ELKB项目总结(基于ELKB-6.5.0版本)
Posted 兜里有糖心里不慌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELKB项目总结(基于ELKB-6.5.0版本)相关的知识,希望对你有一定的参考价值。

FileBeat的原理框架:
FileBeat主要由两个核心组件input和harvesters组成。
- Input用来管理Harvesters,对于配置文件中的每一个输入源都启动一个Go协程和一个Harvesters
- Harvesters对于配置文件中每一个需要监听的文件进行读取,同时会维持一个当前文件的state并定期保存到磁盘文件中,state是用来标记最后一次读取文件的偏移量
- FileBeat采用发送-确认的方式来保证文件传输的完整性,采用背压机制来保证传输和接收速率的一致
Logstash的原理框架:

开源的服务器端数据处理管道,可同时从多个来源采集、转换数据。
Elasticsearch的原理框架:
1) 搭建流程:
- 配置运行的JVM环境
- 配置初始和最大的堆内存Xms,Xmx
- 配置日志文件
- 配置日志记录等级等参数
- 配置elastic的配置文件
- Cluster(集群名称),对于同一集群中的ES需要相同的名称才能自动加入集群
- ES数据、日志存储路径:一般都放在/var/log/elasticsearch
- node.data, node.master, 设置当前节点的角色:master,data,coordinating
- 当前ES节点IP地址,使用端口:http.port,http.port
- 配置ES集群的IP地址,该选项可以是固定写死的地址列表,也可以是某一网段,也可以指定IP地址的文件
- 配置最小master节点discovery.zen.minimum_master_nodes,该配置是整个ES集群中最重要的配置项,推荐配置数为:(有选举能力的节点总数/2+1)Prevent the “split brain” by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1)
- xpack.security为ES的安全插件,在以127.0.0.1的本地IP调试时默认关闭,当设置为内网IP时默认自动开启
| node.master | node.data | 角色及功能 |
|---|---|---|
| true | false | 管理节点,主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。 |
| false | true | 数据节点,保存数据分片,负责数据分片的CRUD,搜索整合操作,负载较大 |
| false | false | 协调节点,该节点和检索应用创建连接、接受检索请求,但其本身不负责存储数据,可当负责均衡节点 |
- 配置系统环境
- 修改 /etc/profile:
增加ulimit -n 65535 - 修改 /etc/security/limits.conf, 增加:
soft nofile 65536 hard nofile 65536
- 修改 /etc/profile:
2)ES原理:
架构
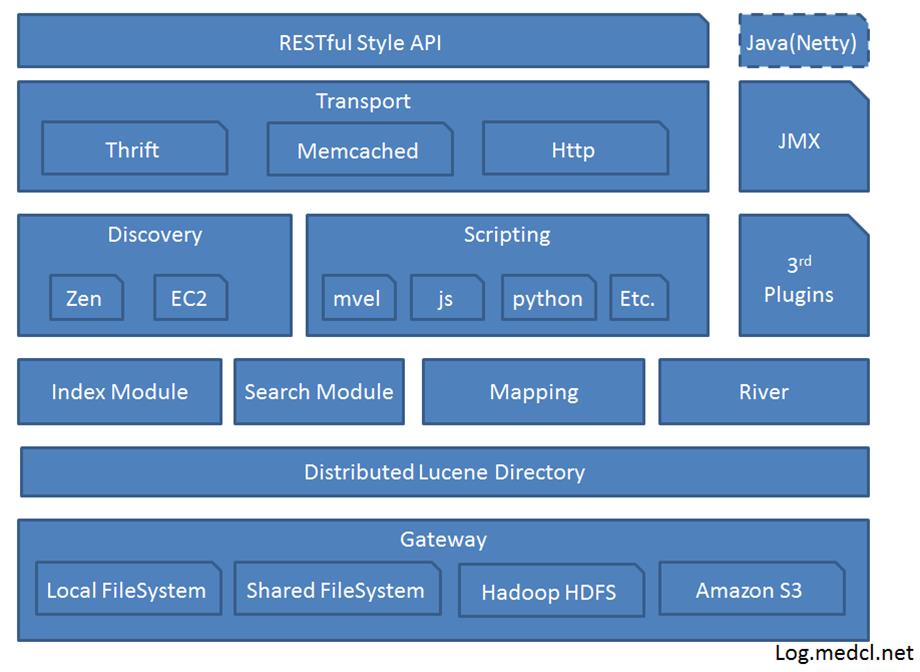
-
Gateway是ES用来存储索引的文件系统,支持多种类型
-
Gateway的上层是一个分布式的lucene框架
-
Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
-
ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure,ES默认使用Zen
-
Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。 ES也支持多种第三方插件
-
再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用
-
最上层是ES提供给用户的接口,可以通过RESTful接口或java api和ES集群进行交互
搜索
ES的搜索基于Lucene,Lucene是一个Apache旗下的全文检索引擎
ES搜索的过程(默认Query Then Fetch方式):
- 先向所有的shard发出查询请求,个分片只返回排序和排名相关信息,不包含实际文档;
- 按照各分片返回的数据进行重新排序和排名,取前size个排名数据
- 去相关的shard取出size个文档
Master选举

- 节点启动后先ping(这里的ping是 Elasticsearch 的一个RPC命令。如果 discovery.zen.ping.unicast.hosts 有设置,则ping设置中的host,否则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点)Ping的response会包含该节点的基本信息以及该节点认为的master节点。
- 选举开始,先从各节点认为的master中选,规则很简单,按照id的字典序排序,取第一个
- 如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举
- 最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己
- 如果当前节点是master,则开始等待节点数达到 minimum_master_nodes(最小候选节点数),然后提供服务
- 如果当前节点不是master,则尝试加入master
以上是关于ELKB项目总结(基于ELKB-6.5.0版本)的主要内容,如果未能解决你的问题,请参考以下文章