用户画像用户画像简介用户画像的架构搭建用户画像管理平台
Posted OneTenTwo76
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用户画像用户画像简介用户画像的架构搭建用户画像管理平台相关的知识,希望对你有一定的参考价值。
文章目录
一 用户画像简介
1 用户画像
数据仓库是大数据体系的基石,用户画像是建立在数仓之上的一种应用,类似的应用还有商业智能,推荐系统等。
用户画像,英文: User Profile,( 也有少数称: User Portrait 或User Persona)。
一句话概念就是将用户信息标签化(Tag或者Label),以用户为中心,将各种各样的标签对应到其身上,一般表现为《人 – 标签 – 标签值》。

通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌。
2 定位
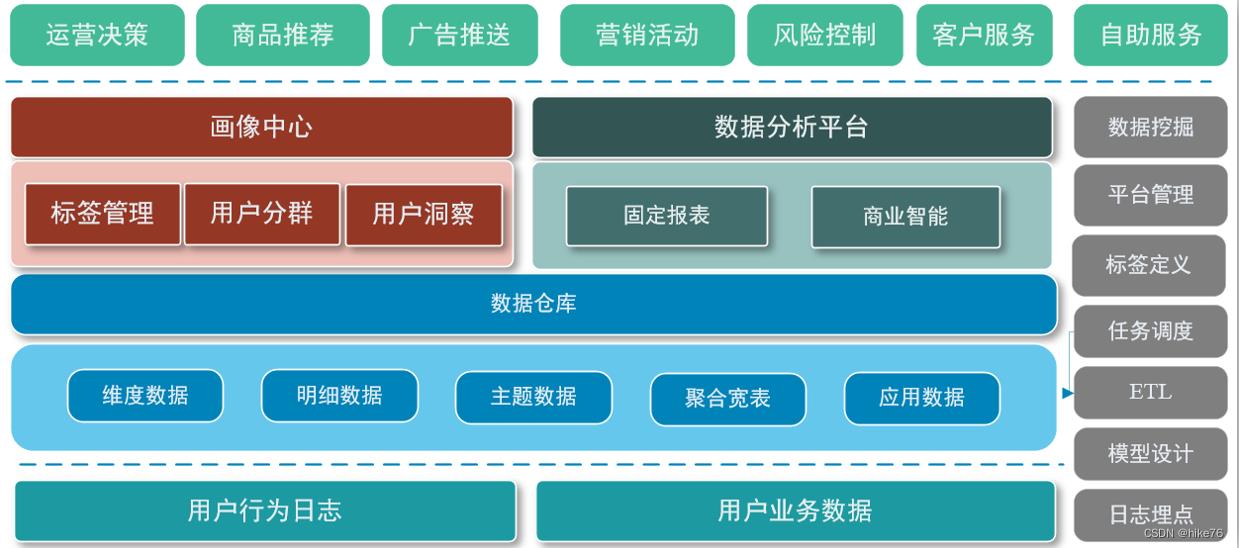
相对于数据仓库而言,用户画像属于“上层建筑”,以数据仓库沉淀的数据为基础,提炼出更有价值的信息。
同时用户画像也是一种数据服务,在它之上还有“更高的建筑”,比如推荐系统,营销系统、风控系统、用于广告投放的DMP系统等等。这些系统往往需要对用户进行识别定位,那么用户画像就是最重要的数据来源。
画像中心的数据全部来源于数仓,但是其又不能直接使用数仓,所以需要按照画像的标准,以用户为单位,将数据再次进行提炼、加工组合,形成以用户标签为中心的数据。
2 应用
画像数据的主要应用类型:
- 运营决策:了解用户群体,聚焦目标用户,定位产品方向。
- 精准营销:营销活动推送、广告投放、个性化推荐。
- 用户分群:寻找高价值用户,挽留待流失用户,提升用户活跃。
3 用户标签
(1)标签分级
不同公司分级不同,最常见的为以下四级标签,又可以分为三种:
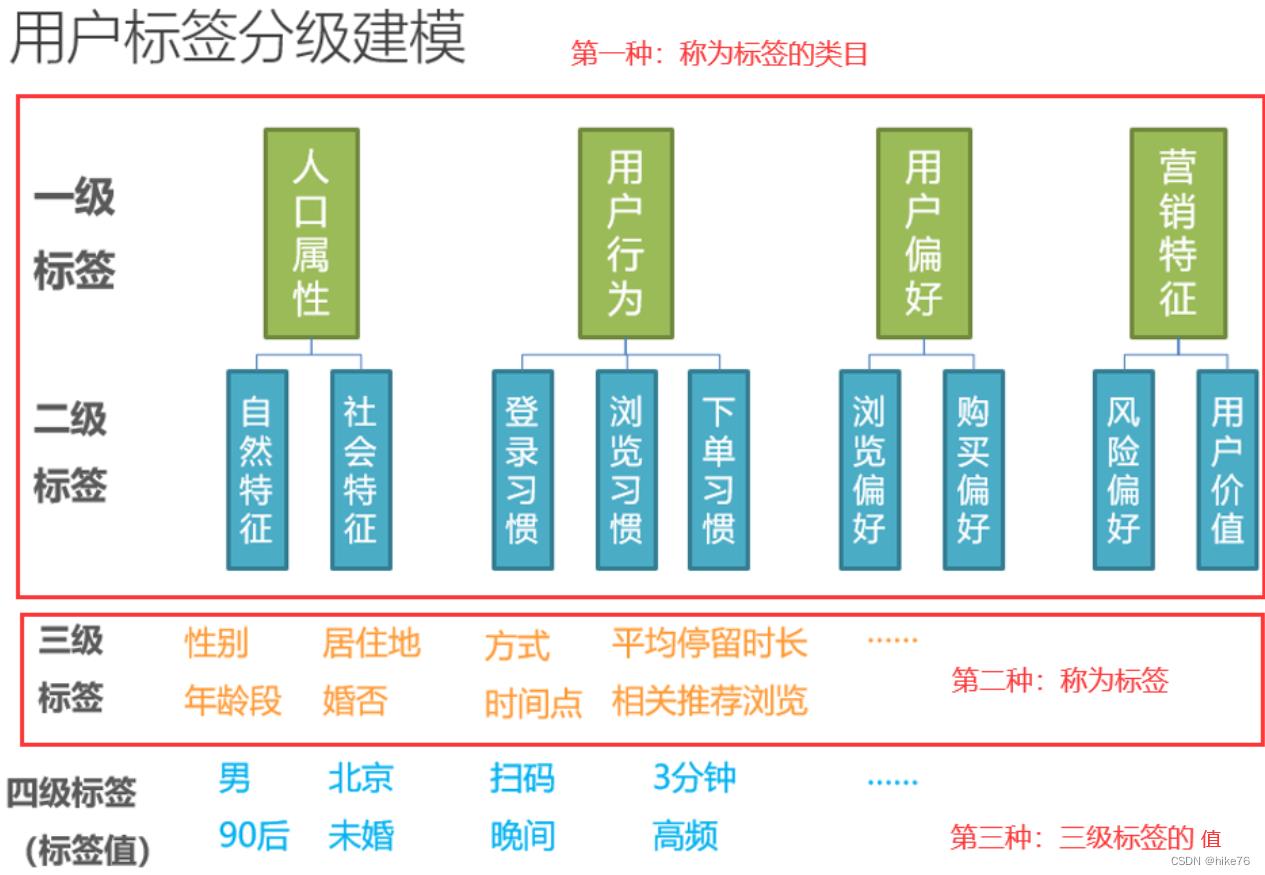
有的公司分为5级标签或者6级标签,不同在类目,5/6级标签的类目更加详细。
少数公司不分级,第一种称为标签的分类,第二种称为标签,第三种称为值
(2)标签分类
各个公司的标签分类都大差不差,分为以下三类:
-
统计类标签
统计类标签的规则放之四海皆准,每个公司的定义都差不多,如性别指的就是人的性别,不会有歧义,偏客观。
直接提取的标签,又叫事实标签。
比如:性别,年龄,最近一次登录时间,月均消费。
有非常通用且明确的定义,是最为常见的标签。
-
规则类标签
规则类标签与统计类标签不同在于概念上的差别,技术上差不多,往往各个公司的业务人员根据公司的需求灵活定义,偏主观。
从程序员角度来说,统计类标签与规则类标签没有本质差别。
需要自定义规则。
比如:高价值用户、意见领袖、电子产品爱好者、黄牛党。
需要运营、产品、业务人员,根据企业自身的业务特征,设计适合自身的规则定义。往往同一个名称的标签,在不同企业的规则不同。
-
挖掘类标签
挖掘类标签是企业做用户画像的分水岭,通常来说,这个标签不是由人来制定规则,因为有些规则没有办法通过人类语言描述清楚,或者人类语言描述的不准确,尤其是预测相关的规则,规则随着时间的变化也在不停的变化。
一般通过机器学习算法进行预测的标签。又叫预测类标签。
比如:预测性别、预测年龄、潜在流失用户。
通常是很难根据某一个规则得到的标签。需要机器学习通过系统现有的数据,反复迭代获得一个模型算法,再根据算法得到标签。
开发周期长,难度大,准确度不能保证。但是往往也是最有价值的标签,因为从数据得到的数据,有时往往比定死的规则更反映真实情况。
二 用户画像的架构
用户画像架构如图:
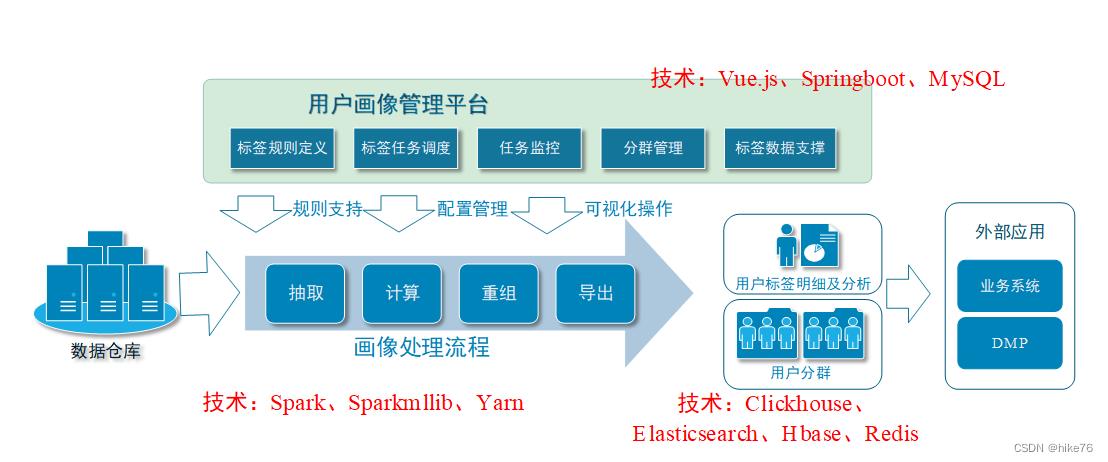
1 画像处理流程
画像处理流程主要是根据标签及整个流程的规则计算标签,把数据仓库中的数据进行重组。
一般统计类和规则类标签使用spark-sql即可,复杂的规则类标签和挖掘类标签可以使用spark-core和spark-mllib完成。
是一个标准的ETL(清洗、转移、提取)流程,将数仓中的数据提取为以用户和标签为结构的数据,流程类似于数仓中的由ODS – DWD – DWS – DWT – ADS 逐层计算的过程,与数仓不同的是,画像处理中不全是SQL,并且不只是用一个数据库。
一般这个流程使用shell + 定时调度(Azkaban)就可以完成。
数仓计算的最终结果如果数据量小一般存放在mysql中,数据量大一般存放在Kylin,Presto,HBase等容器中。
2 画像标签数据应用
用户画像最终的计算结果一般存放在ClickHouse中,目的主要有两个。
- 用户标签明细及分析:以用户的维度对数据进行统计分析。
- 用户分群:是画像最核心的需求,使用各种标签,通过标签的筛选,快速定位到目标群体,通过在数据库中编写配置文件可以完成。
