后CNN探索,如何用RNN进行图像分类
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了后CNN探索,如何用RNN进行图像分类相关的知识,希望对你有一定的参考价值。
摘要:RNN可以用于描述时间上连续状态的输出,有记忆功能,能处理时间序列的能力,让我惊叹。
本文分享自华为云社区《用RNN进行图像分类——CNN之后的探索》,作者: Yin-Manny。
一、 写前的思考:
当看完RNN的PPT,我惊叹于RNN可以用于描述时间上连续状态的输出,有记忆功能,能处理时间序列的能力。
当拿到思考题,在CNN框架下加入RNN程序,这是可以实现的吗,如果可以,它的理论依据是什么,它的实现方法是什么,它的效果是怎样的。加入这个有必要吗。
我寻找了CNN combine with RNN的资料,看了CLDNN论文,我知道了:
CNN和RNN直接的不同点:
CNN进行空间扩展,神经元与特征卷积;RNN进行时间扩展,神经元与多个时间输出计算;
RNN可以用于描述时间上连续状态的输出,有记忆功能;CNN则用于静态输出;
CNN高级结构可以达到100+深度;RNN的深度有限。
CNN和RNN组合的意义:
大量信息同时具有时间空间特性:视频,图文结合,真实的场景对话;
带有图像的对话,文本表达更具体;
视频相对图片描述的内容更完整。
但是这对思考题没有什么帮助。
于是我又从RNN分类图像下手,试图弄明白RNN能用于图像分类的原理,首先需要将图片数据转化为一个序列数据,例如MINST手写数字图片的大小是28x28,那么可以将每张图片看作是长为28的序列,序列中的每个元素的特征维度是28,这样就将图片变成了一个序列。同时考虑循环神经网络的记忆性,所以图片从左往右输入网络的时候,网络可以记忆住前面观察东西,然后与后面部分结合得到最后预测数字的输出结果,理论上是行得通的。但是对于图像分类,CNN才是主流,RNN图像分类的理论,对于CNN能有什么帮助呢?
甚至我们知道,循环神经网络还是不适合处理图片类型的数据:
第一个原因是图片并没有很强的序列关系,图片中的信息可以从左往右看,也可以从右往左看,甚至可以跳着随机看,不管是什么样的方式都能够完整地理解图片信息;
第二个原因是循环神经网络传递的时候,必须前面一个数据计算结束才能进行后面一个数据的计算,这对于大图片而言是很慢的,但是卷积神经网络并不需要这样,因为它能够并行,在每一层卷积中,并不需要等待第一个卷积做完才能做第二个卷积,整体是可以同时进行的。
那么我要怎么在CNN中加入RNN程序呢?
初步设想:
把CNN比较深层次的网络提取到的特征序列化,再喂给RNN进行分类,因为我认为这时候CNN提取到的特征比原始图像有更强的序列关系(如下图,越深层得到的特征序列关系越强,比如跳着看可能就难以进行分类了)
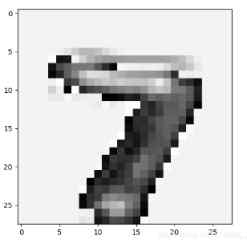
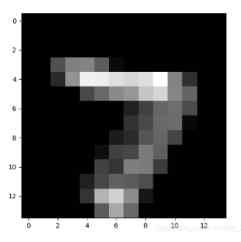
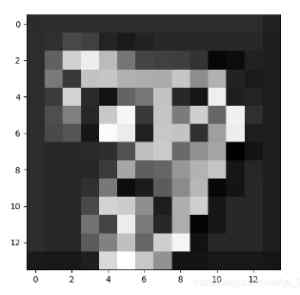
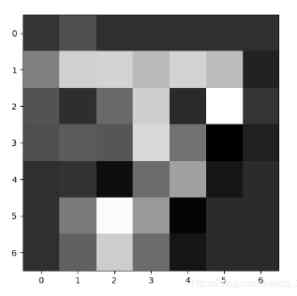
二、 如何将图像数据改成序列数据?如何加入RNN系列程序,以改进图片分类的性能?
设image.shape为(h,w)
则令time_steps=h, input_size=w即可将图像数据改成序列数据
令X=[batch_size,h,w]
outputs, states = tf.nn.dynamic_rnn(rnn_cell, X, dtype=tf.float32)即可将X应用于RNN程序
如果是三通道图片,如RGB,则利用图像处理知识将三通道图像转为单通道灰度图像。
例如:
import matplotlib.pyplot as plt # plt 用于显示图片
from PIL import Image
import numpy as np
image1 = Image.open('./1.jpg')
img=np.array(image1)
# 通道转换
def change_image_channels(image):
# 3通道转单通道
if image.mode == 'RGB':
r, g, b = image.split()
return r,g,b
ima = change_image_channels(image1)
for i in range(3):
plt.imshow(ima[i])
plt.show()
r=img[:,:,0]
g=img[:,:,1]
b=img[:,:,2]
GRAY = b * 0.114 + g * 0.387 + r * 0.29
im=Image.fromarray(GRAY) # numpy 转 image类
im.show()效果如下:


正如初步设想所说,把CNN比较深层次的网络提取到的特征序列化,再喂给RNN进行分类,因为我认为这时候CNN提取到的特征比原始图像有更强的序列关系,也许能够改进图片分类的性能?
