机器学习介绍
Posted chocolate2018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习介绍相关的知识,希望对你有一定的参考价值。
机器学习
Sitara机器学习工具包通过在所有Sitara设备(仅Arm、Arm+专用硬件加速器)上启用机器学习推理,将机器学习推向了最前沿。它是作为TI的处理器SDK Linux的一部分提供的,可以免费下载和使用。今天的Sitara机器学习包括TI深度学习(TIDL)、Neo AI DLR、TVM运行时、TensorFlow Lite、Arm NN和RNN库。
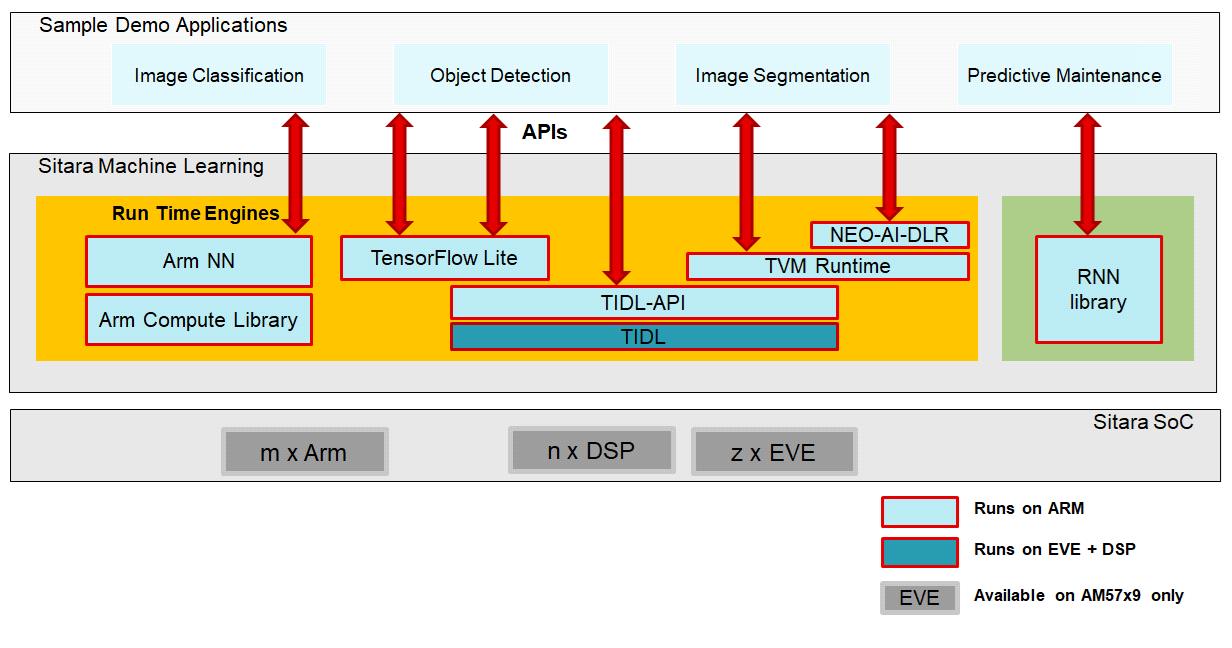
图1 Sitara机器学习
深度学习(TIDL)
•加速C66x DSP内核和/或嵌入式视觉引擎(EVE)子系统上的深度学习推理。
•仅在AM57x设备上可用。
•目前支持CNN,并导入Caffe、ONNX和Tensorflow模型。
Neo AI深度学习运行时(DLR)
•Neo-AI-DLR是一个新的开放源码机器学习运行库,用于设备上的推理。
•支持Keras, Tensorflow, TFLite, GluonCV, MXNet, Pytorch, ONNX,和XGBoost模型自动优化的Amazon SageMaker Neo或TVM编译器。
•支持所有Cortex-A ARM内核(AM3x、AM4x、AM5x、AM6x Sitara设备)。
•在AM5729和AM5749设备上,使用TIDL自动加速支持的模型。
运行时TVM
•开源深度学习运行时,用于设备上的推理,支持TVM编译器编译的模型。
•可用于所有Cortex-A ARM核心(AM3x、AM4x、AM5x、AM6x Sitara设备)。
TensorFlow Lite
•用于设备上推理的开源深度学习运行库。
•在所有Cortex-A ARM内核(AM3x、AM4x、AM5x、AM6x Sitara设备)上运行。
•导入Tensorflow Lite模型。
•使用TIDL导入工具创建TIDL可卸载Tensorflow Lite模型,该模型可通过Tensorflow Lite运行时在AM5729和AM5749设备上使用TIDL加速执行。
Arm NN
Arm提供的开源推理引擎。
•在所有Cortex-A ARM内核(AM3x、AM4x、AM5x、AM6x Sitara设备)上运行。
•导入Caffe, ONNX, TensorFlow和TensorFlow Lite模型。