画像提供了分群操作所以要操作支持即席查询的OLAP,对标签及人群进行操作。
根据实际需要一般选择性能较好,支持即席查询的OLAP数据库。用于组合和多个条件来筛选用户,比如Clickhouse或者Elasticsearch。同时也会使用K-V数据库用于精确查询用户和人群,比如Redis、Hbase 、Pika。
以上1 2 两个过程除用户标签明细及分析,其余过程均可以实现无界面化。
3 用户画像管理平台
在画像管理平台提供可视化页面,对标签及标签产生的规则进行定义,甚至直接提供可视化开发页面。
提供后台调度系统,根据标签定义的规则,从数仓中抽取计算。
计算后的用户画像标签也由平台管理,通过标签的组合,把用户分成不同的群体。为其他业务系统提供支持。
技术实现:
用户画像系统本质上是一个内部的管理系统,方便用户画像开发团队,搭建标签管理任务的。基于标准的Web应用的技术。
- Vue.js:负责前端页面。
- Springboot :负责后台应用,数据保存在Mysql数据库中,相关的技术框架还包括MybatisPlus、StringTask。因为还需要把spark程序任务提交到Yarn,所以还用到SparkLauncher插件。
各个模块任务:
-
标签规则定义:计算哪些标签,标签任务的定义。
-
标签任务调度:标签何时执行,如计算性别,机器学习的预测。
-
任务监控:调度配置好后,到达运行条件,可以对任务进行观察,哪些标签计算成功哪些计算失败。
-
分群管理:标签全部运行成功之后,可以对标签进行筛选,分组管理,需要提供一个界面,这个界面可以供数据分析、营销等人员进行使用。对人群的定义,称为人群包。分群又称人圈(人群圈选)。
画像处理流程都是批处理(夜里计算),人圈则一般是即时产生的(白天计算),即筛选完几个条件,当场把目标群体圈出来,要求及时性更强。
-
标签数据支撑:标签数据计算完成之后,供其他部门查询这些标签,做一些数据支持或者是接口。
三 搭建用户画像管理平台
1 一些问题
-
导入代码之后,初始化完成之后,project一栏只出现pom.xml 和 external libraries原因是idea没有将项目识别为一个Maven工程或SpringBoot工程,解决办法点击file – new – Module from Existing Sources… 重新选择该项目,一路next。
-
如果src – main – java 不是蓝色目录,说明idea没有找到对应的源码目录,需要手动设置,在java上右键 – Mark Directory as – Source Root。
-
搭建平台时,代码中可能会有getter、setter方法飘红,不影响运行,修复飘红方法,Settings – Plugins – 搜索栏搜索lombok – 安装 – 重启idea。lombok能在编译时给实体Bean自动生成getter、setter方法。
-
忘记MySQL密码
# 1.修改配置文件 my.ini,在配置文件 [mysqld] 下添加 skip-grant-tables,重启MySQL服务即可免密码登录 # 其中 --skip-grant-tables 选项的意思是启动 MySQL 服务的时候跳过权限表认证。 启动后,连接到 MySQL 的 root 将不需要口令(危险)。 # 用空密码的 root 用户连接到 MySQL,并且更改 root 口令 # 免密码登录MySQL数据库: mysql -u root # 重置密码: use mysql; update user set password=password('你的密码') where user='root'; # 3.到 my.ini 中删除 skip-grant-tables 选项,然后重启MySQL服务。
2 启动服务
(1)数据库建表脚本
创建数据库 – utf8 – utf8_general_ci
建表语句
/*
SQLyog
MySQL - 5.7.16 : Database - user_profile_manager
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
/*Table structure for table `file_info` */
CREATE TABLE `file_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`file_name` varchar(200) DEFAULT NULL COMMENT '文件名',
`file_ex_name` varchar(20) DEFAULT NULL COMMENT '扩展名',
`file_path` varchar(200) DEFAULT NULL COMMENT '文件路径',