例如我们将第一层的特征图喂到RNN中

import sys
sys.path.append('..')
import torch
from torch.autograd import Variable
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms as tfs
from torchvision.datasets import MNIST
# 定义数据
data_tf = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.5], [0.5]) # 标准化
])
train_set = MNIST('./data', train=True, transform=data_tf, download=True)
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
train_data = DataLoader(train_set, 64, True, num_workers=2)
test_data = DataLoader(test_set, 128, False, num_workers=2)
# 定义模型
class rnn_classify(nn.Module):
def __init__(self, in_feature=28, hidden_feature=100, num_class=10, num_layers=2):
super(rnn_classify, self).__init__()
self.rnn = nn.LSTM(in_feature, hidden_feature, num_layers) # 使用两层 lstm
self.classifier = nn.Linear(hidden_feature, num_class) # 将最后一个 rnn 的输出使用全连接得到最后的分类结果
def forward(self, x):
'''
x 大小为 (batch, 1, 28, 28),所以我们需要将其转换成 RNN 的输入形式,即 (28, batch, 28)
'''
x = x.squeeze() # 去掉 (batch, 1, 28, 28) 中的 1,变成 (batch, 28, 28)
x = x.permute(2, 0, 1) # 将最后一维放到第一维,变成 (28, batch, 28)
out, _ = self.rnn(x) # 使用默认的隐藏状态,得到的 out 是 (28, batch, hidden_feature)
out = out[-1, :, :] # 取序列中的最后一个,大小是 (batch, hidden_feature)
out = self.classifier(out) # 得到分类结果
return out
net = rnn_classify()
criterion = nn.CrossEntropyLoss()
optimzier = torch.optim.Adadelta(net.parameters(), 1e-1)
# 开始训练
from utils import train
train(net, train_data, test_data, 10, optimzier, criterion)迭代10次准确率高达98%,因此分类效果还是不错的。
三、 不同的RNN细胞结构、不同的RNN整体结构,对分类性能有什么影响?
不同的细胞结构具有不同的门结构,对长短期记忆有不同的权重
不同的RNN整体结构有不同的层数与架构,对长短期记忆有不同的遗忘属性
常见RNN细胞总结:
BasicRNNCell--一个普通的RNN单元。
GRUCell--一个门控递归单元细胞。
BasicLSTMCell--一个基于递归神经网络正则化的LSTM单元,没有窥视孔连接或单元剪裁。
LSTMCell--一个更复杂的LSTM单元,允许可选的窥视孔连接和单元剪切。
MultiRNNCell--一个包装器,将多个单元组合成一个多层单元。
DropoutWrapper - -一个为单元的输入和/或输出连接添加dropout的包装器。
常见RNN整体结构:
LSTM和GRU,其它的还有向GridLSTM、AttentionCell等
这些在tf.keras.layers.***中都可以直接调用API
因此只需修改下面一行代码的API即可实现不同的RNN细胞结构、不同的RNN整体结构对分类性能的影响的实验。
self.rnn = nn.LSTM(in_feature, hidden_feature, num_layers) # API由于时间问题我没有运行完代码,直接附上相关资料的实验结果:


一般来说,多层结构的复杂度更高,分类性能会更好,但是产生的时间成本也会更多。
四、 nn.dynamic_rnn输出的final_state.h和output[:,-1,:]是否是相同的?
