新一代开源数据可视化平台 datart——技术架构与应用场景
Posted running_elephant
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新一代开源数据可视化平台 datart——技术架构与应用场景相关的知识,希望对你有一定的参考价值。
随着实时报表、BI、实时大屏、仪表板、甚至数字孪生等交互式数据可视化类产品应用越来越广,数据可视化领域备受关注,以下阐述:
1、数据可视化概念
2、企业为什么需要数据可视化
3、企业如何进行数据可视化建设?
4、开源的数据可视化平台 datart
首先,进入第一个问题
什么是数据可视化?
数据可视化,百度百科将其定义为数据的视觉表现形式,是一种以概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
但这个定义让人觉得云山雾罩,不明所以。所以,我们换个方式表达,例如你给领导提交一份文档,在展现形式上,一般是PPT>EXCEL>WORD,所谓“文不如表,表不如图”。由此可见,赏心悦目的图表更高效,更直观。
数据可视化借助图形化手段,通过可视化插件库,各式各样的图表种类和主题可供选择,可以清晰有效地传达和沟通信息,通过直观、美观的图表、大屏来传达关键数据信息和展现数据特征,从而帮助用户实现对零散且又繁杂的数据集进行深入洞察。
企业为什么需要数据可视化?
数字可视化应用工具帮助企业改变纯文字、纯数字的项目汇报方式,利用图形化报表,凸显数据对比关系,一方面帮助企业决策者更高效抓取到关键数据信息和重要细节;另一方面让企业技术人员和其他中层管理人员掌握新方法,提高数据信息的整合能力。
具体优势如下:
(1)拉动产品营销转化
企业管理层借助数据可视化工具,查看最新销售数据,掌握畅销产品和滞销产品的数据表现,另外可针对折扣力度、款式等等因素进行分析,得出各项经营决策对产品销售额的影响力度,从而有效调整并制定出新的计划。
数据可视化管理工具还可以针对性地对下一轮销售数据进行高级预测分析,让企业管理人员早发现、分析和预判问题,更高效地采取相应措施,促进营销转化。
(2)增强业务运营能力
数据可视化工具为业务和运营动态提供多角度视图,让企业管理者可以有效识别并理解操作执行和业务发展之间的关系属性;允许管理团队更好地了解客户对产品的深层需求是否能够普遍实现,这样的见解使企业能够把握新商机,领先于竞争对手。
(3)洞察经营发展趋势
