Linux工具学习
Posted Jocelin47
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux工具学习相关的知识,希望对你有一定的参考价值。
linux内核追踪系统
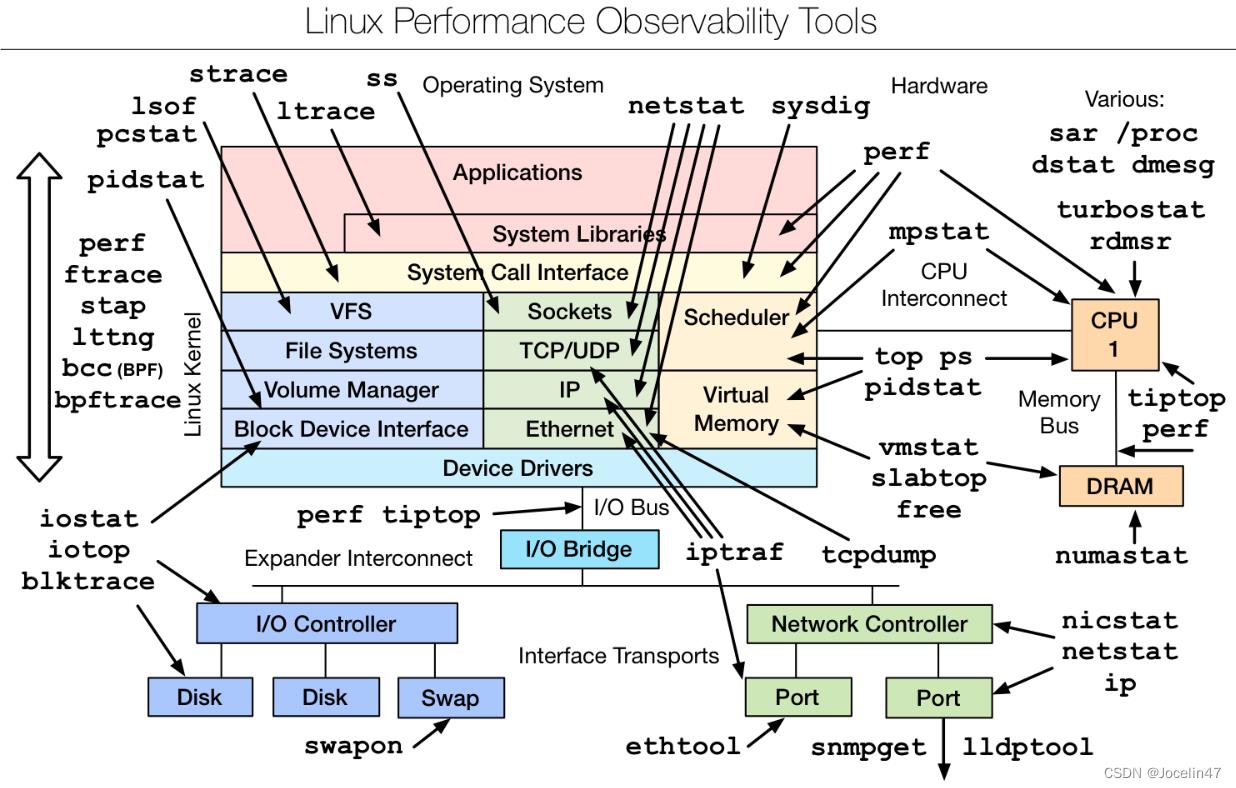
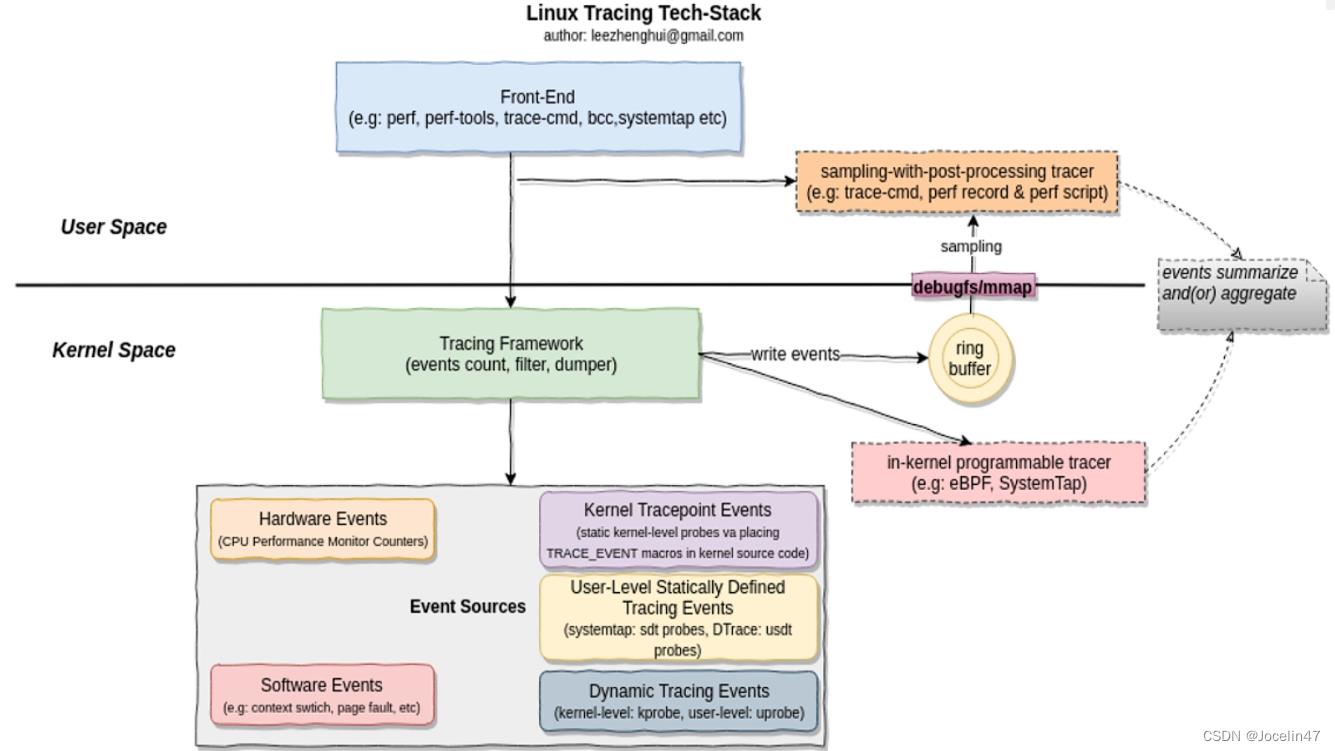
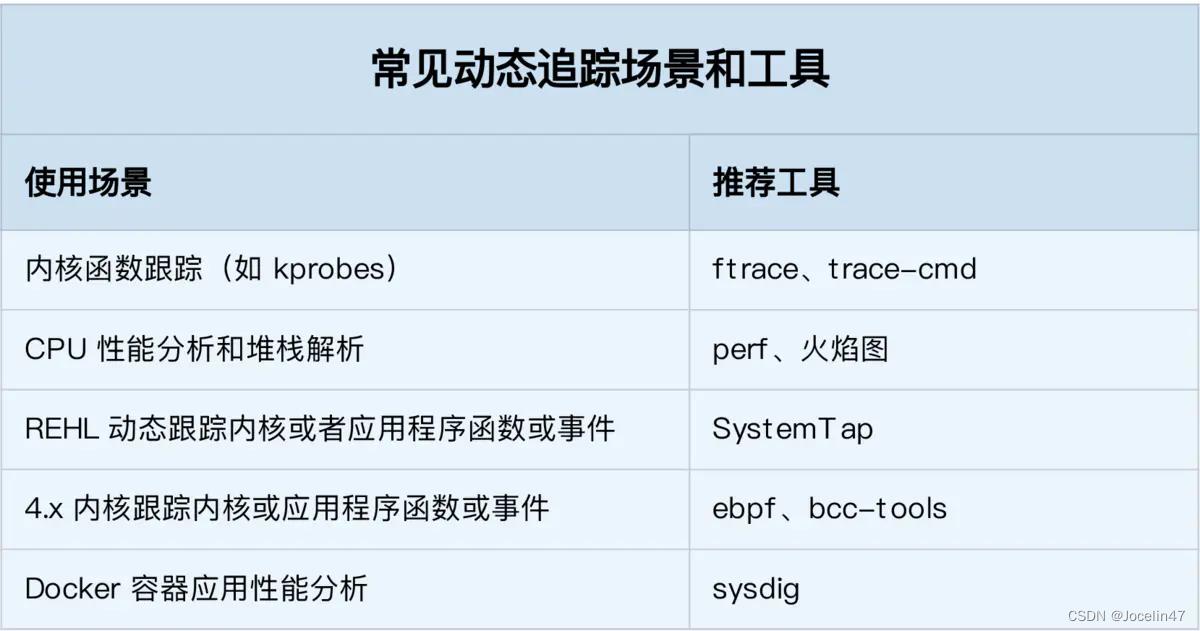
linux内核动态追踪技术:
事件源 (Event Source)
1、 硬件事件
- 性能监控计数器PMCS
场景如下:
(1) 追踪CPU缓存
(2) 追踪指令周期
(3) 分支预测等事关硬件性能情况
2、静态探针 (实现在代码中定义好,并编译到应用程序或内核中的探针)
-
追踪点(tracepoints)
实现方式:
(1) printfk – 最经典使用的方式,手动埋点编译内核,debuglevel控制输出
(2) 内核函数
(3) 内核trace event等 -
USDT探针(User Statically-Defined Tracing)
USDT 探针,全称是用户级静态定义跟踪,需要在源码中插入DTRACE_PROBE()代码,并编译到应用程序中。
3、动态探针
-
kprobes
kprobes主要用来对内核进行调试追踪,属于比较轻量级的机制,本质上是在指定的探测点(比如函数的某行,函数的入口地址和出口地址,或者内核的指定地址处)插入一组处理程序.内核执行到这组处理程序的时候就可以获取到当前正在执行的上下文信息,比如当前的函数名,函数处理的参数以及函数的返回值,也可以获取到寄存器甚至全局数据结构的信息。用法:
(1) kprobes是可以被插入到内核的任何指令位置的探测点
(2) jprobes则只能被插入到一个内核函数的入口
(3) kretprobes则是在指定的内核函数返回时才被执行实现:
(1) 通过编写内核模块的方式向内核注册探测点(可插拔方式注入探测点)
(2) kprobes on ftrace场景:
(1) 某个内核函数是否被调用到?