`file_system` varchar(20) DEFAULT NULL COMMENT '文件系统',
`file_status` bigint(20) DEFAULT NULL COMMENT '文件状态 1 正常 2 弃用',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `tag_common_task` */
CREATE TABLE `tag_common_task` (
`id` bigint(20) NOT NULL,
`task_file_id` bigint(20) DEFAULT NULL,
`main_class` varchar(200) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `tag_info` */
CREATE TABLE `tag_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`tag_code` varchar(200) DEFAULT NULL,
`tag_name` varchar(200) DEFAULT NULL,
`tag_level` bigint(20) DEFAULT NULL,
`parent_tag_id` bigint(20) DEFAULT NULL,
`tag_type` varchar(20) DEFAULT NULL,
`tag_value_type` varchar(20) DEFAULT NULL COMMENT '1 整数 2 浮点 3 文本 4 日期',
`tag_value_limit` decimal(16,2) DEFAULT NULL COMMENT '数值预估上限 数字型填写',
`tag_value_step` bigint(20) DEFAULT NULL COMMENT '1,10,100,1000',
`tag_task_id` bigint(20) DEFAULT NULL,
`tag_comment` varchar(2000) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_tag_level_id` (`tag_level`,`id`)
) ENGINE=InnoDB ;
/*Table structure for table `task_info` */
CREATE TABLE `task_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`task_name` varchar(200) DEFAULT NULL COMMENT '任务名称',
`task_status` varchar(20) DEFAULT NULL COMMENT '任务状态',
`task_comment` varchar(2000) DEFAULT NULL COMMENT '任务说明',
`task_time` varchar(10) DEFAULT NULL COMMENT '任务作业时间(小时分)',
`task_type` varchar(20) DEFAULT NULL COMMENT '任务类型(标签,流程)',
`exec_type` varchar(20) DEFAULT NULL COMMENT '执行方式(jar,sparksql)',
`main_class` varchar(200) DEFAULT NULL COMMENT '启动执行的主类',
`file_id` bigint(200) DEFAULT NULL COMMENT '程序jar文件id',
`task_args` varchar(500) DEFAULT NULL COMMENT '启动任务的参数',
`task_sql` varchar(5000) DEFAULT NULL COMMENT '启动的执行的sql',
`task_exec_level` bigint(20) DEFAULT NULL COMMENT '执行层级',
`create_time` date DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_task_time` (`task_time`)
) ENGINE=InnoDB ;
/*Table structure for table `task_process` */
CREATE TABLE `task_process` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`task_id` bigint(20) DEFAULT NULL COMMENT '任务id',