数据可视化让企业领导者360度洞察营收对比和商业机会–从海量的数据中发现机会。决策者能够更快地掌握的商品销量及利润,有效调整业务结构,从而有效驱动公司收益最大化。
(4)打破数据连接壁垒
传统数据表格、ppt和报表,只能以静态表格和图表来为管理层提供信息,而数据可视化使用户能够接收有关运营和业务条件的大量动态信息。数据可视化允许决策者查看多维数据集之间的连接,并通过使用柱状图、条形图、饼状图、百分比图、指标卡、数据变化,单行文本和其他丰富的图形更好的诠释商业数据。
柱状竞赛图-年
可视化动态视频效果演示
企业如何进行数据可视化建设?
关于企业要如何进行数据可视化建设,下面给大家分享采用开源数据可视化工具 datart 的典型案例:
案例企业:国内大型药企
所属行业:医药行业
该药企自2015年起开启了数据化建设10年规划,到2025年彻底实现数据应用连接企业各个系统端口,以数据技术驱动企业发展运作,这也为后续采用跑象科技 datart 开源数据可视化应用提供了契机。
(1)企业数据管理存在哪些问题?
在此之前,该企业因发展较快,经久累计的发展数据,在数量空间和维度层次方面变得日益繁杂,而且企业内部各个系统相互独立,数据孤岛化现象越发凸显。
另外,底层数据管理工具很局限,一线员工的工作质量较为低下,无法做到快速抓取、甄别有效信息,从而使得企业中高层做管理决策时缺乏有效数据的支撑和驱动。具体如下:
-
日常办公一部分采用excel/ppt管理数据,另一部分采用传统报表,数据统计延迟、不精确、且相互间割裂严重,不能适应业务
-
设计人员依赖基本的AI/PS操作,数据图表种类单一,不抓人,美观和直观程度不足
-
以纯文字、纯数字、多表格的方式汇报经营管理和项目进展的数据,无法做到突出展示和对比分析,决策者无法高效掌握重要信息,影响决策制定
-
部分业务端口采用ERP 系统,但业务处理界面不完善,使用成本高
-
数据处理方式不灵活,系统应用不支持移动办公,管理方式无法做到协同
(2)数据可视化建设方案
跑象科技的 datart 团队由 DBus、Wormhole、Moonbox、Davinci 等四大开源项目研发的主创人员组成,在基础平台研发、数据中台建设和数据应用等方面均有超过10年以上的经验。
打造出完整的企业级敏捷实时数据应用架构,成功服务数千家企业用户,并和很多行业龙头企业达成了长期战略合作,datart 团队助力该药企从业务需求出发,建立专属落地方案,直到企业实现数字可视化业务的创新转型。
-
从该医药企业内外部数据管理环境入手;
-
帮助企业深入分析痛点问题;
-
可视化工具协助管理者分析出当前数据利用方面的难点和痛点;