(2) 内核函数耗时分析
(3) 注入BUG修复代码,相当于内核补丁 -
uprobes
uprobes用来跟踪用户态的函数,包括用于函数调用的uprobe和用于函数返回的 uretprobe。
追踪框架(Tracing Frameworks)
-
ftrace
可消费事件源:tracepoints, kprobes, and uprobes;
依赖debugfs;
依赖debugfs;前端工具:
/sys/kernel/debug/tracing
trace-cmd(上面的简化版)
perf-tools(perf-tools是ftrace和perf_event的包装器) -
perf(perf_event)
可消费事件源:tracepoints, kprobes, and uprobes等;可以完成ftrace的大部分功能。
但是不能做函数遍历(函数调用的层级),比ftrace更安全,支持采样;支持自定义动态事件;场景:
(1) 寻找热点函数,定位性能瓶颈
(2) perf可以用来分析CPU cache、CPU迁移、分支预测、指令周期等各种硬件事件
(3) perf 也可以只对感兴趣的事件进行动态追踪工具用法:
–event: 在perf的各个子命令中添加- -event选项,设置追踪感兴趣的事件。
perf list: 查询支持的事件,类似/sys/kernel/debug/tracing/available_events的输出实测发现,perf支持的事件要比ftrace多一倍左右。 -
eBPF
eBPF是一个内核虚拟机,可在events上高效地运行programs;支持常用的事件追踪;eBPF允许在Linux上执行自定义分析程序来处理事件,包括dynamic tracing, static tracing, and profiling events
前端工具:
bcc工具包 (核心开发语言C,前端为python和lua)
bpftrace(与上面相比,不需要写代码,通过配置就能实现) -
SystemTap
最强大的追踪程序;自己写脚本,由stap编译为驱动并插入内核,几乎可做任何事情,但不太安全; -
sysdig
使用类似tcpdump的语法和lua后处理操作系统调用事件;
还可以通过eBPF来进行扩展,所以,也可以用来追踪内核中的各种函数和事件。
一、linux下性能调优工具OProfile和perf
OProfile 已经存在了几十年,有一段时间是在基于 Linux的系统上进行性能分析的主力军,今天也可以发挥同样的作用。但是,OProfile 不包含在 Red Hat Enterprise Linux (RHEL) 8 beta 中,因此 OProfile 用户开始考虑替代工具可能是谨慎的。在功能、易用性和社区活力方面与OProfile 相比非常有利的类似项目如perf命令。
OProfile 和perf当前在 Linux 内核中使用相同的基本机制来启用事件跟踪:perf_events 基础结构。虽然它主要是一个用户空间工具,perf但从开发的角度来看,该命令是 Linux 内核的一部分,作为 Linux 内核的一部分有优点也有缺点。一个可能的优势是代码更容易维护,因为代码库不会随着时间的推移而分崩离析。一个缺点是版本perf在很大程度上与 Linux 内核的版本有内在联系:获得新功能perf通常意味着获得新内核。
1.1 OProfile
1.1.1 OProfile介绍
OProfile是用于Linux的若干种评测和性能监控工具中的一种,它可以工作在不同的体系结构上,包括MIPS、ARM、IA32、IA64和AMD。
同时OProfile是Linux平台上的一个功能强大的性能分析工具,支持两种采样(sampling)方式:基于事件的采样(eventbased)和基于时间的采样(timebased)。
基于事件的采样是OProfile只记录特定事件(比如L2 cache miss)的发生次数,当达到用户设定的定值时OProfile就记录一下(采一个样)。这种方式需要CPU内部有性能计数器(performace counter)。
基于时间的采样是oProfile借助OS时钟中断的机制,每个时钟中断OProfile都会记录一次(采一次样),引入此种采样方式的目的在于提供对没有性能计数器的CPU的支持,其精度相对于基于事件的采样要低。因为要借助OS时钟中断的支持,对禁用中断的代码OProfile不能对其进行分析。
oProfile在Linux上分两部分,一个是内核模块(oprofile.ko),一个为用户空间的守护进程(oprofiled)。前者负责访问性能计数器或者注册基于时间采样的函数(使用register_timer_hook注册之,使时钟中断处理程序最后执行profile_tick时可以访问之),并采样置于内核的缓冲区内。后者在后台运行,负责从内核空间收集数据,写入文件。
1.1.2 安装OProfile
http://oprofile.sourceforge.net/download/
./configure make & sudo make install
-
ERROR1:configure:error:popt library not found
下载popt-1.16,下载地址:https://www.linuxfromscratch.org/blfs/view/svn/general/popt.html
./configure make & sudo make install -
ERROR2:configure:error: liberty library not found
下载binutils-2.25,下载地址:http://ftp.gnu.org/gnu/binutils/?C=M;O=D./configure make & sudo make install
1.3 使用OProfile
(1) OProfile使用流程
1. opcontrol --init
2. opcontrol --no-vmlinux
3. opcontrol --start
4. ./your_app
5. opcontrol --dump
6. opcontrol --stop
7. opreport -l ./your_app
(2) oprofile初始化
opcontrol --init
该命令会加载oprofile.ko模块,mount oprofilefs。成功后会在/dev/oprofile/目录下导出
一些文件和目录如: cpu_type, dump, enable, pointer_size, stats/
(3) 配置
主要设置计数事件和样本计数,以及计数的CPU模式(用户态、核心态)
opcontrol --vmlinux=/boot/vmlinux-`uname -r` # 监控内核及驱动模块
opcontrol --no-vmlinux # 不监控内核及驱动模块
