Bitmap使用详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bitmap使用详解相关的知识,希望对你有一定的参考价值。
参考技术A 用到的图片不仅仅包括.png、.gif、.9.png、.jpg和各种Drawable系对象,还包括位图Bitmap图片的处理也经常是影响着一个程序的高效性和健壮性。
为什么不直接用Bitmap传输?
位图文件虽好,但是非压缩格式,占用较大存储空间。
Bitmap主要方法有:获取图像宽高、释放,判断是否已释放和是否可修改,压缩、创建制定位图等功能
用于从不同的数据源(如文件、输入流、资源文件、字节数组、文件描述符等)解析、创建Bitmap对象
允许我们定义图片以何种方式如何读到内存。
推荐阅读: android - Bitmap-内存分析
注意事项:
decodeFileDescriptor比decodeFile高效
查看源码可以知道
替换成
建议采用decodeStream代替decodeResource。
因为BitmapFactory.decodeResource 加载的图片可能会经过缩放,该缩放目前是放在 java 层做的,效率比较低,而且需要消耗 java 层的内存。因此,如果大量使用该接口加载图片,容易导致OOM错误,BitmapFactory.decodeStream 不会对所加载的图片进行缩放,相比之下占用内存少,效率更高。
这两个接口各有用处,如果对性能要求较高,则应该使用 decodeStream;如果对性能要求不高,且需要 Android 自带的图片自适应缩放功能,则可以使用 decodeResource。
推荐阅读:[ BitmapFactory.decodeResource加载图片缩小的原因及解决方法
canvas和Matrix可对Bitmap进行旋转、放缩、平移、切错等操作
可以用Bitmap.onCreateBitmap、Canvas的clipRect和clipPath等等方式
推荐阅读: android自定义View学习4--图像剪切与变换
对初始化Bitmap对象过程中可能发生的OutOfMemory异常进行了捕获。如果发生了OutOfMemory异常,应用不会崩溃,而是得到了一个默认的Bitmap图。
如果不进行缓存,尽管看到的是同一张图片文件,但是使用BitmapFactory类的方法来实例化出来的Bitmap,是不同的Bitmap对象。缓存可以避免新建多个Bitmap对象,避免内存的浪费。
如果图片像素过大,使用BitmapFactory类的方法实例化Bitmap的过程中,需要大于8M的内存空间,就必定会发生OutOfMemory异常。
可以将图片缩小,以减少载入图片过程中的内存的使用,避免异常发生。
推荐阅读:
Bitmap详解与Bitmap的内存优化
一看就懂 详解redis的bitmap(面试加分项)
在上文《面试杀手锏:Redis源码之SDS》中我们深入分析了 SDS 的实现,本次介绍的位图(BitMap)就是借助 SDS 实现的。
本文在最后讲解了BitMap对腾讯面试题的解决方案,并基于BitMap实现了仿GitHub提交次数的日历图,希望各位看官看的开心😄
1.位图简介
如果我们需要记录某一用户在一年中每天是否有登录我们的系统这一需求该如何完成呢?如果使用KV存储,每个用户需要记录365个,当用户量上亿时,这所需要的存储空间是惊人的。
Redis 为我们提供了位图这一数据结构,每个用户每天的登录记录只占据一位,365天就是365位,仅仅需要46字节就可存储,极大地节约了存储空间。
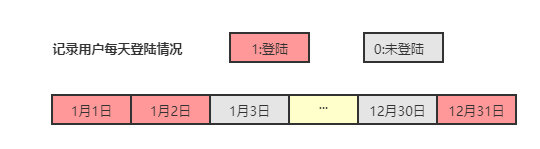
位图数据结构其实并不是一个全新的玩意,我们可以简单的认为就是个数组,只是里面的内容只能为0或1而已(二进制位数组)。
2.命令实战
Redis提供了SETBIT、GETBIT、BITCOUNT、BITOP四个常用命令用于处理二进制位数组。