-
根据直观的图表展现,找到促进营销需求转化的点;
-
根据可视化图表展示出的数据情况,对企业未来发展或将面临的市场问题进行预判;
-
全面结合企业经营现状,提供最合理的数据可视化建设方案
(3)卓有成效的敏捷方案
-
在引入 datart 数据可视化应用之后,企业快速构建起了专属的数据应用系统;
-
企业将 datart 整合、内嵌到企业本身的系统应用当中,完成企业级报表、仪表板、大屏、分析和可视化数据应用的敏捷构建;
-
并以此开发了基于协同办公平台的辅助决策可视化报表和大屏;
-
实时掌握财务、营销、生产、采购以及人力资源系统产生的各类信息,辅助各级管理者完成经营决策。
通过 datart 进行数据和报表的展现,满足该医药企业360度产能分析、营销数据分析、药品宣传、临床培训等数字可视化需求,达到业务经营管理资产留存及有效传递。此外,datart 帮助企业实现降本增效超过30%,并且实现长期化、及标准流程化管理。
实现数据可视化是医药行业数字化转型能否成功的关键所在。
开源的数据可视化平台 datart
datart 是基于 Apache V2 开源协议打造出的新一代开源数据可视化开放平台,支持各类企业数据可视化场景需求,如创建和使用报表、仪表板和大屏,进行可视化数据分析,构建可视化数据应用等。
由原 davinci 主创团队出品,datart 更加开放、可塑和智能,并在数据与艺术之间寻求最佳平衡。
需要用到数据可视化开源产品的,可以关注一下 datart 在github、gitee上的地址
另外,国产开源数据可视化社群请加V信(retech01)
Github:
https://github.com/running-elephant/datartgithub.com/running-elephant/datart
Gitee:
running-elephant/datartgitee.com/running-elephant/datart
先看在开源数据可视化 datart 上简单配置的习作-实时大屏
datart 实时大屏——决策驾驶舱
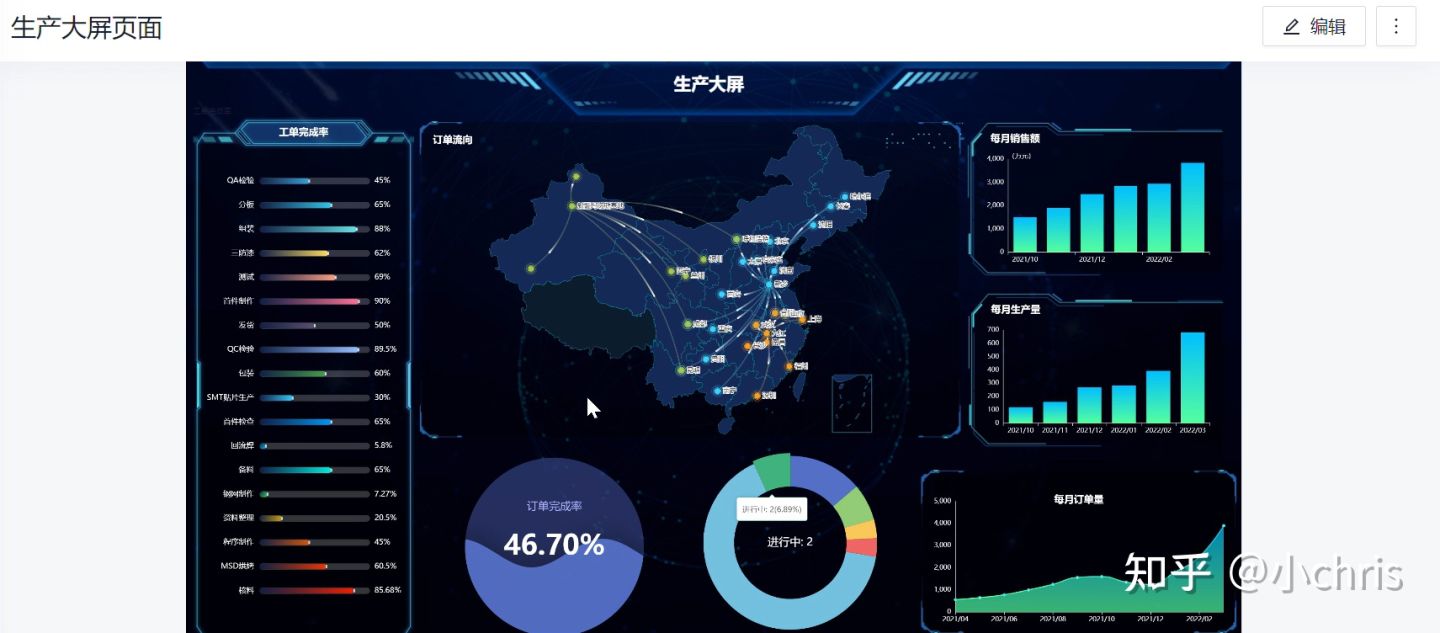
datart——生产大屏
上面是在国产开源的数据可视化 datart 上简单配置的两个实时大屏,截图展现不出来交互的效果,下面传一段视频:
Datart - 个人 - 生产大屏80 播放 · 0 赞同视频
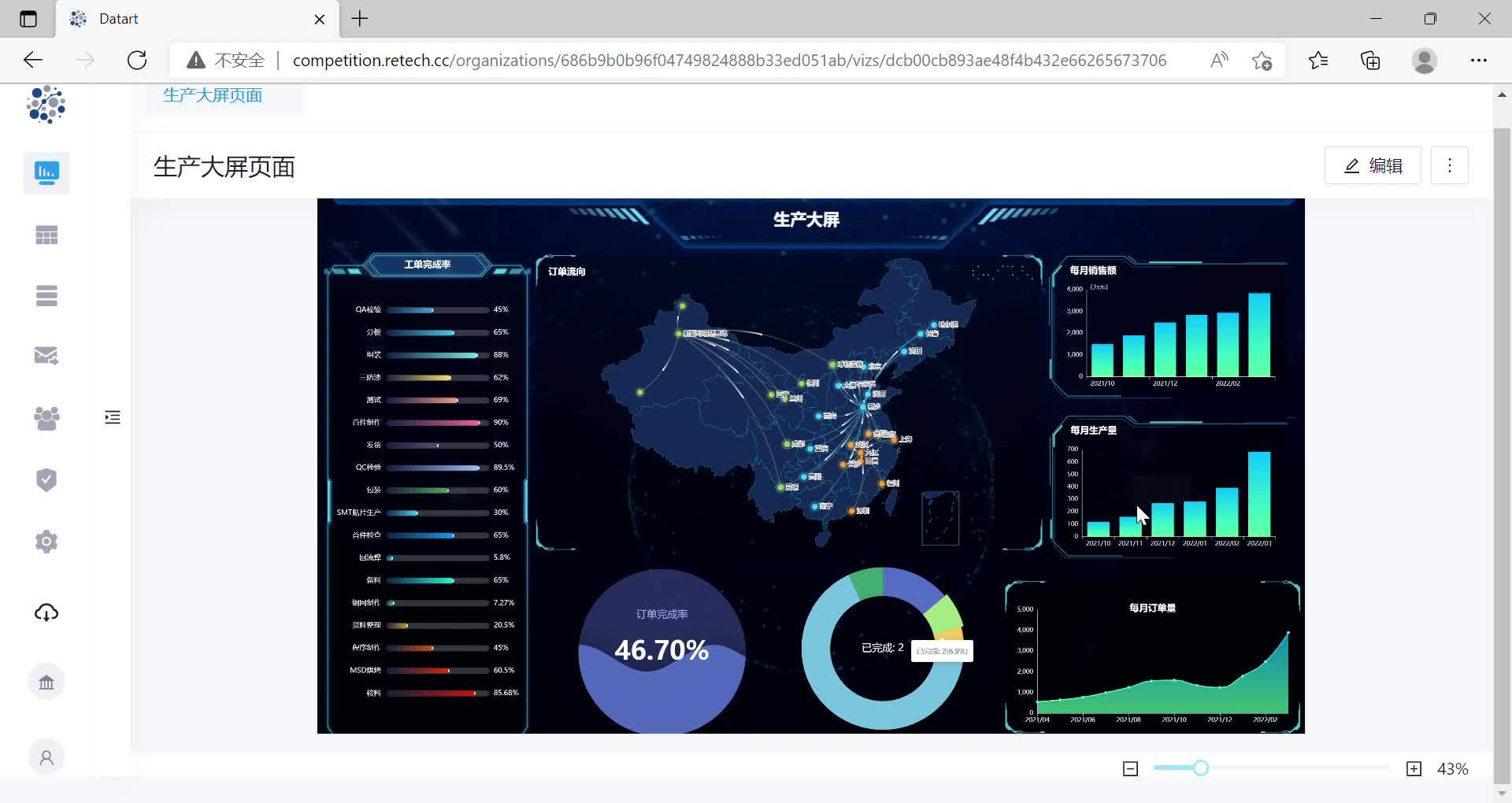
