:Knowledge Distillation
Posted Terry_dong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:Knowledge Distillation相关的知识,希望对你有一定的参考价值。
目录
摘要
本问提供了 KD 的复杂研究包括了下述方面:
- KD 的种类
- 训练方案
- teacher-student 结构
- 蒸馏算法
- 表现对比和实际应用
在此基础上,简要回顾了知识蒸馏面临的挑战,并对未来的研究方向进行了讨论和展望。
1. Introduction
近年来深度学习发展火热,主要方向是:
计算机视觉
强化学习
自然语言处理
能够帮助训练深层网络的技术:
residual connection 残差连接
batch normalization 批标准化
为了将大型的复杂网络迁移到移动设备上,节省内存和运算,主要有两个方面的工作:
1)为深度模型提供高效的构建模块:
- 深度可分卷积(MobileNet、ShuffleNet为例)
2)模型压缩和加速技术 有如下分类:
- 参数剪枝和参数共享(Parameter pruning and sharing):这些方法主要是在不影响性能的情况下从深度神经网络中去除不重要的参数。该类别又分为:
- 模型量化(Wu et al., 2016)
- 模型二值化(Courbariaux et al., 2015)
- 结构矩阵(Sindhwani et al., 2015)
- 参数共享(Han et al., 2015;Wang等,2019f)
- 低秩因子分解(Low-rank factorization):这些方法利用矩阵和张量分解来识别深度神经网络的冗余参数(Yu等,2017;Denton等,2014)。
- 可迁移的紧凑卷积滤波器(Transferred compact convolutional filters):这些方法通过传输或压缩卷积滤波器来去除不必要的参数(Zhai et al., 2016)。
- 知识蒸馏(Knowledge distillation (KD)):这些方法将知识从一个较大的深度神经网络提取到一个较小的网络中(Hinton et al., 2015)。
本文不涉及到其他模型压缩算法,只是针对知识蒸馏进行研究:
- 知识蒸馏本质是在 teacher 网络的监督下实现 student 网络的学习
- 知识蒸馏的关键在于如何将 knowledge 从 teacher 网络迁移到 student 网络
- 知识蒸馏网络通常有三部分构成:
- knowledge (知识)
- distillation algorithm (蒸馏算法)
- teacher-student architecture (老师-学生网络结构)

虽然在实践上取得了巨大的成功,但对无论是理论理解还是经验理解的知识提炼的著作并不多。具体地说:
- 为了了解 KD 的工作机制, Phuong & Lampert 在深线性分类器的情况下获得了快速收敛的学习提取学生网络的泛化边界的理论证明(Phuong and Lampert, 2019a)。这个解释回答了学生网络学习的速度,并揭示了决定知识蒸馏成功的因素:
- 数据几何(data geometry)
- 蒸馏目标的优化偏差(optimization bias of distillation objective)
- 学生分类器的强单调性(strong momotonicity of the student classifier)
- Cheng等人量化了从深度神经网络的中间层提取视觉概念,以解释知识的精馏
- Cho & Hariharan 实证详细分析了知识蒸馏的有效性(Cho和Hariharan, 2019)。
- 实证结果表明,由于模型容量的差距(capacity gap),一个较大的模型不一定是一个更好的教师 (Mirzadeh等人,2020)。
- 实验还表明,蒸馏对学生的学习有负面影响。Cho和Hariharan(2019) 的论文中并没有涵盖对不同形式的知识蒸馏的经验评价,也没有关于知识的蒸馏和 teacher-student 的相互影响。
- 知识蒸馏也被用于平滑标签、评估教师模型的准确性以及获得最佳输出层几何形状的先验(Tang et al., 2020)。
对模型压缩的知识蒸馏类似于人类学习的方式。
受此启发,最近的知识提炼方法已经扩展到:
- teacher-student learning(Hinton等人,
- mutual learning (Zhang et al., 2018b)
- assistant teaching (Mirzadeh et al., 2020)
- life-long learning(Zhai et al., 2019)
- self-learning (Yuan et al.,2020)
所有这些知识蒸馏的扩展主要集中在压缩深度神经网络上。由此产生的轻量级学生网络可以轻松地部署在诸如视觉识别、语音识别和自然语言处理(NLP)等应用程序中
此外,知识精馏中的知识从一个模型到另一个模型的迁移可以扩展到其他任务,如:
- 对抗性攻击(adversarial attacks)(Papernot et al., 2016)
- 数据增加 (data augmentation)(Lee et al., 2019a; Gordon and Duh, 2019)
- 数据隐私和安全(data privacy and security)(Wang et al., 2019a)
基于对模型压缩的知识蒸馏,进一步将知识转移的思想应用于训练数据压缩中(compressing training data)
- 数据集精馏:将知识从一个大数据集转移到一个小数据集,以减少深度模型的训练负荷(Wang et al., 2018c; Bohdal et al., 2020).
