世纪证券Zabbix监控系统升级高可用架构的实践分享
Posted Zabbix_China
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世纪证券Zabbix监控系统升级高可用架构的实践分享相关的知识,希望对你有一定的参考价值。
洪嘉铭,就职于世纪证券信息技术部,目前负责运维、监控系统的相关架构设计、开发工作。对操作系统、网络编程、服务器后台架构有丰富实践经验。
世纪证券于2022年8月初完成了Zabbix监控系统的版本(5.2->6.0)和架构升级。本次升级最重要的变更是利用Zabbix6.0官方提供的原生高可用HA特性实现了服务端架构上的高可用。主备机房所有设备的监控已平稳运行一月有余,现将整个过程做一个分享,供有需要的小伙伴参考使用。
1. 架构介绍
公司自建机房和网络,主机房和同城灾备机房通过裸光纤实现内网互联。图1为升级前的部署架构。

图1 Zabbix监控系统v5.2部署架构
该架构明显存在以下问题:
公司两个机房所有被监控设备都只连接一个Zabbix Server节点,且只有一个mysql数据库节点,造成Zabbix Server和MySQL都存在单点故障。一旦这两个服务出现异常,公司监控系统将无法工作,如发生在交易时间,将直接导致公司失去生产系统的运行状态的及时掌握,带来极大的风险隐患。
Zabbix Server和MySQL都只有单节点,造成监控时间的空缺。任何服务器的升级改造、停机操作都将导致公司整个监控服务的暂停中断;
公司业务还处于高速发展期,需监控的设备节点数量和监控维度还在不断增加,Zabbix server的承载能力受制于所在宿主主机的硬件配置,系统扩展性不够。
为解决以上问题,降低系统运行风险,我们对架构进行了升级 ,如图2。

图2 Zabbix监控系统v6.0部署架构
升级后架构带来以下改善:
升级Zabbix6.0,引入了的HA(High Availability)特性,分别在两个机房部署zabbix server主备节点;正常情况下,主节点部署于主机房,备节点部署于同城灾备机房,主节点一旦停止服务,备节点可在1分钟(可配置)内接管服务;如主机主动停止,备节点可立马接管。
增加了MySQL的双主架构下的主备模式部署,提高了监控服务可用性。
增加部署了Zabbix Proxy,用于分散Zabbix Server负载,同时也方便连接网络区域。
主备Server应急切换预案
主备Zabbix Server应急切换预案如图3所示。正常情况下,主Server处于Active状态,备Server处于Standby状态。当主Server停止服务,状态由Active变为Stop或Unavailable后,备Server通过主备状态信息同步机制感知到异常,立即启动接管服务,状态切换为Active状态;Zabbix Agent和Zabbix Proxy在连接主Server失败后,也会尝试连接备Server。整个监控服务自动接管和切换,从而保持监控持续可用。当主节点故障恢复后,状态由Stop或Unavailable切换为Standby状态。

图3 主备Zabbix Server切换预案
MySQL双主架构下的主备模式应急切换预案
MySQL数据库双主架构下的主备模式部署架构的应急切换预案如图4所示。正常情况下,主机房的MySQL数据库作为主数据库,同城灾备机房的数据库作为备数据库,同步主数据库的数据。当主机房的MySQL主数据库停止服务后,此时备数据库作为主数据库继续提供服务,由于主备Zabbix Server服务同时只能配置一个数据库地址,所以此时需要将Zabbix Server服务的数据库配置同时指向备数据库地址,并重启Zabbix Server服务保持整个系统依然可用(此过程目前采用手动切换)。当主机房数据库服务恢复后,此时作为备数据库,可自动同步灾备机房的主数据库,从而自动恢复停止服务期间丢失的数据,继续保持两个数据库可用的状态。