下面展示一些实时报表、实时看板
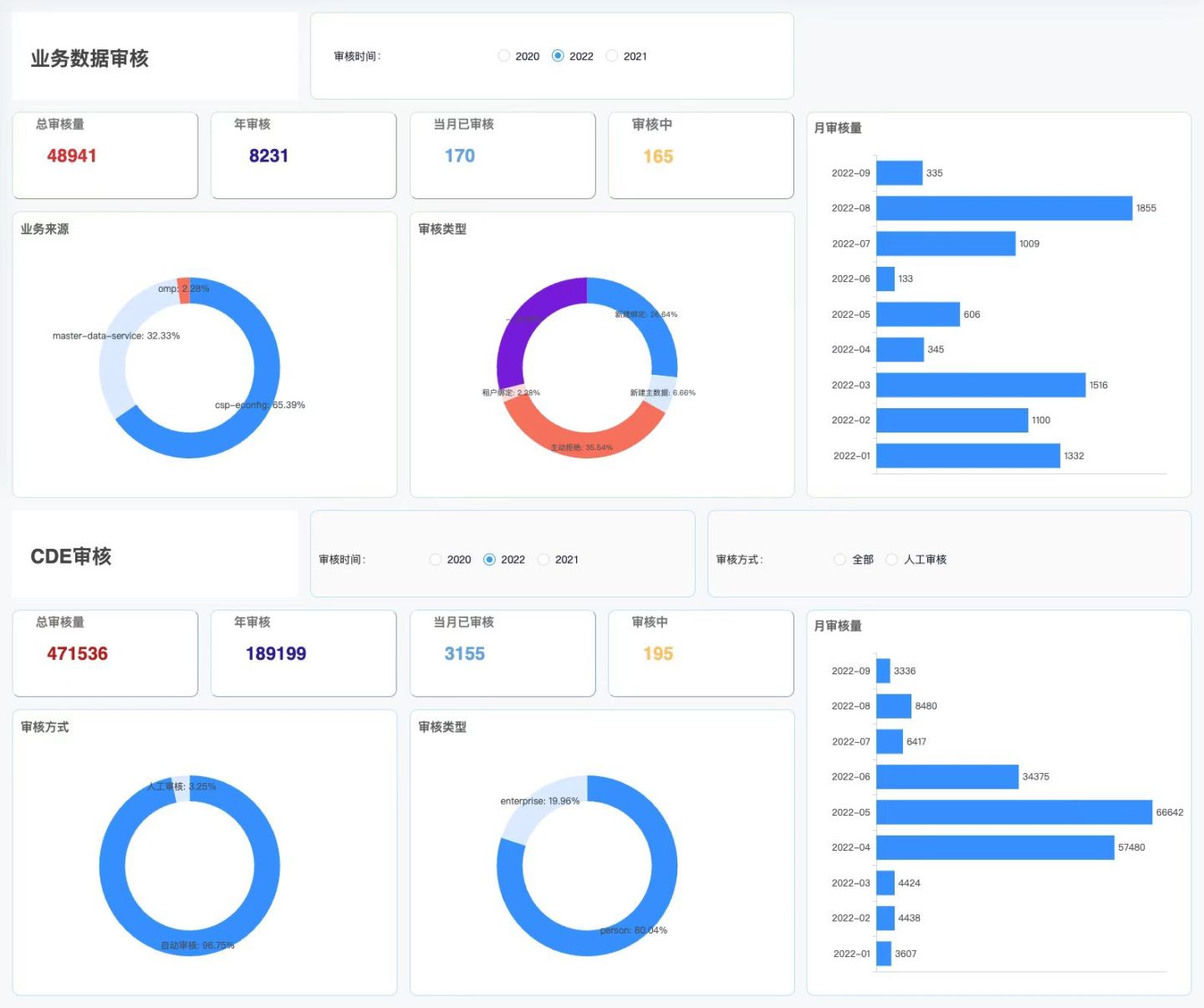
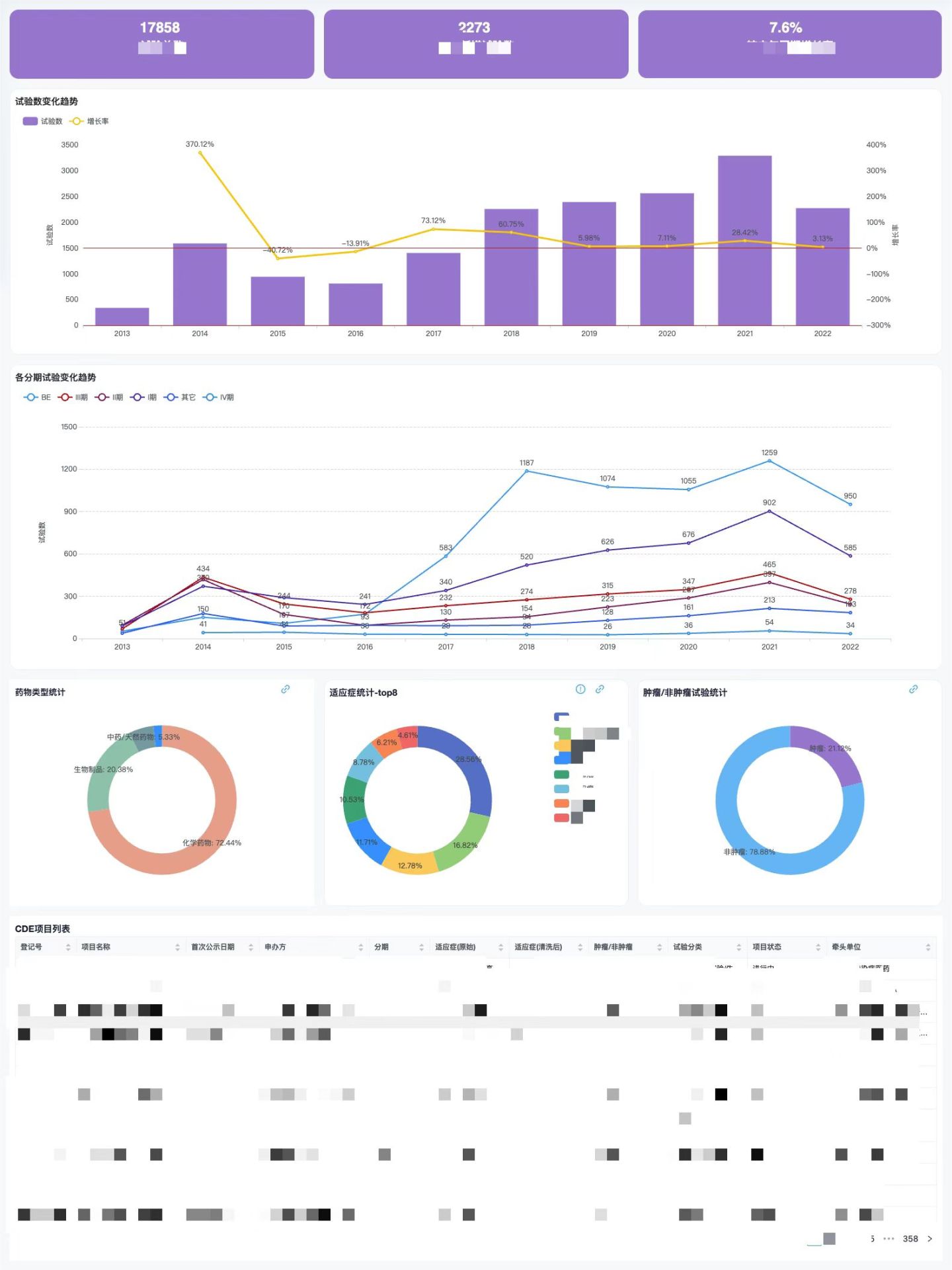
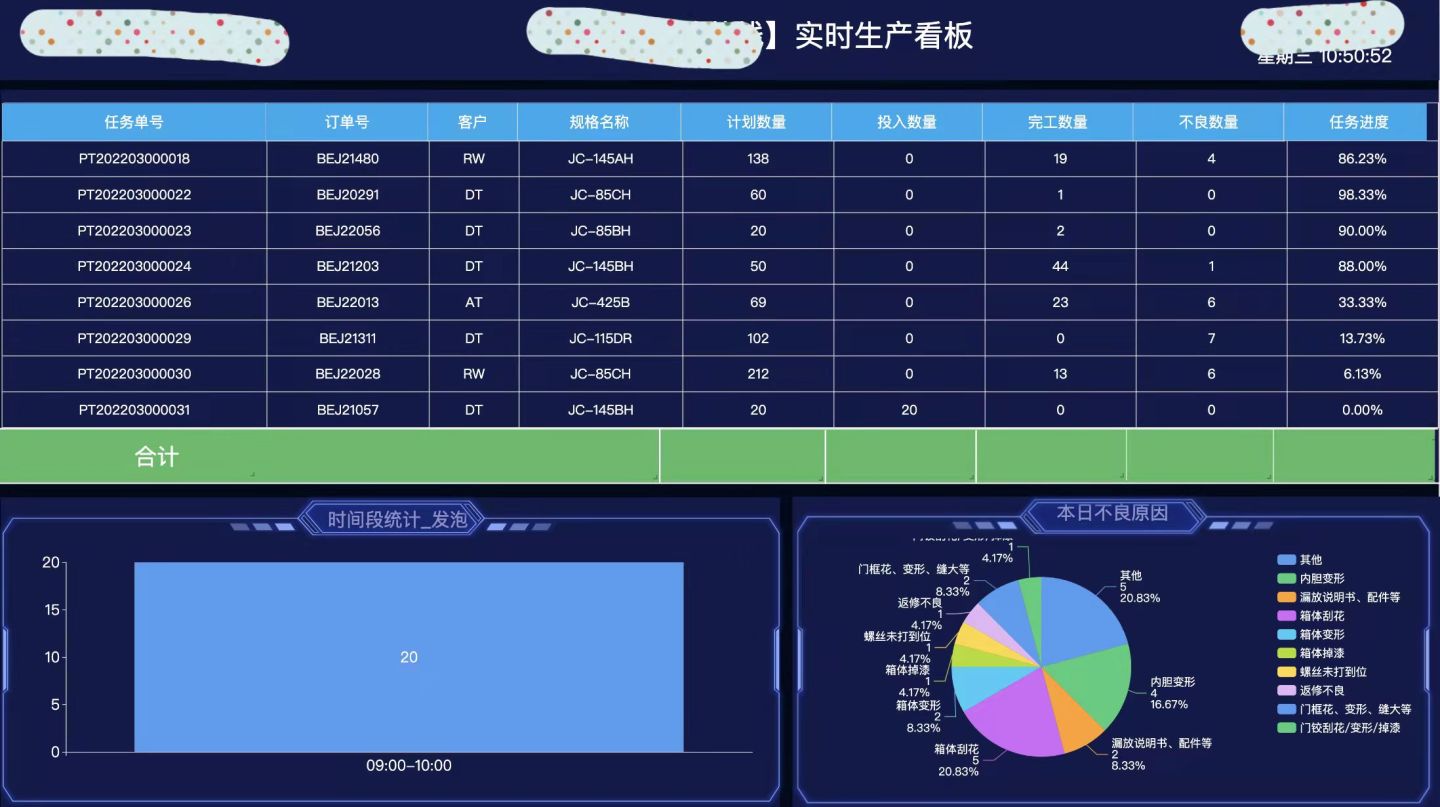
数据可视化 datart 使用场景
(1)直接对接数仓或生产备库
通过数据视图加工 >> 自助分析 >> 制作仪表板 >> 定时任务发送邮件 / 分享链接到决策人,以上步骤产出报表;是最典型的使用场景。
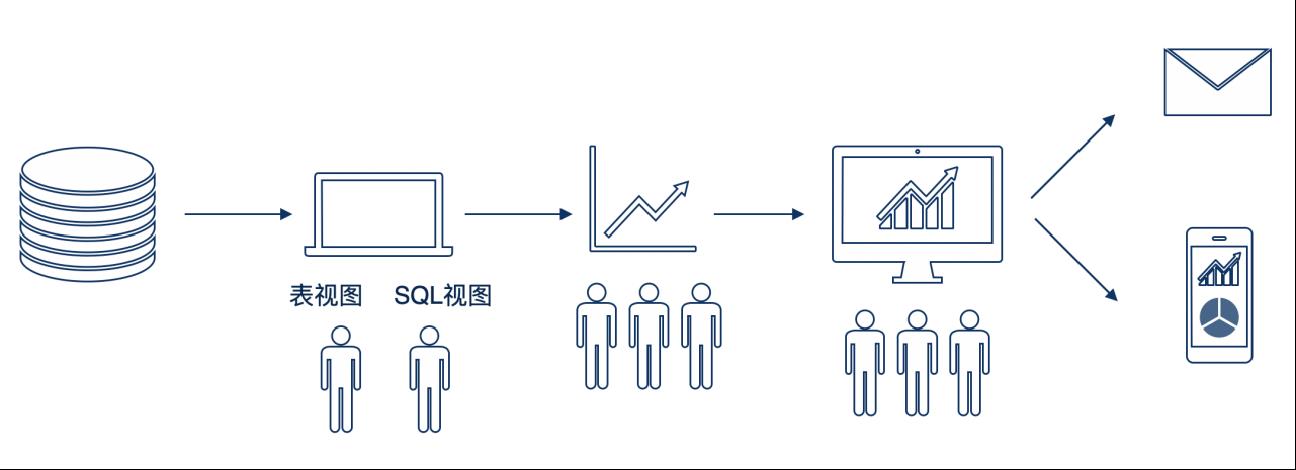
(2)对接指标平台
一些规模较大的企业拥有自己的指标平台,datart 支持直接从指标平台获取数据,在数据视图中仅做简单开发 / 不开发,分析时可以禁用数据聚合,避免对指标二次加工,最终制作仪表板、分享、递送,产出报表。
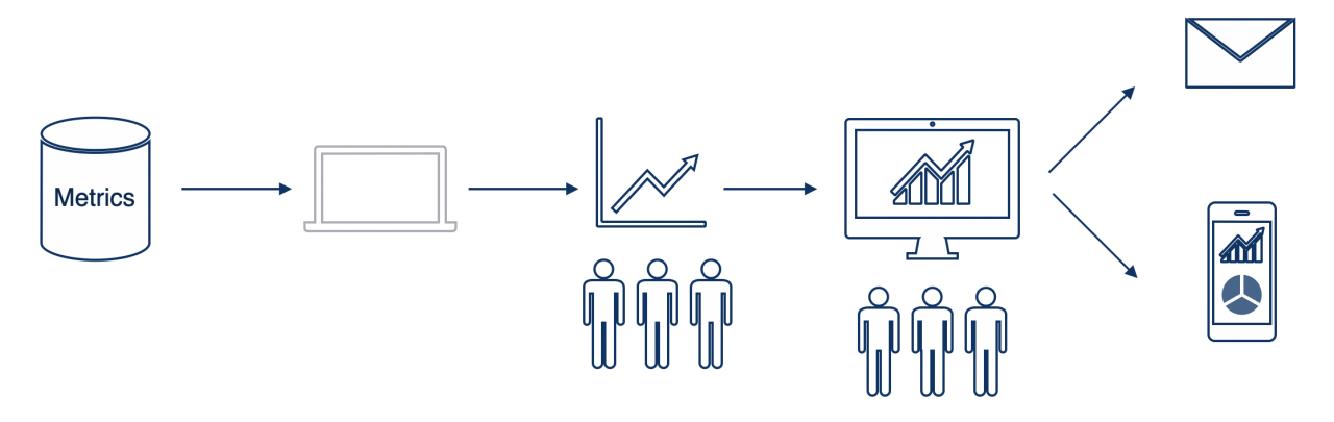
(3)对接 API
datart 支持通过 Http 数据源从 API 直接获取数据,数据存储在内置的 H2 内存数据库中,用于分析和呈现报表。
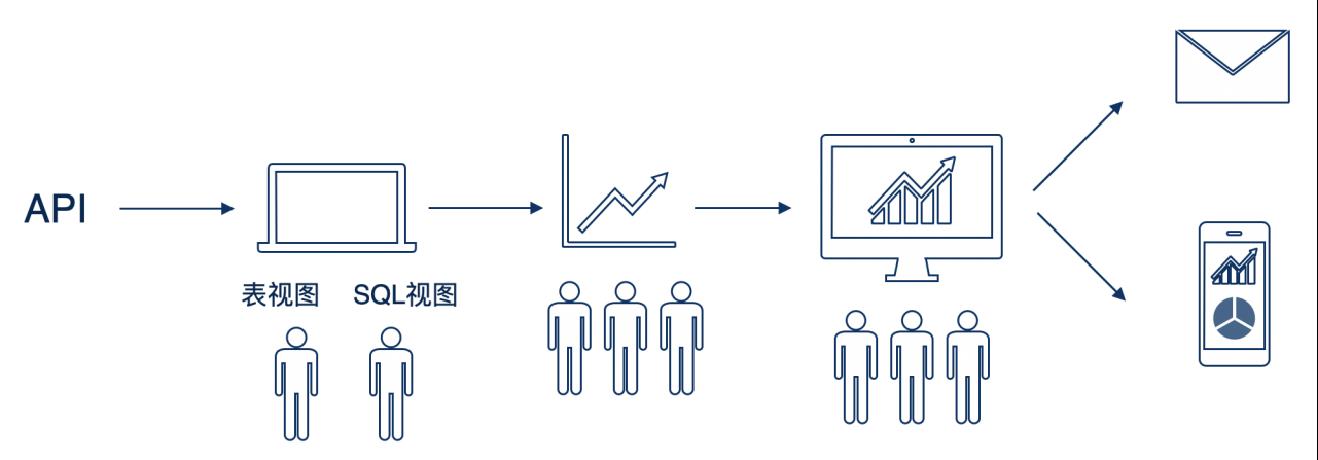
(4)作为即席开发工具
得益于 datart 对接众多数据库的能力,部分企业将 datart 数据视图编辑器当做即席开发工具使用,未来计划支持导出开发结果。
(5)嵌入到自有系统中,通过单点登录鉴权
部分企业将 datart 仪表板分享页嵌入到自有系统中,通过 OAuth2 配置 + 授权分享的方式,统一用户鉴权方式,来做到数据权限控制。
(6)嵌入到自有系统中,作为查询轻应用
部分企业将 datart 仪表板分享页嵌入到自有系统中,作为对数据库的查询轻应用。
datart 开源数据可视化+开放特性
(一)架构设计
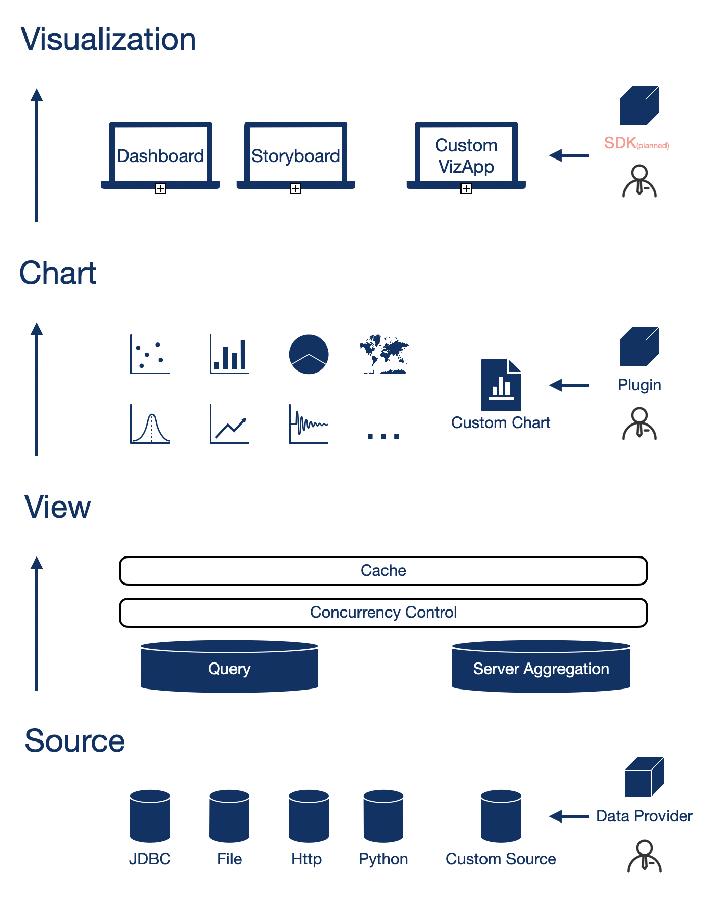
(二)开放特性——图表扩展
datart 设计了完善的图表插件机制,方便技术用户对 BI 系统的核心能力 - 分析图表进行便捷的定制化扩展;摆脱了传统 BI 软件需要对整个应用进行二次开发来定制图表的弊端。
插件机制提供了标准的输入接口,使得开发用户可以灵活适配不同的 Web 绘图引擎(如 D3、echarts 等),通过定义图表元信息、配置参数、生命周期函数来自由构建满足业务需求的图表。高度简化了定制化开发周期。
