python下用selenium如何获取页面显示的文本内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python下用selenium如何获取页面显示的文本内容相关的知识,希望对你有一定的参考价值。
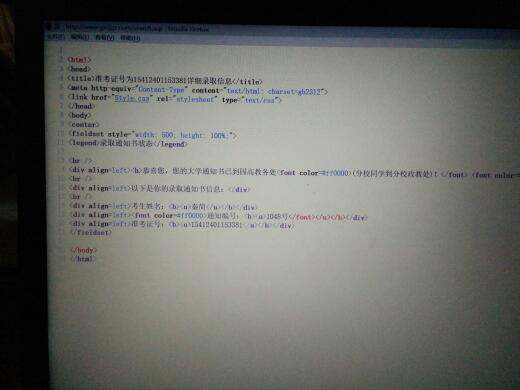
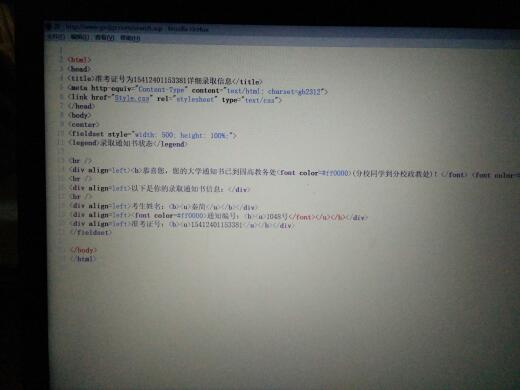
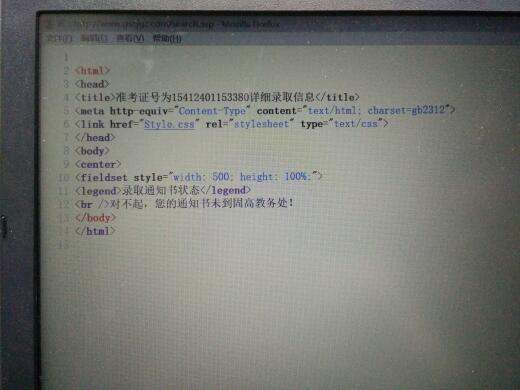
网页代码是这个,现在想获取姓名和通知编号,不知道怎么弄
<div align=left>考生姓名:<b><u>秦简</u></b></div>
<div align=left><font color=#ff0000>通知编号:<b><u>1048号</font></u></b></div>
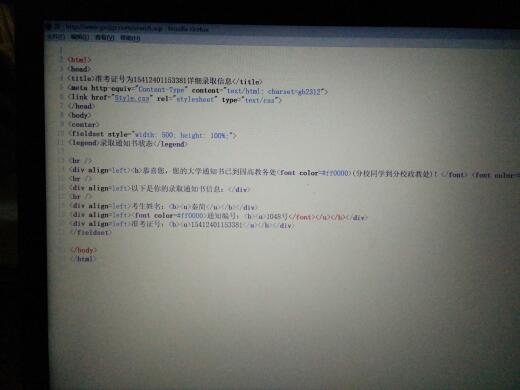
整个网页代码啥样的?代码中只出现两个div?那就用css选择器,看下面:
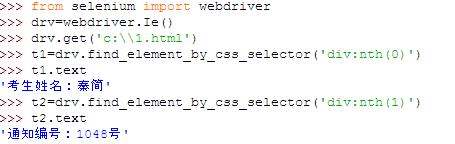
代码是这样的,能否麻烦一下再给下解答
追答你改下我的代码就行了,把nth(0)改为nth(2),得到的就是考生姓名,通知是nth(3)
追问就是它还有种情况是未查询到通知书
想加一个判断不知道怎么加,劳烦了
其实查询不到信息时,是没有div的,那你也就定位不到,这时会报异常,你只要加个异常处理就行了try...except..
追问我在try里面打印,但是却打印不出来
追答