图4 MySQL数据库主主模式架构切换预案
数据库架构的选择
根据Zabbix HA原理,主、备Zabbix Server的状态依赖于数据库来进行同步。如数据库出现故障,整个Zabbix的服务的可用性仍然无法保障。为了保障整个服务的高可用,MySQL数据库的备份部署选择双主架构下的主从模式。
为何不是单主从?在MySQL数据库单主从模式下,当主数据库实例故障后,Zabbix Server服务数据库请求切换到备数据库,如需恢复主数据库停止服务期间丢失的数据,则需要手工同步故障期间的数据,而双主同步则可自动恢复故障期间数据。
为何不用keepalived?考虑到keepalived存在发生“脑裂”的可能,当出现“脑裂”时,主备Zabbix Server基于数据库的状态同步可能会出现数据不一致的情况,从而导致极端情况下,主备Zabbix Server切换不成功。
2. 环境准备
| 主机 | ip | 操作系统 | 软件 |
|---|---|---|---|
| 主Zabbix server/Zabbix web | 192.168.8.111 | CentOS 7.7.1908 | docker 20.10.2 |
| 备Zabbix server/Zabbix web | 192.168.24.111 | CentOS 7.7.1908 | docker 20.10.2 |
| 主Mysql | 192.168.8.222 | CentOS 7.7.1908 | mysql 8.0.28 |
| 备Mysql | 192.168.24.222 | CentOS 7.7.1908 | mysql 8.0.28 |
· 为了阐述后续的配置步骤,此处列出IP地址,但均已做了处理,和真实环境IP地址无任何实际关联。
· zabbix agent版本不高于zabbix server
· zabbix server、zabbix web通过docker镜像的方式安装
· mysql通过原生方式安装。
3. 备份zabbix server文件
· /etc/zabbix/* 中的配置文件
· /usr/lib/zabbix/externalscripts/ 中的外部脚本
· /usr/lib/zabbix/alertscripts 中的告警通知脚本
4. 备份数据库
进入zabbix web,配置zabbix维护期间
停止zabbix server、zabbix web服务(都以docker方式运行)。
docker stop zabbix-web-nginx-mysql
docker stop zabbix-server-mysql
备份整个数据库
mysqldump -uroot -p --single-transaction zabbix | gzip > zabbix_backup.sql.gz
官方文档介绍history相关表结构有相关变化,很多人的做法是不备份history相关表,通过额外脚本导入原数据库的history相关表数据。我们的做法有所不同,备份的是整个数据库,原因是zabbix server在启动时会自动检测数据库版本,并完成数据库的自动升级操作
5. 安装mysql 8
为了避免安装mysql冲突,需先移除已安装的mariadb。
rpm –qa|grep maria
> mariadb-libs-5.5.64-1.el7.x86_64
rpm –e --nodeps mariadb-libs-5.5.64-1.el7.x86_64
官网下载rpm安装包,解压到一个空目录中。

mysql8下载地址
3.rpm安装。
rpm –ivh *.rpm --force
4.关闭selinux。
setenforce 0
编辑 /etc/selinux/config使永久生效
SELINUXTYPE=disabled
启动mysql服务
systemctl start mysqld
systemctl status mysqld
systemctl enable mysqld
查看、修改初始默认密码
cat /var/log/mysqld.log|grep "temporary password"
mysql -uroot -p
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'xxxxx@password';
6. 还原数据库
1.创建zabbix数据库和用户
mysql> create database zabbix character set utf8mb4 collate utf8mb4_bin;
mysql> create user zabbix@localhost identified by 'xxxxxx@password';
mysql> grant all privileges on zabbix.* to zabbix@localhost;
mysql> FLUSH PRIVILEGES;
2.创建root和zabbix用户远程访问权限
mysql> CREATE USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'admin@1234'
mysql> GRANT ALL privileges ON *.* TO 'root'@'%' WITH GRANT OPTION ;
mysql> CREATE USER 'zabbix'@'%' IDENTIFIED WITH mysql_native_password BY 'admin@1234' ;
mysql> GRANT ALL ON zabbix.* TO 'zabbix'@'%' ;
mysql> FLUSH PRIVILEGES;
3.还原zabbix数据库
gunzip < zabbix_backup.sql.gz | mysql -uzabbix -p zabbix
- 配置数据库主主同步
修改配置文件
修改主数据库配置文件/etc/my.cnf,重启服务
#server-id MySQL实例中全局唯一
server-id=1
#relay-log命名,binlog采用默认命名
relay-log=zabbix-relay-bin
#增加最大连接数
#防止当zabbix server进程过多无法连接数据库
max_connections=1500
skip-name-resolve
systemctl restart mysqld
修改从数据库配置文件/etc/my.cnf,重启服务
#server-id MySQL实例中全局唯一
server-id=2
#relay-log命名,binlog采用默认命名
relay-log=zabbix-relay-bin
#增加最大连接数
#防止当zabbix server进程过多无法连接数据库
max_connections=1500
skip-name-resolve
systemctl restart mysqld
2.主从数据库分别创建用户备份的账户
CREATE USER 'repl'@'%' identified with mysql_native_password by 'xxxxxx@password';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
FLUSH PRIVILEGES;
3.设置互为主从
主从数据库分别设置如下
#加锁,阻止所有的写入操作
FLUSH TABLES WITH READ LOCK;
change master to master_host='192.168.xxx.222', \\
master_user='repl', \\
master_password='xxxxxx@password', \\
master_port=3306, \\
master_log_file='binlog.0000xx',\\
master_log_pos=xxxx;
#master host:同步的数据库的地址
#master_user:备份的用户名
#master_password:备份的用户密码
#master_log_file:bin-log的文件名
#master_log_pos:bin-log的位置
#bin-log文件名和位置通过
#show master status命令查看
#对应File, Position字段
START SLAVE;#开启同步
#解锁
UNLOCK TABLES;
分别检查主从数据库同步状态
show slave status\\G;
如下则证明正常