在技术方面,只要了解 javascript 语言,可以通过绘图引擎提供的 demo 做出样例,就能够胜任开发图表插件的工作,大幅降低了扩展 BI 软件的准入门槛。
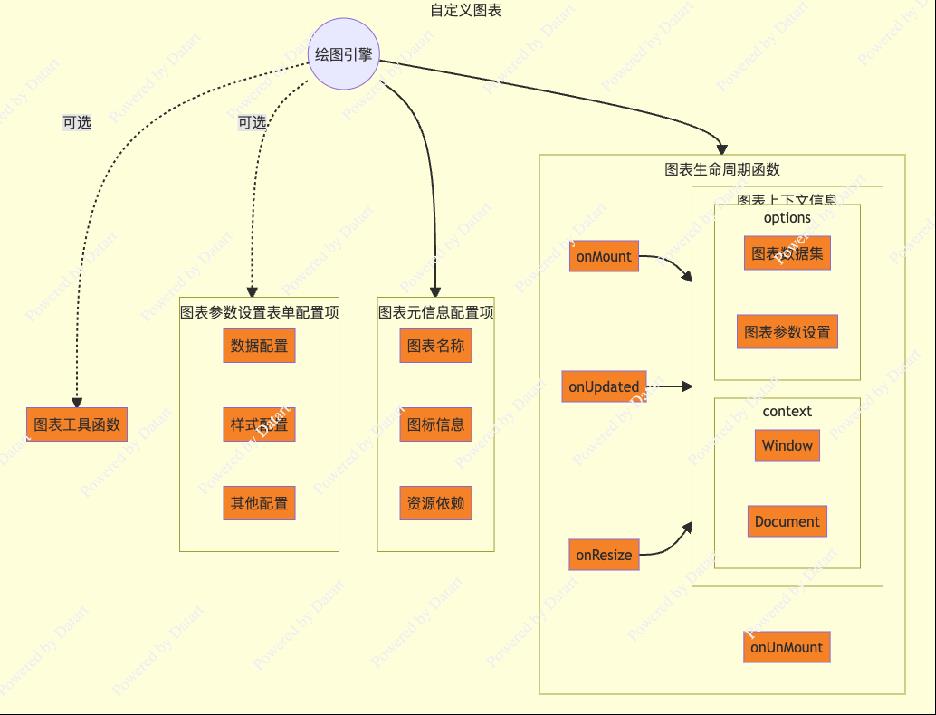
(三)开放特性——数据源扩展
datart 按照标准 JDBC 接口从数据源获取数据。限于时间与人力,datart 没有内置所有类型的 JDBC 数据源配置;但用户可以按照官方文档指导,通过简单配置就可以扩展 JDBC 数据源类型。
对于有更高要求的技术用户,可以参考源码中 DataProvider 类的实现;DataProvider 封装了作为一个 datart 数据源所需的所有标准接口,用户可以自定义业务需要的数据源类别。

(四)开放特性——内置聚合&存储引擎扩展
datart 内置了 H2 内存数据库来支持文件数据源、Http 数据源、以及 JDBC 数据源的服务端聚合功能。
在一些场景下,用户对内置的聚合+存储引擎有着更高的要求,H2 限于能力无法支持这些场景。此时,技术用户可以参考源码中对 H2 数据库的封装,来自行替换为其他性能更强劲的数据库。

(五)开放特性——定时任务递送终端扩展
datart 默认支持发送定时任务到邮件和企业微信,技术用户可以自行扩展标准化接口来支持其他递送终端。

传统BI产品只能对已有数据进行勘察,而现代BI产品更加重视对数据延展洞见,以形成完整数据分析洞察能力,或增强分析能力。
datart 会在平台层面提供可扩展数据增强分析能力,基于数据通过可视化方式不仅回答 What,并且可以回答 Why。
需要用到数据可视化开源产品的,可以关注一下 datart 在github、gitee上的地址
另外,国产开源数据可视化社群请加V信(retech01)
Github:
https://github.com/running-elephant/datartgithub.com/running-elephant/datartgithub.com/running-elephant/datart
Gitee:
running-elephant/datartgitee.com/running-elephant/datart
ES 集中式日志分析平台 Elastic Stack(介绍)
一、ELK 介绍
ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源、任何格式的数据,并且能够实时地对数据进行搜索、分析和可视化。
