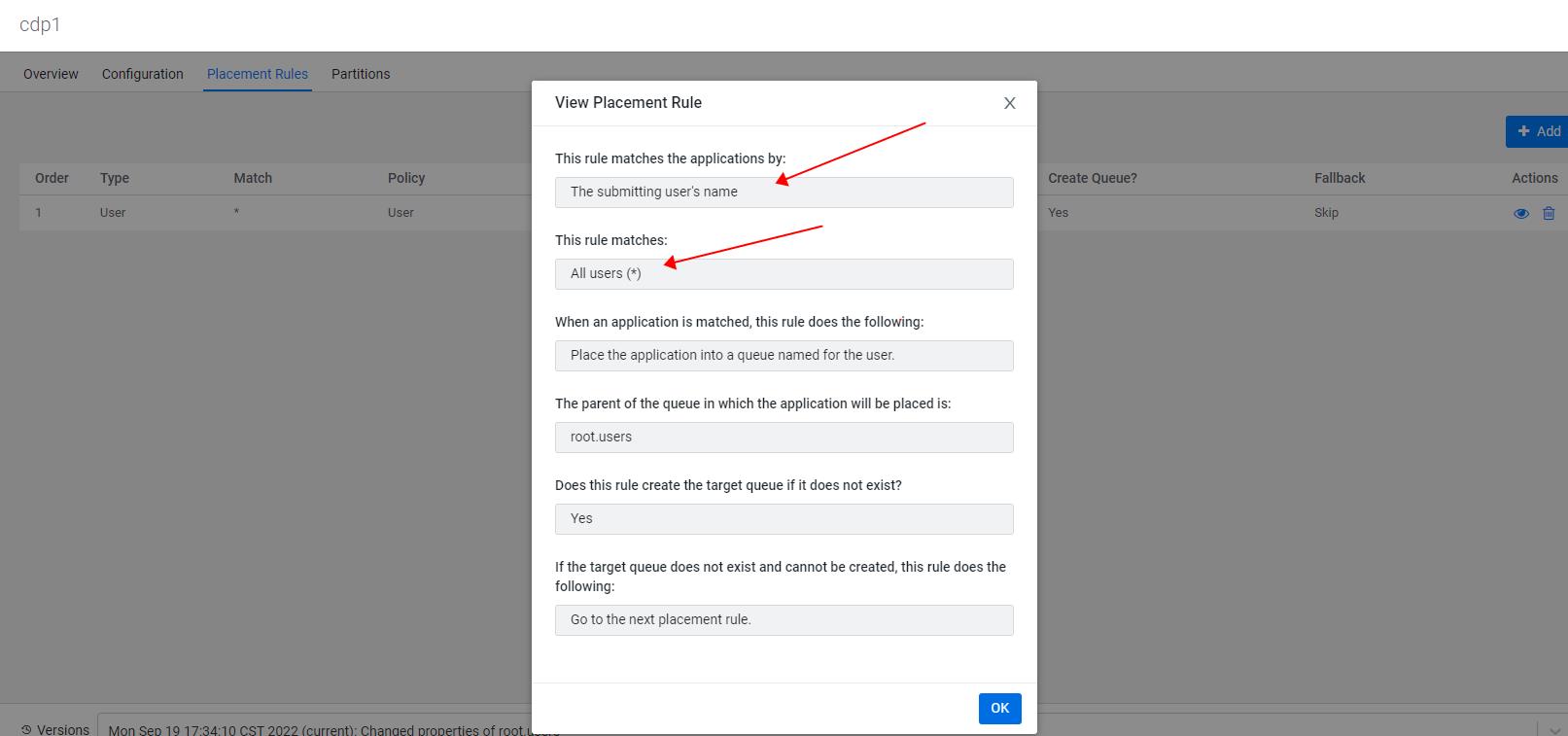
- 此时CDP中一些相关的参数的默认值如下:

那么如何达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列,以达到资源隔离的目的呢?请继续看。
3 CDP 中如何手动指定 HIVE 作业执行时的 YARN 队列?
CDP中要达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列,以达到资源隔离的目的,一种方法是手动指定YARN 队列。
由于CDP使用的是容量调度器而不是公平调度器,且只支持HIVE ON TEZ 而不是 hive on mr/spark,所以指定方式略有不同:
- 手动指定队列名时,由于hive on tez 背后有 tez session pool 和 tez default sessions 的概念,其指定方式略有不同,推荐使用参数 tez.queue.name 而不是 mapreduce.job.queuename/mapred.job.queue.name 指定队列名;
- 可以登录时指定队列名:比如 beeline -u “jdbc:hive2://cdp3:10000/hs_ods;principal=hive/_HOST@HUNDSUN.COM;” --hiveconf tez.queue.name=root.dap2 或者 beeline -u “jdbc:hive2://cdp3:10000/hs_ods;principal=hive/_HOST@HUNDSUN.COM?tez.queue.name=root.dap2”;
- 可以登录后提交SQL前指定队列名,比如 set tez.queue.name=root.users.dap;
- 为确保客户端手动指定的YARN 队列不会被覆盖,需要确保 CDP 服务端容量调度器的参数 yarn.scheduler.capacity.queue-mappings-override.enable 为 false,该参数默认值即为 false;

不过很多管理员倾向于将参数 yarn.scheduler.capacity.queue-mappings-override.enable 改为 true,以禁止用户在客户端随意指定队列,所以此时用户通过 set tez.queue.name=root.users.dap 手动指定的队列,会被服务端的队列放置规则等配置覆盖:
#用户在客户端指定的yarn 队列,会被服务端的放置规则覆盖,YARN RM 相关日志:
2022-09-21 09:39:01,306 INFO org.apache.hadoop.yarn.server.resourcemanager.RMAppManager: Placed application with ID application_1663663279733_0012 in queue: dap, original submission queue was: root.dap2
#用户在客户端指定的yarn 队列,会被服务端的放置规则覆盖,yarn 相关源码
org.apache.hadoop.yarn.server.resourcemanager.RMAppManager#copyPlacementQueueToSubmissionContext:
private void copyPlacementQueueToSubmissionContext(
ApplicationPlacementContext placementContext,
ApplicationSubmissionContext context)
// Set the queue from the placement in the ApplicationSubmissionContext
// Placement rule are only considered for new applications
if (placementContext != null && !StringUtils.equalsIgnoreCase(
context.getQueue(), placementContext.getQueue()))
LOG.info("Placed application with ID " + context.getApplicationId() +
" in queue: " + placementContext.getQueue() +
", original submission queue was: " + context.getQueue());
context.setQueue(placementContext.getQueue());
# 参数 yarn.scheduler.capacity.queue-mappings-override.enable 改为 true说明:
This function is used to specify whether the user specified queues can be overridden, this is a Boolean value and the default value is false.
If a queue mapping is present, will it override the value specified by the user? This can be used by administrators to place jobs in queues that are different than the one specified by the user.