8. 启动zabbix server
1.自定义docker镜像,编写dockerfile
FROM zabbix/zabbix-server-mysql:6.0-centos-latest
USER root
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo \\
&& yum makecache \\
&& yum -y install epel-release \\
&& yum -y install python38 \\
&& python3.8 -m pip install pymssql
USER 1997
在官方镜像的基础上构建了一个python环境
2.构建镜像
docker build -t zabbix/zabbix-server-mysql:6.0-centos-py38 .
3.启动容器
主server
docker run --name zabbix-server-mysql -t \\
-e DB_SERVER_HOST="192.168.8.222" \\
-e MYSQL_DATABASE="zabbix" \\
-e MYSQL_USER="zabbix" \\
-e MYSQL_PASSWORD="xxxxxx@password" \\
-e MYSQL_ROOT_PASSWORD="xxxxxx@password" \\
-e ZBX_HANODENAME="zabbix-server-pbs" \\
-e ZBX_NODEADDRESS="192.168.8.111:10051" \\
-v /etc/localtime:/etc/localtime:ro \\
--privileged=true \\
--restart unless-stopped \\
--net=host \\
-d zabbix/zabbix-server-mysql:6.0-centos-py38
备server
docker run --name zabbix-server-mysql -t \\
-e DB_SERVER_HOST="192.168.8.222" \\
-e MYSQL_DATABASE="zabbix" \\
-e MYSQL_USER="zabbix" \\
-e MYSQL_PASSWORD="xxxxxx@password" \\
-e MYSQL_ROOT_PASSWORD="xxxxxx@password" \\
-e ZBX_HANODENAME="zabbix-server-nfzx" \\
-e ZBX_NODEADDRESS="192.168.24.111:10051" \\
-v /etc/localtime:/etc/localtime:ro \\
--privileged=true \\
--restart unless-stopped \\
--net=host \\
-d zabbix/zabbix-server-mysql:6.0-centos-py38
8. 启动zabbix web
1.自定义docker镜像,编写dockerfile
#用stkaiti.ttf文件替换DejaVuSans文件
#解决中文乱码问题
mv stkaiti.ttf DejaVuSans.ttf
FROM zabbix/zabbix-web-nginx-mysql:6.0-centos-latest
USER root
COPY DejaVuSans.ttf /usr/share/zabbix/assets/fonts/DejaVuSans.ttf
USER 1997
2.构建镜像
docker build -t zabbix/zabbix-web-nginx-mysql:6.0-centos-ch .
3.启动容器
主/备web
docker run --name zabbix-web-nginx-mysql -t \\
-e DB_SERVER_HOST="192.168.8.222" \\
-e MYSQL_DATABASE="zabbix" \\
-e MYSQL_USER="zabbix" \\
-e MYSQL_PASSWORD="xxxxxx@password" \\
-e MYSQL_ROOT_PASSWORD="xxxxxx@password" \\
-e php_TZ="Asia/Shanghai" \\
-p 80:8080 \\
--restart unless-stopped \\
-d zabbix/zabbix-web-nginx-mysql:6.0-centos-ch
9. zabbix agent配置
1.agent 5.2
根据公司的实际情况,agent端尽量保持5.2版不变,但如何保证服务的高可用性,我们的解决方案是:配置文件Server和ServerActive项多配一个ip,用逗号分隔
Server=192.168.8.111,192.168.24.111
ServerActive=192.168.8.111,192.168.24.111
2.agent 6.0
ServerActive项用分号分隔
Server=192.168.8.111,192.168.24.111
ServerActive=192.168.8.111;192.168.24.111
10. 总结
本次升级重点可归纳为三个部分。
· Zabbix Server的主备架构的升级
· MySQL数据库双主架构下的主从模式架构升级
· 为实现高可用,Zabbix Agent在版本v5.2和v6.0共存的情形下进行的升级。
升级后完善了公司的监控服务架构,但仍有可以继续改善的地方。如Zabbix Proxy服务还没有做到高可用,后期可考虑引入keepalived做高可用;Zabbix Server切换MySQL数据库时,目前采用的是人为判定切换时机,后期可考虑设定数据库故障检测的规则,通过脚本实现自动化切换。
更多案例分享将在12月2日Zabbix中国峰会分享!
扫码报名!