最近查看 ELK 官方网站,发现新一代的日志采集器 Filebeat,他是 Beats 家族其中的一员,性能超越 logstash,部署简单,占用资源少,可以很方便的和 logstash,ES 对接。
从官方网站可以看出新一代 ELK 架构如下:
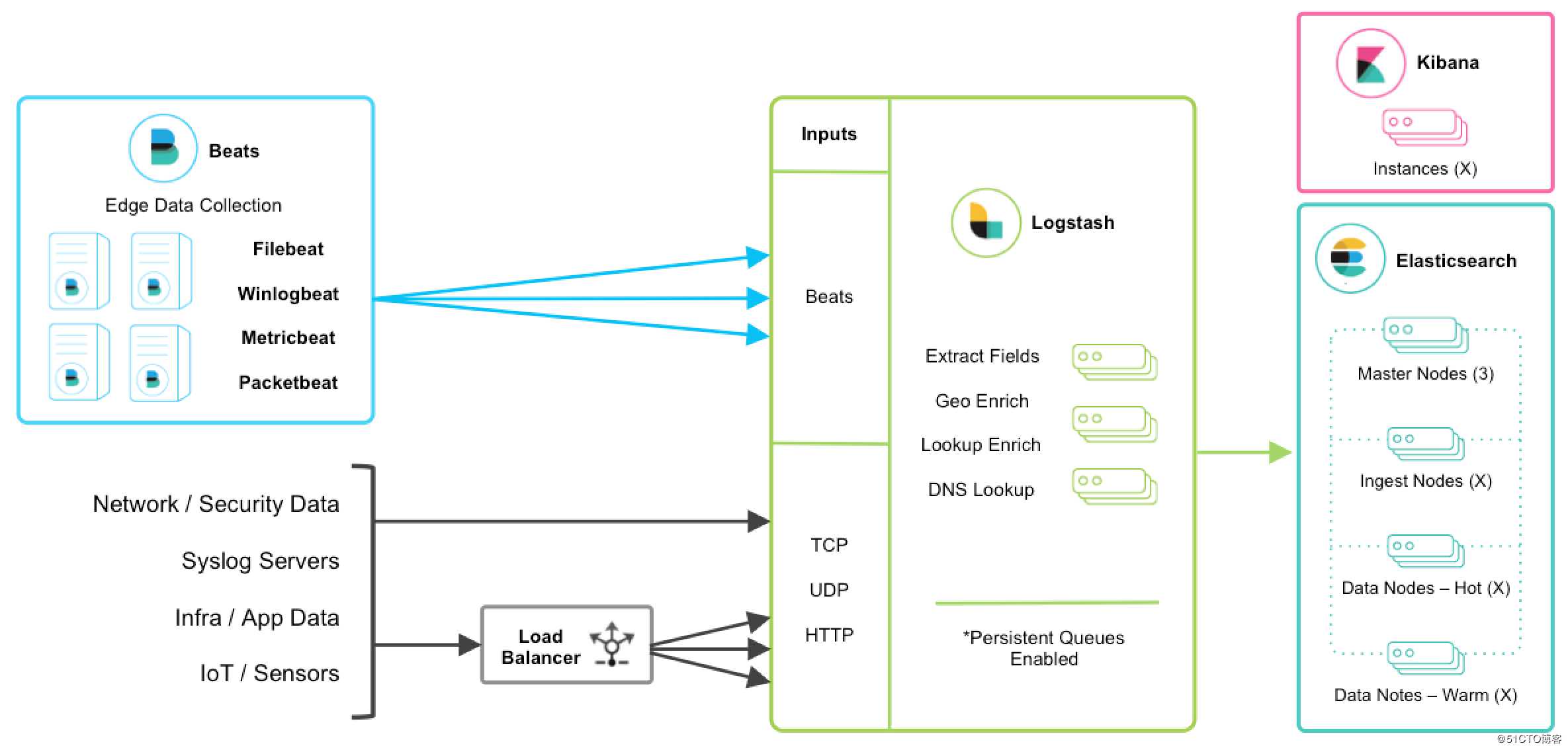
1、Beats
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
Beats 家族各采集器如下:
| 采集器 | 采集内容 |
|---|---|
| Auditbeat | 审计数据 |
| Filebeat | 日志文件 |
| Heartbeat | 可用性检测 |
| Metricbeat | 指标 |
| Packetbeat | 网络数据 |
| Winlogbeat | Windows 事件日志 |
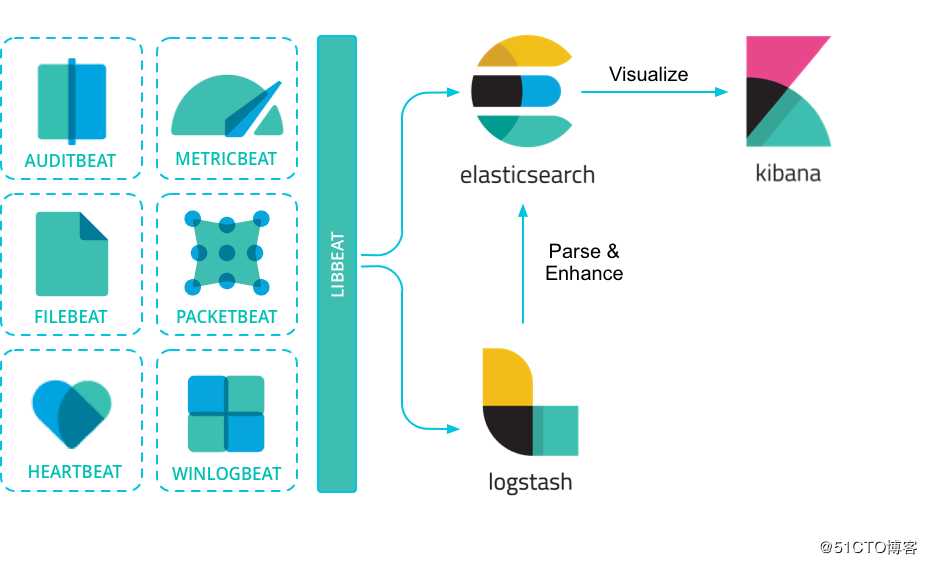
Beats可以直接发送数据到ElasticSearch或通过logstash,在那里您可以进一步处理和增强数据,然后在Kibana可视化。
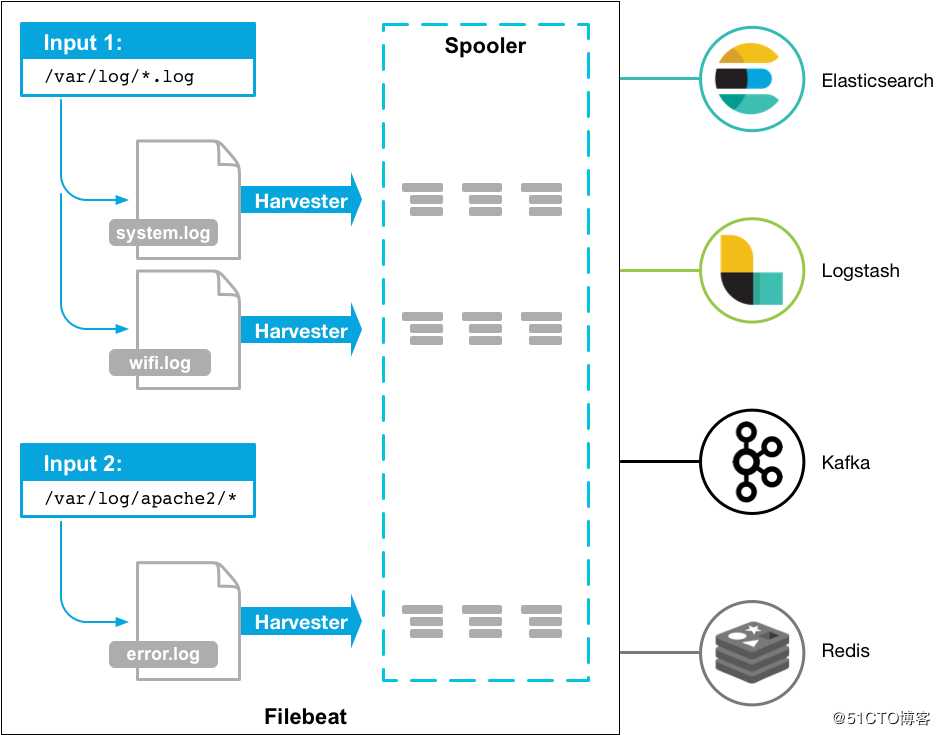
Filebeat
filebat是一个用于转发和集中日志数据的轻量级shipper。作为代理安装在服务器上,filebeat监视指定的日志文件或位置,收集日志事件,并将它们转发给ElasticSearch或logstash进行索引。
以下是filebeat的工作原理:当您启动filebeat时,它将启动一个或多个输入,这些输入位于您为日志数据指定的位置。对于文件记录所在的每一个日志,filebat启动一台harvester。每个harvester读取一个新内容的日志,并将新的日志数据发送到libbeat,ibbeat聚合事件并将聚合的数据发送到filebeat配置的输出。
2、Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
借助 Pipeline 管理图形界面来管理 Logstash 的部署,您可以轻而易举地治理数据加工管道。此外,此项管理功能也与 Elastic Stack 内置的安全特性无缝集成,用以避免任何意外操作。
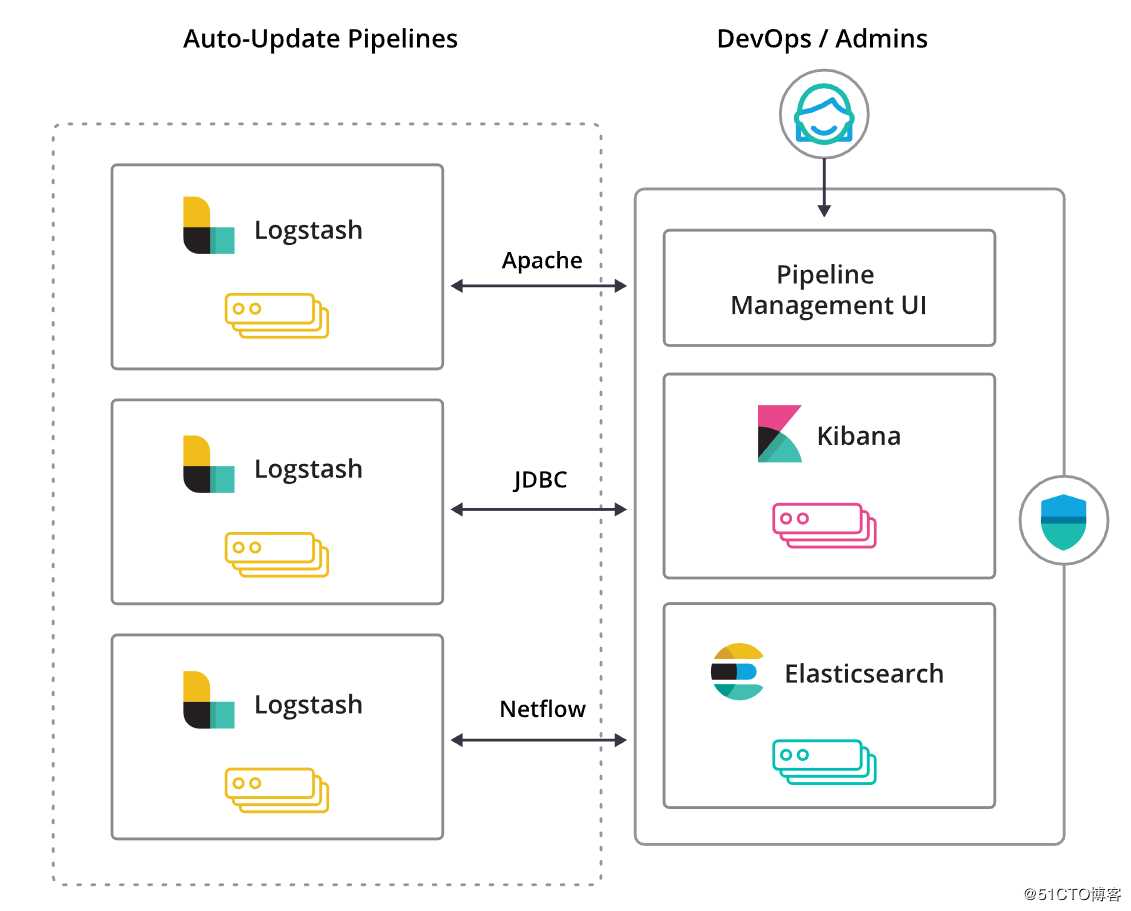
3、Elasticsearch
Elasticsearch 是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可靠性和管理便捷性而设计。
