Java与Mysql的unicode编码
Posted YuYunTan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java与Mysql的unicode编码相关的知识,希望对你有一定的参考价值。
文章目录
前言
近期工作时候,遇到爆冷知识,主要是因为mysql的utf8默认是utf8mb3,而用4个字节表示的utf8编码,存入数据库,需要mysql的utf8mb4,所以导致数据入库异常。故而记录一波。然后自己要做数据插入数据库前的限制(因为DBA明确表示目前环境不支持utf8mb4)。
本篇博文会夹杂一点知识盲区的地方,秉着共享的观点分享,内容进行了一定语言的整理。
Unicode字符编码
要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A。具体的符号对应表,可以查询Unicode网站。
Java中的char
char原本表示单个字符,在java中是2字节大小(16 bit)。以前的unicode可以用一个char表示,而现在存在一些unicode字符使用两个char表示。
码点
码点:与一个编码表(例如Unicode编码表)中的某个字符对于的代码值。
Unicode码点的值采用十六进制书写,并加上前缀U+
类似于下面所示,一般来说Java中的char可以使用UTF-16的编码unicode去指定字符,例如\\u0022,是字符 " 的Unicode编码码点值。
char A = '\\u0022';
String testA = "\\u0022";// 编译会出错,Unicode转义序列会在解析代码前处理,无论你是注释还是非注释
// C:\\user ==> 编译时会爆非法unicode转义序列,因为java认为\\u后跟着的是16进制的unicode编码,当写成C:\\\\user则没有问题了
Java中的Unoicode的码点最大和最小值分别是 Character.MIN_CODE_POINT 和 Character.MAX_CODE_POINT。这两个值用16进制表示,分别是 0x000000 和 0X10FFFF。十进制则是0和1114111。
单一的char字符,是16位长度的原数据类型,也就是能表示的范围只有0到65536,即码点值在0x0000和0XFFFF之间,这之间的字符属于Unicode 的代码级别(平面)的第一基本的多语言级别(BMP,basic multilingual plane),剩下的16个代码级别在 0x010000 和 0X10FFFF,其中包含了辅助字符(supplementary character)。
oracle是这么描述的:
The
chardata type is a single 16-bit Unicode character. It has a minimum value of'\\u0000'(or 0) and a maximum value of'\\uffff'(or 65,535 inclusive).
码元和代理对
BMP级别中,每个字符可以用16位表示,也就是一个char表示,被称为代码单元(code unit)。而辅助字符则采用一对连续的代码单元(两个char)进行编码,称为代理对(surrogate pair)。这种编码模式就称为UTF-16。
意思就是说,辅助字符(码点值大于0XFFFF)采用一对代理对(高、低代理)表示。
在Java中除非确实要处理UTF16的代码单元时才采用char,因为java中char是UTF16编码的一个代码单元,它并非代表UTF-8编码。
代理所处于BMP区域的码点值不会有其他字符,所以如果判断出一个码点单元的码点值属于高代理,那么就说明,下一个码点单元是低代理(否则字符串非法)。
| 码点值 | 名字 |
|---|---|
| U+D800-U+DB7F | High Surrogates |
| U+DB80-U+DBFF | High Private Use Surrogates |
| U+DC00-U+DFFF | Low Surrogates |
现在的问题来了。
辅助字符是如何分为两个代码单元的?
