CartPole-v1 50行python实现
Posted pysnow530
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CartPole-v1 50行python实现相关的知识,希望对你有一定的参考价值。
CartPole-v1 50行python实现
CartPole-v1 50行python实现
背景
很久没有写文章了,github上维护的博客 https://blog.dong.black/ 上篇还是今年5月15号的,距离现在也有一个多月了。
之前在优达学过一小段时间的机器学习,感觉挺有意思,最近又看到了gym,想动手再尝试一把。
CartPole-v1是gym中比较经(jian)典(dian)的题目,号称机器学习中的 hello world,比较适合我这种小白。趁着周末的闲功夫,求解一下。
题目
官方其实已经给出解释了:
Reinforcement learning Q-learning approach to OpenAI Gym’s CartPole environment.
这本质上是一个Q-learning问题,但是作为强化学习的 hello world,其实也有很多其它的解法。
作者尝试过使用DQN解,但是收敛速度和稳定性差强人意。个人电脑吱吱转,算法却死活不收敛。
罢了,使用线性模型蒙一下吧。
线性模型
基本思路,是使用单个神经元。这里也不反向传导了,直接在当前空间随机探索,然后查看效果。
激活函数就是根据结果符号输出action,可以简单理解为 int(input > 0)。
基本的过程如下:
- 随机选取 weights + bias
- 生成随机步长 delta_weights
- 计算更新后 weights 可以得到的回报 rewards
- 如果 rewards 相较之前增大了,应用 delta_weights;减小了,反向应用 delta_weights
算法简单粗暴,但是针对这个简单粗暴的题目,效果挺好。
代码
代码量只有50行,也没有比较复杂的逻辑,所以这里就直接贴出来了。
import gym
import numpy as np
import matplotlib.pyplot as plt
def predict(state, weight):
return int(np.dot(state, weight) >= 0.0)
def run_once(env, weight):
state = env.reset()
rewards = 0
while True:
# env.render()
rewards += 1
action = predict(state[1:], weight)
state, reward, done, info = env.step(action)
if done:
return rewards
def fix_weight(weight, delta_weight, this_rewards, last_rewards):
return weight + delta_weight * (1 if this_rewards > last_rewards else -1)
def main():
episodes = 100
env = gym.make('CartPole-v1')
weight = np.random.random(3)
last_rewards = None
reward_list = []
for i in range(episodes):
delta_weight = np.random.random(weight.shape) * 2 - 1
this_rewards = run_once(env, weight + delta_weight)
if last_rewards is not None and this_rewards != last_rewards:
weight = fix_weight(weight, delta_weight, this_rewards, last_rewards)
last_rewards = this_rewards
reward_list.append(last_rewards)
print(i, last_rewards, weight)
plt.plot(reward_list)
plt.show()
if __name__ == "__main__":
main()
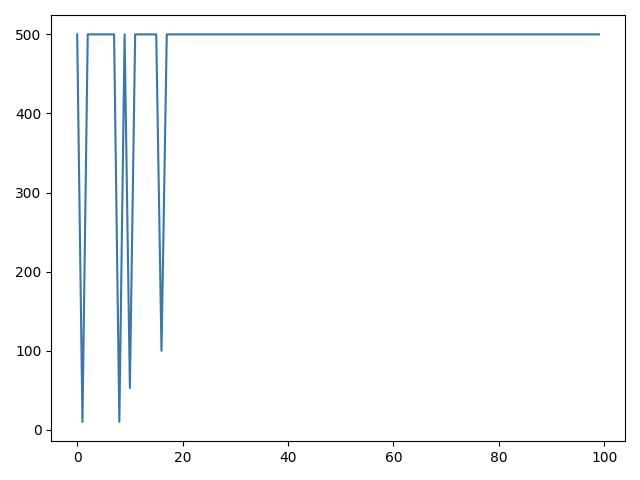
过程中的优化及问题
该模型中没有太多机器学习的核心理论。不过过程中,有借鉴一些机器学习的理念,都比较浅显,这里不做过多解释。
总结下过程中优化的几个点:
- 这个题目实际上是个二值问题,而且两个值是对称的,bias实际上没有意义,去掉
- 输入是4个参数,但是实际上位置信息很难用来做优化,对总体回报影响太小,去掉
问题:
这个算法大部分时候效果可以,但是存在以下两个问题:
- 某些情况下来回震荡,不能收敛
- 大部分回合500,但是后期仍会出现回报较低的情况 见 CartPole-v1线性模型局限
嗯,这两个问题挺典型,值得做进一步研究。
以上是关于CartPole-v1 50行python实现的主要内容,如果未能解决你的问题,请参考以下文章