redis源码阅读-主从复制增量复制细节
Posted 5ycode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码阅读-主从复制增量复制细节相关的知识,希望对你有一定的参考价值。
之前在写redis详解(内部分享版)的时候,主从复制的增量复制没有搞明白,昨天一个小伙伴问我增量复制偏移量的问题,我撸了一下源码。
想了解主从复制的细节,还得从源头来说,一个命令的执行,会有哪些操作。
master节点相关的操作
话说,readQueryFromClient 从客户端连接里读取到命令以后,整个处理逻辑的关键代码如下:
networking.c文件中
/**
* @brief ①读取客户端信息
* @param el
* @param fd 对应请求的fd
* @param privdata client客户端
* @param mask
*/
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask)
//将读取到的命令长度,添加到客户端的读取偏移量上
if (c->flags & CLIENT_MASTER) c->read_reploff += nread;
//处理输入流
processInputBufferAndReplicate(c);
void processInputBufferAndReplicate(client *c)
//非master节点,单机走这里
if (!(c->flags & CLIENT_MASTER))
//处理输入缓冲区
processInputBuffer(c);
else
//master节点处理
//获取master节点的应用偏移量(在没有加上当前这条命令之前的偏移量)
size_t prev_offset = c->reploff;
processInputBuffer(c);
//当前的客户端的应用位移-之前的应用位移,就是当前命令的数据长度
size_t applied = c->reploff - prev_offset;
//有数据主从复制
if (applied)
//③ master节点投递信息给所有的slave节点
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
//②命令读取与执行
void processInputBuffer(client *c)
//从querybuf读取的长度< querybuf的长度,一直执行
while(c->qb_pos < sdslen(c->querybuf))
if (c->argc == 0)
else
//执行命令
if (processCommand(c) == C_OK)
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI))
/**
* 更新当前客户的应用偏移量,直白些就是获取没有添加之前的缓冲区位移
* 更新值是客户端的读取偏移量(已经加上了当前的命令长度)- 读取缓冲区的长度 +本次读取的长度
*/
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
/**
* @brief 命令执行
* @param c 客户端
* @return int
*/
int processCommand(client *c)
//处理命令
//如果是集群,槽点不在本节点,且没有宕机会返回给客户端一个moved命令
/**
* ③从master的流里,复制并传输给所有的slaves节点
* @param slaves 所有的slave节点
* @param buf 当前客户端的缓冲区
* @param buflen 长度
*/
void replicationFeedSlavesFromMasterStream(list *slaves, char *buf, size_t buflen)
listNode *ln;
listIter li;
/* Debugging: this is handy to see the stream sent from master
* to slaves. Disabled with if(0). */
if (0)
printf("%zu:",buflen);
for (size_t j = 0; j < buflen; j++)
printf("%c", isprint(buf[j]) ? buf[j] : '.');
printf("\\n");
//④ 添加到背压,默认为null
if (server.repl_backlog) feedReplicationBacklog(buf,buflen);
//遍历所有的从节点,并投递过去
listRewind(slaves,&li);
while((ln = listNext(&li)))
client *slave = ln->value;
/* Don't feed slaves that are still waiting for BGSAVE to start */
//不给slave节点是等待RDB文件的客户投递
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
//实时投递过去
addReplyString(slave,buf,buflen);
在replication.c文件中
/**
* ④ 添加数据到复制背压队列server.repl_backlog,此队列会做增量同步
* @param ptr
* @param len
*/
void feedReplicationBacklog(void *ptr, size_t len)
unsigned char *p = ptr;
//表示最后的位置
server.master_repl_offset += len;
/**
* 背压是一个循环缓冲区,默认1mb大小
*/
while(len)
size_t thislen = server.repl_backlog_size - server.repl_backlog_idx;
if (thislen > len) thislen = len;
//将当前的命令复制到背压上
memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen);
server.repl_backlog_idx += thislen;
if (server.repl_backlog_idx == server.repl_backlog_size)
server.repl_backlog_idx = 0;
len -= thislen;
p += thislen;
server.repl_backlog_histlen += thislen;
if (server.repl_backlog_histlen > server.repl_backlog_size)
server.repl_backlog_histlen = server.repl_backlog_size;
/* Set the offset of the first byte we have in the backlog. */
server.repl_backlog_off = server.master_repl_offset -
server.repl_backlog_histlen + 1;
总结下吧,不总结下,大家都蒙圈了。
核心点:
- ① master接收到client端的命令后
- ② master从缓冲区中读取命令,并执行
- ③ master节点投递信息给所有的slave节点
- 如果有背压,数据会往背压里存一份(这里是处理增量同步的关键)
- while 遍历所有的节点并投递(如果slave是等待RDB文件的状态,不投递)
- ④ 添加到背压队列里
要了解增量复制,我们得好好的研究几个参数?