`task_name` varchar(100) DEFAULT NULL COMMENT '任务名称',
`task_exec_time` varchar(10) DEFAULT NULL COMMENT '任务触发时间',
`task_busi_date` varchar(10) DEFAULT NULL COMMENT '任务执行日期',
`task_exec_status` varchar(100) DEFAULT NULL COMMENT '任务阶段 TODO ,START,SUBMITTED,RUNNING,FAILED,FINISHED',
`task_exec_level` bigint(20) DEFAULT NULL COMMENT '任务执行层级',
`yarn_app_id` varchar(100) DEFAULT NULL COMMENT 'yarn的application_id',
`batch_id` varchar(100) DEFAULT NULL COMMENT '批次id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`start_time` datetime DEFAULT NULL COMMENT '启动时间',
`end_time` datetime DEFAULT NULL COMMENT '结束时间(包括完成和失败)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `task_tag_rule` */
CREATE TABLE `task_tag_rule` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`tag_id` bigint(20) DEFAULT NULL COMMENT '标签主键',
`task_id` bigint(20) DEFAULT NULL COMMENT '任务id',
`query_value` varchar(200) DEFAULT NULL COMMENT '查询值',
`sub_tag_id` bigint(20) DEFAULT NULL COMMENT '对应子标签id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `user_group` */
CREATE TABLE `user_group` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_group_name` varchar(200) DEFAULT NULL COMMENT '分群名称',
`condition_json_str` varchar(2000) DEFAULT NULL COMMENT '分群条件(json)',
`condition_comment` varchar(2000) DEFAULT NULL COMMENT '分群条件(描述)',
`user_group_num` bigint(20) DEFAULT NULL COMMENT '分群人数',
`update_type` varchar(20) DEFAULT NULL COMMENT '更新类型(手动,自动按天)',
`user_group_comment` varchar(2000) DEFAULT NULL COMMENT '分群说明',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
(2)配置修改
在idea中修改application.properties配置文件中的mysql相关配置(地址、用户名、密码)
在UserProfileManagerApplication中启动
将hadoop101地址与 userprofile.gmall.com进行映射(C:\\Windows\\System32\\drivers\\etc目录下的host文件中进行修改)
现在就可以在浏览器中进行访问了(输入userprofile.gmall.com 或者 hadoop101地址 )
用户画像
这里不包含算法、技术、架构内容,因为相对来说,用户画像落地比较简单,难的是用户画像的价值落地。
用户画像是一个挺新颖的词,最初它是大数据行业言必及之的时髦概念。现在我们谈及用户画像,它也是和精准营销、精细化运营直接钩挂的。这篇文章主要讲产品运营角度的用户画像。
什么是用户画像
用户画像一点也不神秘,它是根据用户在互联网留下的种种数据,主动或被动地收集,最后加工成一系列的标签。比如猜用户是男是女,哪里人,工资多少,有没有谈恋爱,喜欢什么,准备剁手购物吗?