设置计数事件为CYCLES,即对处理器时钟周期进行计数样本计数为1000,即每1000个时钟周期,oprofile 取样一次。处理器运行于核心态则不计数,运行于用户态则计数。
opcontrol --setup --event=CYCLES:1000::0:1
(4) 清除会话中的数据
opcontrol --reset # 清除当前会话中的数据
(5) oprofile启动监控
opcontrol --start
opcontrol --start-daemon;opcontrol --start # 轻量级,减少启动守护进程对测试结果的影响
(6) 运行测试程序
./test
(7) oprofile停止监控
运行完成后,停止oprofile数据的收集。
opcontrol --stop # 停止监控
opcontrol --shutdown # 停止监控,并结束监控进程(监控的数据默认保存在/var/lib/oprofile/samples)
(8) 查看报告
opreport -l # 如果需要保存信息,可以重定向到文件中,比如opreport -l > 1.txt
(9) 卸载模块
opcontrol --deinit # 卸载模块
1.2 perf
1.2.1 perf介绍
Perf是Linux内核自带的系统性能优化工具,原理是:CPU的PMU registers(性能监控单元寄存器)中Get/Set performance counters来获得诸如instructions executed, cache-missed suffered, branches mispredicted(预测失准的分枝)等信息。
通过Perf,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。使用 perf可以分析程序运行期间发生的硬件事件,比如 cache miss等;也可以分析软件事件,比如 page fault 和进程切换。
1)PMU:性能监控单元(Performance Monitor Unit), CPU提供的一个性能监视单元,用于统计CPU性能数据;
2)Tracepoint:散落在内核源代码中的一些 hook,它们可以在特定的代码被运行到时被触发,这一特性可以被各种 trace/debug 工具所使用。
3)内核运行状态计数,例如: 1) 进程切换 2) Page fault 3) 中断计数
Perf的基本原理就是对被监测对象进行采样,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但若想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 TIck 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
Perf是运行在用户态,它通过RingBuffer数据结构(覆盖方式)与内核态进行交互,每次woken up的时候就是在读RingBuffer中的数据
Perf的使用流程和OProfile很像。所以如果你会用OProfile的话,用Perf就很简单。
1.2.2 安装perf
sudo apt install linux-tools-common

sudo apt install linux-tools-5.4.0-58-generic
sudo apt install linux-cloud-tools-5.4.0-58-generic
1.2.3 使用perf
(1) Perf事件处理常用的参数:
record : 记录到文件perf.data
report: 读取perf.data并以CUI方式展示
stat :统计事件个数
script:脚本自定义处理
trace : live输出事件(strace) ==> (比ptrace更高效的机制)
probe :自定义软件事件
top:类似top命令
list :列出事件
perf record后会将数据保存到perf.data中
perf stat 不会收集数据,只是展示出来通用事件
(2) 实例代码
#include<stdio.h>
void longa()
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
void foo2()
int i;
for(i=0 ; i < 10; i++)
longa();
void foo1()
int i;
for(i = 0; i< 100; i++)
longa();
int main(void)
foo1();
foo2();
return 0;
(3) record 记录到perf.data文件
gcc -o test -g test.c
带上-g选项,加入调试和符号表信息。
sudo perf record -e cycles ./test
带上-e cycles可以不加默认是给我们加上的

perf唤醒内核1次去写(通过信号),与内核交互的ringbuffer交互次数为1次。
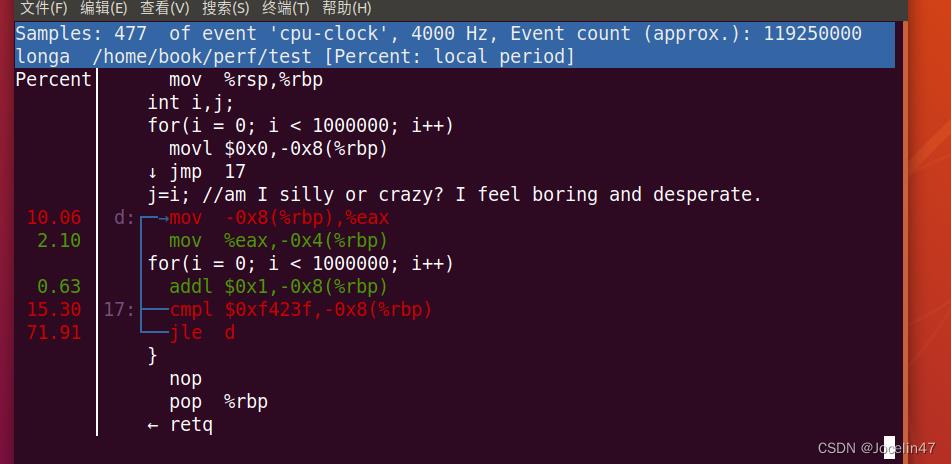
perf report
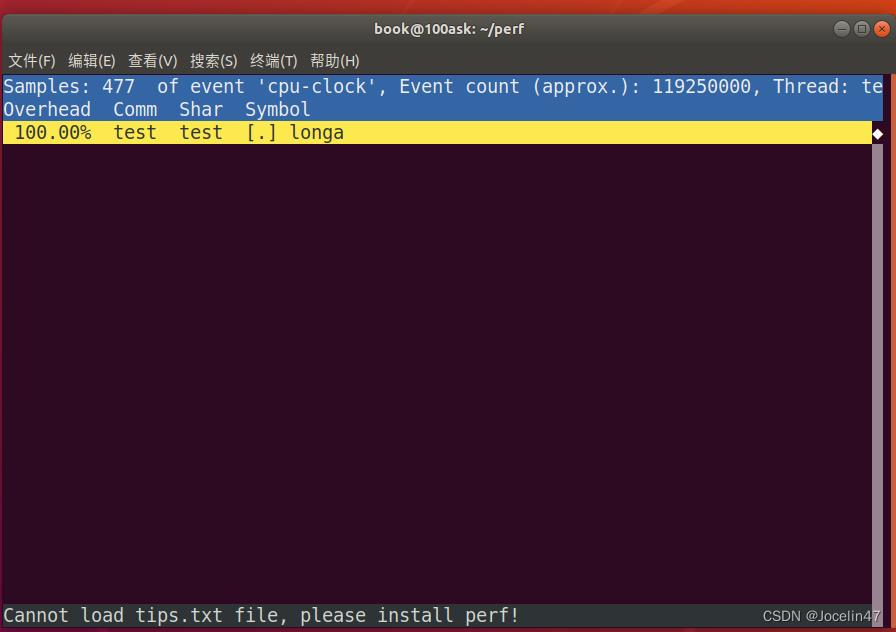
进入可以看到函数的用时占比
(4) stat统计事件个数
sudo perf stat ./test
将通用的事件展示出来
Performance counter stats for './test':
403.33 msec task-clock # 0.985 CPUs utilized
20 context-switches # 0.050 K/sec
0 cpu-migrations # 0.000 K/sec
45 page-faults # 0.112 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
0.409406795 seconds time elapsed
0.380006000 seconds user
0.024000000 seconds sys
(5) probe自定义软件事件
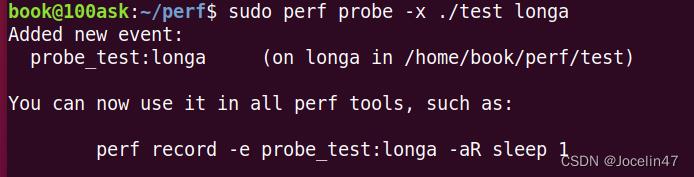
在test中加入一个probe,在longa函数上。可以统计调用longa调用的次数。
sudo perf probe -x ./test longa
sudo perf record -e probe_test:longa ./test
此时的事件-e就不是cycles了,指定的是probe_test
sudo perf report
可以看到有110个事件

也可以通过-d参数删除事件
sudo perf probe -d longa # 删除这个事件,才能再次运行

(6) script 查看调用详细的次数
sudo perf script # 可以看到调用输出的次数
可以看到函数调用的次数。