SETBIT:为位数组指定偏移量上的二进制位设置值,偏移量从0开始计数,二进制位的值只能为0或1。返回原位置值。GETBIT:获取指定偏移量上二进制位的值。BITCOUNT:统计位数组中值为1的二进制位数量。BITOP:对多个位数组进行按位与、或、异或运算。
127.0.0.1:6379> SETBIT first 0 1 # 0000 0001
(integer) 0
127.0.0.1:6379> SETBIT first 3 1 # 0000 1001
(integer) 0
127.0.0.1:6379> SETBIT first 0 0 # 0000 1000
(integer) 1
127.0.0.1:6379> GETBIT first 0
(integer) 0
127.0.0.1:6379> GETBIT first 3
(integer) 1
127.0.0.1:6379> BITCOUNT first # 0000 1000
(integer) 1
127.0.0.1:6379> SETBIT first 0 1 # 0000 1001
(integer) 0
127.0.0.1:6379> BITCOUNT first # 0000 1001
(integer) 2
127.0.0.1:6379> SETBIT first 1 1 # 0000 1011
(integer) 0
127.0.0.1:6379> BITCOUNT first # 0000 1011
(integer) 3
127.0.0.1:6379> SETBIT x 3 1
(integer) 0
127.0.0.1:6379> SETBIT x 1 1
(integer) 0
127.0.0.1:6379> SETBIT x 0 1 # 0000 1011
(integer) 0
127.0.0.1:6379> SETBIT y 2 1
(integer) 0
127.0.0.1:6379> SETBIT y 1 1 # 0000 0110
(integer) 0
127.0.0.1:6379> SETBIT z 2 1
(integer) 0
127.0.0.1:6379> SETBIT z 0 1 # 0000 0101
(integer) 0
127.0.0.1:6379> BITOP AND andRes x y z #0000 0000
(integer) 1
127.0.0.1:6379> BITOP OR orRes x y z #0000 1111
(integer) 1
127.0.0.1:6379> BITOP XOR x y z #0000 1000
(integer) 1
# 对给定的位数组进行按位取反
127.0.0.1:6379> SETBIT value 0 1
(integer) 0
127.0.0.1:6379> SETBIT value 3 1 #0000 1001
(integer) 0
127.0.0.1:6379> BITOP NOT notValue value #1111 0110
(integer) 1
3.BitMap源码分析
3.1 数据结构
如下展示了一个用 SDS 表示的一字节(8位)长的位图:
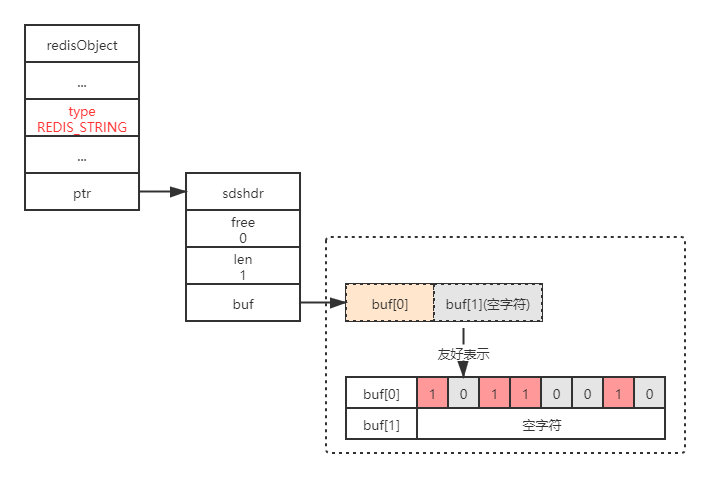
扩展:Redis 中的每个对象都是有一个 redisObject 结构表示的。
typedef struct redisObject // 类型 unsigned type:4; // 编码 unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ // 引用计数 int refcount; // 执行底层实现的数据结构的指针 void *ptr; robj;
type的值为REDIS_STRING表示这是一个字符串对象sdshdr.len的值为1表示这个SDS保存了一个1字节大小的位数组- buf数组中的