RNN Library
•在一个独立的库中提供长-短期记忆(LSTM)和完全连接的层,以便快速原型化需要递归神经网络的推理应用程序。
•在所有Cortex-A ARM内核(AM3x, AM4x, AM5x, AM6x Sitara设备)上运行。
•在预测性维护的OOB演示中集成到TI的Processor SDK Linux。
介绍
TI Deep Learning(TIDL)API通过使应用程序能够利用TI专有的、高度优化的CNN/DNN实现,并在EVE和C66x DSP计算引擎上实现,从而为边缘带来了深入的学习。TIDL最初将瞄准AM57x Sitara™处理器上的Vision/2D用例。
TIDL API利用TI的OpenCL? 产品将深度学习应用程序卸载到EVE和DSP。TIDL API显著改善了用户的开箱即用深度学习体验,使他们能够专注于他们的整体用例。他们不需要花时间在Arm??DSP/EVE通信的机制上,或在EVE和/或DSP上实现优化的网络层。该API允许客户轻松集成OpenCV等框架和快速原型深度学习应用。
注意
本用户指南主要关注TIDL API。有关TIDL的信息,如整体开发流程、CNN/DNN在TI处理器上优化性能的技术、性能/基准数据和支持层列表,请参见处理器SDK Linux软件开发人员指南(TIDL章节)中的TIDL部分。
关键特性
易用性
• 轻松地将TIDL API集成到其他框架中,例如OpenCV
• 为用户应用程序提供简单的主机抽象,以便跨多个计算核心(EVE和C66x DSP)运行网络。指?为用户应用程序提供简单的主机抽象,以跨多个计算核心(EVEs和C66x dsp)运行网络。参考每个EO处理单个帧和跨EOs的帧分割的详细信息.
低开销
主机上的TIDLAPI的执行时间相当于每帧执行时间的一小部分。例如,对于jseg21网络,1024x125帧,有3个通道,API占每帧处理时间的约1.5%。
开发流程
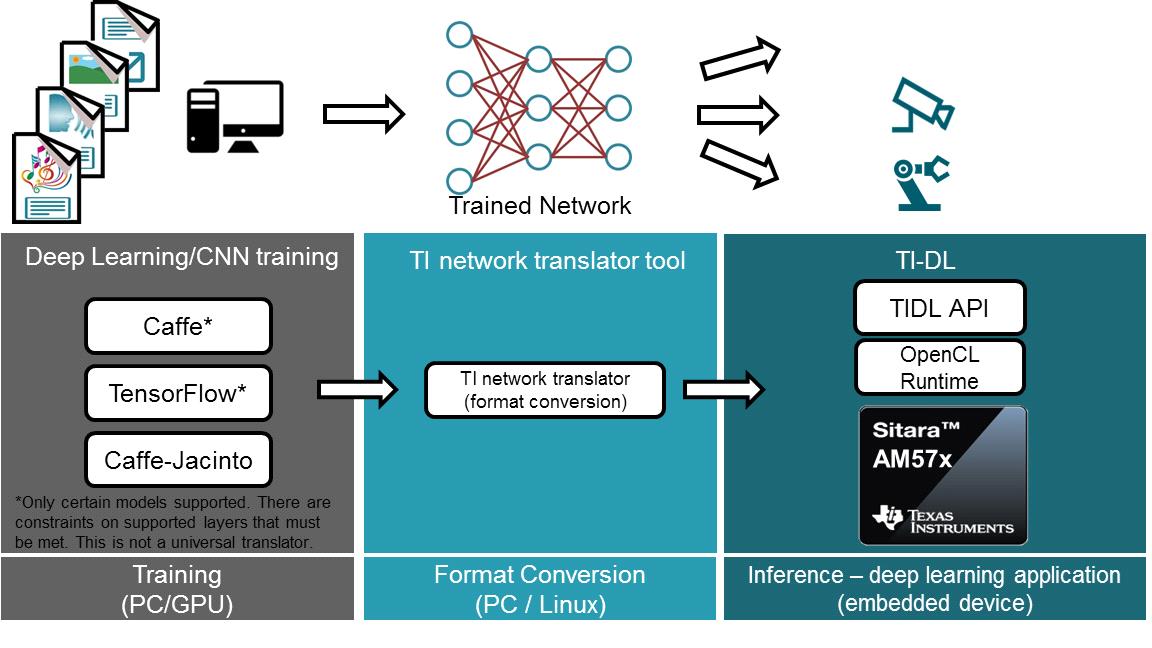
图1显示了整个开发过程。
深度学习分为两个阶段:发展阶段的训练和部署阶段的推理。训练包括设计神经网络模型,通过网络运行训练数据来调整模型参数。推理采用包含参数的预训练模型,应用于新的输入并产生输出。训练是计算密集型的,使用Caffe/TensorFlow等框架完成。网络训练完成后,可以使用TIDL转换工具将网络和参数转换为TIDL。处理器SDK Linux软件开发指南(TIDL章节)提供了关于开发流程和转换器工具的详细信息。