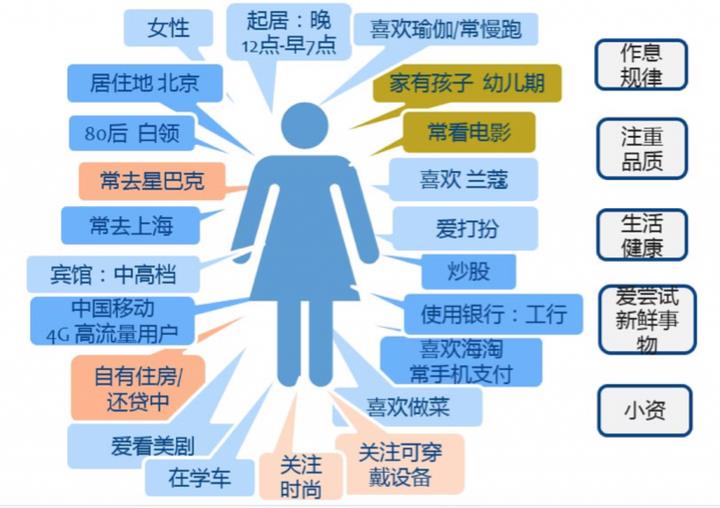
我们常把用户标签和用户画像对等。但凡用户画像的文章,类似上文图片都会出现,有用烂的趋势。标签化是最直观的解释,但它不等于用户画像。
用户画像的正式名称是User Profile,大家往往把它和User Persona混淆,后者更恰当的名字是用户角色。是产品设计和用户调研的一种方式方法。当我们讨论产品、需求、场景、用户体验的时候,往往需要将焦点聚集在某类人群上,用户角色便是一种抽象的方法,是目标用户的集合。
用户角色不指代具体的谁。「她是一位25岁的白领,211大学毕业,现在从事于互联网行业的设计工作,居住在北京。单身,平时喜爱摇滚乐」,这段话语,常用来描述产品的典型用户。
本文谈的User Profile,更多是运营和数据息息相关的平台级应用,本质是对任何一个用户都能用标签和数据描述。
用户画像的应用
它在企业迈大迈强的过程中有举足轻重的作用。以下是主要的应用。
精准营销:这是运营最熟悉的玩法,从粗放式到精细化,将用户群体切割成更细的粒度,辅以短信、推送、邮件、活动等手段,驱以关怀、挽回、激励等策略。
数据应用:用户画像是很多数据产品的基础,诸如耳熟能详的推荐系统广告系统。操作过各大广告投放系统的同学想必都清楚,广告投放基于一系列人口统计相关的标签,性别、年龄、学历、兴趣偏好、手机等等。
用户分析:虽然和Persona不一样,用户画像也是了解用户的必要补充。产品早期,PM们通过用户调研和访谈的形式了解用户。在产品用户量扩大后,调研的效用降低,这时候会辅以用户画像配合研究。新增的用户有什么特征,核心用户的属性是否变化等等。
数据分析:这个就不用多提了,用户画像可以理解为业务层面的数据仓库,各类标签是多维分析的天然要素。数据查询平台会和这些数据打通。
对大部分产品,用户画像用不到推荐系统,个性化推荐也提高不了几个利润,毕竟它需要大量的用户和数据作支撑。所以这些产品,更适合以用户画像为基础去驱动业务。
提了那么多好处,但是据我了解,不少公司,花了一大笔钱招了不少人建设用户画像系统,结果用不起来。或者做了一份用户画像的报告,性别用户地理位置用户消费金额,看上去挺高大上的,看完也就看完了。
归根结底,难以用好。
很多用户画像初衷是好的,但是沦为了形式主义。
举身边的例子,朋友在公司建立用户画像划分了百来个维度。用户消费、属性、行为无所不包。本来这不错啊,但是上线后运营看着这个干瞪眼。
问题包含但不限于,用户有那么多维度,怎么合理地选择标签?我想定义用户的层级,VIP用户应该累积消费金额超过多少?是在什么时间窗口内?为什么选择这几个标准?后续应该怎么维护和监控?业务发生变化了这个标签要不要改?
设立好标签,怎么验证用户画像的有效性?我怎么知道这套系统成功了呢?效果不佳怎么办?它有没有更多的应用场景?
策略的执行也是一个纠结的问题。从岗位的执行看,运营背负着KPI。当月底KPI完不成时,你觉得他们更喜欢选择全量运营,还是精细化呢?