buf[0]实际保存了位数组 - buf数组中的
buf[1]为自动追加的\\0字符
为了便于我们观察,buf数组的每个字节都用一行来表示,buf[i]表示这是buf数组的第i个字节,buf[i]之后的8个格子表示这个字节上的8位。
为再次拉齐各位思想,如下展示了另外一个位数组:
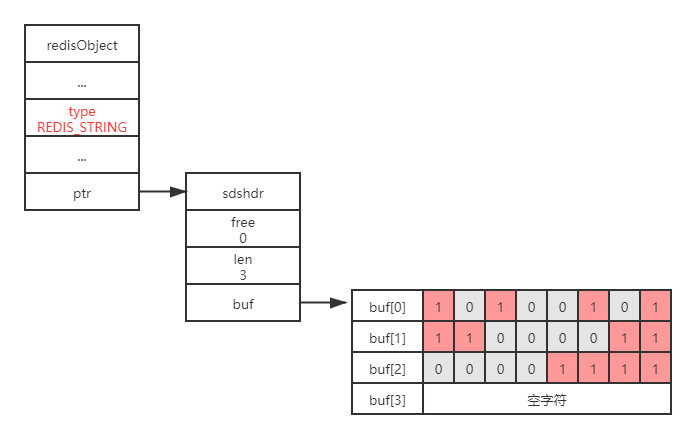
位数组由buf[0]、buf[1]和buf[2]三个字节保存,真实数据为
1111 0000 1100 0011 1010 0101
3.2 GETBIT
GETBIT用于返回位数组在偏移量上的二进制位的值。值得我们注意的是,GETBIT的时间复杂度是O(1)。
GETBIT命令的执行过程如下:
- 计算$ byte = \\lfloor offset\\div8 \\rfloor $ (即
>>3),byte 值表示指定的 o f f s e t offset offset 位于位数组的哪个字节(计算在第几行); - 指定 b u f [ i ] buf[i] buf[i] 中的 i i i了,接下来就要计算在8个字节中的第几位呢?使用 $ bit = (offset\\ %\\ 8)+1 $计算可得;
- 根据 b y t e byte byte 和 b i t bit bit 在位数组中定位到目标值返回即可。
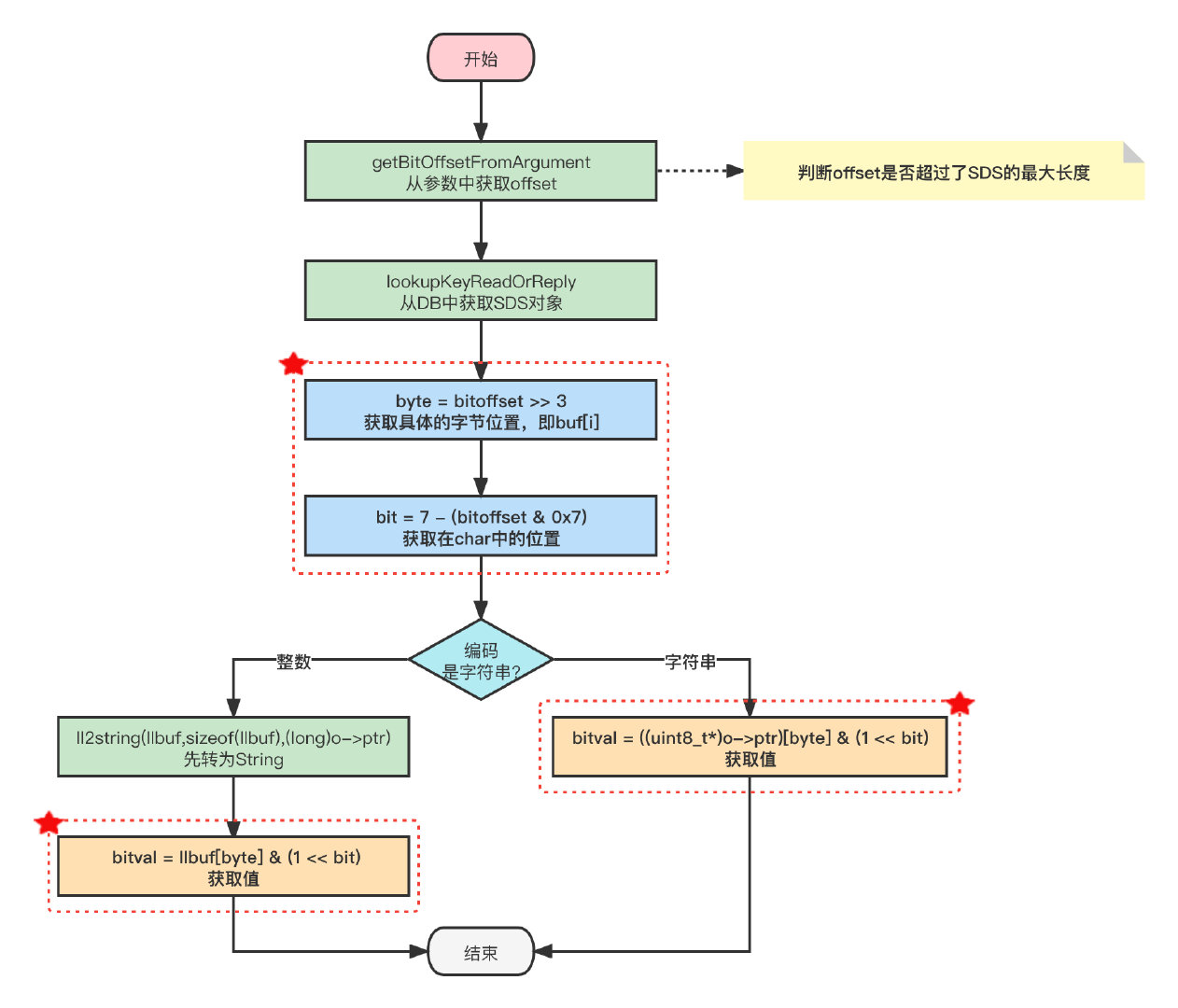
GETBIT命令源码如下所示:
void getbitCommand(client *c)
robj *o;
char llbuf[32];
uint64_t bitoffset;
size_t byte, bit;
size_t bitval = 0;
// 获取offset
if (getBitOffsetFromArgument(c,c->argv[2],&bitoffset,0,0) != C_OK)
return;
// 查找对应的位图对象
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.czero)) == NULL ||
checkType(c,o,OBJ_STRING)) return;
// 计算offset位于位数组的哪一行
byte = bitoffset >> 3;
// 计算offset在一行中的第几位,等同于取模
bit = 7 - (bitoffset & 0x7);
// #define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
if (sdsEncodedObject(o))
// SDS 是RAW 或者 EMBSTR类型
if (byte < sdslen(o->ptr))
// 获取指定位置的值
// 注意它不是真正的一个二维数组不能用((uint8_t*)o->ptr)[byte][bit]去获取呀~
bitval = ((uint8_t*)o->ptr)[byte] & (1 << bit);
else
// SDS 是 REDIS_ENCODING_INT 类型的整数,先转为String
if (byte < (size_t)ll2string(llbuf,sizeof(llbuf),(long)o->ptr))
bitval = llbuf[byte] & (1 << bit);
addReply(c, bitval ? shared.cone : shared.czero);
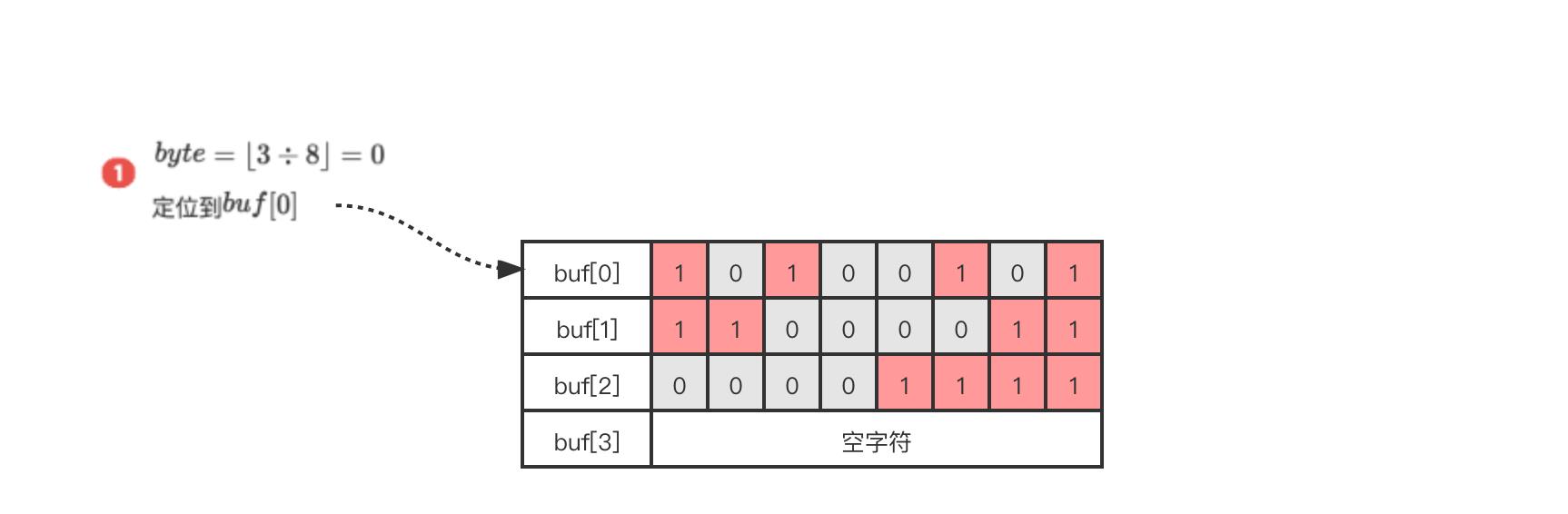
举个栗子🌰
以GETBIT array 3为例,array表示上图中三个字节的位数组。
1. $byte = \\lfloor 3 \\div8 \\rfloor$ 得到值为0,说明在 $buf[0]$ 上
2. $bit = (3\\ mod\\ 8 ) + 1$得到值为4