server.master_repl_offset当前master节点,主从复制最后的偏移量(这个偏移量是结束位置)server.repl_backlog当前master所有的数据server.repl_backlog_off当前master节点可以同步数据的开始偏移量server.repl_backlog_time_limit复制缓冲区还有有效期,如果这么长时间都没动,就释放了server.repl_no_slaves_since最后一次主从同步的时间
超过repl_backlog_time_limit 这么长时间没有slave节点来消费,就直接将repl_backlog 释放了
看到这是不是比较清晰了?
那何时会开启背压呢?
是在master节点接收到psync命令的时候,这个命令是什么时候被调用的?是在slave周期性轮训的时候会调用(一般是连接以后,由状态控制)
/**
* 1,master接到psync命令的时候,会创创建
* 2,slave 发起sysnc的时候创建
*/
void createReplicationBacklog(void)
serverAssert(server.repl_backlog == NULL);
server.repl_backlog = zmalloc(server.repl_backlog_size);
server.repl_backlog_histlen = 0;
server.repl_backlog_idx = 0;
/* We don't have any data inside our buffer, but virtually the first
* byte we have is the next byte that will be generated for the
* replication stream. */
server.repl_backlog_off = server.master_repl_offset+1;
/**
* master接收到psync的处理
* @param c
*/
void syncCommand(client *c)
//创建背压,用于增量同步
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL)
changeReplicationId();
clearReplicationId2();
createReplicationBacklog();
salve节点的相关操作
我们再看下redis是如何开启主从复制的。
redis主从的关键是replicaof masterIp masterPort
这个可以启动一个redis执行,就变为了slave,可以在redis启动的时候,在配置文件中配置replicaof masterIp masterPort
来看下代码里执行了什么
void replicaofCommand(client *c)
//表示master节点,不能执行该命令
if (server.cluster_enabled)
addReplyError(c,"REPLICAOF not allowed in cluster mode.");
return;
/**
* 如果命令未 replicaof no one ,那么本机从slave切换为master
* 主从切换的时候执行
*/
if (!strcasecmp(c->argv[1]->ptr,"no") && !strcasecmp(c->argv[2]->ptr,"one"))
else
//已经标记为slave客户端了,不能再执行该命令了
if (c->flags & CLIENT_SLAVE)
addReplyError(c, "Command is not valid when client is a replica.");
return;
/**
* 检查是否已经建立了链接,已建立,直接返回已建立链接的消息
*/
if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr)&& server.masterport == port)
addReplySds(c,sdsnew("+OK Already connected to specified master\\r\\n"));
return;
/**
* 这个方法里主要是设置master的host和port
* 如果是主从切换,会断掉所有的slave,并清除所有的阻塞方法
* slave的状态设置成了 server.repl_state == REPL_STATE_CONNECT
*/
replicationSetMaster(c->argv[1]->ptr, port);
- 各种校验,确保能正确执行命令