4 CDP 中应如何配置服务端的队列放置规则,以达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列?
CDP 中应如何配置服务端的队列放置规则,以达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列,从而达到资源隔离的目的呢?CDP官方有如下建议:
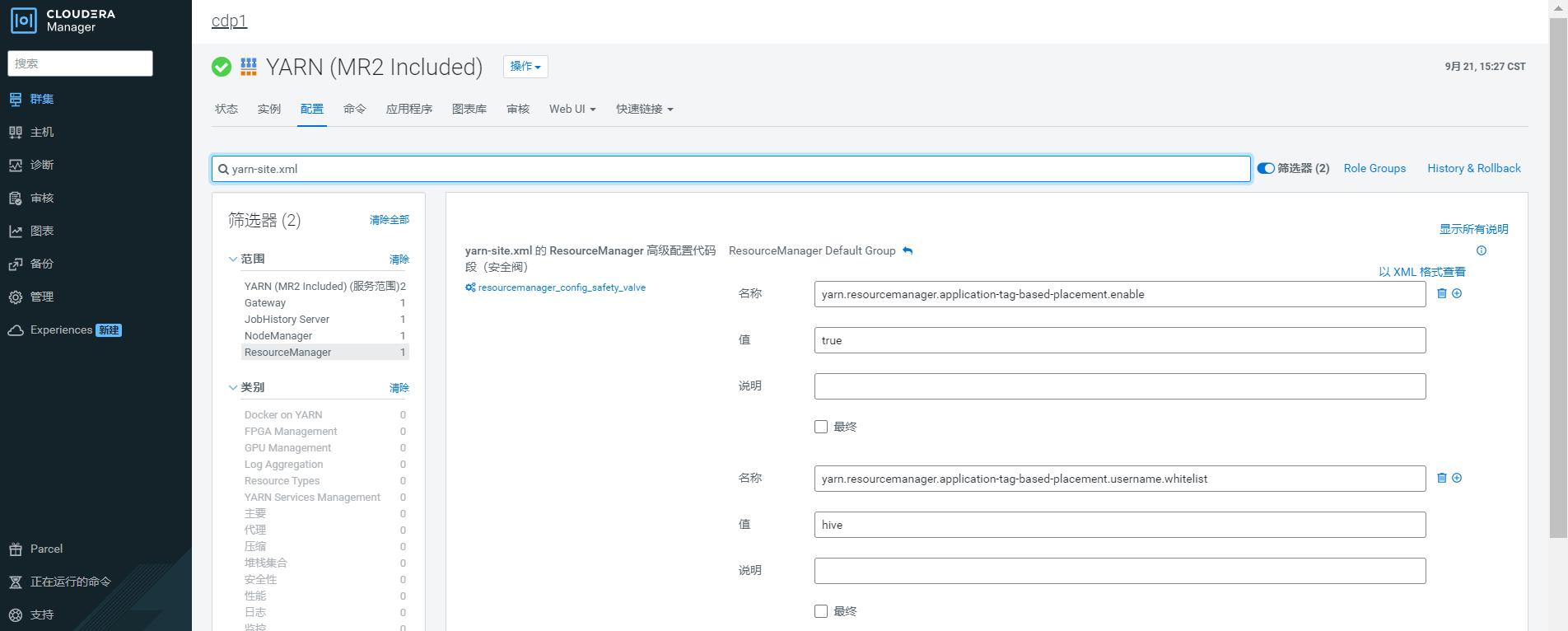
- 按照官方建议,修改 cdp yarn 服务端的配置,打开 yarn 基于标签的调度策略并允许 hive 用户使用基于标签的调度策略:
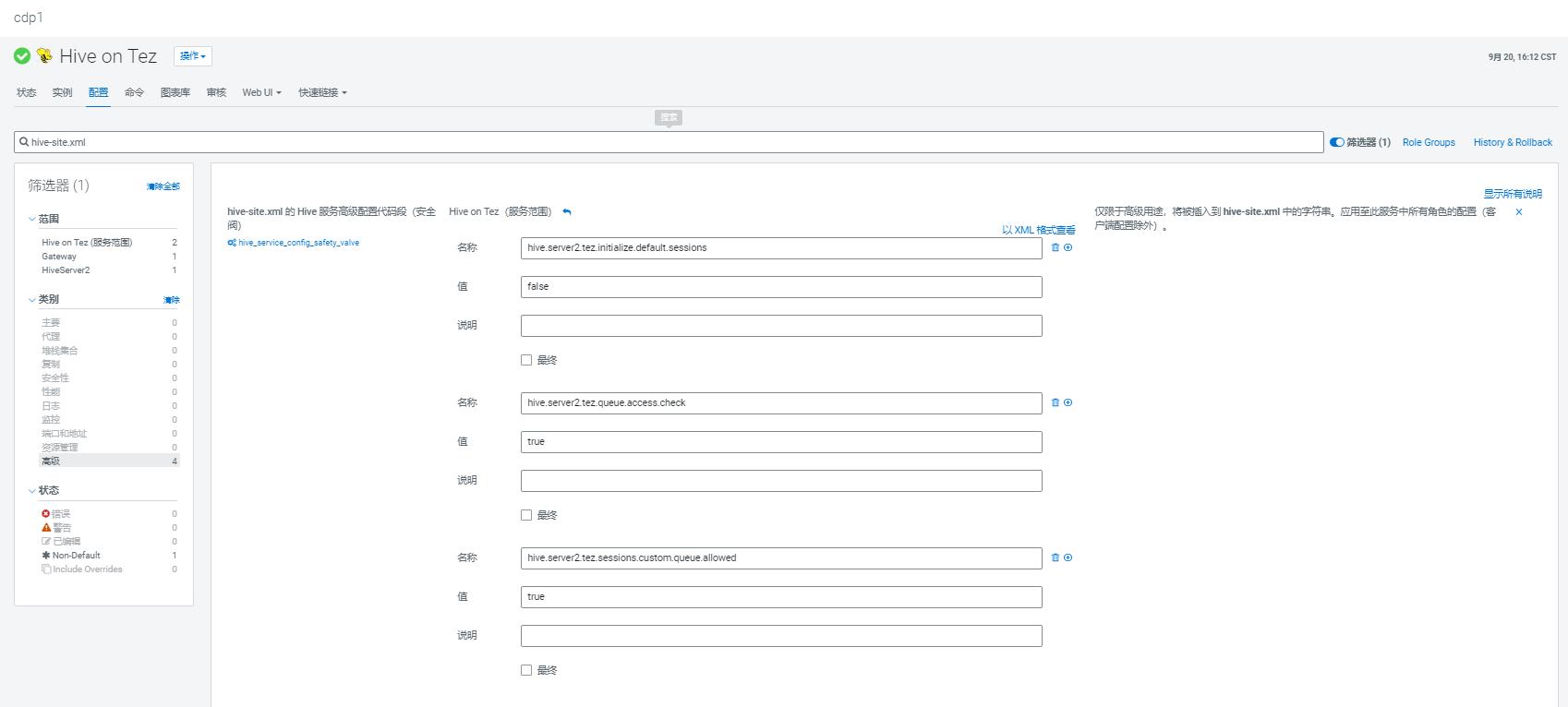
- 按照官方建议,修改 cdp hive on tez 服务端的配置,关闭 tez default sessions, 允许 tez session 使用指定的yarn队列:
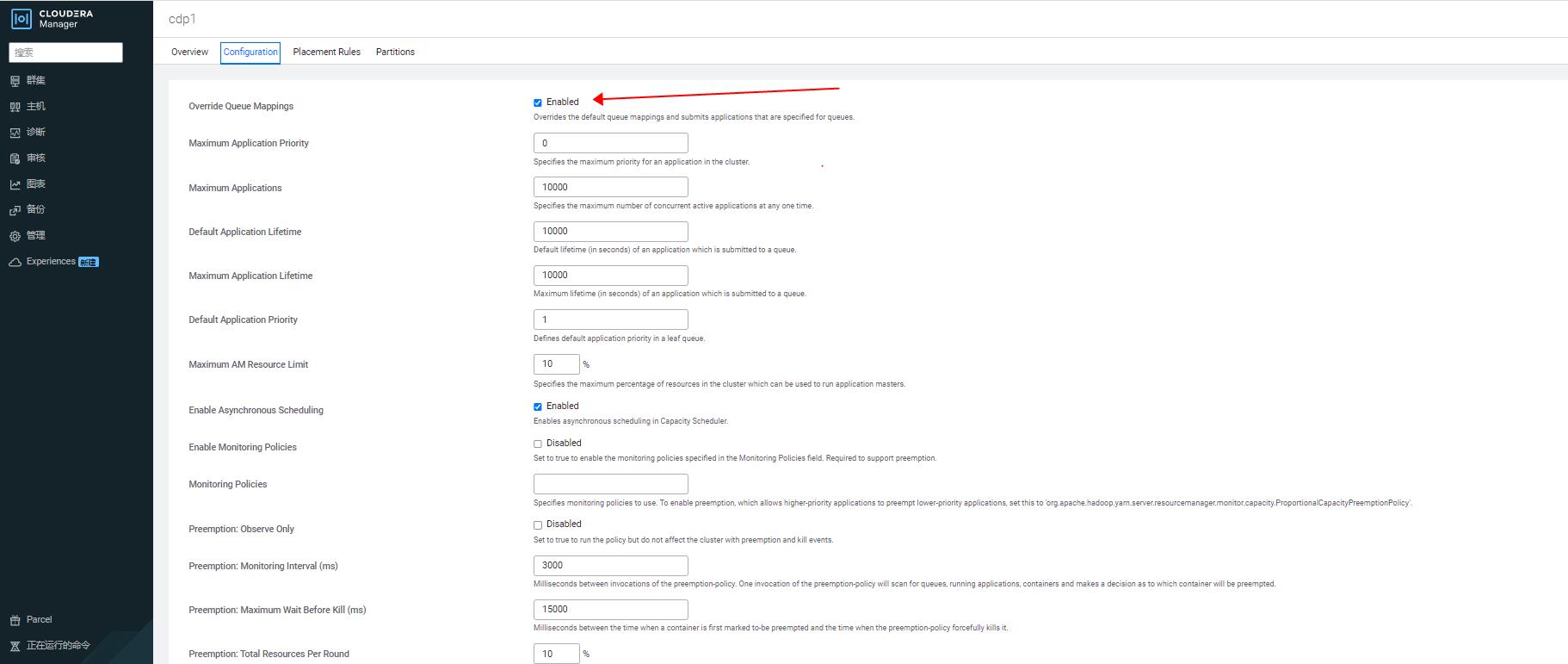
- 通过 cdp 的 yarn queue manager ui 配置容调度器的放置规则 placement rules:
- 通过 cdp 的 yarn queue manager ui,打开参数 yarn.scheduler.capacity.queue-mappings-override.enable,以覆盖用户在客户端手动指定的队列,从而禁止用户在客户端随意指定队列(该参数是否开启,视乎管理员对集群的管理规范):