3. 定位到 $buf[0]$ 字节的从左至右第4个位置上
因为 GETBIT 命令执行的所有操作都可以在常数时间内完成,所以该命令的算法复杂度为O(1)。
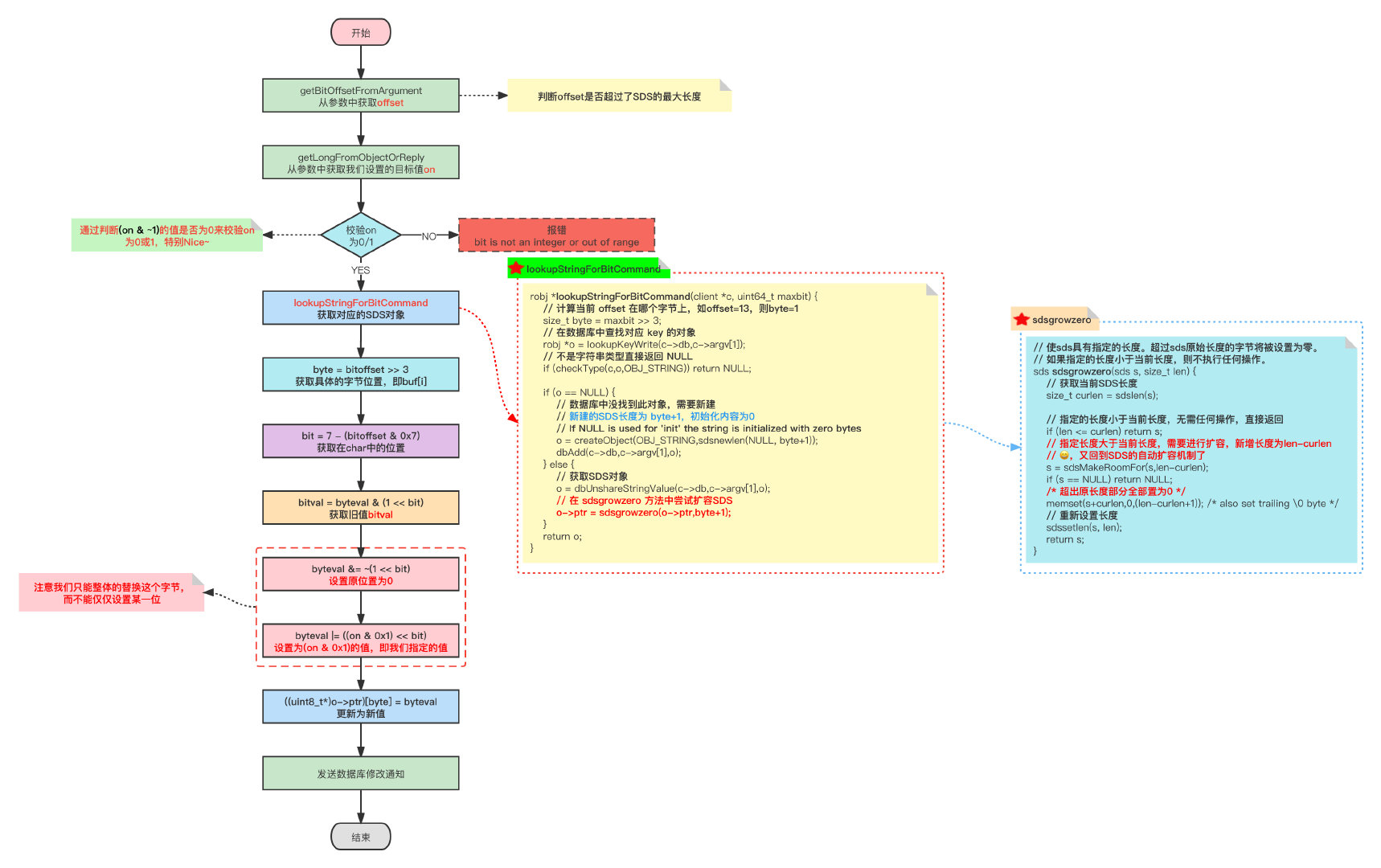
3.3 SETBIT
SETBIT用于将位数组在偏移量的二进制位的值设为value,并向客户端返回旧值。
SITBIT命令的执行过程如下:
- 计算 l e n = ⌊ o f f s e t ÷ 8 ⌋ + 1 len = \\lfloor offset÷8\\rfloor + 1 len=⌊offset÷8⌋+1, l e n len len值记录了保存 o f f s e t offset offset偏移量指定的二进制位至少需要多少字节
- 检查位数组的长度是否小于 l e n len len,如果是的话,将SDS的长度扩展为len字节,并将所有新扩展空间的二进制位设置为0
- 计算 b y t e = ⌊ o f f s e t ÷ 8 ⌋ byte = \\lfloor offset÷8\\rfloor byte=⌊offset÷8⌋, b y t e byte byte值表示指定的 o f f s e t offset offset位于位数组的那个字节(就是计算在那个 b u f [ i ] buf[i] buf[i]中的 i i i)
- 使用 b i t = ( o f f s e t m o d 8 ) + 1 bit = (offset\\ mod\\ 8)+1 bit=(offset mod 8)+1计算可得目标 b u f [ i ] buf[i] buf[i]的具体第几位
- 根据 b y t e byte byte和 b i t bit bit的值,首先保存 o l d V a l u e oldValue oldValue,然后将新值 v a l u e value value设置到目标位上
- 返回旧值
因为SETBIT命令执行的所有操作都可以在常数时间内完成,所以该命令的算法复杂度为O(1)。
SETBIT命令源码如下所示:
void setbitCommand(client *c)
robj *o;
char *err = "bit is not an integer or out of range";
uint64_t bitoffset;
ssize_t byte, bit;
int byteval, bitval;
long on;
// 获取offset
if (getBitOffsetFromArgument(c,c->argv[2],&bitoffset,0,0) != C_OK)
return;
// 获取我们需要设置的值
if (getLongFromObjectOrReply(c,c->argv[3],&on,err) != C_OK)
return;
/* 判断指定值是否为0或1 */
if (on & ~1)
// 设置了0和1之外的值,直接报错
addReplyError(c,err);
return;
// 根据key查询SDS对象(会自动扩容)
if ((o = lookupStringForBitCommand(c,bitoffset)) == NULL) return;
/* 获得当前值 */
byte = bitoffset >> 3;
byteval = ((uint8_t*)o->ptr)[byte];
bit = 7 - (bitoffset & 0x7);
bitval = byteval & (1 << bit);
/* 更新值并返回旧值 */
byteval &= ~(1 << bit);
byteval |= ((on & 0x1) << bit);
((uint8_t*)o->ptr)[byte] = byteval;
// 发送数据修改通知