本文对知识蒸馏的研究进行了综述。本综述的主要目的是:
- 提供知识蒸馏的概述,包括动机的背景知识,基本的符号和公式,以及一些典型的知识,蒸馏和算法;
- 回顾知识蒸馏的最新进展,包括算法和在不同现实场景中的应用;
- 针对知识迁移(knowledge transfer)的不同角度,提出知识蒸馏的一些困难和见解包括:
- 知识的不同类型
- 训练方案
- 知识蒸馏的算法和结构及应用
整个综述研究的问题的组织结构如下图所示:

- section2: KD 的重要概念和传统模型
- section3:不同种类的知识
- section4:不同种类的蒸馏方法
- section5:知识蒸馏的 teacher-student 结构研究
- section6:全面总结了 KD 的最新的研究
- section7:不同知识蒸馏的表现比较
- section8:知识蒸馏的众多应用
- section9:关于知识蒸馏有关的挑战性的问题和未来发展的方向的研究和讨论
2. Background
- 一个普通的 KD 框架通常包含一个或多个大型的 pre-trained 教师模型和一个小型的学生模型。教师模型通常比学生模型大得多。其主要思想是在教师模式的指导下,培养一种高效的学生模式,以获得相当的准确性,从而实现将知识从复杂的 teacher 网络 迁移到紧凑简单的 student 网络;
- 来自教师模型的监督信号,通常是指教师模型学习到的 “知识”,这些知识被用来帮助学生模型模仿教师模型的表现。
- 在一个典型的图像分类任务中,使用 logits (深度神经网络中最后一层的输出)作为教师模型知识的载体,这不同于训练样本中的训练标签
- 例如,一只猫的图像被错误地归类为一只狗的概率非常低,但是这种错误的概率仍然比把一只猫误当成一辆车的概率高很多倍;另一个例子是,手写数字2的图像更类似于数字3,而不是数字7。
- 这种由教师模型学习到的知识也被称为“dark knowledge”
在vanilla KD 中传递 dark knowledge 的方法表述如下。
- 给定 logits 的输出表示为
 ,它是全连接层最后的输出(进入 softmax 函数之前);
,它是全连接层最后的输出(进入 softmax 函数之前); -
是第
 个类的 logit 值
个类的 logit 值 - 属于第 类的概率
 可以被 softmax 函数估计出来:
可以被 softmax 函数估计出来: 
-
因此,这些每个类的概率就可以作为 soft target 来指导 student 网络的训练
-
类似地,one-hot标签被称为 hard target。一个关于 soft target 和 hard target 的直观例子如图所示。

- 不仅如此,一个温度参数 T TT 被引入来控制每个 soft target 的重要程度

-
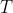 越大,产生的概率分布越“软”,越平滑。尤其地,当
越大,产生的概率分布越“软”,越平滑。尤其地,当  的时候,所有的类的概率分布都变成一样的了。当
的时候,所有的类的概率分布都变成一样的了。当  时,soft target 就变成了 hard target