所包含的示例演示了三类深度学习网络:分类、分割和目标检测。imagenet和segmentation可以在EVE或C66x内核的AM57x处理器上运行。ssd_multibox需要具有EVE和C66x的AM57x处理器。示例可以在EVM文件系统和linux devkit中的/usr/share/ti/tidl/example中找到。
使用以下方法获得性能数据:
• am574x IDK EVM, Sitara AM5749处理器- 2 Arm Cortex-A15内核运行在1.0GHz, 2 EVE内核运行在650MHz, 2 C66x内核运行在750MHz.
• 处理器SDK Linux v5.1与TIDL API v1.1
对于每个示例,报告设备处理时间、主机处理时间和TIDL API开销.
• 设备处理时间在设备上测量,从帧处理开始到处理完成.
• 主机处理时间是在主机上测量的,从调用ProcessFrameStartAsync()到ProcessFrameWait()在用户应用程序中返回。它包括tidlapi开销、OpenCL运行时开销以及将用户输入数据复制到填充TIDL内部缓冲区的时间.
Imagenet
imagenet示例将图像作为输入并输出1000个概率。每个概率对应于网络预先训练的1000个对象中的一个对象。对于给定的输入图像,该示例输出概率为5%或更高的前5个(最多)预测。
下图和表显示了输入图像、作为输出的前5个预测对象以及EVE或C66x上的处理时间.
Rank Object Classes Probability
1 tabby 52.55%
2 Egyptian_cat 21.18%
3 tiger_cat 17.65%
Device Device Processing Time Host Processing Time API Overhead
EVE 106.5 ms 107.9 ms 1.37 %
C66x 117.9 ms 118.7 ms 0.93 %
本例中使用的网络为jacintonet11v2。它有14层。网络输入为224x224的RGB图像。用户可以指定是在EVE还是C66x上运行网络。
示例代码将buffer_factor设置为2,以使用相同的ExecutionObjects创建重复的executionobjectpipeline,以执行双重缓冲,这样主机预处理/后处理就可以与设备处理重叠(详情请参阅代码中的注释)。下表显示了使用单缓冲和双缓冲超过10帧的循环总时间。./imagenet -f 10 -d -e .