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
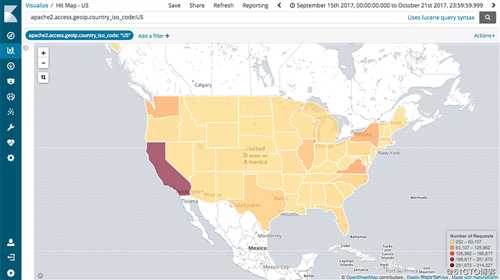
Elasticsearch 允许执行和合并多种类型的搜索 ( 结构化、非结构化、地理位置、度量指标 )搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。
4、Kibana
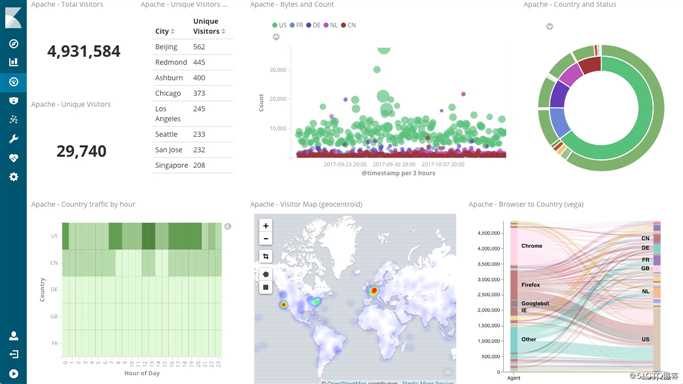
Kibana 能够以图表的形式呈现数据,并且具有可扩展的用户界面,供您全方位配置和管理 Elastic Stack。
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、旭日图,等等。它们充分利用了 Elasticsearch 的聚合功能。
ELK中各组件承担的角色和功能
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据处理引擎,它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到 ES;
Kibana:数据分析和可视化平台。与 Elasticsearch 配合使用,对数据进行搜索、分析和以统计图表的方式展示;
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,使用 golang 基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析。
二、ELK的几种常见架构
1、All-In-One
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例,集中部署于一台服务器。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
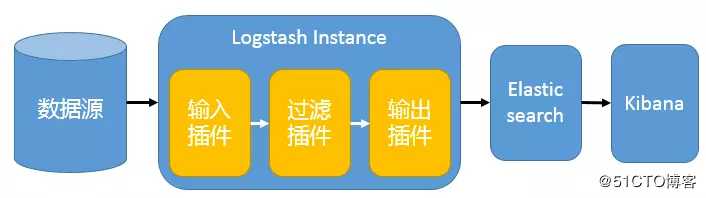
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作。
2、Logstash 分布式采集
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等。
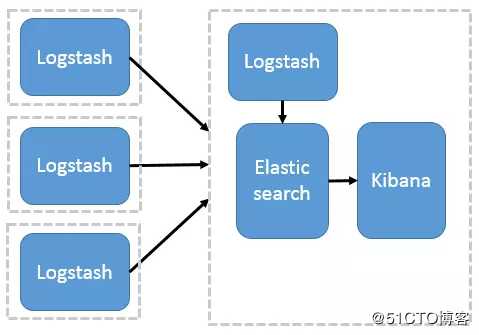