时,soft target 就变成了 hard target
-
teacher 网络产生的 soft targets 和 ground-truth label 对于引导 student 网络的训练都是很重要的;这两部分分别用于构建 distillation loss 和 student loss。
-
distillation loss 是用来逼近 teacher model 的 logits 和 student 网络的 logits的
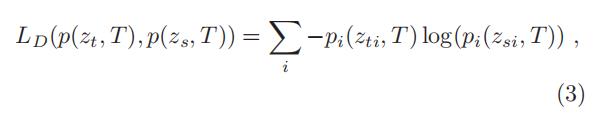
-
和
分别是 teacher 和 student 的 logits,通过一系列的推导:

- 根据式(6),distillation loss 等于在 high temperature下教师模型和学生模型的 零均值 logits 的匹配;即:最小化

- 因此,通过在 hight temperature 学习 teacher 的 logits 和 student 的 logits 之间的差距可以将教师模型所学到的非常有用的知识信息传递给学生模型来训练学生模型。
- student loss 定义为ground truth label和student model的 soft logits 之间的交叉熵
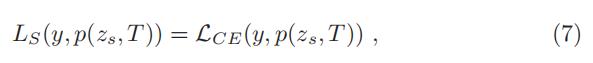
-
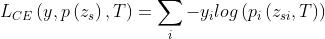 是个 cross-entropy loss
是个 cross-entropy loss  是 groundtruth 的向量;其中只有一个元素为1,表示传输训练样本的ground truth label,其他都为0。
是 groundtruth 的向量;其中只有一个元素为1,表示传输训练样本的ground truth label,其他都为0。
- 在 distillation loss 和 student loss 中,都使用相同的学生模型的 logits,但他们的温度不同:
- student loss 中

- distillation loss 中

- 最终,这个 vanilla KD 的 loss function 是结合 distillation loss 和 student loss:
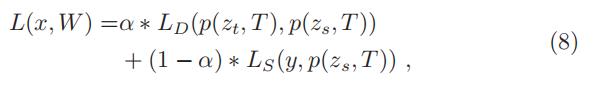
- 其中
 为训练输入
为训练输入  为学生模型的参数
为学生模型的参数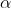 为调节参数。
为调节参数。
- 为了便于理解知识蒸馏,结合教师模型和学生模型的 vanilla KD 的具体架构如图所示:

-
实际上,这是利用基于响应的知识(response-based knowledge)对线下知识(offline knowledge)的蒸馏(distillation)。knowledge 和 distillation 的类型将分别在接下来的第3节和第4节中讨论。
3. Knowledge