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"setbit",c->argv[1],c->db->id);
server.dirty++;
addReply(c, bitval ? shared.cone : shared.czero);
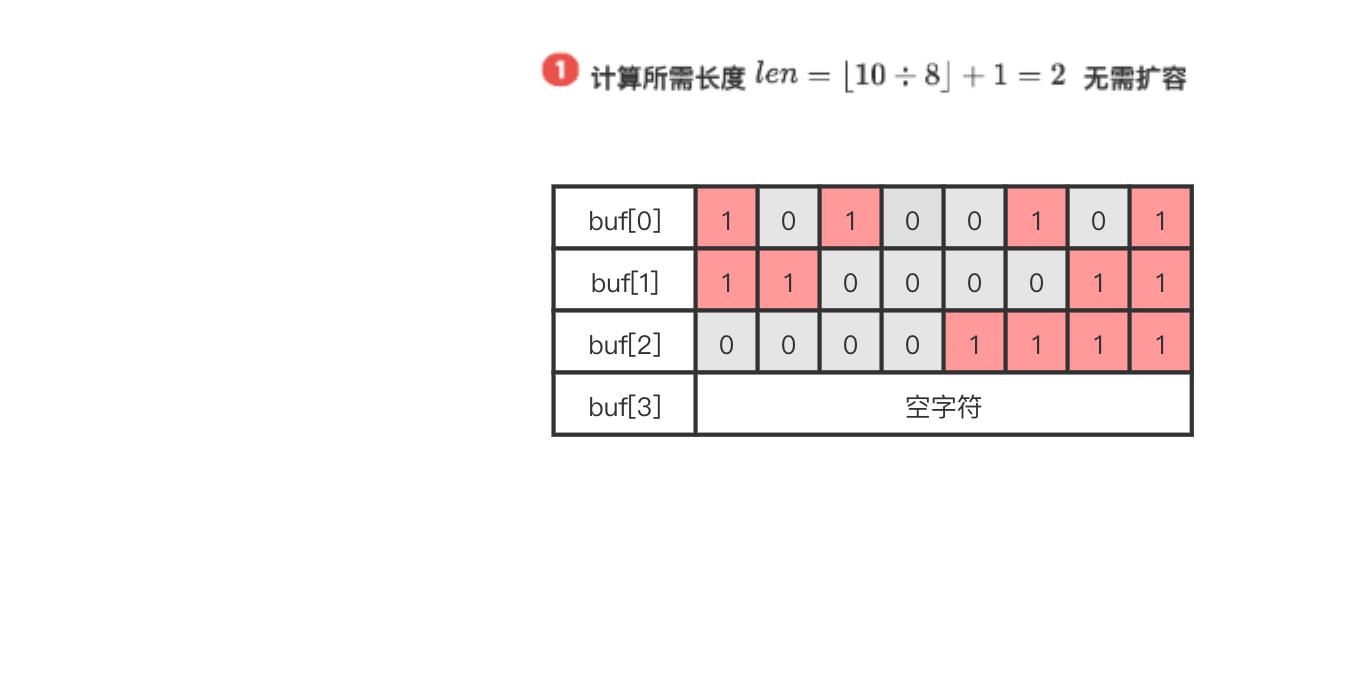
举个栗子1.0🌰
array表示上图中的三个字节位数组。以SETBIT array 10 1为例:
- $ len = \\lfloor10÷8\\rfloor + 1$得到值为2,说明至少需要2字节长的位数组
- 检查是否需要扩容,不需要
- 计算$byte = 1 , 计 算 ,计算 ,计算bit = 3 , 保 存 ,保存 ,保存oldValue$,设置新值
- 返回 o l d V a l u e oldValue oldValue
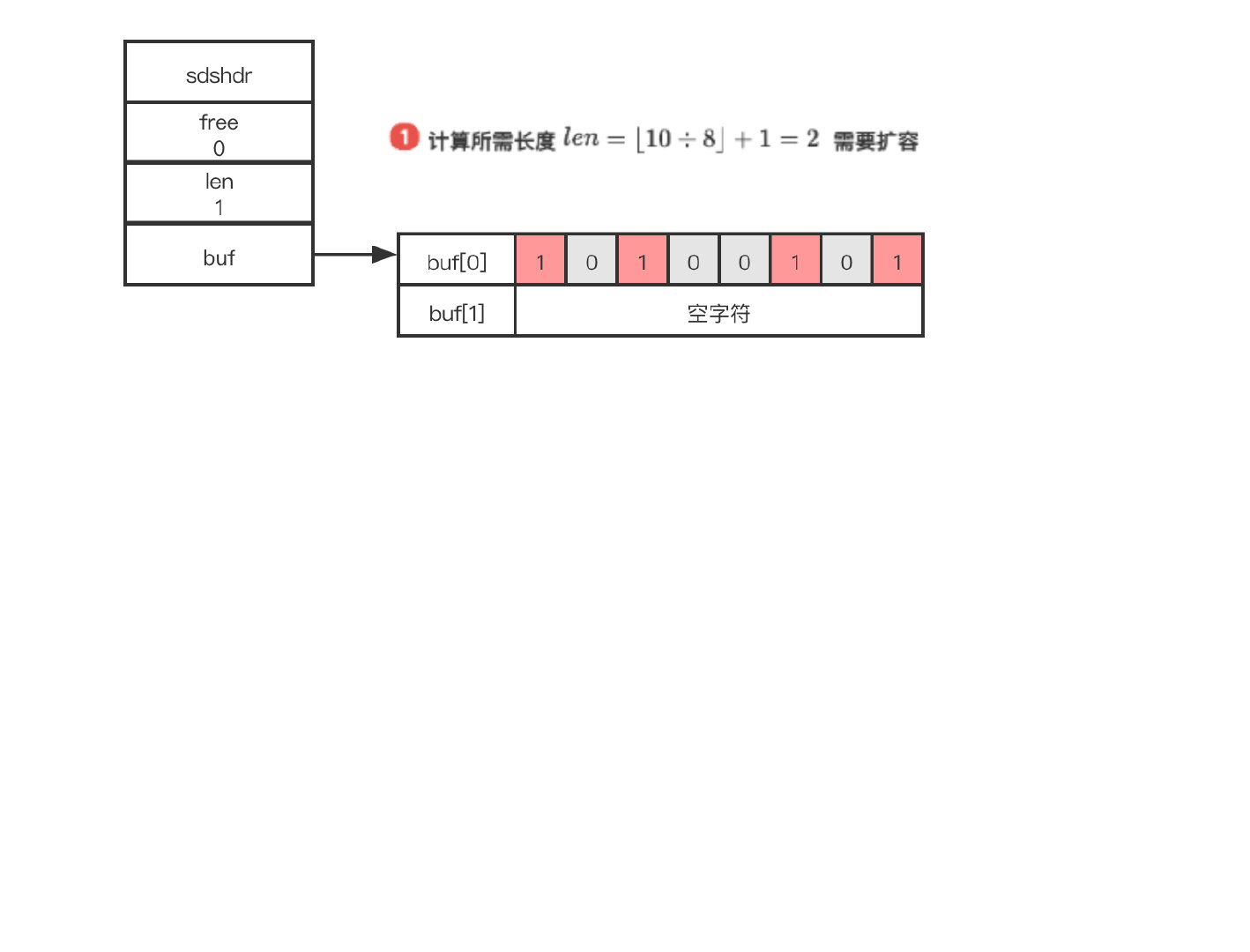
举个栗子2.0🌰
假设目标位数组为1字节长度。执行SETBIT array 12 1,执行如下:
- l e n = ⌊ 12 ÷ 8 ⌋ + 1 len = ⌊12÷8⌋ + 1 len=⌊12÷8⌋+1 得到值为2,说明需要2字节长的 SDS
- 检查是否需要扩容,需要呀!由 SDS 的自动扩容机制可知, SDS 将按新长度的两倍扩容。
- 计算 $byte = 1 $
- 计算 $bit = 5 $
- 保存 o l d V a l u e oldValue oldValue,设置新值
- 返回 o l d V a l u e oldValue oldValue
3.4 BITCOUNT
BITCOUNT命令用于统计给定位数组中值为1的二进制位的数量。功能似乎不复杂,但实际上要高效地实现这个命令并不容易,需要用到一些精巧的算法。
统计一个位数组中非0二进制位的数量在数学上被称为"计算汉明重量"。
3.4.1 暴力遍历
实现BITCOUNT命令最简单直接的方法,就是遍历位数组中的每个二进制位,并在遇到值为1的二进制位时将计数器加1。
小数据量还好,大数据量直接PASS!
3.4.2 查表法
对于一个有限集合来说,集合元素的排列方式是有限的,并且对于一个有限长度的位数组来说,它能表示的二进制位排列也是有限的。根据这个原理,我们可以创建一个表,表的键为某种排列的位数组,而表的值则是相应位数组中值为1的二进制位的数量。
对于8位长的位数组来说,我们可以创建下表,通过这个表格我们可以一次从位数组中读入8位,然后根据这8位的值进行查表,直接知道这个值包含了多少个1。
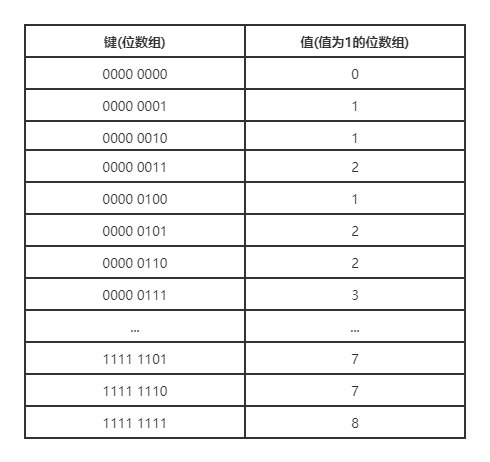
可惜,查表法耗内存呀!
3.4.3 二进制位统计算法:variable-precision SWAR
目前已知效率最好的通用算法为variable-precision SWAR算法,该算法通过一系列位移和位运算操作,可以在常数时间(这就很牛逼了🐂😍)内计算多个字节的汉明重量,并且不需要使用任何额外的内存。
SWAR算法代码如下所示:
uint32_t swar(uint32_t i)
// 5的二进制:0101
i = (i & 0x55555555) + ((i >> 1) & 0x55555555);
// 3的二进制:0011
i = (i & 0x33333333) + ((i >> 2) & 0x33333333);
i = (i & 0x0F0F0F0F) + ((i >> 4) & 0x0F0F0F0F);
i = (i*(0x01010101) >> 24);
return i;
i = i - ((i >> 1) & 0x55555555);
i = (i & 0x33333333) + ((i >> 2) & 0x33333333);
return (((i + (i >> 4)) & 0x0F0F0F0F) * 0x01010101) >> 24;
是不是看不懂,这啥啥啥!