假设有一个码点a,(范围在U+10000-U+10FFFF)之间。
-
计算高代理步骤:
(1) 码点值减去
0x10000,得到的值的范围为20比特长的0...0xFFFFF。辅助平面中的码位从U+10000到U+10FFFF,共计FFFFF个,即 2 20 = 1 , 048 , 576 2^20=1,048,576 220=1,048,576个,需要20位bit来表示。
(2) 高位的10比特的值(值的范围为
0...0x3FF)被加上0xD800得到第一个码点值称为高代理,值的范围是0xD800...0xDBFF。10 个1组成1111111111,换算16进制就是3FF。
-
计算低代理步骤
(3)低位的10比特的值(值的范围也是
0...0x3FF)被加上0xDC00,就能得到低位代理。
java底层很巧妙的这么计算:
public static final char MIN_HIGH_SURROGATE = '\\uD800'
public static final char MIN_LOW_SURROGATE = '\\uDC00';
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000;
public static char highSurrogate(int codePoint)
return (char) ((codePoint >>> 10)
+ (MIN_HIGH_SURROGATE - (MIN_SUPPLEMENTARY_CODE_POINT >>> 10)));
public static char lowSurrogate(int codePoint)
return (char) ((codePoint & 0x3ff) + MIN_LOW_SURROGATE);
高位主要是因为码点是20比特长度,所以高位往左移10位,留下的便是高代理所需要的10位比特,同时需要减掉的
0x10000也进行左移10位。
个人认为高位处理可以是下面所示,意思比较明确
(char) (((codePoint-MIN_SUPPLEMENTARY_CODE_POINT) >>> 10) + MIN_HIGH_SURROGATE)
低位和
0x3FF进行与操作后,高位的前10位全为0,然后再加上低代理的最低位,即可。
unicode,UTF-8,UTF-16,UTF-32
Unicode和UTF-8和UTF-16以及UTF-32,可能容易比较混淆。
Unicode表示是字符集,和美国的ASCII,西欧的ISO 8859-1,俄罗斯的KOI-8,中国的GB 18030等一样,表示的是一个编码字符集,是一组编号的有序字符集或一组字符表,每个字符集都有唯一的编号。 完成字符和码点值之间映射而用。
UTF-8和UTF-16以及UTF-32都是unicode字符集的字符编码方案,是计算机将码点表示为八位字节(octets)序列的方式,例如UTF-16。UTF8、UTF16、UTF32是出于要在内存中存储字符的目的而对unicode字符编号进行编码。
UTF-8
UTF-8的设计有以下的多字符组序列的特质:
- 单字节字符的最高有效byte永远为0。
- 多字节序列中的首个字符组的几个最高有效byte决定了字节的大小。最高有效位为
110的是2字节,而1110的是三字节,如此类推。 - UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序的问题,也因此它实际上并不需要字节顺序标记。(byte-order mark,BOM)。
- 但存储文件时,在UTF-8+BOM格式文件的开首,很多时都放置一个
U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文本文件是以UTF-8编码的文件。 - 兼容ASCII,由于互联网兴起而制定
Java中Unicode和UTF-8之间的转换关系表
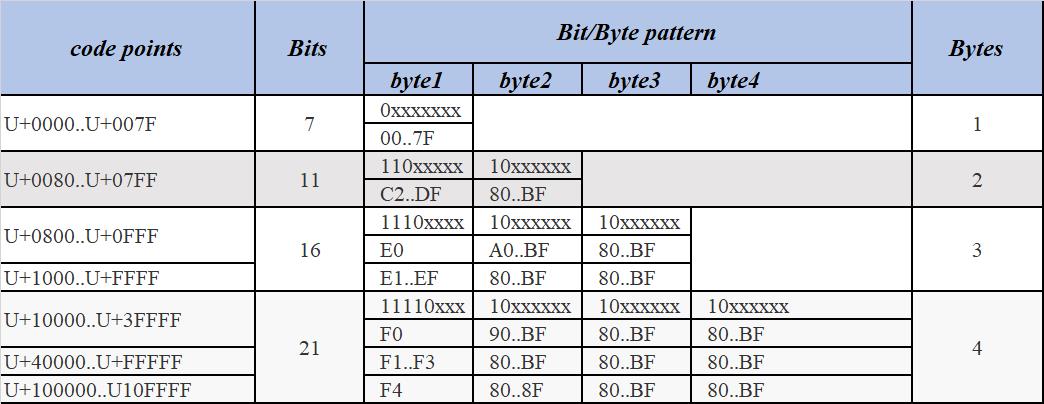
UTF-16
把Unicode字符集的抽象码点映射为采用固定长为16位码元(char)的整数的序列,用于数据存储或传递。Unicode字符的码点值,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
在java中,UTF-8变长表示是1-4字节。而UTF16则是1-2个码元(char)。
UTF-16中,无论是进行编码成字节序存储文件时还是将字符串按照UTF16编码成字节数组,都需要指定字节顺序,这个字节顺序分两类,称为大端序(Big endian )和小端序( Little endian )。默认情况下,java的UTF-16是大端序编码。
java中,StandardCharsets类的静态变量。UTF_16是默认的大端序,和UTF_16BE是一样。UTF_16LE则是小端序。
大小端序
一个多位的整数,按照存储地址从低到高排序的字节中,如果该整数的最低有效字节(类似于最低有效位)在最高有效字节的前面,则称小端序;反之则称大端序。
在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。
以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是大端序 方式;25在前,4E在后,这是小端序方式。
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端序方式;如果头两个字节是FF FE,就表示该文件采用小端序方式。
UTF-32
UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