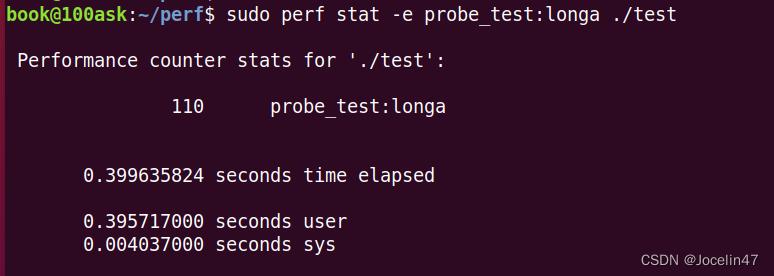
sudo perf stat -e probe_test:longa ./test
在使用前面用的stat命令,可以看到直接输出了调用次数
二、/proc/cpuinfo文件使用
2.1 /proc/cpuinfo涉及的内容介绍
在linux系统中,提供了/proc目录下文件,显示系统的软硬件信息。如果想了解系统中CPU的提供商和相关配置信息,则可以查/proc/cpuinfo。但是此文件输出项较多,不易理解。例如我们想获取,有多少颗物理CPU,每个物理cpu核心数,以及超线程是否开启等信息。
使用cat /proc/cpuinfo可以查看到cpu的信息:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 61
model name : Intel(R) Core(TM) i5-5200U CPU @ 2.20GHz
stepping : 4
microcode : 0x2d
cpu MHz : 2196.822
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap xsaveopt arat md_clear flush_l1d arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_multihit srbds
bogomips : 4393.64
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
其中关键字表示的意思如下:
processor :系统中逻辑处理核心数的编号,从0开始排序。
vendor_id :CPU制造商
cpu family :CPU产品系列代号
model :CPU属于其系列中的哪一代的代号
model name:CPU属于的名字及其编号、标称主频
stepping :CPU属于制作更新版本
cpu MHz :CPU的实际使用主频
cache size :CPU二级缓存大小
physical id :单个物理CPU的标号
siblings :单个物理CPU的逻辑CPU数。siblings=cpu cores [*2]。
core id :当前物理核在其所处CPU中的编号,这个编号不一定连续。
cpu cores :该逻辑核所处CPU的物理核数。比如此处cpu cores 是4个,那么对应core id 可能是 1、3、4、5。
apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
fpu :是否具有浮点运算单元(Floating Point Unit)
fpu_exception :是否支持浮点计算异常
cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
flags :当前CPU支持的功能
bogomips:在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second
clflush size :每次刷新缓存的大小单位
cache_alignment :缓存地址对齐单位
address sizes :可访问地址空间位数
power management :对能源管理的支持
2.2 快速的查看具体的内容
-
查询系统有几颗物理CPU:
cat /proc/cpuinfo | grep "physical id" |sort |uniq -
查询系统每颗物理CPU的核心数
cat /proc/cpuinfo | grep "cpu cores" | uniq -
查询系统的每颗物理CPU核心是否启用超线程技术。
如果启用此技术那么,每个物理核心又可分为两个逻辑处理器。
cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq如果cpu cores数量和siblings数量一致,则没有启用超线程,否则超线程被启用。

-
查询系统具有多少个逻辑CPU
cat /proc/cpuinfo | grep "processor" | wc -l
三、Top工具使用
3.1 top命令介绍
top 命令是 Linux 系统下常用的系统监控工具,通过 top 命令我们可以获取到系统动态运行的信息,包括内存使用情况,系统负载情况,进程的运行情况等等。
3.2 top命令用法
使用top命令后,可以在界面进行交互操作,参数h可以看到帮助命令

-d:number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。要手动刷新,用户可以输入回车或者空格
-b:以批次的方式执行top。
-n:与-b配合使用,表示需要进行几次top命令的输出结果,到达指定次数后 top 退出
top 命令的批处理模式(Batch-mode)可以区别于正常使用的交互模式(Interactive-mode),在批处理模式下top 只会不断打印系统状态,无法接受其他交互模式下的命令。如果配合-n 选项指定刷新次数的话,可以通过批处理模式将系统状态不断打印到日志中,实现实时监控的效果。
-p:指定特定的pid进程号进行观察。
-u: user 只显示指定用户启动的进程
示例: top -u root(只显示以root用户启动的进程)
-B:重要内容加粗
-H:切换到线程状态
-k:结束指定进程
-m:切换内存使用量的显示样式
-e:调整内存的计量单位
F:命令指定字段过滤
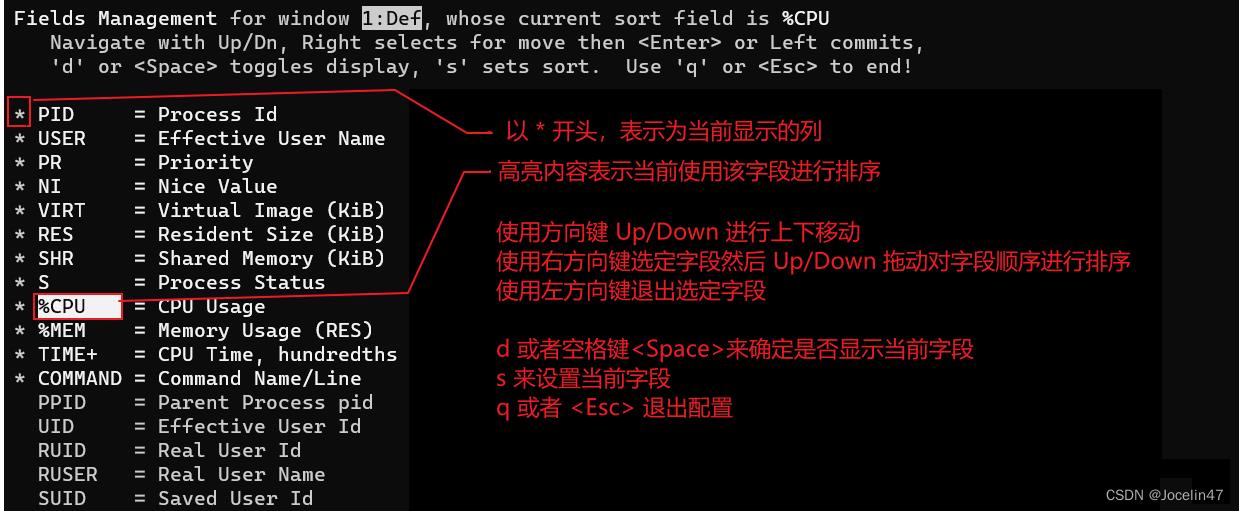
通过选中MEM字段右移调序到CPU上面后,优先以MEM排序;
通过空格可以选择是否显示该字段
-c:切换是否显示进程启动时的完整路径和程序名。
-o:命令执行过滤
命令的格式如下:
<!> <字段名称> <操作符> <包含值/排除值>
支持>,<,=这三类操作符
例子:显示PID>100的可以使用PID>100或者!PID<100
通过COMMAND=top,可以查看到top进程

使用 Ctrl+o 显示当前生效的过滤器
使用 =重置当前窗口的过滤器
使用 +重置全部窗口的过滤器
3.3 top界面参数说明
3.3.1 top前五行信息说明
top - 22:33:04 up 2 min, 1 users, load average: 0.85, 0.62, 0.25
Tasks: 155 total, 2 running, 153 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.4 us, 1.4 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2967536 total, 2249804 free, 303732 used, 414000 buff/cache