下面描述一下这几步都干了啥:
- 步骤一计算出的值i的二进制表示可以按每两个二进制位为一组进行分组,各组的十进制表示就是该组的1的数量;
- 步骤二计算出的值i的二进制表示可以按每四个二进制位为一组进行分组,各组的十进制表示就是该组的1的数量;
- 步骤三计算出的值i的二进制表示可以按每八个二进制位为一组进行分组,各组的十进制表示就是该组的1的数量;
- 步骤四的
i*0x01010101语句计算出bitarray中1的数量并记录在二进制位的最高八位,而>>24语句则通过右移运算,将bitarray的汉明重量移动到最低八位,得出的结果就是bitarray的汉明重量。
举个栗子🌰
对于调用swar(0xFBB4080B),步骤一将计算出值0xA6640406,这个值表的每两个二进制位的十进制表示记录了0xFBB4080B每两个二进制位的汉明重量。
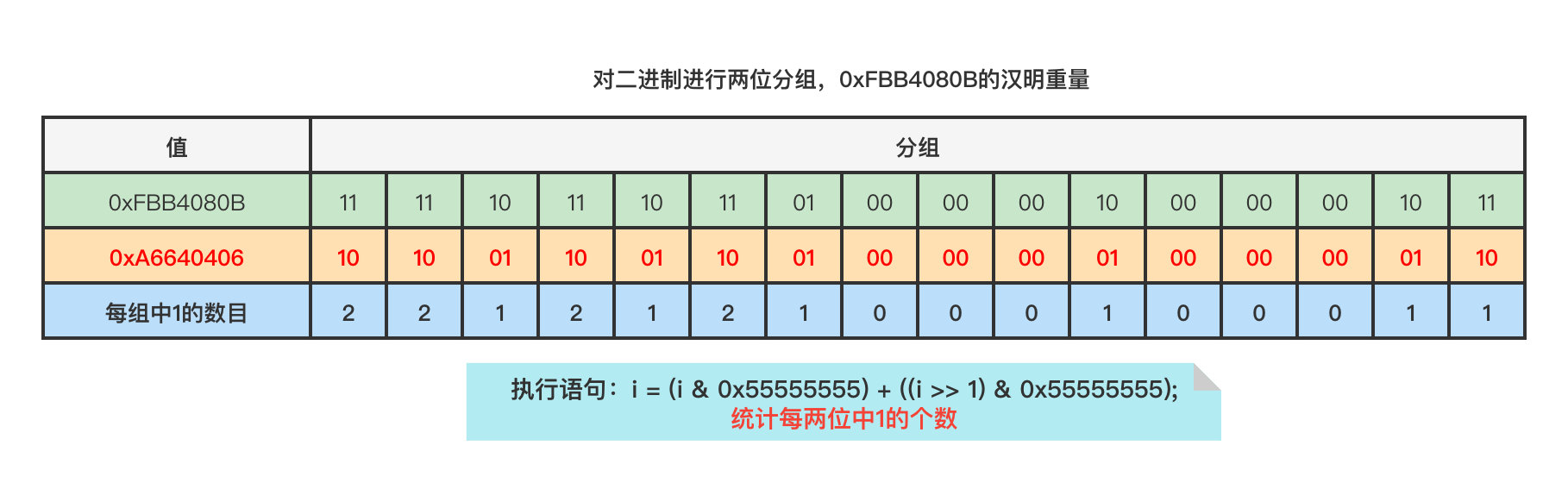
步骤二将计算出值0x43310103,这个值表的每四个二进制位的十进制表示记录了0xFBB4080B每四个二进制位的汉明重量。
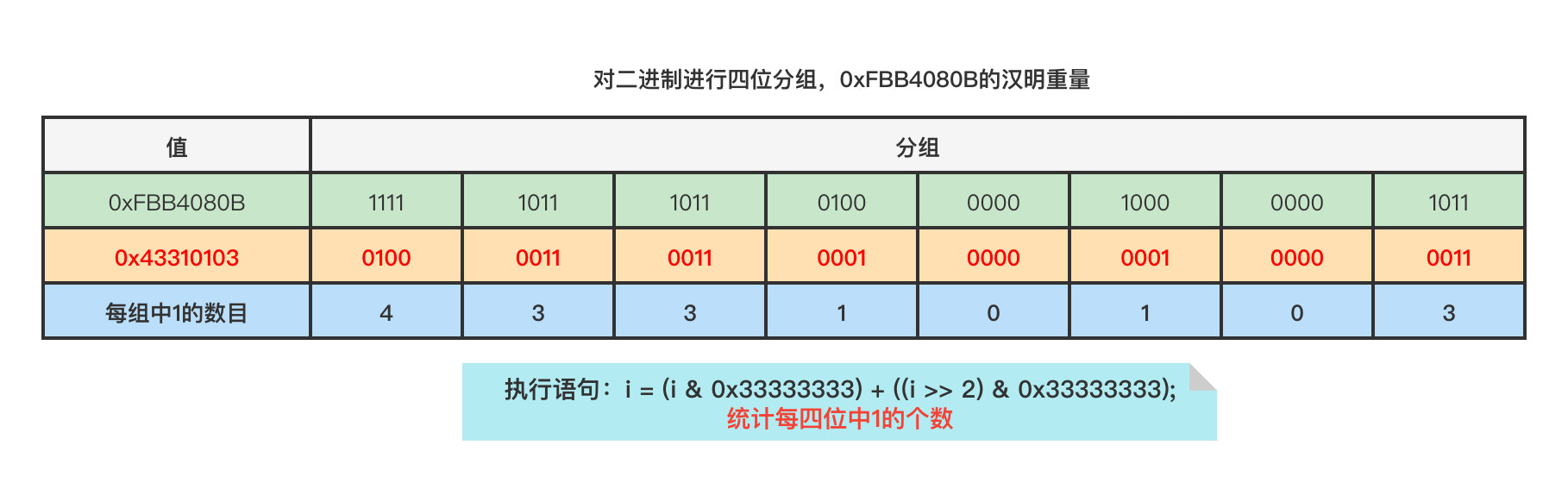
步骤三将计算出值0x7040103,这个值表的每八个二进制位的十进制表示记录了0xFBB4080B每八个二进制位的汉明重量。
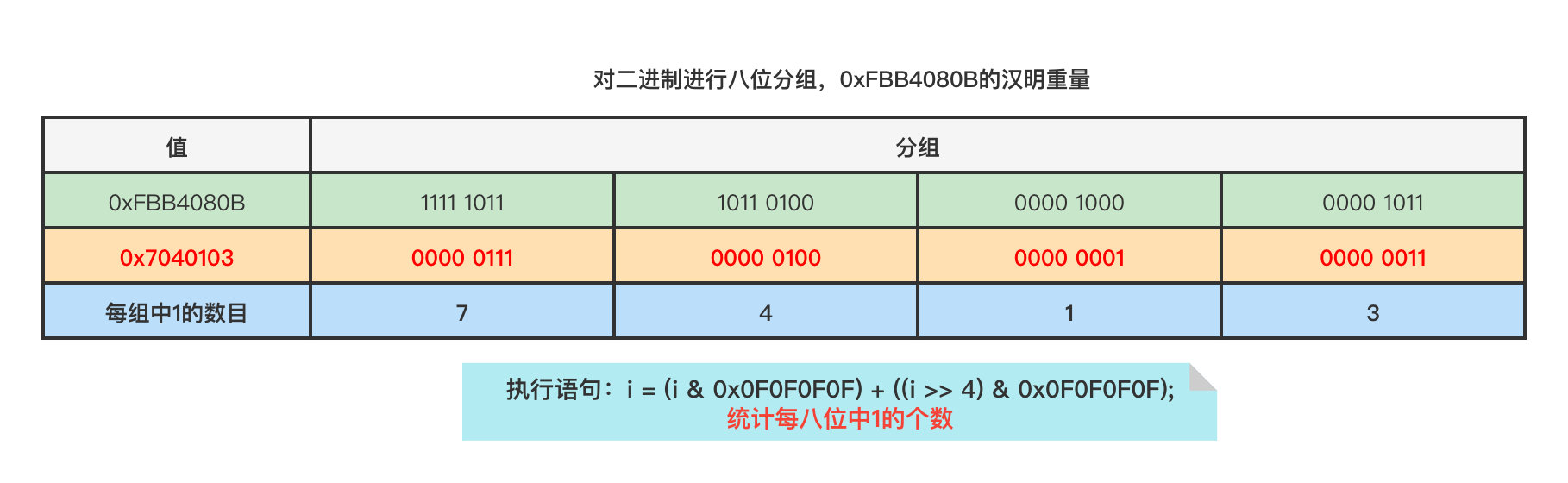
步骤四首先计算0x7040103 * 0x01010101 = 0xF080403,将汉明重量聚集到二进制位的最高八位。
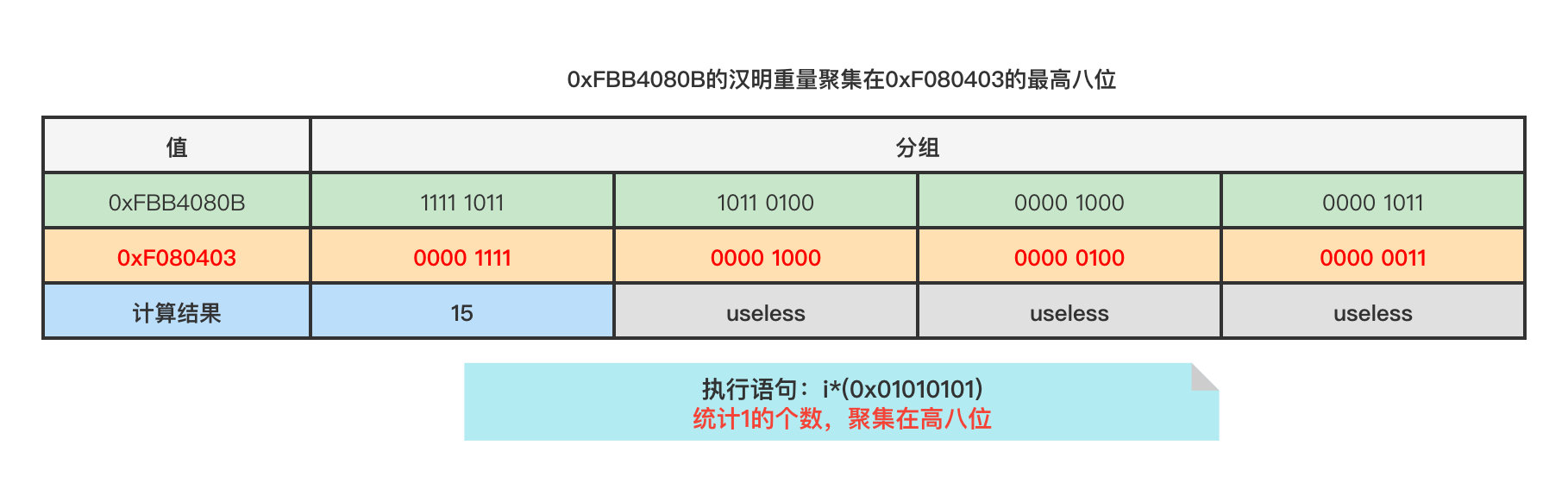
之后计算0xF080403 >> 24,将汉明重量移动到低八位,得到最终值0x1111,即十进制15。
如果您是Java程序员,可以去看看Integer.bitCount方法,也是基于SWAR算法的思想哦!
大家也可以看看StackFlow上大神对它的讲解:[How does this algorithm to count the number of set bits in a 32-bit integer work?](https://stackoverflow.com/questions/22081738/how-does-this-algorithm-to-count-the-number-of-set-bits-in-a-32-bit-integer-work)

3.4.4 源码分析
Redis 中通过调用redisPopcount方法统计汉明重量,源码如下所示:
long long redisPopcount(void *s, long count)
long long bits = 0;
unsigned char *p = s;
uint32_t *p4;
// 为查表法准备的表
static const unsigned char bitsinbyte[256] = 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,4,5,5,6,5,6,6,7,5,6,6,7,6,7,7,8;
// CPU一次性读取8个字节,如果4字节跨了两个8字节,需要读取两次才行
// 所以考虑4字节对齐,只需读取一次就可以读取完毕
while((unsigned long)p & 3 && count)
bits += bitsinbyte[*p++];
count--;
// 一次性处理28字节,单独看一个aux就容易理解了,其实就是SWAR算法
// uint32_t:4字节