扫一扫|加入技术交流群
微信号|17502189550
备注“使用Zabbix年限+企业+姓名”
5000+用户已加入!

一个人走得快,一群人走得远!
鲸品堂|复杂业务系统高扩展架构设计与实践
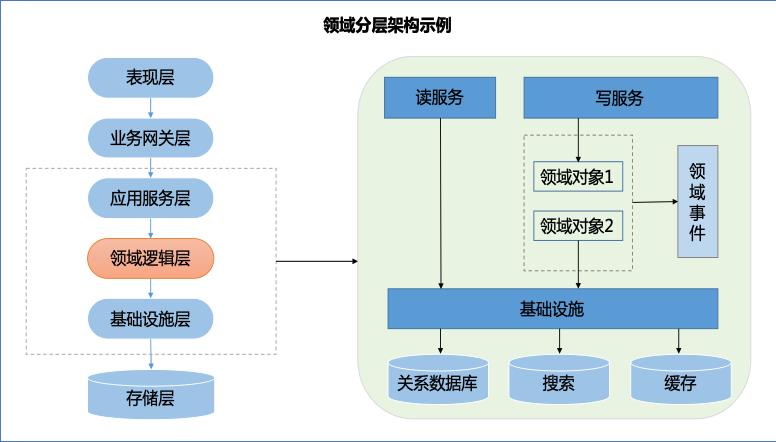
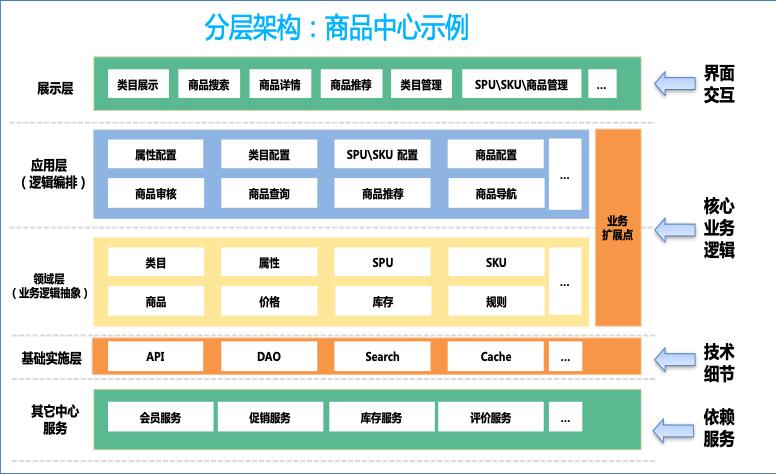
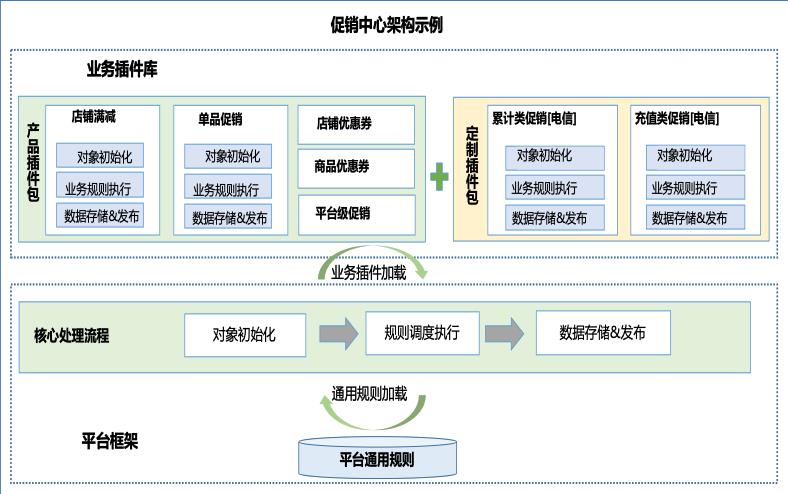
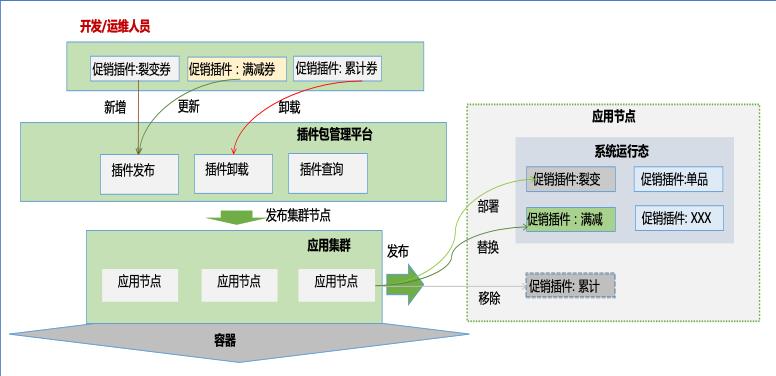
如果问架构师什么是架构,可能会得到很多不同的答案,每个架构师对“架构”都有不一样的理解,当然这不分对错。数据架构、应用架构、部署架构、高性能架构、高可用架构、高扩展架构等都是架构,每一种架构都有应用场景,有不同的技术方法、特征及要求,但我觉得有一个核心的概念是共同的:架构必定是在长期的生产过程中,经过架构师深刻的总结和思考,积累下来的最佳实践和可复用的合理抽象。能够应对复杂挑战的架构在过去、现在及未来都是架构师所向往和追求的理想目标。