replicationSetMaster设置这个slave对应的master信息- 这里剔除了之前master的各类信息
这个命令主要是设置,真正执行是在周期性循环里
/**
* @brief 时间事件执行
* @param eventLoop fd
* @param id fd
* @param clientData
* @return int
*/
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData)
/**
* 主从复制,当server.hz=10的时候10次轮训执行一次
*/
run_with_period(1000) replicationCron();
/**
* 主从复制周期任务,10次轮训调用一次
* 状态机驱动
*/
void replicationCron(void)
//针对各种状态,如果多长时间没有响应,就取消了
/**
* 已经确定了主从,就执行connectWithMaster,
* 和master建立链接后,master会告诉slave是做全同步还是增量同步
*/
if (server.repl_state == REPL_STATE_CONNECT)
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
//重点
if (connectWithMaster() == C_OK)
serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started");
/**
* server.masterhost 只有slave才会执行
*/
if (server.masterhost && server.master &&
!(server.master->flags & CLIENT_PRE_PSYNC))
/**
* 不定时的向主机发送ack信息
*/
replicationSendAck();
//这里master还会不停地ping salve节点,用来判断是否主观下线
//对所有等待RBD文件的salve 发送一个\\n
//这里也是重点,定期会清理掉
if (listLength(server.slaves) == 0 && server.repl_backlog_time_limit &&server.repl_backlog && server.masterhost == NULL)
time_t idle = server.unixtime - server.repl_no_slaves_since;
//判断下最后一次主从到现在的时间,超过了这个配置时间,就直接释放
if (idle > server.repl_backlog_time_limit)
//释放积压缓冲区
freeReplicationBacklog();
/**
* REPL_STATE_CONNECT 状态执行,
* ①,通过非阻塞链接master
* ②,链接成功,创建一个处理器为syncWithMaster的FileEvent(具体执行等下一个loop中触发)
* 创建一个处理为syncWithMaster的fileEvent
* @return
*/
int connectWithMaster(void)
int fd;
//和主库建立链接(这个fd是对应master的socket)
fd = anetTcpNonBlockBestEffortBindConnect(NULL,server.masterhost,server.masterport,NET_FIRST_BIND_ADDR);
if (fd == -1)
return C_ERR;
//完成链接后,创建事件以syncWithMaster去处理,(fd是对应master的socket)
if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) ==AE_ERR)
close(fd);
return C_ERR;
//修改状态
server.repl_state = REPL_STATE_CONNECTING;
return C_OK;
//重点中的重点,这里主要是状态机驱动(fd是对应master的socket)
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask)
//
if (server.repl_state == REPL_STATE_SEND_PSYNC)
//发起psync命令,异常就直接中断了
if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR)
goto write_error;