在知识蒸馏 KD 中,最重要的三个部分是:
知识类型(knowledge type)
蒸馏方法(distillation strategies)
师生结构(teacher-student architecture)
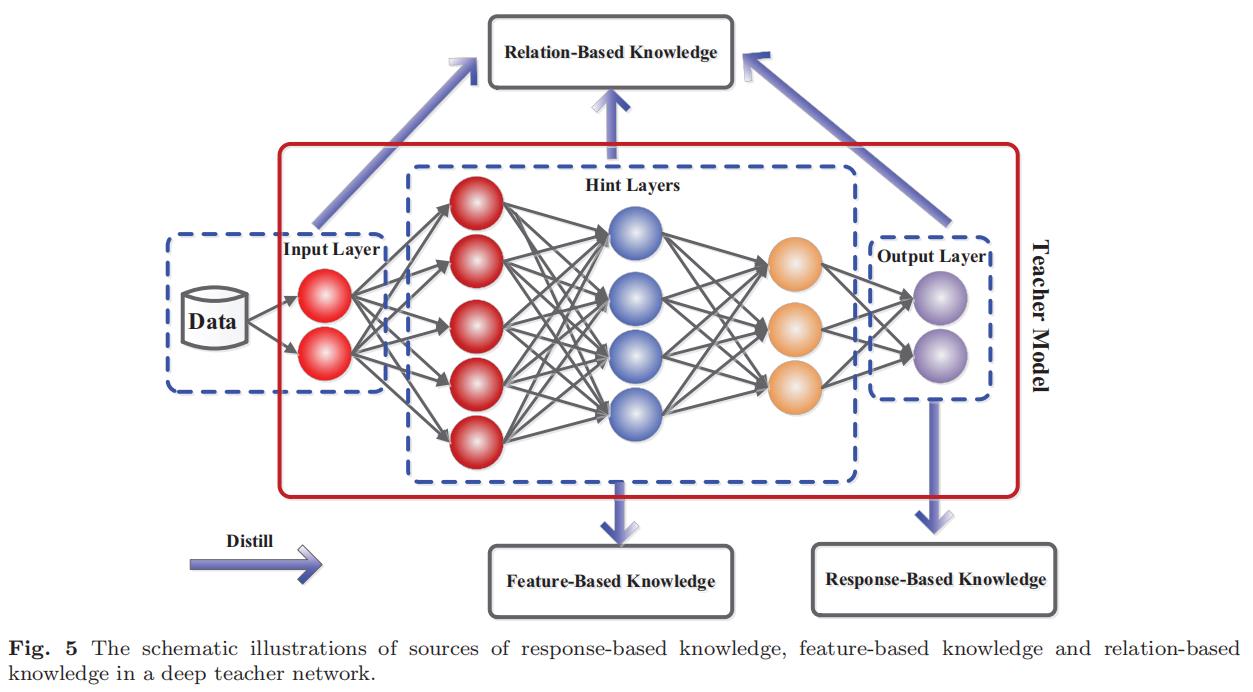
这个部分,精力主要放在研究 knowledge type 上 。
- vanilla KD 使用一个大型深层模型的 logits 作为 teacher knowledge
- 激活层、神经元或中间层的特征也可以作为知识来指导学生模型的学习
- 不同激活层、神经元或成对样本之间的关系包含了教师模型所获得的丰富信息
- 此外,教师模型的参数(或层之间的连接)还包含另一种 knowledge
我们将在以下类别中讨论不同形式的 knowledge:
- response-based knowledge
- feature-based knowledge
- relation-based knowledge
下图显示了教师模型中不同知识类别的直观示例:
3.1 Response-base Knowledge
-
response-based knowledge 通常是指教师模型中最后一个输出层的神经响应。其主要思想是直接模仿教师模型的最终预测结果
- response-based knowledge 方法用于模型压缩简单有效,已广泛应用于不同的任务和应用中
- 图像分类中最常用的 response-based knowledge 是 soft target
- response-based knowledge 的 distillation loss 可以表述为:
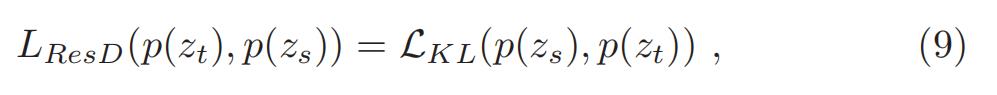
- KL 代表了 KL 散度
- 典型的 response-based 的KD模型如下图所示:

- response-based knowledge 可以用于不同类型的模型预测:
- 对象检测(object detection)任务中的 response knowledge 可能包含 logits 和边界框的偏移量
- 在语义地标定位任务(semantic landmark localization)中,如人体姿态估计,教师模型的 response knowledge 可能包括每个地标的热图(heatmap)
- 近年来,基于响应的知识被进一步探索,以解决 ground-truth label 作为条件目标(conditional targets)的问题
- 基于响应的知识的想法是直接和容易理解的,尤其是在“dark-knowledge”的背景下。
- 从另一个角度来看,软目标 soft target 的有效性类似于标签平滑(label smoothing)或是 regularizers
- 然而,基于响应的知识通常依赖于最后一层的输出,比如 soft target 就是如此。因此,response-based knowledge 就很难代表 teacher model 的中间层中包含的能够知道 student 网络训练的有效信息;尤其是我们认为在 network 很深的时候,中间层的重要程度更加不能忽略