Table 3 Loop overall time over 10 frames¶
Device(s) Single Buffering (buffer_factor=1) Double Buffering (buffer_factor=2)
1 EVE 1744 ms 1167 ms
2 EVEs 966 ms 795 ms
1 C66x 1879 ms 1281 ms
2 C66xs 1021 ms 814 ms
分割
分割实例以图像为输入,根据预先训练好的类别进行像素级分类。下图显示了作为输入的街道场景,以及以像素级分类叠加的场景作为输出:绿色的道路,红色的行人,蓝色的车辆,灰色的背景。
本例中使用的网络为jsegnet21 v2。它有26层。用户可以指定是在EVE还是C66x上运行网络。网络输入为RGB图像,大小为1024x512。输出1024x512个值,每个值表示当前像素属于哪个预训练类别。这个例子将使用网络输出,创建一个覆盖层,并将覆盖层混合到原始输入图像上,以创建输出图像。从下表中报告的时间,我们可以看到这个网络在EVE上比在C66x上运行得快得多。
Device Device Processing Time Host Processing Time API Overhead
EVE 251.8 ms 254.2 ms 0.96 %
C66x 812.7 ms 815.0 ms 0.27 %
示例代码将buffer_factor设置为2,以使用相同的ExecutionObjects创建重复的executionobjectpipeline,以执行双重缓冲,这样主机预处理/后处理就可以与设备处理重叠(详情请参阅代码中的注释)。下表显示了使用单缓冲和双缓冲超过10帧的循环总时间。./segmentation -f 10 -d -e .
Table 4 Loop overall time over 10 frames¶
Device(s) Single Buffering (buffer_factor=1) Double Buffering (buffer_factor=2)
1 EVE 5233 ms 3017 ms
2 EVEs 3032 ms 3015 ms
1 C66x 10890 ms 8416 ms
2 C66xs 5742 ms 4638 ms
SSD
SSD是单发多盒探测器的缩写。ssd_multibox示例以一幅图像作为输入,并根据预先训练的类别检测带有边界框的多个对象。示例支持ssd网络的两组预训练类别:jdetnet_voc和jdetnet。
下图显示了一个作为输入的图像,以及jdetnet_voc中被识别对象框起来作为输出的图像:红色的person和绿色的horse。
下图显示了另一个作为输入的街道场景,以及由jdetnet将识别对象框起来作为输出的场景:红色的行人、蓝色的车辆和黄色的路标。
请使用命令行选项在这两套预先训练的类别之间切换,例如.
./ssd_multibox # default is jdetnet_voc
./ssd_multibox -c jdetnet -l jdetnet_objects.json -p 16 -i ../test/testvecs/input/preproc_0_768x320.y
两种类型中使用的ssd网络都有43层。网络输入为768x320的RGB图像。输出是一个方框列表(最多20个),每个方框都有关于方框坐标的信息,以及方框内的对象属于哪个预先训练的类别。该示例将获取网络输出,相应地绘制框,并创建输出图像。该网络可以完全在EVE或C66x上运行。然而,最好的性能是在EVE上以组形式运行前30层,在C66x上以组形式运行后的13层。我们的端到端示例显示,将层组id分配给执行器是多么容易,以及构造ExecutionObjectPipeline将一个执行器的ExecutionObject的输出连接到另一个Executor的ExecutionObject的输入是多么容易。
Device Device Processing Time Host Processing Time API Overhead
EVE+C66x 169.5ms 172.0ms 1.68 %
示例代码将pipeline_depth设置为2,以使用相同的ExecutionObjects创建重复的executionobjectpipeline,从而在ExecutionObject级别执行流水线执行。它的副作用是,主机预处理/后处理与设备处理重叠(详情请参阅代码中的注释)。下表显示了在ExecutionObjectPipeline级别和ExecutionObject级别使用pipelining超过10帧的循环总时间。./ssd_multibox -f 10 -d -e .