RNN 是这样一个单元:y_t, s_t = f(x_t, s_t-1) ,画成图的话,就是这样:
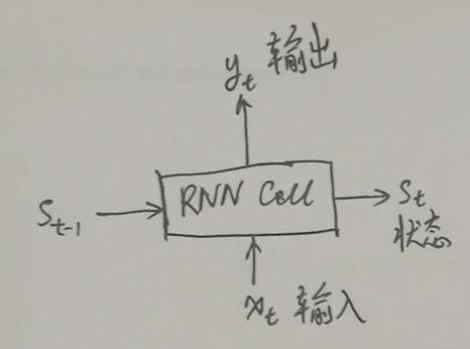
考虑 Vanilla RNN/GRU Cell(vanilla RNN 就是最普通的 RNN,对应于 TensorFlow 里的 BasicRNNCell),工作过程如下:
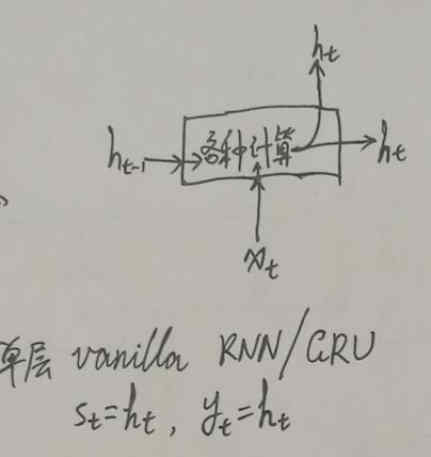
这时,s_t = y_t = h_t
对于 LSTM,它的循环部件其实有两部分,一个是内部 cell 的值,另一个是根据 cell 和 output gate 计算出的 hidden state,输出层只利用 hidden state 的信息,而不直接利用 cell。这样一来,LSTM 的工作过程就是:
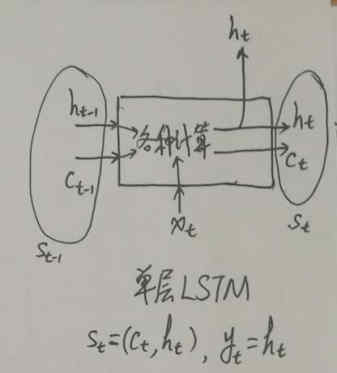
其中真正用于循环的状态 s_t 其实是 (c_t, h_t) 组成的 tuple(就是 TensorFlow 里的 LSTMStateTuple),而输出 y_t 仅仅是 h_t(例如网络后面再接一个全连接层然后用 softmax 做分类,这个全连接层的输入仅仅是 h_t,而没有 c_t),这时就可以看到区分 RNN 的输出和状态的意义了。
如果是一个多层的 Vanilla RNN/GRU Cell,那么一种简单的抽象办法就是,把多层 Cell 当成一个整体,当成一层大的 Cell,然后原先各层之间的关系都当成这个大的 Cell 的内部计算过程/数据流动过程,这样对外而言,多层的 RNN 和单层的 RNN 接口就是一模一样的:在外部看来,多层 RNN 只是一个内部计算更复杂的单层 RNN。图示如下:
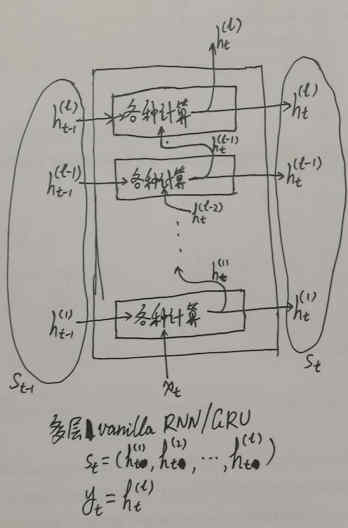
大方框表示把多层 RNN 整体视为一层大的 Cell,而里面的小方框则对应于原先的每一层 RNN。这时,如果把大方框视为一个整体,那么这个整体进行循环所需要的状态就是各层的状态组成的集合,或者说把各层的状态放在一起组成一个 tuple:st=(st(l),st(2),…, st(l))而这个大的 RNN 单元的输出则只有原先的最上层 RNN 的输出,即整体的yt= yt(l)=ht(l)。
最后对于多层 LSTM:
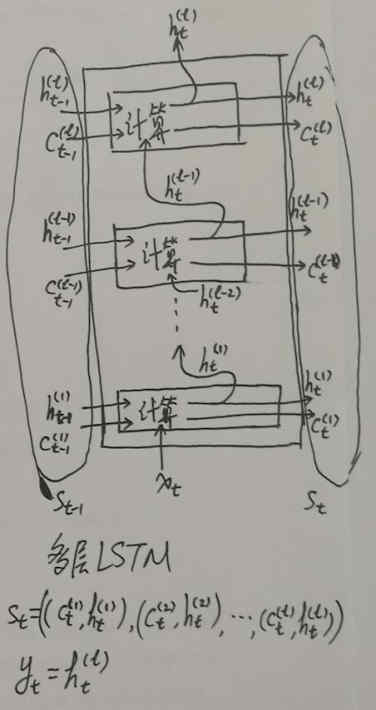
和之前的例子类似,把多层 LSTM 看成一个整体,这个整体的输出就是最上层 LSTM 的输出:yt=ht(l);而这个整体进行循环所依赖的状态则是每一层状态组合成的 tuple,而每一层状态本身又是一个 (c, h) tuple,所以最后结果就是一个 tuple 的 tuple
这样一来,便可以回答问题:final_state.h和output[:,-1,:]是否是相同的
output是RNN Cell的output组成的列表,假设一共有T个时间步,那么 outputs = [y_1, y_2, ..., y_T],因此 outputs[:,-1,:] = y_T;而 final_state.h 则是最后一步的隐层状态的输出,即 h_T。
那么,到底 output[:,-1,:]等不等于final_state.h 呢?或者说 y_T 等不等于 h_T 呢?看一下上面四个图就可以知道,当且仅当使用单层 Vanilla RNN/GRU 的时候,他们才相等。
代码运行结果具体见附件代码第三问。
以上是关于后CNN探索,如何用RNN进行图像分类的主要内容,如果未能解决你的问题,请参考以下文章