- 因此, soft logits 实际上是类概率分布, response-based KD 也被局限于监督学习领域。
3.2 Feature-Based Knowledge
- 深度神经网络善于学习抽象程度不断提高的多级特征表示。这就是所谓的 “表示学习(representation learning)”
- 因此,无论是最后一层的输出,还是中间层的输出,即 feature map,都可以作为知识来监督学生模型的训练。
- 具体来说,来自中间层的基于特征的知识是 response-based knowledge 的很好的扩展,尤其适用于更狭窄但是层数更深的网络的训练。
- 首先在 Fitnets 中引入了中间表示(intermediate representation)(Romero et al., 2015),为改进学生模型的训练提供了提示。
- 其主要思想是直接匹配教师和学生网络的中间层的激活特征。受此启发,人们提出了各种其他方法来间接匹配这些特征。具体而言
- Zagoruyko和Komodakis(2017) 从原始的特征图衍生出一个“注意图(attention map)”来表达知识。
- Huang和Wang(2017)利用神经元选择性转移对注意图进行了推广。
- Passalis和Tefas(2018)通过匹配特征空间中的概率分布来迁移知识。
- 为了使老师的知识更容易传递,Kim等人(2018)引入了所谓的 factor 作为一种更容易理解的中间表征形式。
- 为了缩小教师与学生之间的表现差距,Jin et al.(2019)提出了路径约束 hint learning,通过教师的 hint 层输出来对学生进行监督。
- 最近,Heo等人(2019c)提出利用隐藏神经元的激活边界(activation boundary of the hidden neurons)进行知识转移
- 有趣的是,教师模型中间层的参数共享与 response-based 知识联合被当做 teacher 的知识(Zhou et al., 2018)。
- 一般情况下,基于特征的知识转移(feature-based)的 distillation loss 可以表示为:
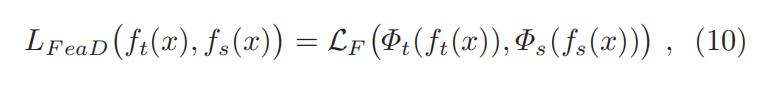
-
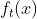 和
和 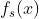 代表的分别是 teacher 和 student 网络的中间层特征图(intermediate feature map
代表的分别是 teacher 和 student 网络的中间层特征图(intermediate feature map 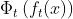 和
和  分别代表当 teacher 网络和 student 网络的 中间层特征不是同一个维度的时候,使用的 transformation function (变换函数)