//改为等待接收PSYNC的结果
server.repl_state = REPL_STATE_RECEIVE_PSYNC;
return;
//读取psync中的结果
psync_result = slaveTryPartialResynchronization(fd,1);
/*
* @param fd master对应的额socket
* @param read_reply 是否读取恢复,0 否,1 是
* @return
*/
int slaveTryPartialResynchronization(int fd, int read_reply)
//通过read_reply 判断发送命令还是读取
// 发送 PSYNC
if (!read_reply)
//如果有cached_master,表示是中断了的,cached_master 是上一个master的客户端
if (server.cached_master)
/**
* server.cached_master->reploff+1 为之前同步的master的偏移量
* psync_offset 将之前的偏移量读入到psync_offset 作为新的起始的偏移量
*/
snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1);
//发送psync同步命令给主库 这个时候,会携带当前slave的已经同步的偏移量 psync_offset
reply = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC",psync_replid,psync_offset,NULL);
/**
* 读取PSYNC的回复
* 返回 +FULLRESYNC 全量同步
* 返回 +CONTINUE 增量同步
*/
if (!strncmp(reply,"+CONTINUE",9))
replicationResurrectCachedMaster(fd);
void replicationResurrectCachedMaster(int newfd)
//设置主从复制为
server.repl_state = REPL_STATE_CONNECTED;
//使用处理器readQueryFromClient创建一个FileEvent,从master的缓冲区读取
if (aeCreateFileEvent(server.el, newfd, AE_READABLE, readQueryFromClient, server.master))
捋一下:分两步
第一步:
- 在slave上执行
replicaof masterIp masterPort命令 - 这个slave 可能是一个新,也可能是一个中断的
- 如果是中断的,会将原来的slave持有的master客户端放入
cached_master上 - 将masterId和port赋值给 主从复制的master上
第二步
- 在slave客户端执行周期性任务的时候
- 在
connectWithMaster中- 针对replicaof 的ip和port,建立一个socket连接,并返回fd
- 然后注册一个处理器为
syncWithMaster的fileEvent 去处理
- 在
syncWithMaster中- 发起PSYNC命令,这个时候会带上
cached_master上之前已经处理的偏移量 - 然后读取PSYNC的返回结果
- 返回
+FULLRESYNC重新全量复制 - 返回
+CONTINUE增量复制,具体代码在replicationResurrectCachedMaster
- 返回
- 发起PSYNC命令,这个时候会带上
- 在
replicationResurrectCachedMaster中- 注册了一个处理器为
readQueryFromClient的FileEvent readQueryFromClient是要从master客户端里接收master发过来的增量信息
- 注册了一个处理器为
到这,流程都整理清楚了。
我们回过头来看下在master中PSYNC做了什么。
master 处理PSYNC 命令
直接上代码
/**
* master接收到psync的处理
* @param c
*/
void syncCommand(client *c)
/**
* psync 命令处理,决定是全量复制还是增量复制
*/
if (!strcasecmp(c->argv[0]->ptr,"psync"))
if (masterTryPartialResynchronization(c) == C_OK)
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
else