Table 5 Loop overall time over 10 frames¶
Device(s) pipeline_depth=1 pipeline_depth=2
1 EVE + 1 C66x 2900 ms 1735 ms
2 EVEs + 2 C66xs 1630 ms 1408 ms
当需要非分区运行SSD网络时,例如SoC只有C66x核,没有EVE核,则使用-e 0仅在C66x核上运行完整网络,而不进行分区。
MNIST
MNIST示例从一个文件中选取一个经过预处理的28x28黑白帧作为输入,并预测帧中的手写数字。例如,这个例子将为接下来的帧预测0。
root@am57xx-evm:~/tidl/examples/mnist# hexdump -v -e '28/1 "%2x" "\\n"' -n 784 ../test/testvecs/input/digits10_images_28x28.y
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 314 8 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0319bdfeec1671b 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 01ed5ffd2a4e4ec89 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1bcffee2a 031e6e225 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 05ff7ffbf 2 0 078ffa1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0b2f2f34e 0 0 015e0d8 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0148deab2 0 0 0 0 0bdec 2 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 084f845 0 0 0 0 0a4f222 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0c4d3 5 0 0 0 0 096f21c 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 052f695 0 0 0 0 0 0a7ed 8 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 09af329 0 0 0 0 0 0d1cf 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 2d4c8 0 0 0 0 0 01ae9a2 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 038fa9a 0 0 0 0 0 062ff76 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 07afe5d 0 0 0 0 0 0a9e215 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0bdec1d 0 0 0 0 017e7aa 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1e7d6 0 0 0 0 0 096f85a 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 01df2bf 0 0 0 0 015e1ca 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 061fc95 0 0 0 0 084f767 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 06eff8b 0 0 0 033e8ca 4 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 060fc9e 0 0 0 092d63e 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 01bf1da 6 0 019b656 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0c3fb8e a613e7b 5 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 049f1fcf5f696 9 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 04ca0b872 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
该文件可以包含多个帧。如果还给出了一个可选的标签文件,示例将比较预测的结果与预先确定的标签的准确性。输入文件可能有MNIST数据集文件头,也可能没有。如果使用头文件,输入文件名必须以idx3-ubyte或idx1-ubyte结尾。
MNIST的例子还说明了TIDL API对于低计算要求(<5ms)的小型网络的低开销。网络在EVE上运行大约3ms,只需一帧。如下表所示,当运行超过1000帧时,开销约为1.8%。
Table 6 Loop overall time over 1000 frames¶
Device(s) Device Processing Time Host Processing Time API Overhead
1 EVE 3091 ms 3146 ms 1.78%
运行示例
示例位于EVM文件系统的/usr/share/ti/tidl/examples目录中。由于配置文件的相对路径,每个示例都需要在其自己的目录中运行。使用-h运行一个示例将显示带有选项集的帮助消息。下面的清单说明了如何构建和运行这些示例。
root@am57xx-evm:~/tidl/examples/imagenet# ./imagenet
Input: ../test/testvecs/input/objects/cat-pet-animal-domestic-104827.jpeg
1: tabby, prob = 52.55%
2: Egyptian_cat, prob = 21.18%
3: tiger_cat, prob = 17.65%
Loop total time (including read/write/opencv/print/etc): 183.3ms
imagenet PASSED
root@am57xx-evm:~/tidl-api/examples/segmentation# ./segmentation
Input: ../test/testvecs/input/000100_1024x512_bgr.y
frame[ 0]: Time on EVE0: 251.74 ms, host: 258.02 ms API overhead: 2.43 %
Saving frame 0 to: frame_0.png
Saving frame 0 overlayed with segmentation to: overlay_0.png
frame[ 1]: Time on EVE0: 251.76 ms, host: 255.79 ms API overhead: 1.58 %
Saving frame 1 to: frame_1.png
Saving frame 1 overlayed with segmentation to: overlay_1.png
...