分别代表当 teacher 网络和 student 网络的 中间层特征不是同一个维度的时候,使用的 transformation function (变换函数)- LF(⋅) 代表为了匹配 teacher 、student 中间层特征而使用的相似度函数
-
- 一个普通的 feature-based knowledge 在下图中表示:
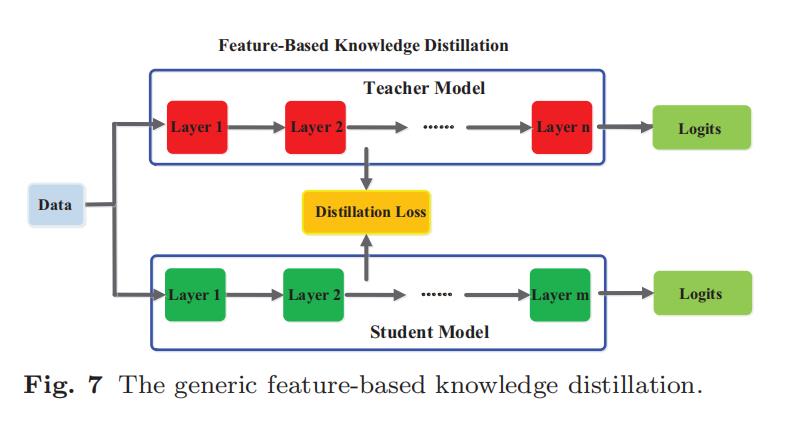
- 在下图的表中我们从 feature type、source layers 和 distillation loss 的角度总结了不同的 feature-based knowledge:
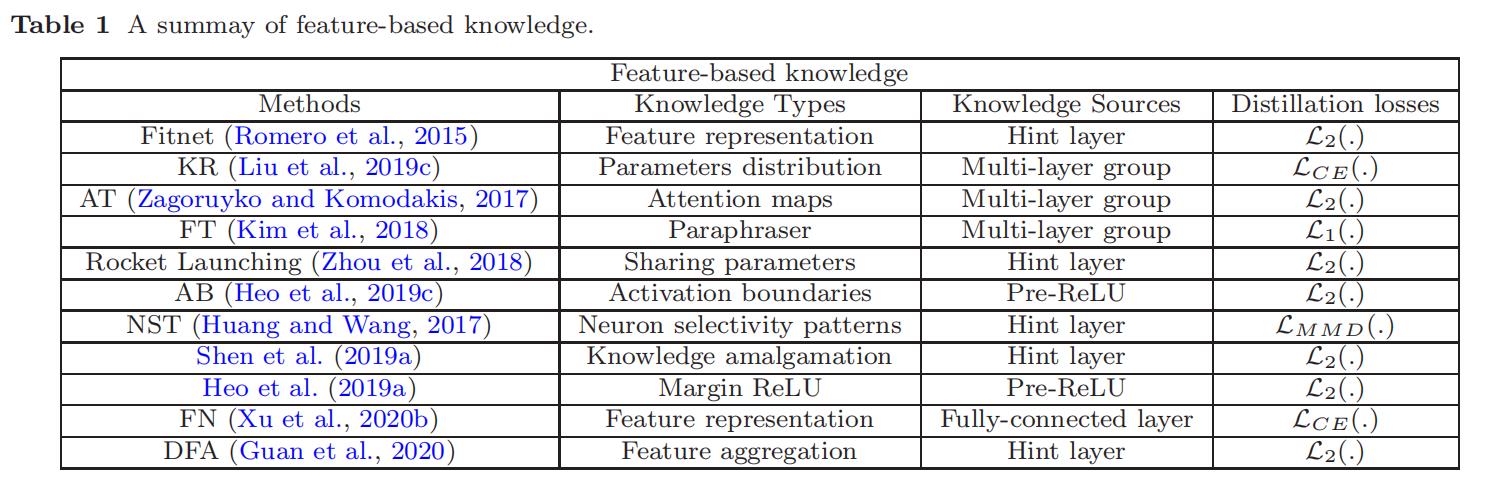
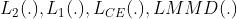 分别代表了
分别代表了  范数距离,
范数距离,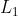 范数距离,交叉熵损失和最大平均偏差损失
范数距离,交叉熵损失和最大平均偏差损失
虽然 feature-based 的知识转移为学生模型的学习提供了有利的信息,但如何有效地从教师模型中选择 hint 层,从学生模型中选择 guided 层,仍有待进一步研究(Romero et al., 2015);由于 hint 层和 guided 层的 尺寸 差异很大,如何正确匹配教师和学生的特征表示也需要探索。
3.3 Relation-Based Knowledge
- response-based knowledge 和 feature-based knowledge 都使用了教师模型中特定层次的输出。relation-based knowledge 进一步探索不同层或数据样本之间的关系。
- 为了探究不同特征图之间的关系,Yim等人(2017)提出了一种求解流程 (flow of solution process (FSP)),该流程由两层之间的 Gram 矩阵定义。FSP矩阵总结了特征图对之间的关系。它是利用两层特征之间的内积(inner products)来计算的。
- (Lee et al., 2018) 提出了利用特征图之间的相关性作为提取的知识,通过奇异值分解的知识蒸馏(knowledge distillation via singular value decomposition)来提取特征图中的关键信息
- 为了利用来自多个教师网络的知识,Zhang和Peng(2018)分别以每个教师模型的 logits 和 features 作为节点,形成了两个图。具体来说,不同教师模型的重要性和关系是通过知识转移前的 logits 和 representation graphs 来建模的(Zhang and Peng, 2018)。
- Lee和Song(2019)提出了 multi-head graph-based 的知识蒸馏。graph knowledge 是任意两个特征图通过多头注意网络(multi-head attention)之间的数据内(intra-data)关系