KiB Swap: 4194300 total, 4194300 free, 0 used. 2509432 avail Mem
前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。含义如下:
| 22:39:11 | 当前时间 |
|---|---|
| up 8 min | 系统运行时间 |
| 1 user | 当前登录用户数 |
| load average: 0.00, 0.17, 0.16 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。top - 22:33:04 up 2 min, 2 users, load average: 0.85, 0.62, 0.25 |
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。
第二行内容及含义如下:
Tasks: 155 total, 2 running, 153 sleeping, 0 stopped, 0 zombie
| 内容 | 含义 |
|---|---|
| total | 进程总数 |
| running | 正在运行的进程数 |
| sleeping | 睡眠的进程数 |
| stopped | 停止的进程数 |
| zombie | 僵尸进程数 |
第三行内容及含义如下:(可以按1查看所有CPU的信息)
%Cpu(s): 3.4 us, 1.4 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
| 内容 | 含义 |
|---|---|
| us | 用户空间占用CPU百分比 |
| sy | 内核空间占用CPU百分比 |
| ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| id | 空闲CPU百分比 |
| wa | 等待输入输出的CPU时间百分比 |
| hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| si | 软中断(Software Interrupts)占用CPU的百分比 |
| st | (Steal time) 是当 hypervisor 服务另一个虚拟处理器的时候,虚拟 CPU 等待实际 CPU 的时间的百分比。 |
最后两行为内存信息。
第四行的内容及含义如下:
KiB Mem : 2967536 total, 2249804 free, 303732 used, 414000 buff/cache
| 内容 | 含义 |
|---|---|
| KiB Mem | 使用的物理内存总量 |
| used | 使用的内存总量 |
| buff/cache | 用作内核缓存的内存量 |
第五行的内容及含义如下:
KiB Swap: 4194300 total, 4194300 free, 0 used. 2509432 avail Mem
| 内容 | 含义 |
|---|---|
| KiB Swap | 交换区总量 |
| avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上表中的缓冲交换区总量含义为:内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入
3.3.2 进程信息说明
| 列名 | 含义 |
|---|---|
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值,负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEN | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
四、vmstat使用
4.1 vmstat介绍
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。
vmstat是对系统的整体情况进行统计,相比于top命令是无法对某个进程进行深入分析。
vmstat 工具提供了一种低开销的系统性能观察方式。因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果
4.2 命令参数介绍
(1) vmstat [options] [delay [count]]
其中不带options只有delay一集count则如下:
vmstat 1 3 代表1s收集一次,收集三次,没有count则一直按照delay收集。

常用的OPTIONS如下:
(2) -a: 查看内存的active和inactive
vmstat -a
(3) -f: 查看系统已经fork了多少次
vmstat -f
这个数据是从/proc/stat中的processes字段里取得的
(4) -s: 查看内存使用的详细信息
vmstat -s
2006960 K total memory
1066488 K used memory
586192 K active memory
811164 K inactive memory
82216 K free memory
236672 K buffer memory
621584 K swap cache
8787964 K total swap
279268 K used swap
8508696 K free swap
65379 non-nice user cpu ticks
794744 nice user cpu ticks
240195 system cpu ticks
3190159 idle cpu ticks
3553 IO-wait cpu ticks
0 IRQ cpu ticks
6492 softirq cpu ticks
0 stolen cpu ticks
3888549 pages paged in
1053420 pages paged out
7942 pages swapped in
78605 pages swapped out
4567257 interrupts
2767542 CPU context switches
1655110598 boot time
4533 forks
这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat
(5) -d: 查看内存的读写
vmstat -d
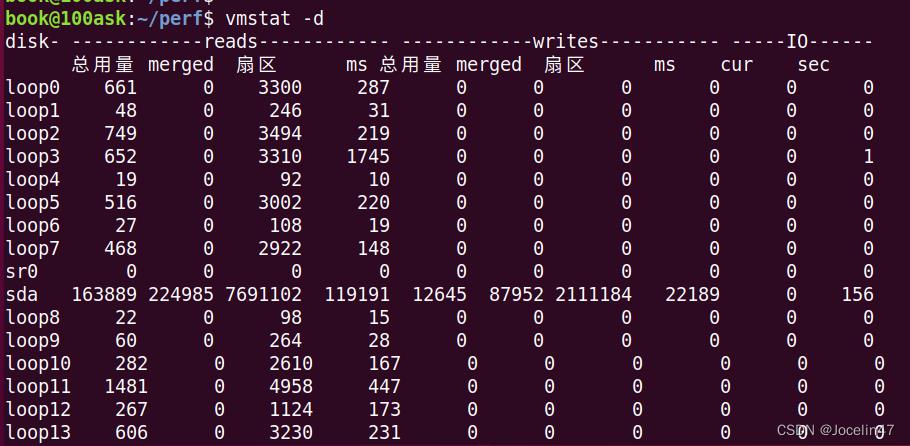
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作
(6) -p: 查看具体磁盘的读/写
vmstat -p /dev/sda1

reads:来自于这个分区的读的次数.
