Python深度学习之路-1 机器学习概论
Posted Vax_Loves_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python深度学习之路-1 机器学习概论相关的知识,希望对你有一定的参考价值。
【Python深度学习之路】-1 机器学习概论
1.1 机器学习简介
机器学习火热的原因是:人类无论如何也做不到在短时间内实现从大量数据中自动地计算出正确结果的操作。
所谓机器学习:通过对数据进行反复的学习,来找出其中潜藏的规律和模式。
机器学习中所使用到的算法可以归结为三大类:
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 强化学习(Reinforcement Learning)
1.2各类机器学习算法
1.2.1 监督学习
- 监督学习中的“监督”,是指“数据中附带的正确答案标签”。
- 监督学习问题主要分为两大类:
- 回归问题:对连续变化的数值进行预测。例如:房租预测、销售额预测、气温预测、股价预测。
- 分类问题:对数据所属类别进行预测。例如:0-9手写数字识别、识别照片中所拍摄的物体、推测文章作者。
- 监督学习的基本原理:使用大量的数据,通过计算机对数据进行反复处理,最终能够产生接近正确答案标签的输出值。
- 监督学习的实现流程:
- 将各种各样的监督数据交给计算机,并让其对“正确答案标签”进行学习,最终创建出能够输出“正确答案标签”的学习模型。
- 使用创建好的模型对未知的数据进行处理,并检测模型是否能够产生接近“正确答案标签”的输出值。
1.2.2 无监督学习
- 与“监督学习”的区别:监督学习中包含“正确答案标签”问题的答案,而在“无监督学习”中是不包含“正确答案标签”的,其属于从输入的数据中发现规则,并进行学习的一种方法。监督学习会告诉计算机正确的答案,而无监督学习则是使用计算机去推导答案。
- 通常,无监督学习是在对数据集合中所存在的某些规律或数据的分组进行推导时所采用的一种方法。
- 无监督学习常见问题举例:热卖商品的推荐、菜单推荐以及多维信息压缩(主成分分析及降维处理)。
1.2.3 强化学习
- 在“强化学习”中也不需要监督,强化学习会提供“智能体”和“环境”。配备“智能体”和“环境”后,智能体会根据环境的变化采取相应的行动,环境将根据行动的结果给予智能体相应的“报酬”,而智能体根据其获得的报酬,对行动做出“好”或“不好”的评价,并以此决定下次该如何行动。
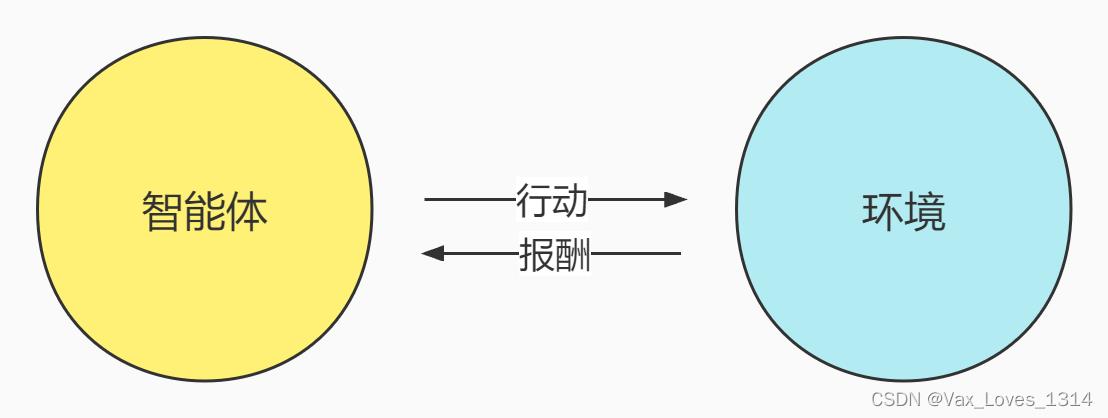
- 强化学习常见场景问题:象棋AI、围棋AI、机器人的操作和控制。
总结:
“监督学习”作为机器学习领域中的代表,其特点是处理名为“监督数据”的问题,以及该问题所附带的答案的数据。它是通过使用机器学习算法从学习数据中找出答案,再使用附带的标签数据来对比答案,不断地与正确答案进行对比,直到得出正确答案为止。而“强化学习”则属于最近几年才开始受到关注的技术,在棋盘类游戏对战中的应用是其强项。强化学习在围棋对战中的应用无疑是其最广为人知的案例。
以上是关于Python深度学习之路-1 机器学习概论的主要内容,如果未能解决你的问题,请参考以下文章