- 为了探究 pairwise 的提示信息,学生模型还模仿了教师模型中 pairs of hint layers 的相互信息流(mutual information flow) (Passalis et al., 2020b)。
- 一般来说,基于不同特征图之间关系的 relation-based 的 distillation loss 可以表述为:
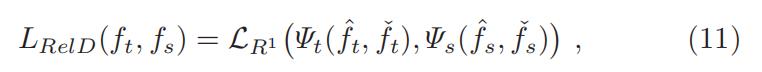
-
 和
和  是 teacher 和 student 网络的特征图
是 teacher 和 student 网络的特征图 - 成对的(pairs)特征是分别从 teacher 网络和 student 网络中提取出来的:teacher 网络的 pair 特征是
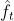 和
和 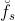
 和
和  分别代表 teacher 内部 feature pairs 的相似度函数 和 student 内部的 feature pairs 的相似度函数。
分别代表 teacher 内部 feature pairs 的相似度函数 和 student 内部的 feature pairs 的相似度函数。 代表的是 teacher 和 student 特征图之间的相关函数。
代表的是 teacher 和 student 特征图之间的相关函数。- 先把 teacher 和 student 内部的 feature map pairs 之间的关系(相似度)求出来;然后再看看 teacher 中的 feature map pairs 之间的关系是否和 student 中的一样
-
- 传统的知识迁移方法往往涉及到单独的 knowledge distillation。也就是说,单独的知识蒸馏之后得到 soft target 直接用于 student 网络的训练。事实上,经过蒸馏的知识不仅包含特征信息,还包含数据样本之间的相互关系 (You et al., 2017; Park et al., 2019). 具体来说:
- Liu et al. (2019g)提出了一种基于 实例关系图 的鲁棒、有效的知识蒸馏方法。实例关系图中传递的知识包含实例特征(instance features)、实例关系图(instance relationship graph)和跨层特征空间转换(space transformation cross layers)。
- Park et al.(2019)提出了一种关系知识蒸馏(relational knowledge distillation),将知识从实例关系中转移(instance relations)。
- 基于流形学习(manifold learning)的思想,通过特征嵌入(feature embedding)来学习学生网络,保留了教师网络中间层样本的特征相似性(Chen et al., 2020b)。
- 利用数据的特征表示,将数据样本之间的关系建模为概率分布(Passalis和Tefas, 2018;Passalis等,2020a)。教师和学生网络的概率分布是通过知识迁移(knowledge transfer)匹配的。