read sectors:来自于这个分区的读扇区的次数.
writes:来自于这个分区的写的次数.
requested writes:来自于这个分区的写请求次数.
与-d命令一样,这些信息来自:/proc/diskstats。
(7) -S: 指定单位显示
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)

(8) -m: 显示slabinfo
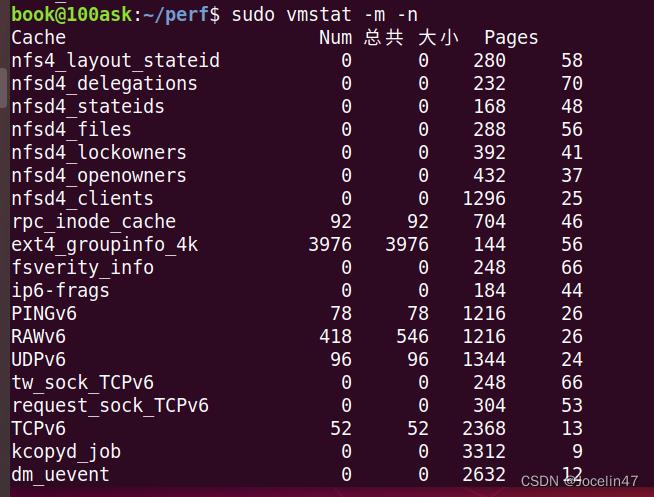
来自 /proc/slabinfo
(9) -n: 只在开始显示一次字段名称
4.3 参数含义介绍
FIELD DESCRIPTION FOR VM MODE
Procs # 进程
r: The number of runnable processes (running or waiting for run time).
# r:等待执行的任务数 含义:展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。
b: The number of processes in uninterruptible sleep.
# b:等待IO的进程数量
Memory
swpd: the amount of virtual memory used.
# swpd:正在使用虚拟的内存大小,单位k
free: the amount of idle memory.
# free:空闲内存大小
buff: the amount of memory used as buffers.
# buff:已用的buff大小,对块设备的读写进行缓冲
cache: the amount of memory used as cache.
# cache:已用的cache大小,文件系统的cache
inact: the amount of inactive memory. (-a option)
# 非活跃内存大小,即被标明可回收的内存,区别于free和active(当使用-a选项时显示)
active: the amount of active memory. (-a option)
# active:活跃的内存大小(当使用-a选项时显示)
Swap
si: Amount of memory swapped in from disk (/s).
# si:每秒从交换区写入内存的大小(单位:kb/s)
so: Amount of memory swapped to disk (/s).
# so:每秒从内存写到交换区的大小
IO
bi: Blocks received from a block device (blocks/s).
# bi:每秒读取的块数(读磁盘)
bo: Blocks sent to a block device (blocks/s).
# bo:每秒写入的块数(写磁盘)
System
in: The number of interrupts per second, including the clock.
# in:每秒中断数,包括时钟中断
cs: The number of context switches per second.