我想不少公司都存在这样类似情况:使用过用户画像一段时间后,发现也就那么一回事,也就渐渐不再使用。
这是用户画像在业务层面遇到老大难的问题。虽然企业自称建立用户画像,应用还是挺粗糙的。
怎样深入理解用户画像
画虎不全反类汪,想要用好它,首先得深入理解用户画像。
现在运营按用户生命周期设立了几个标签,比如新用户、活跃用户、流失用户,这些标签当然够细分。但它真的是一个好标签么?不是。
因为这些都是滞后性的。按流失用户的一般定义,往往是用户很长一段时间没有回应和行动,但是都几个月没有响应了,哪怕知道是流失用户也于事无补。它有价值,但太滞后。
聪明的运营会设立一个新的标签,最近一次活跃距今天数,用户有六个月没有活跃,那么天数就是180天。这个比单纯的流失用户标签好,能凭此划分不同的距今天数,设立30天,90天,180天的时间节点。
距今天数也不是最好的。用户有差异,同样两个用户A和B,哪怕不活跃天数相同,我也不能认为它们的流失可能性相等。该问题在低频场景更凸显,旅游APP,半年没有活跃也是正常的,此时距今天数力有未逮。
回过头看流失用户,我们定义它,不是为了设立一个高大上的系统。任何企业,肯定一开始就希望流失用户越少越好,其次才是如何挽回。这种业务前提下,预防性的减少流失用户比已经流失的标签更重要。
所以最好的标签的标签是用户流失概率,流失概率>距今消费天数>流失标签。
不要想当然的归纳一个齐全完备的体系,却忽略了画像的核心价值。用户画像首先得是商业目的下的用户标签集合。
猜用户是男是女,哪里人,工资多少,有没有谈恋爱,喜欢什么,准备剁手购物吗?探讨这些是没有意义的。是男是女如何影响消费决策,工资多少影响消费能力,有没有谈恋爱会否带来新的营销场景,剁手购物怎么精准推荐,这些才是用户画像背后的逻辑。
不是我有了用户画像,便能驱动和提高业务。而是为了驱动和提高业务,才需要用户画像。这是很容易犯的错误。
用户画像的标签一般通过两种形式获得,基于已有数据或者一定规则加工,流失标签和距今天数皆是。另外一种是基于已有的数据计算概率模型,会用到机器学习和数据挖掘。
概率是介于0~1之间的数值。拿性别举例,除非能直接获取用户的身份证信息,用户很少会填写性别,填写的性别也不一定准确,网游中性别为女的扣脚大汉一抓一大把呢。
这里就要增加一层推断用户真实性别的算法。中国人的性别和名字是强相关,建国建军,翠花翠兰,很容易判断。算法中常用贝叶斯,通过已有的姓名性别库预测新加入的用户性别。
特殊情况下,不少姓名是中性,男女不辩。像晓晶,可男可女。更特殊的情况,看上去是男性的名字,也有可能是女性,我的初中老师就叫建军,然而是个和蔼可亲的小姐姐。
特殊情况意味着特殊的概率,所以不能用非此即彼的二分法。所谓概率,它更习惯告诉你,通过模型推断,建军有95%的可能是男性姓名,表示为0.95;晓晶有55%的可能是男性,表示为0.55。
虽然为了方便,模型会设立阈值,将50%以上的概率默认为男性,以下默认为女性。但业务部门的同学要清楚,用户标签的本质往往是0~1之间的概率。
概率型的标签很难验证。某位用户被标上学生标签,要么真的哄他上传学籍证明,否则很难知道他是不是真的学生。这种黑箱情况下,针对学生用户进行营销活动,效果好与不好,都受标签准确率的影响。广告、推荐、精准营销都会遇到这个问题。
概率肯定有多有少。90%流失概率的用户,和30%流失概率的用户,虽然是模型建立出的预测值,非真实,我们还是会认为前者更有离开的可能性,凭此设立运营策略。
这带来一个新的问题,如何选择概率的阈值?
我们想要挽回流失用户,选择80%以上概率的人群,还是60%呢?答案已经说过了,要考虑业务,挽回流失用户是手段不是目的,实际目的是通过挽回流失用户提高利润,那么阈值的选择迎刃而解。计算不同阈值下,挽回用户的收入和成本,选择最优解。
推而广之,推荐系统也好,广告系统也罢,它们有更复杂的维度、标签、特征,本质也是找出用户最近想不想买车,用户最近想不想旅游。把最合适的信息在最恰当时机推给用户,获取最大的利益。
我列举的案例,是简化过的。像姓名,在电商和消费行业,除了生理上的性别,还会建立消费模型上的性别标签,有些人虽然是男性,但购物行为是女性,这是要区分的。
看到这里别怕,想要建好用户画像,说简单不简单,说难也不难。
如何建立正确的用户画像
用户画像首先是基于业务模型的。业务部门连业务模型都没有想好,数据部门只能巧妇难为无米之炊。数据部门也别关门造车,这和做产品一样,连用户需求都没有理解透彻,匆匆忙忙上线一个APP,结果无人问津。