太无知,直接写print t1.text
真的很感谢
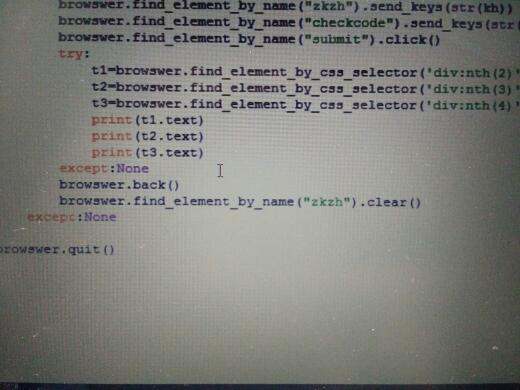

我是这样写的,但还是无法打印
追答你的python是啥版本? py2.x版print不能带括号 ,要用print t1.txt,我的是py3.3
追问2的版本
第一次用的是没带括号的就不行

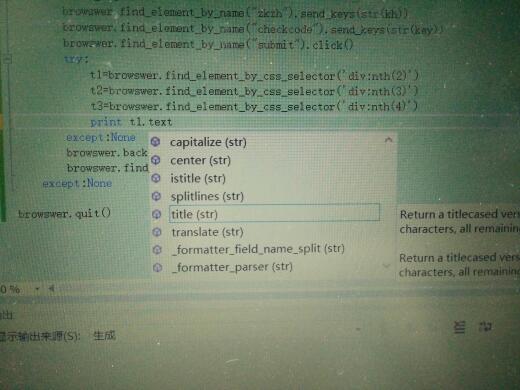
用VS运行,t1没找到text的成员
追答你在第2个try前面加上个等待时间,browswer.implicitly_wait(3)
追问还是不成
追答你先判断是哪个try出了问题,两个except你分别随便打印个字符出来
追问好的
这个是循环想网站提交考号(一个大区间)开始的时候第二的try是一直会出问题的(考号不正确),第一个try是基本不会有问题的
第一个try可以不用管它
追答考号不正确是啥意思?这么个简单脚本怎搞的这么复杂
追问就是输入一个考号会出现“通知书未到”
当我就测试一个能查到通知书的数据,到执行Css筛选器的时候报错
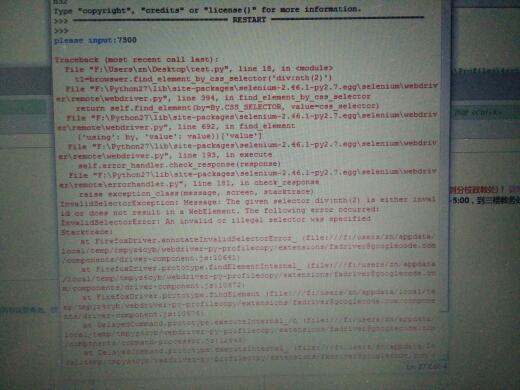
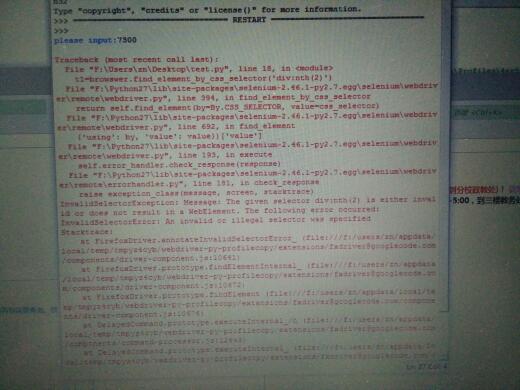
错误的下面部分给贴出来,这么模糊看不清
追问

如何在python中使用Selenium WebDriver获取整个网页源[重复]
【中文标题】如何在python中使用Selenium WebDriver获取整个网页源[重复]【英文标题】:How to get the entire web page source using Selenium WebDriver in python [duplicate] 【发布时间】:2016-05-30 21:48:35 【问题描述】:我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
感谢任何帮助
【问题讨论】:
【参考方案1】:你的 WebDriver 对象应该有一个page_source 属性,所以对于 Firefox 来说它看起来像
from selenium import webdriver
driver = webdriver.Firefox()
driver.page_source
【讨论】:
以上是关于python下用selenium如何获取页面显示的文本内容的主要内容,如果未能解决你的问题,请参考以下文章