- (Tung and Mori, 2019)提出了一种保持相似性(similarity-preserving)的知识蒸馏方法。特别是: 教师网络中 input pair 的相似激活(similar activation)所产生的 similarity-preserving knowledge 被转移到学生网络中,保留了 pairwise similarities。
- Peng et al. (2019a)提出了一种基于相关一致性(correlation congruence) 的知识蒸馏方法,该方法中提取的知识既包含实例级信息(instance-level information),又包含实例之间的关联(correlations between instances)。利用关联同余进行蒸馏,学生网络可以学习实例之间的关联。
综上所述,基于实例关系的 relation-based knowledge 的 distillation loss 可以被描述为:
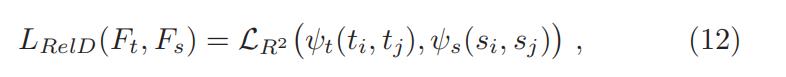
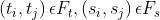
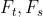 分别是 teacher 和 student 网络中的 特征表示的集合(set of feature representations)
分别是 teacher 和 student 网络中的 特征表示的集合(set of feature representations) ,
,  是相似度函数,代表的分别是
是相似度函数,代表的分别是 和
和  之间的各自的相似度(feature pair 间的相似度)
之间的各自的相似度(feature pair 间的相似度) 是 teacher 和 student 特征表示的相关函数
是 teacher 和 student 特征表示的相关函数
一个典型的 instance relation-based KD 模型如下图所示:

4.知识蒸馏发展趋势
- 教学相长
- 助教,多个老师,同学
- 知识的表示(中间层) 数据集蒸馏,对比学习
- 多模态,知识图谱,预训练大模型的知识蒸馏
- Attention transfer
- channel-wise knowledge distillation for dense。prediction
- contrastive representation distillation
- distill bert
5. 代码
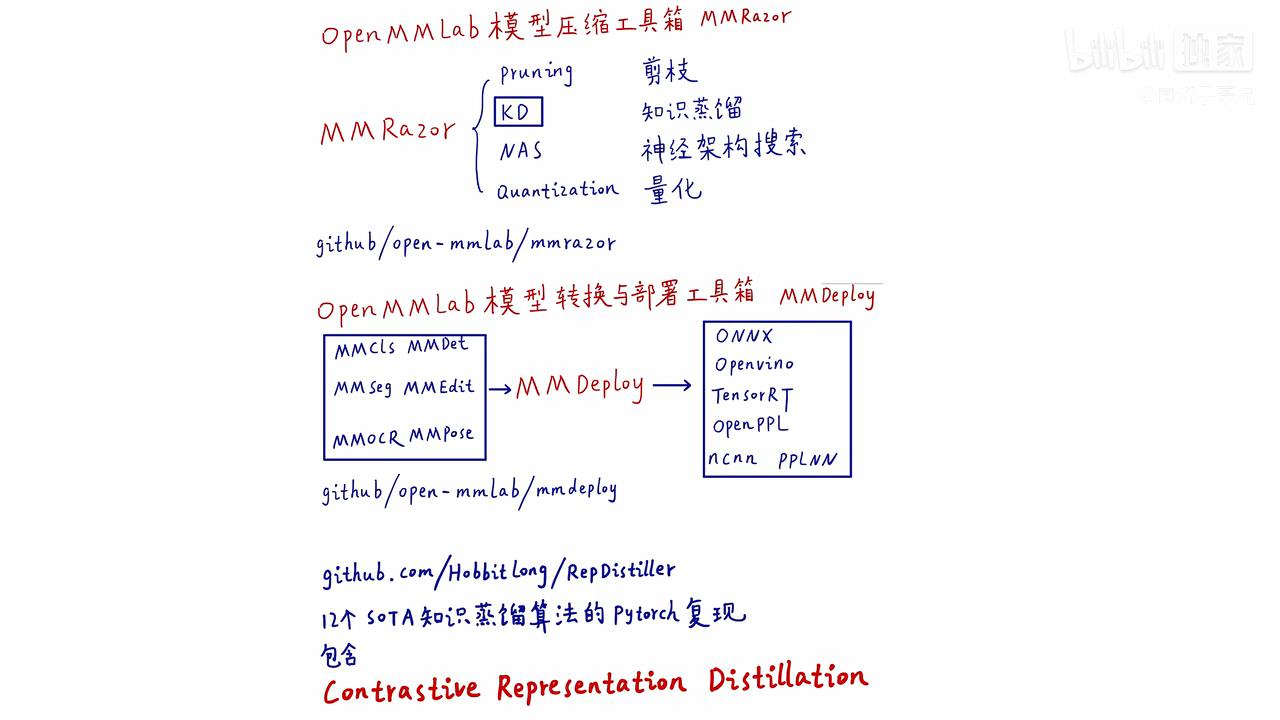
- 模型压缩工具箱MMRazor开源库 (包括剪枝、蒸馏、神经架构搜索和量化)
- open-mmlab/mmrazor
- 模型转换与部署工具箱MMDeploy开源库
- 12个SOTA知识蒸馏算法的pytorch复=现
- HobbitLong/RepDistiller
以上是关于:Knowledge Distillation的主要内容,如果未能解决你的问题,请参考以下文章