理解消费者的决策,考虑业务场景,考虑业务形态,考虑业务部门的需求…这些概念说得很虚,但是一个好的用户画像离不开它们。本文没有说数据、模型和算法,是我认为,它们比技术层面更重要。
我们从一个故事开始设立用户画像吧。
老王是一家互联网创业公司的核心人员,产品主营绿色健康沙拉,老王和绿色比较搭嘛。这家公司推出了APP专卖各式各样的沙拉,现在需要建立用户画像指导运营。
公司现阶段在业务层面,更关注营销和销售:如何将沙拉卖得更好。下图是老王简单梳理的运营流程。
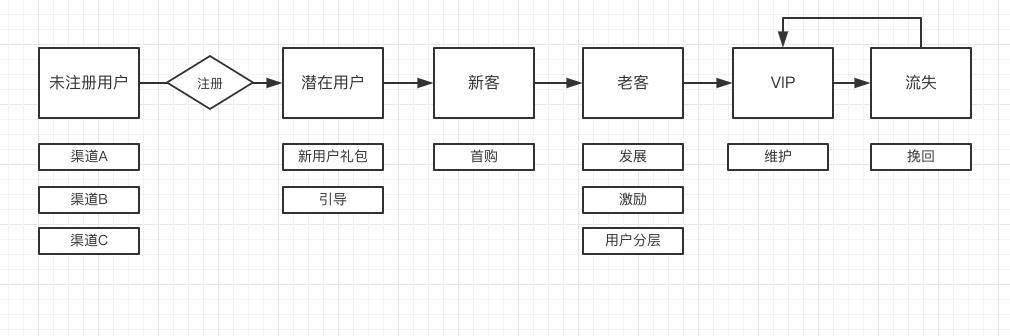
老王将顾客按是否购买过沙拉,划分成潜在用户和新客。潜在用户是注册过APP但还没有下单,新客是只购买过一次沙拉的用户,除此以外还有老客,即消费了两次及以上的人群。

为了便于大家理解,我用JSON格式表示一个简易的用户画像。
为什么独立出新客标签?因为老王的沙拉针对未消费用户会有新人红包引导消费,万事开头难。这也带来新客一次后不再消费的问题,所以需要潜在、新客、老客的划分。
作为一个有追求的运营人员,划分老客也是不够,这里继续用户分层。
传统的分层用RFM三个维度衡量,沙拉的客单价比较固定,F和M取一个就够用了。老王现在计算不同消费档次的用户留存度差异,譬如某时间段内消费达XX元的用户,在未来时间段是否依旧消费。
沙拉这类餐饮是高频消费,XX应该选择一个较窄的时间窗口,统计365天内的消费意义不大。还有一点需要注意的是,沙拉不同季节的销量是有差异的,冬天沙拉肯定卖的不如夏天,要综合考虑消费分布。
这里姑且定义,30天内消费200元以上为VIP用户。老王的生意如果特别好,也可以继续划分超级VIP。这种标签往往配合业务,譬如VIP有赠送饮料,优先配送的权益。非VIP人群,也需要激励往VIP发展。
画像的人口统计属性,老王靠用户填写订单上的收货人姓名搞定。籍贯年龄这几个,对沙拉生意没有特别大的帮助,难道为四川籍用户提高麻辣沙拉?
用户地址,可以通过收货地设立规则判断,比如某个地址出现X次,可以将其认为常用地地址。再依据送货地在写字楼还是学校,推算用户是白领还是学生。
老王针对不同属性的人群,采取了特殊的运营策略。像学生群体,因为7,8月份是暑假,所以老王提前预估到校园地区的销售额下降。当9月开学季,又能对返校学生进行召回。
白领相关的群体,更关注消费体验,对价格敏感是次要的。如果平台女用户的消费占比高,老王就主打减肥功能的沙拉,并且以包月套餐的形式提高销量。

以一家沙拉店来看,老王的用户画像已经不错了,但他还是焦头烂额,因为用户流失率开始上升。用户流失有各种各样的原因:对手老李沙拉的竞争、沙拉的口味、用户觉得性价比不高、老王不够帅等。
流失是一个老大难的预测问题。老王对流失用户的定义是30天没有消费。想要准确预测,这里得尝试用机器学习建模,技术方面先这里略过。所谓建模,最好要找到用户开始不消费的时间点之前的关键因素,可是是行为,可以是属性。
用户历史窗口内消费金额少,有可能流失;用户历史窗口内消费频次低,有可能流失;用户历史窗口内打开APP次数少,有可能流失;用户给过差评,有可能流失;用户等餐时间长,有可能流失;用户的性别差异,有可能流失;餐饮的季度因素,有可能流失…
老王依据业务,挑选了可能影响业务的特征,提交给数据组尝试预测流失。需要注意的是,这些用户行为不能反应真实的情况。大家不妨想一下,流失用户的行为,是不是一个动态的变化过程?
我曾经消费过很多次,但是突然吃腻了,于是减少消费次数,再之后不怎么消费,最终流失。单位时间段内的消费忠诚度是梯度下降的,为了更好的描述变化过程,将时间窗口细分成多个等距段。前30~20天、前20~10天、前10天内,这种切分比前30天内可以更好地表达下降趋势,也更好的预测流失。
从老王的思路看,所谓流失,可以通过用户行为的细节预判。机器学习的建模虽然依赖统计手段,也离不开业务洞察。这里再次证明,用户画像建立在业务模型上。
流失概率解决了老王的心头之患,通过提前发现降低流失用户。挽回流失推行一段时间后,老王发现虽然流失用户减少了,但是成本提高了,因为挽回用户也是要花钱的呀。亏本可不行,老王心头又生一计,他只挽回有价值的,那种拿了红包才消费的用户老王他不要了!老王要的是真爱粉。于是他配合消费档次区别对待,虽然流失用户的数量没有控制好,但是利润提高了。
上述的用户画像,没有一个标签脱离于业务之外。基于业务场景,我们还能想象很多用户画像的玩法。沙拉有不同的口味,蔬果鸡肉海鲜。用户的口味偏好,可以用矩阵分解、模糊聚类或者多分类的问题计算,也以0~1之间的数字表示喜好程度,相似的,还有价格偏好,即价格敏感度。