# cs:每秒上下文切换数;秒上下文切换次数,例如我们调用系统函数,
# 就要进行上下文切换线程的切换,也要进程上下文切换,这个值要越
# 小越好,太大了,要考虑调低线程或者进程的数目。
# in和cs这两个值越大,会看到由内核消耗的cpu时间sy会越多
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
# us:用户进程执行消耗cpu时间(user time);us的值比较高时,说
# 明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我
# 们就该考虑优化程序算法或其他措施了
sy: Time spent running kernel code. (system time)
# sy:系统进程消耗cpu时间(system time),sys的值过高时,说明系统
# 内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里
# us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
# id:空闲时间(包括IO等待时间),一般来说 us+sy+id=100
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
# wa:等待IO时间,wa过高时,说明io等待比较严重,这可能是由于磁盘大
# 量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
# st:代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间
五、free工具使用
5.1 free介绍
查看内存是否存在瓶颈,使用top指令看比较麻烦,而free命令更为直观。free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。


其中参数与top一样
total:总内存大小。
used:已经使用的内存大小(这里面包含cached和buffers和shared部分)。
free:空闲的内存大小。
shared:进程间共享内存(一般不会用,可以忽略)。
buffers:内存中写完的东西缓存起来,这样快速响应请求,后面数据再定期刷到磁盘上。
cached:内存中读完缓存起来内容占的大小(这部分是为了下次查询时快速返回)。
5.2 命令参数介绍
-b: 以Byte为单位显示内存使用情况。
-k: 以KB为单位显示内存使用情况。
-m: 以MB为单位显示内存使用情况。
-g: 以GB为单位显示内存使用情况。
-h: 根据内存大小自动选择合适的单位显示
-o: 不显示缓冲区调节列。
-s: <间隔秒数> 持续观察内存使用状况。
-c: <显示次数> 和-s配合使用
-t: 显示内存总和列。
六、/cpu/meminfo
6.1 /cpu/meminfo介绍
/proc/meminfo是了解Linux系统内存使用状况的主要接口,我们最常用的”free”、”vmstat”等命令就是通过它获取数据的 ,/proc/meminfo所包含的信息比”free”等命令要丰富得多
负责输出/proc/meminfo的源代码是:
fs/proc/meminfo.c : meminfo_proc_show()
cat /proc/meminfo得到:
MemTotal: 2006960 kB
MemFree: 163468 kB
MemAvailable: 713260 kB
Buffers: 212512 kB
Cached: 432348 kB
SwapCached: 6644 kB
Active: 603872 kB
Inactive: 691688 kB
Active(anon): 323396 kB
Inactive(anon): 341636 kB
Active(file): 280476 kB
Inactive(file): 350052 kB
Unevictable: 16 kB
Mlocked: 16 kB
SwapTotal: 8787964 kB
SwapFree: 8509208 kB
Dirty: 208 kB
Writeback: 0 kB
AnonPages: 645072 kB
Mapped: 172928 kB
Shmem: 15500 kB
KReclaimable: 101472 kB
Slab: 183640 kB
SReclaimable: 101472 kB
SUnreclaim: 82168 kB
KernelStack: 12768 kB
PageTables: 42388 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 9791444 kB
Committed_AS: 4707140 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 30348 kB
VmallocChunk: 0 kB
Percpu: 46080 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
FileHugePages: 0 kB
FilePmdMapped: 0 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 288640 kB
DirectMap2M: 1808384 kB
DirectMap1G: 0 kB
6.2 /cpu/meminfo得到的参数含义
-
MemTotal: 所有内存(RAM)大小,减去一些预留空间和内核的大小。
系统从加电开始到引导完成,firmware/Bios要保留一些内存,kernel本身要占用一些内存,最后剩下可供kernel支配的内存就是MemTotal。这个值在系统运行期间一般是固定不变的。

内核所用内存的静态部分,比如内核代码、页描述符等数据在引导阶段就分配掉了,并不计入MemTotal里,而是算作reserved因此total-reserved = 2096628-138012=1958616 -
MemFree: 完全没有用到的物理内存,lowFree+highFree
-
MemAvailable: 在不使用交换空间的情况下,启动一个新的应用最大可用内存的大小
有些应用程序会根据系统的可用内存大小自动调整内存申请的多少,所以需要一个记录当前可用内存数量的统计值,MemFree并不适用,因为MemFree不能代表全部可用的内存,系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存,即MemAvailable。计算方式:MemFree+Active(file)+Inactive(file)-(watermark+min(watermark,Active(file)+Inactive(file)/2)),这个值是一个估计值。 -
Buffers: 块设备所占用的缓存页,包括:直接读写块设备以及文件系统元数据(metadata),比如superblock使用的缓存页。它与“Cached”的区别在于,”Cached”表示普通文件所占用的缓存页。FREE命令显示的BUFFERS与CACHED的区别
-
Cached: 表示普通文件数据所占用的缓存页。
Page Cache里包括所有file-backed pages,统计在/proc/meminfo的”Cached”中。
“Cached”和”SwapCached”两个统计值是互不重叠的,Shared memory和tmpfs在不发生swap-out的时候属于”Cached”,而在swap-out/swap-in的过程中会被加进swap cache中、属于”SwapCached”,一旦进了”SwapCached”,就不再属于”Cached”了。 -
SwapCached: swap cache中包含的是被确定要swapping换页,但是尚未写入物理交换区的匿名内存页。那些匿名内存页,比如用户进程malloc申请的内存页是没有关联任何文件的,如果发生swapping换页,这类内存会被写入到交换区。
匿名页(anonymous pages)要用到交换区,而shared memory和tmpfs虽然未统计在AnonPages里,但它们背后没有硬盘文件,所以也是需要交换区的。也就是说需要用到交换区的内存包括:”AnonPages”和”Shmem”
-
Active: active包含active anon和active file
-
Inactive: inactive包含inactive anon和inactive file
-
Active(anon): anonymous pages(匿名页),用户进程的内存页分为两种:
(1) 与文件关联的内存页(比如程序文件,数据文件对应的内存页);
(2) 与内存无关的内存页(比如进程的堆栈,用malloc申请的内存;
其中,(1)称为file pages或mappedpages,(2)称为匿名页。 -
Inactive(anon): 见上
-
Active(file): 见上
-
Inactive(file): 见上
-
Unevictable:不能被释放的内存页
-
Mlocked:系统调用 mlock
-
SwapTotal: 可用的swap空间的总的大小(swap分区在物理内存不够的情况下,把硬盘空间的一部分释放出来,以供当前程序使用)
-
SwapFree: 当前剩余的swap的大小
-
Dirty: 需要写入磁盘的内存去的大小
-
Writeback: 正在被写回的内存区的大小
-
AnonPages: 未映射页的内存的大小Mapped: 设备和文件等映射的大小
前面提到用户进程的内存页分为两种:file-backed pages(与文件对应的内存页),和anonymous pages(匿名页) -
Mapped:用户进程的file-backed pages就对应着/proc/meminfo中的”Mapped”
Page cache中(“Cached”)包含了文件的缓存页,其中有些文件当前已不在使用,page cache仍然可能保留着它们的缓存页面;而另一些文件以上是关于Linux工具学习的主要内容,如果未能解决你的问题,请参考以下文章