1、解耦拆分原则:稳定部分与易变部分分离;核心业务与非核心业务分离;主流程与辅流程分离;应用与数据分离;服务与实现细节分离。
2、松耦合原则:跨域调用异步化,不同业务域之间尽量异步解耦。非核心业务尽量异步化,核心和非核心业务之间,尽量异步解耦。
3、服务依赖原则:核心服务不依赖非核心服务;非核心服务可依赖核心服务;稳定部分不依赖易变的部分、容易变的部分可以依赖稳定的部分。
4、服务自治原则:服务能彼此独立修改、部署、发布和管理。避免引发连锁反应。
1、要定义规范:明确代码扩展性规范与约束,给出示例,引导开发人员在实现业务逻辑时,能够进行结构化、抽象化思考,保障代码的可维护性和可读性。
2、要搭好基础框架:高扩展架构有很多成功的案例,但实施起来没有标准,不能复制,也难以衡量,所以我们需要结合我们自身规范,自身需求,搭建基础框架,降低技术门槛,让开发人员关注业务逻辑编码。
3、要引入设计模式:应用面向对象思想,原则,使用常见设计模式,进行代码层面的设计。
4、要找到扩展点:结合业务需求,识别易变化的点,梳理扩展点清单,对于存在业务变动的代码,利用扩展点重构原有代码,抽象稳定基础能力。
5、要做好代码审查:对代码的审查内容很多,在关注代码的编写是否规范、技术处理规范、业务逻辑实现等的同时,考虑扩展设计来阻止代码腐化。

以上是关于世纪证券Zabbix监控系统升级高可用架构的实践分享的主要内容,如果未能解决你的问题,请参考以下文章