p4 = (uint32_t*)p;
while(count>=28)
uint32_t aux1, aux2, aux3, aux4, aux5, aux6, aux7;
aux1 = *p4++;// 一次性读取4字节
aux2 = *p4++;
aux3 = *p4++;
aux4 = *p4++;
aux5 = *p4++;
aux6 = *p4++;
aux7 = *p4++;
count -= 28;// 共处理了4*7=28个字节,所以count需要减去28
aux1 = aux1 - ((aux1 >> 1) & 0x55555555);
aux1 = (aux1 & 0x33333333) + ((aux1 >> 2) & 0x33333333);
aux2 = aux2 - ((aux2 >> 1) & 0x55555555);
aux2 = (aux2 & 0x33333333) + ((aux2 >> 2) & 0x33333333);
aux3 = aux3 - ((aux3 >> 1) & 0x55555555);
aux3 = (aux3 & 0x33333333) + ((aux3 >> 2) & 0x33333333);
aux4 = aux4 - ((aux4 >> 1) & 0x55555555);
aux4 = (aux4 & 0x33333333) + ((aux4 >> 2) & 0x33333333);
aux5 = aux5 - ((aux5 >> 1) & 0x55555555);
aux5 = (aux5 & 0x33333333) + ((aux5 >> 2) & 0x33333333);
aux6 = aux6 - ((aux6 >> 1) & 0x55555555);
aux6 = (aux6 & 0x33333333) + ((aux6 >> 2) & 0x33333333);
aux7 = aux7 - ((aux7 >> 1) & 0x55555555);
aux7 = (aux7 & 0x33333333) + ((aux7 >> 2) & 0x33333333);
bits += ((((aux1 + (aux1 >> 4)) & 0x0F0F0F0F) +
((aux2 + (aux2 >> 4)) & 0x0F0F0F0F) +
((aux3 + (aux3 >> 4)) & 0x0F0F0F0F) +
((aux4 + (aux4 >> 4)) & 0x0F0F0F0F) +
((aux5 + (aux5 >> 4)) & 0x0F0F0F0F) +
((aux6 + (aux6 >> 4)) & 0x0F0F0F0F) +
((aux7 + (aux7 >> 4)) & 0x0F0F0F0F))* 0x01010101) >> 24;
/* 剩余的不足28字节,使用查表法统计 */
p = (unsigned char*)p4;
while(count--) bits += bitsinbyte[*p++];
return bits;
不难发现 Redis 中同时运用了查表法和SWAR算法完成BITCOUNT功能。
4.面试题:40亿QQ号去重

据说这是腾讯三面的面试题,回答出来了就可以拿OFFER了😄~
如果没有1GB的内存限制,我们可以使用排序和Set完成这个算法:
- 排序:① 首先将40亿个QQ号进行排序;② 从小到大遍历,跳过重复元素只取第一个元素。
- Set:将40亿个QQ号统统放进Set集合中,自动完成去重,Perfect🐂
这样回答是要GG的节奏呀!