UTF-32的主要优点是可以直接由Unicode码位来索引。在编码序列中查找第N个编码是一个常数时间操作。编码序列中的字符位置可以用一个整数来表示,整数加一即可得到下一个字符的位置,就和ASCII字符串一样简单。
每个码位使用四个字节,空间浪费较多。
比如ASCII字符
a,用UTF8编码是1个字节,用UTF-16编码是2个字节,而用UTF32编码,却是4个字节。
UTF32也有大端序和小端序。
大端序:
00 00 FE FF小端序:
FF FE 00 00
java针对UTF-8和UTF-16的额外说明
考虑下面的字符,ASCII的字符 a,构成的字符串。
String test = "a";// 字符a的Unicode码\\u0041
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);// 1
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);// 4
test = "aa";
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);// 2
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);// 6
test = "aaa";
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);// 3
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);// 8
test = new StringBuilder().appendCodePoint(0x07FF).toString();
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);//2
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);//4
test = new StringBuilder().appendCodePoint(0x07FF).appendCodePoint(0x07FF).toString();
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);//4
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);//6
test = new StringBuilder().appendCodePoint(0X10FFFF).appendCodePoint(0X10FFFF).toString();
System.out.println(test.getBytes(StandardCharsets.UTF_8).length);// 8
System.out.println(test.getBytes(StandardCharsets.UTF_16).length);// 10
理解2个点:
- UTF-8是可变长编码,在
U+0000..U+007F之间只需要编码成1个字节,以此类推(按照前面的表格对应)。 - UTF-16编码,需要额外加入编码的字节数组前加BOM,占据2个字节。另外的字符再按照字符对应的码点值进行UTF-16编码,每个字符占据2个字节或4个字节(如果码点值大于
0XFFFF)。
常见的中文,比如“谭”字构成的字符串,UTF-8编码属于3字节,UTF16则是4字节。原因是,“谭”字属于BMP平面内,可以用一个char表示,所以转换成字符串长度则是1。
java中码点与char互换的函数(列出部分实用的)
Character类
public static boolean isValidCodePoint(int codePoint)
判断码点是否是有效码点
public static boolean isBmpCodePoint(int codePoint)
判断码点是否属于BMP平面字符
public static boolean isSupplementaryCodePoint(int codePoint)
判断码点是否属于补充字符
public static boolean isHighSurrogate(char ch)
判断char是否属于高代理区间的字符
public static boolean isLowSurrogate(char ch)
判断char是否属于低代理区间的字符
public static boolean isSurrogate(char ch)
判断char是否属于代理区间的字符(可能是高代理,可能是低代理)
public static boolean isSurrogatePair(char high, char low)
判断两个char是否属于一对代理对
public static int charCount(int codePoint)
判断码点需要几个char表示
public static int toCodePoint(char high, char low)
将高低代理字符转换成码点
public static int codePointAt(CharSequence seq, int index)
给定字符序列及下标,得到对应字符的码点
public static int codePointAt(char[] a, int index)
给定字符数组及下标,得到对应字符的码点
public static int codePointAt(char[] a, int index)
给定字符数组及下标,得到对应字符的码点