frame[ 8]: Time on EVE0: 251.75 ms, host: 254.21 ms API overhead: 0.97 %
Saving frame 8 to: frame_8.png
Saving frame 8 overlayed with segmentation to: overlay_8.png
Loop total time (including read/write/opencv/print/etc): 4809ms
segmentation PASSED
root@am57xx-evm:~/tidl-api/examples/ssd_multibox# ./ssd_multibox
Input: ../test/testvecs/input/preproc_0_768x320.y
frame[ 0]: Time on EVE0+DSP0: 169.44 ms, host: 173.56 ms API overhead: 2.37 %
Saving frame 0 to: frame_0.png
Saving frame 0 with SSD multiboxes to: multibox_0.png
Loop total time (including read/write/opencv/print/etc): 320.2ms
ssd_multibox PASSED
root@am57xx-evm:~/tidl/examples/mnist# ./mnist
Input images: ../test/testvecs/input/digits10_images_28x28.y
Input labels: ../test/testvecs/input/digits10_labels_10x1.y
Device total time: 31.02ms
Loop total time (including read/write/print/etc): 32.49ms
Accuracy: 100%
mnist PASSED
图像输入
图像输入选项-i,将图像文件作为输入。您可以提供一个OpenCV可以读取的格式的图像文件,因为我们使用OpenCV进行图像预处理/后处理。当使用-f选项时,将重复处理相同的图像。
摄像机(实时视频)输入
输入选项-i camer,启用来自相机的实时帧输入。是Linux中相机的视频输入端口号。使用以下命令检查视频输入端口。AM57x EVMs上使用的TMDSCM572X摄像头模块的默认值为1。可以使用-f指定要处理的帧数。
root@am57xx-evm:~# v4l2-ctl --list-devices
omapwb-cap (platform:omapwb-cap):
/dev/video11
omapwb-m2m (platform:omapwb-m2m):
/dev/video10
vip (platform:vip):
/dev/video1
vpe (platform:vpe):
/dev/video0
预先录制的视频(mp4/mov/avi)输入
输入选项-imp4,mov,avi启用来自mp4,mov或avi格式的预录视频文件的帧输入。如果您有一个不同OpenCV支持格式/后缀的视频,您可以简单地创建一个带有mp4、mov或avi后缀之一的软链接,并将其输入到示例中。再次使用-f指定要处理的帧数。
显示视频输出
当使用视频输入(实时或预录制)时,该示例将使用OpenCV在窗口中显示输出。如果您有一个连接到EVM的LCD屏幕,那么您需要首先关闭matrix gui以查看示例显示窗口,如下面的示例所示。
root@am57xx-evm:/usr/share/ti/tidl/examples/ssd_multibox# /etc/init.d/matrix-gui-2.0 stop
Stopping Matrix GUI application.
root@am57xx-evm:/usr/share/ti/tidl/examples/ssd_multibox# ./ssd_multibox -i camera -f 100
Input: camera
init done
Using Wayland-EGL
wlpvr: PVR Services Initialised
Using the 'xdg-shell-v5' shell integration
... ...
root@am57xx-evm:/usr/share/ti/tidl/examples/ssd_multibox# /etc/init.d/matrix-gui-2.0 start
/usr/share/ti/tidl/examples/ssd_multibox
Removing stale PID file /var/run/matrix-gui-2.0.pid.
Starting Matrix GUI application.
Viewers
网络图查看器
TIDL网络查看器实用程序tidl_viewer可用于查看网络图。如果dot实用程序可用,tidl_viewer将使用它将点文件转换为svg. dot包含在Graphviz Ubuntu包中,通常安装到/usr/bin/dot.
例如,下面的命令将为ssd.dot中的 tidl_net_jdetNet_ssd.bin网络二进制文件生成一个点图描述。
$ tidl_viewer examples/test/testvecs/config/tidl_models/tidl_net_jdetNet_ssd.bin -d ssd.dot
在x86/Linux上,如果/usr/bin/dot可用,tidl_viewer也会生成一个svg文件,ssd.dot.svg。
执行图查看器
TIDL API v1.2允许为ExecutionObjectPipeline和ExecutionObject类中的以下方法生成带有时间戳的日志文件:
⦁ProcessFrameStartAsync(开始)
⦁ProcessFrameStartAsync(结束)
⦁ProcessFrameWait(开始)
⦁ProcessFrameWait(结束)
向TIDL API应用程序添加以下调用,以启用时间戳生成:
bool EnableTimeStamps(const std::string& file, size_t num_frames);
通过使用位于viewer/execution_graph.py.