再次提交作业,可以发现业务用户dap的作业提交到了rootusers.dap,达到了资源隔离的目的:
5 知识总结
- CDP 中默认使用容量调度器,CDH 默认使用公平调度器;
- CDP 和 CDH 都推荐不启用代理(hive.server2.enable.doAS=FALSE;
- CDP 中默认情况下,所有 HIVE 作业执行时的 YARN 队列都是 default 或 root.users.hive,并不能达到资源隔离的目的;
- CDP 中为达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列从而达到资源隔离的目的,用户可以在客户端通过参数 tez.queue.name 手动指定队列;
- 为确保用户在客户端通过参数 tez.queue.name 手动指定的队列,不被服务端公平调度器的放置规则覆盖,需要确保参数 yarn.scheduler.capacity.queue-mappings-override.enable为false;
- CDP 中为达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列从而达到资源隔离的目的,推荐管理员修改 cdp yarn 服务端的配置以打开 yarn 基于标签的调度策略并允许 hive 用户使用基于标签的调度策略,并修改 cdp hive on tez 服务端的配置以关闭 tez default sessions并允许 tez session 使用指定的yarn队列,同时通过 yarn queue manager ui 配置公平调度器的放置规则;(背后配置的是 capacity-scheduler.xml中的参数,如 yarn.scheduler.capacity.queue-mappings/yarn.scheduler.queue-placement-rules.app-name/yarn.scheduler.capacity.queue-mappings-override.enable/yarn.scheduler.capacity.root..acl_submit_applications/yarn.scheduler.capacity.root..acl_administer_queue 等);
6 相关参数
#yarn
yarn.resourcemanager.application-tag-based-placement.enable: Whether to enable application placement based on user ID passed via application tags. When it is enabled, userid=<userId> pattern will be checked and if found, the application will be placed onto the found user's queue, if the original user has enough rights on the passed user's queue.