public static char highSurrogate(int codePoint)
给定码点,得到对应的高代理字符
public static char lowSurrogate(int codePoint)
给定码点,得到对应的低代理字符
public static char[] toChars(int codePoint)
给定码点,得到对应的UTF-16字符表示
String类
public int codePointAt(int index)
得到对应下标的UTF-16字符所对应的码点
codePoints()
得到字符串对应的码点流
public int codePointCount(int beginIndex, int endIndex)
返回beginIndex到endIndex-1之间的码点数量。
StringBuilder,StringBuffer类
appendCodePoint(int codePoint)
通过码点追加字符
mysql的UTF-8和utf8mb4
近期由测试人员,使用apache的commons-lang3包。maven引入如下所示。
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
RandomStringUtils生成的字符串构建的字符串,生成后插入mysql的数据库时,由于Mysql采用的是utf8编码,当遇到码点值不在BMP内的字符时,无法插入数据库,就会抛出异常,报错信息类似于。
Cause: java.sql.SQLException: Incorrect string value: '\\xF0\\xA9\\xB8\\x80' for column 'columnName' at row 1
UTF-8编码,第一个字符
\\F0标明,该字符采用的是UTF8的4字节编码。
主要是该列采用的是varchar类型,而且插入的mysql数据库,默认的数据集是utf8,默认的排序规则是utf8_general_ci,mysql的驱动版本是5.1.25,版本还在5.7的时候,而mysql该版本的utf8默认是utf8mb3,限制是在1-3字节的unicode字符,即BMP字符。
字符集和排序规则不再赘述,相关含义参见MYSQL官方给的解释。
后面给出的解决方案大概分两个类型,一个是mysql底层数据库改成utf8mb4的字符集,以及对应的排序规则。另一个是不改变底层数据库字符集的情况下,兼容改造或者限制。
由于DBA明确表示,不支持utf-8的编码字符集。所以只能采取第二种方式。最后敲定是进行限制。
解决一共就有两种方向:
- 将varchar类型改成varbinary类型
- 限制插入的数据属于utf8mb3的字符
varchar类型改成varbinary类型
- 将出错字段改成byte[]数组而非String类型,所要插入的数据用UTF8模式进行编码,然后mybatis读取回来后的byte[]数组用UTF-8进行解码成String
- 出错字段依旧保持是String类型,将mysql驱动升级为5.1.48,数据库连接参数上加上字符集是characterEncoding=UTF-8的配置
在5.1.25的驱动时,因为底层jdbc的驱动中,ResultSetImpl的getString,将得到的byte[]数据以US-ASCII进行编码。
区别在于下面是5.1.48时,判断元数据的列的类型是binary的类型时,采用连接时的参数编码。
String encoding = metadata.getCollationIndex() == CharsetMapping.MYSQL_COLLATION_INDEX_binary ? this.connection.getEncoding()
: metadata.getEncoding();
字段依旧是String的情况下,采用varbinary,能够解决mysql仅采用utf8编码但可以保存4字节UTF8的问题。
限制字段为utf8mb3
处于utf8mb4的字符属于十分不常见,很少用的字符。所以最后是对其作出限制。如何限制成为一个问题,即给定一个字符串,如果判断不是utf8mb4格式的?或者说如何判断该字符串是utf8mb3格式的?
实际上是对字符串所用的码点进行判断,是否每个码点都是BMP字符,存在一个不是,就说明不符合要求。
public static boolean isMysqlSupportString(String content)
return StringUtils.isBlank(content) || content.codePoints().allMatch(Character::isBmpCodePoint);
然后后面又想到一个优化,大概是这样也可以进行判断。
public static boolean isMysqlSupportString2(String content)
return StringUtils.isBlank(content) || content.codePoints().toArray().length == content.length();
等同于下面的判断:
public static boolean isMysqlSupportString2(String content)
return StringUtils.isBlank(content) || content.codePointCount(0,content.length()) == content.length();
结语
本次算是涨了一波知识,主要是对于字符编码,即Java的码点部分有了清晰的认知。希望该博文对看者有用。
参考文献
以上是关于Java与Mysql的unicode编码的主要内容,如果未能解决你的问题,请参考以下文章