再深入想一下业务场景,如果某个办公地点,每天都有五六笔的订单,分属不同的客户不同的时间段,外卖小哥得送个五六次,对人力成本是多大的浪费呀。运营可以在后台分析相关的数据,以团购或拼单的形式,促成订单合并,或许销售额的利润会下降,但是外卖的人力成本也节约了。这也是用画像作为数据分析的依据。
老王的运营故事说完了,现在对用户画像的建立有一套想法了吧。
用户画像的架构
不同业务的画像标签体系并不一致,这需要数据和运营目的性的提炼。
用户画像一般按业务属性划分多个类别模块。除了常见的人口统计,社会属性外。还有用户消费画像,用户行为画像,用户兴趣画像等。具体的画像得看产品形态,像金融领域,还会有风险画像,包括征信、违约、洗钱、还款能力、保险黑名单等。电商领域会有商品的类目偏好、品类偏好、品牌偏好,不一而足。

上图是随手画的的例子,画一个架构不难,难得是了解每个标签背后的业务逻辑和落地方式,至于算法,又能单独扯很多文章了。
从数据流向和加工看,用户画像包含上下级递进关系。
以上文的流失系数举例,它通过建模,其依赖于用户早期的历史行为。而用户早期的历史行为,即10天内的消费金额、消费次数、登录次数等,本身也是一个标签,它们是通过原始的明细数据获得。

上图列举了标签加工和计算的过程,很好理解。最上层的策略标签,是针对业务的落地,运营人员通过多个标签的组合形成一个用户群组,方便执行。
公司越大,用户画像越复杂。某家主打内容分发的公司进入了全新的视频领域,现在有两款APP,那么用户画像的结构也需要改变。既有内容相关的标签,也有视频相关的标签,两者是并行且关联的。
比如A用户在内容标签下是重度使用,而在视频标签下是轻度。比如B用户很久没打开内容APP有流失风险,但在视频APP的使用时长上看很忠诚。如此种种,看的是灵活应用。当然,姓名性别这类人口统计标签,是通用的。
用户画像作为平台级的应用,很多运营策略及工具,都是在其基础上构建的。
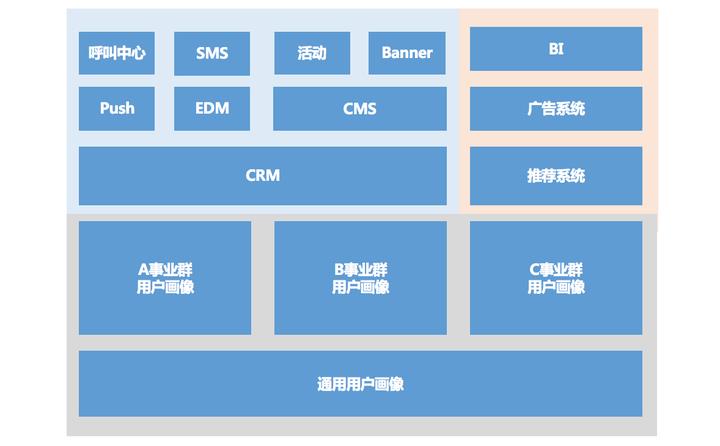
基于营销和消费相关的标签,新客、老客、用户的流失和忠诚、用户的消费水平和频率等,都是构成CRM(客户关系管理)的基础,可能大家更习惯叫它用户/会员管理运营平台。
它的作用在于,将数据化的标签,转换成产品运营策略。不同的标签对应不同的用户群体,也对应不同的营销手段。CRM的结构中会包含各类触达用户的常用渠道比如短信、邮件、推送等。也包含CMS(内容管理系统),执行人员通过其快速配置活动页、活动通道、优惠券等,靠营销活动拉动数据。
老王的沙拉业务要是做大,那么运营平台就会以图中的结构搭建。老王在CRM中组合标签,新客老客流失客的数据借助BI监控,然后通过CMS系统配置红包啊优惠券啊等等,再通过短或Push触达。
好的用户画像系统,既是数据生态体系,也是业务和运营的生态体系,它是一门复杂的交叉领域。
补充:
如何构建用户画像?
“用户画像”的构建需要技术和业务人员的共同参与,以避免形式化的用户画像,具体做法可参考个推构建用户画像的流程:
(1)标签体系设计。开发者需要先了解自身的数据,确定需要设计的标签形式。
(2)基础数据收集、多数据源数据融合。在建设用户画像时,个推用户画像产品会整合个推以及该 APP 自身的数据。
(3)实现用户统一标识。多数情况下,APP 的众多用户分布于不同的账号体系中,个推会将其统一标识,帮助 APP 打通账号,实现信息快速共享。
(4)用户画像特征层构建,即将每一个数据进行特征化。
(5)画像标签规则 + 算法建模,两者缺一不可。在实际的应用中,算法难以解决的问题,利用简单的规则也可以达到很好的效果。
(6)利用算法对所有用户打标签。
(7)画像质量监控。在实际的应用中,用户画像会产生一定的波动,为了解决这个问题,个推建设了相应的监控系统,对画像的质量进行监控。
总之,个推用户画像构建的整体流程,可以概况为三个部分:
第一,基础数据处理。基础数据包括用户设备信息、用户的线上 APP 偏好以及线下场景数据等。
第二,画像中间数据处理。处理结果包括线上 APP 偏好特征和线下场景特征等。
第三,画像信息表。表中应有四种信息:设备基础属性;用户基础画像,包括用户的性别、年龄段、相关消费水平等;用户兴趣画像,即用户更有兴趣的方向,比如用户更偏好拼团还是海淘;用户其它画像等。
在个推用户画像构建的过程中,机器学习占据了较为重要的位置。机器学习主要应用在海量设备数据采集、数据清洗、数据存储的过程。
以上是关于用户画像用户画像简介用户画像的架构搭建用户画像管理平台的主要内容,如果未能解决你的问题,请参考以下文章