char *master_replid = c->argv[1]->ptr;
if (master_replid[0] != '?') server.stat_sync_partial_err++;
//创建背压,用于增量同步(到这里,一定是进行全量复制)
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL)
changeReplicationId();
clearReplicationId2();
createReplicationBacklog();
//然后做BGSAVE 来生成RDB,传输给客户端
/**
* 决定是全量还是增量
* @param c
* @return
*/
int masterTryPartialResynchronization(client *c)
//解析psync 命令传递过来的偏移量
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
C_OK) goto need_full_resync;
//将背压里的数据添加到slave 客户端的缓冲区里
psync_len = addReplyReplicationBacklog(c,psync_offset);
/**
*将背压里的数据添加到slave 客户端的缓冲区里
* @param c master 持有的slave 客户端(发起replicaof命令的客户端)
* @param offset 开始的偏移量
* @return
*/
long long addReplyReplicationBacklog(client *c, long long offset)
while(len)
long long thislen =((server.repl_backlog_size - j) < len) ?
(server.repl_backlog_size - j) : len;
//复制指定的长度的数据恢复过去,slave中的readQueryFromClient就能读取到
addReplySds(c,sdsnewlen(server.repl_backlog + j, thislen));
len -= thislen;
j = 0;
return server.repl_backlog_histlen - skip;
整个过程整理成流程图如下:
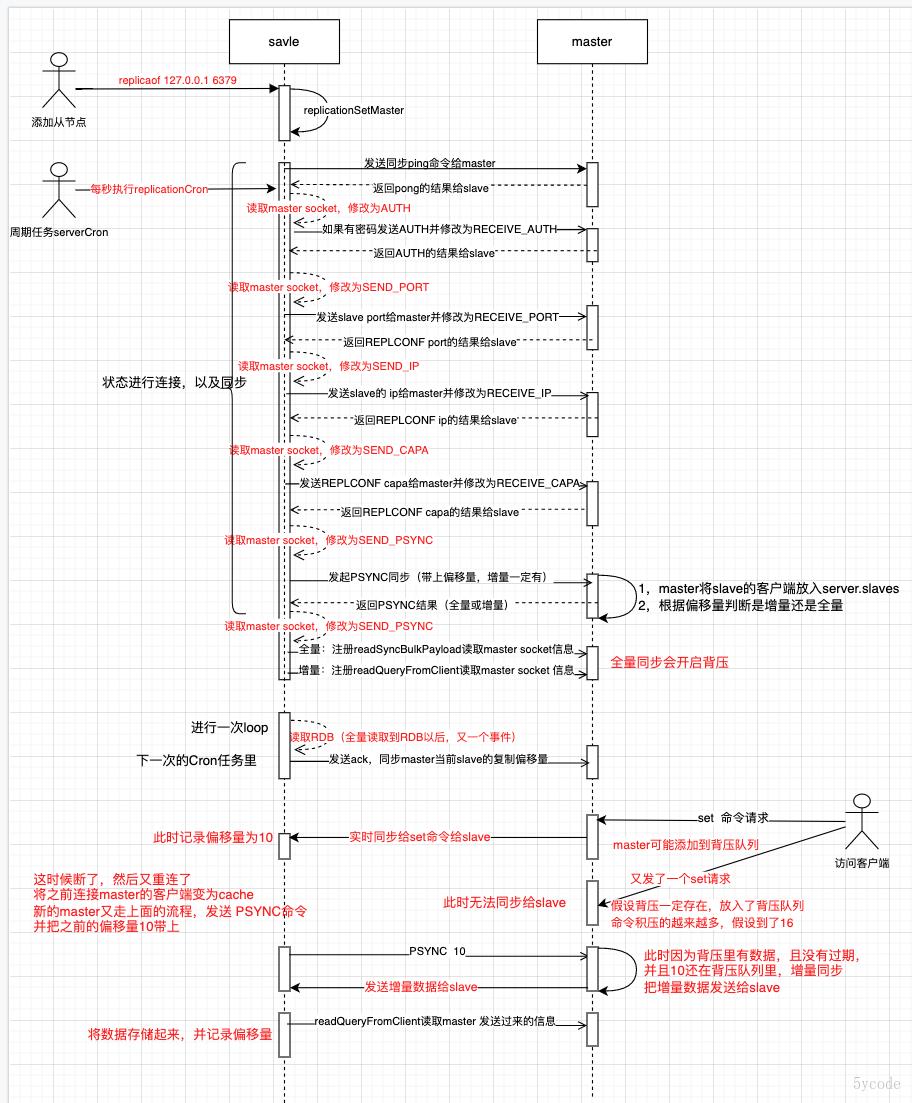
附带一张状态流转图

总结:
- 在开启全量同步以后会开启背压
- 背压是有大小限制和有效期的
- 大小配置:
repl-backlog-size默认1MB - 有效期配置化:
repl-backlog-ttl默认1小时
- 大小配置:
- 如果在1小时内,没有slave访问背压
- 在周期任务serverCron里的
replicationCron函数里会进行释放
- 在周期任务serverCron里的
如果不对参数进行优化,在默认情况下,写并发相对较高的情况下能利用到增量复制的情况相对比较少(还得看综合情况)。
这里需要考虑:
- 客观下线时间(时间就了偏移量不在范围内了)
- 单位时间内写入命令的数据多少(写的多了偏移量就不在范围内了)
- 正常情况下全量同步一个小时候内,如果没有客户端操作背压,背压队列会被释放
- 释放以后,在命令执行的时候,不会往背压队里里存放数据
所以增量复制的作用主要用于全量复制以后的增量复制。
举个例子:
- master的偏移量到了100
- 这个时候slave 发了一条
psync 10的命令过来,master返回全量复制 - master把全量数据打包成RDB文件,同时开启积压缓冲区(=0)
- 这个时候master新进入的数据会进入积压缓冲区一份(偏移量从101开始)
- 这个时候slave有两种情况,一种是RDB解析成功,一种是RDB解析失败
- 解析成功
- 发送
psync 100给master,master返回增量复制 - master 将101 到150的数据推送过去
- 新进来的命令151 就实时的传递了过去
- 发送
- 解析失败
- 比如解析到了70,失败了,slave记录的偏移量为70
- 这个时候发送
psync 70给master - master 判断70不在积压缓冲区101~150内,返回全量复制,重新生成RDB,并重置积压缓冲区(偏移量就为151)
- slave 接收到RDB会把自己清空,然后恢复RDB
- 解析成功
- master的周期性任务会1个小时后把积压缓冲区设置为null
redis系列文章
redis详解(内部分享版)
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了