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
3、Beats 分布式采集
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
- Packetbeat(搜集网络流量数据);
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
- Filebeat(搜集文件数据);
- Winlogbeat(搜集 Windows 事件日志数据)
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
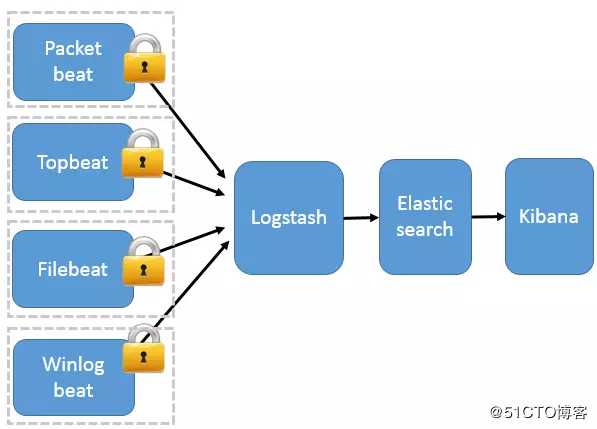
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
4、引入消息队列机制的 Logstash 分布式架构
这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
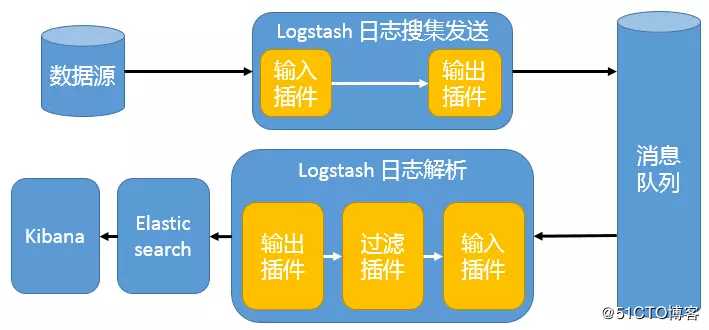
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
5、引入消息队列机制的 Filebeat + Logstash 分布式架构
Filebeat 已经支持 kafka 作为 ouput,5.2.1 版本的 Logstash 已经支持 Kafka 作为 Input,和上面的架构不同的地方仅在于,把 Logstash 日志搜集发送替换为了 Filebeat。这种架构是当前最为完美的,有极低的客户端采集开销,引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性。
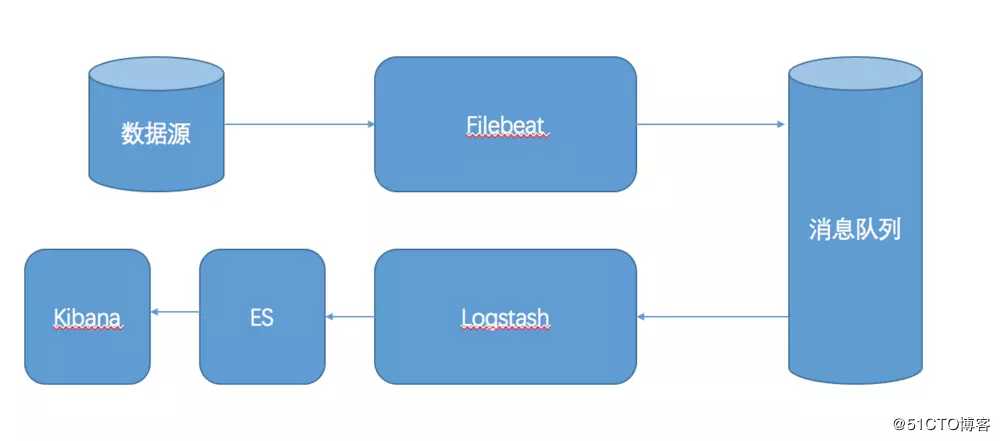
接下来我们进行初步的探视,利用测试环境体验下ELK Stack + Filebeat,测试环境我们就不进行 Kafka 的配置了,因为他的存在意义在于提高可靠性。
以上是关于新一代开源数据可视化平台 datart——技术架构与应用场景的主要内容,如果未能解决你的问题,请参考以下文章
基于webRTC全新架构的新一代可视指挥调度平台VMS/smarteye server-E
云原生视角下,新一代数据平台架构怎么演进? | ArchSummit