yarn.resourcemanager.application-tag-based-placement.username.whitelist: Comma separated list of users who can use the application tag based placement, if it is enabled.
#tez
tez.am.resource.memory.mb
tez.am.resource.cpu.vcores
tez.task.resource.memory.mb
tez.task.resource.cpu.vcores
tez.session.client.timeout.secs: default 2 mins. Time (in seconds) to wait for AM to come up when trying to submit a DAG from the client. Only relevant in session mode. If the cluster is busy and cannot launch the AM then this timeout may be hit. In those case, using non-session mode is recommended if applicable. Otherwise increase the timeout (set to -1 for infinity. Not recommended)
tez.session.am.dag.submit.timeout.secs: default 5 mins.Time (in seconds) for which the Tez Application Master should wait for a DAG to be submitted before shutting down.Only relevant in session mode. Any negative value will disable this check and allow the AM to hang around forever in idle mode.
tez.am.mode.session: Boolean value. Execution mode for the Tez application. True implies session mode. If the client code is written according to best practices then the same code can execute in either mode based on this configuration. Session mode is more aggressive in reserving execution resources and is typically used for interactive applications where multiple DAGs are submitted in quick succession by the same user. For long running applications, one-off executions, batch jobs etc non-session mode is recommended. If session mode is enabled then container reuse is recommended.
tez.queue.name: String value. The queue name for all jobs being submitted from a given client.
tez.local.mode: Boolean value. Enable local mode execution in Tez. Enables tasks to run in the same process as the app master. Primarily used for debugging.
#hive
hive.server2.enable.doAs
hive.tez.container.size
hive.tez.cpu.vcores
hive.server2.tez.default.queues:A list of comma separated values corresponding to YARN queues of the same name. When HiveServer2 is launched in Tez mode, this configuration needs to be set for multiple Tez sessions to run in parallel on the cluster.
hive.server2.tez.initialize.default.sessions: default true.This flag is used in HiveServer2 to enable a user to use HiveServer2 without turning on Tez for HiveServer2. The user could potentially want to run queries over Tez without the pool of sessions.
hive.server2.tez.sessions.init.threads: If hive.server2.tez.initialize.default.sessions is enabled, the maximum number of threads to use to initialize the default sessions.
hive.server2.tez.queue.access.check: Whether to check user access to explicitly specified YARN queues. yarn.resourcemanager.webapp.address must be configured to use this.
hive.server2.tez.sessions.custom.queue.allowed:default true. Whether Tez session pool should allow submitting queries to custom queues. The options are true, false (error out), ignore (accept the query but ignore the queue setting).
hive.server2.tez.session.lifetime: default 162h. The lifetime of the Tez sessions launched by HS2 when default sessions are enabled.Set to 0 to disable session expiration
hive.server2.tez.sessions.per.default.queue
hive.server2.tez.interactive.queue
hive.server2.tez.sessions.restricted.configs
CDP: tez.queue.name/mapreduce.job.queuename/mapred.job.queue.name
CDH: mapreduce.job.queuename/mapred.job.queue.name/mapred.job.queuename
以上是关于大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?的主要内容,如果未能解决你的问题,请参考以下文章