对40亿个QQ号进行排序需要多少时间?这个存储了40亿QQ号的数组容量已经超过1GB了,同理Set集合存储这么多的QQ号也导致内存超限了。
BitMap去重
**这不巧了么~我们可以使用刚刚学的BITMAP来去重呀!**一个字节可以记录8个数是否存在(类似于计数排序),将QQ号对应的offset的值设置为1表示此数存在,遍历完40亿个QQ号后直接统计BITMAP上值为1的offset即可完成QQ号的去重。
如果是对40亿个QQ号进行排序也是可以用位图完成的哦~一样的思想🐂
5.位图实战
既然我们深入了解了BITMAP,那不进行个实战项目可说不过去呀!
我们使用
BITMAP实现GITHUB中统计每天提交次数的这个小功能,基于SpringBoot+Echarts实现😄
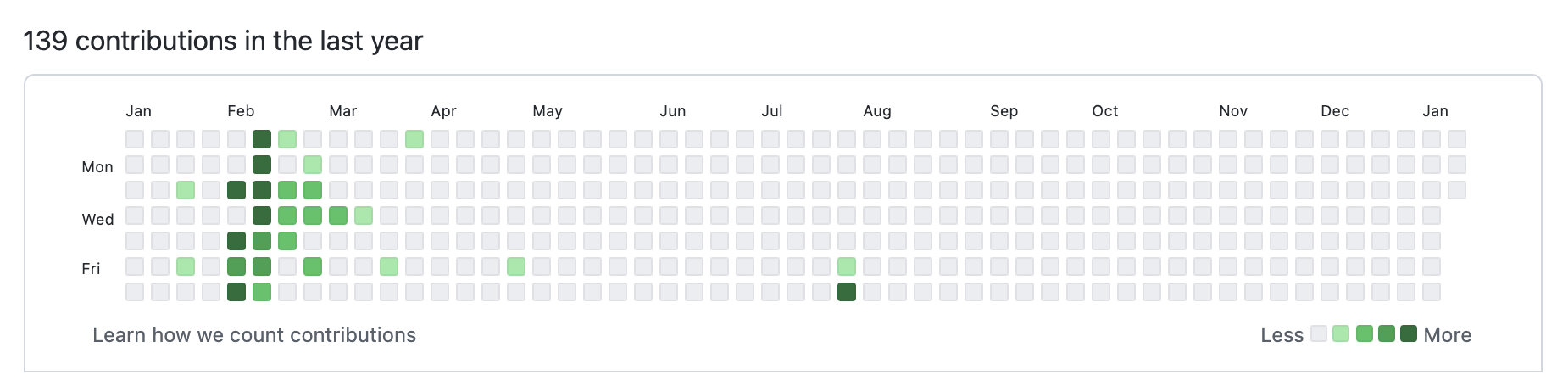
如果是记录登录状态我们可以很方便的使用0和1记录,如果是记录提交次数就显得BITMAP无用了,没关系,我们可以使用一个字节来记录提交次数,只是在业务上需要处理好十进制和二进制直接的转换而已。
生成模拟数据
public void genTestData()
if(redisUtils.isExist(CommonConstant.KEY))
return;
// 获取当前年的总天数
int days = getDays();
for (int i = 0; i < days; i++)
int random = ThreadLocalRandom.current().nextInt(64);
// 生成随机数表示每天的PR次数
String binaryString = Integer.toBinaryString(random);
if (binaryString.length() < 8)
// 填充0
if(binaryString.length() == 0)binaryString = "00000000";
else if(binaryString.length() == 1)binaryString = "0000000"+binaryString;
else if(binaryString.length() == 2)binaryString = "000000"+binaryString;
else if(binaryString.length() == 3)binaryString = "00000"+binaryString;
else if(binaryString.length() == 4)binaryString = "0000"+binaryString;
else if(binaryString.length() == 5)binaryString = "000"+binaryString;
else if(binaryString.length() == 6)binaryString = "00"+binaryString;
else if(binaryString.length() == 7)binaryString = "0"+binaryString;
char[] chars = binaryString.toCharArray();
for (int j = 0; j < chars.length; j++)
// 设置BitMap
redisUtils.setBit(CommonConstant.KEY,i*8+j,chars[j]);
/**
* 获取当前年的总天数
* @return days 总天数
*/
private int getDays()
Calendar calOne = Calendar.getInstance();
int year = calOne.get(Calendar.YEAR);
System.out.println(year);
Calendar calTwo = new GregorianCalendar(year, 11, 31);
return calTwo.get(Calendar.DAY_OF_YEAR);
获取数据
public List<String> getPushData()
List<String> res = new ArrayList<>(366);
// 没有数据就先造数据
genTestData();
int days = getDays();
for(long i=0;i<days;i++)
StringBuilder sb = new StringBuilder();
for (int j = 0; j < 8; j++)
String bit = redisUtils.getBit(CommonConstant.KEY, i * 8 + j);
sb.append(bit);
// 直接返回二进制串,前端转换为十进制
res.add(sb.toString());
return res;
这里敖丙觉得可以直接将所有的bit统统返回,在前端进行分割处理
前端渲染
<script type="text/javascript">
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
function getVirtulData(year)
var date = +echarts.number.parseDate(year + '-01-01');
var end = +echarts.number.parseDate(+year + 1 + '-01以上是关于Bitmap使用详解的主要内容,如果未能解决你的问题,请参考以下文章