-> /viewer/execution_graph.py timestamp.log执行_graph.py 脚本,可以在x86/Linux上查看生成的日志文件。
图7显示了one_eo_per_frame示例的execution_graph.py的输出,当运行在带有2个EVE和2个C66x dsp的AM5749上时:
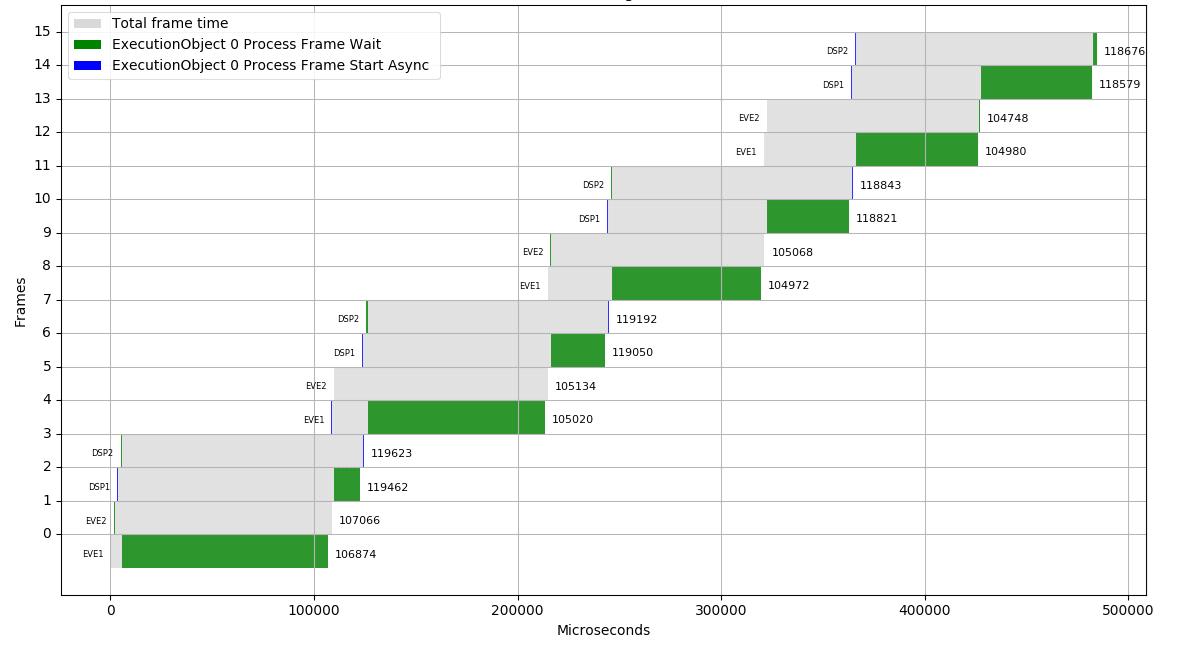
图7帧索引图与执行生成的执行时间的关系图(点击放大)
AM57x Sitara 处理器运行深度学习推理。该推理是部署在最终应用中以执行特定任务(即检查装配线上的瓶子、对房间内的人进行计数和跟踪或确定纸币是否是伪造的)的部分。神经网络仍然必须在桌面或云环境中进行训练,然后必须使用 TI 的器件转换工具将经过训练的网络导入到 AM57x Sitara 处理器中。
有关 TIDL 开发流程和 TIDL 组件,请参阅下图。
TIDL 开发流程
TIDL 开发流程包含三个主要部分。
- 训练 - 教授网络模型执行特定的任务。通常在桌面或云中离线进行,需要将大型标记过的数据集馈送到 DNN 中。这是深度学习的“学习”部分。训练阶段的结果是经过训练的网络模型。
- 导入(格式转换)- 包括使用 TIDL 器件转换工具将经过训练的网络模型转换为最适合在 AM57x 处理器上运行的 TIDL 库内部使用的内部格式。命令行参数指定推理将在 C66x DSP 内核、EVE 子系统还是两者上运行。
- 部署(推断)- 使用 TIDL API 在 AM57x 处理器上运行经转换的网络模型。
以上是关于机器学习介绍的主要内容,如果未能解决你的问题,请参考以下文章