MySQL性能优化系列select count(*)走二级索引比主键索引快几百倍,你敢信?
Posted 三省同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL性能优化系列select count(*)走二级索引比主键索引快几百倍,你敢信?相关的知识,希望对你有一定的参考价值。
问题
在MySQL版本5.7数据测试过程中,一张百万数据的表用 select count(*)查询特别慢需要20s并且是走了主键索引,为什么查询还需要这么久?如何优化?下面我们将请到当事SQL进行发言
验证分析
猜想
先猜想一波为什么走了主键索引依旧很慢?

没有建立二级索引。
聪明的小伙伴会问了二级索引还能比主键索引快?是的,在count统计情况且表字段数据很大的情况下是会快很多。
干货补充。
因为在 InnoDB 存储引擎中,count(*) 函数是先从内存中读取数据到内存缓冲区,然后进行扫描获得行记录数。InnoDB 会优先走二级索引,若无会走主键索引。导致耗时较长。
在MyISAM存储引擎中,count()函数是直接读取数据表保存的行记录数并返回。
在使用count函数中加上where条件时,在两个存储引擎中的效果是一样的,都会扫描全表计算某字段有值项的次数。
聚簇索引:每一个 InnoDB 存储引擎下的表都有一个特殊的索引用来保存每一行的数据,称为聚簇索引(通常都为主键),聚簇索引实际保存了 B-Tree 索引和行数据,所以大小实际上约等于为表数据量。二级索引:除了聚集索引,表上其他的索引都是二级索引,索引中仅仅存储了对应索引列及主键列。
接下来查看下当事表是什么情况吧!
验证
接下来主要对比主键索引和二级索引在count(*)情况下的区别。
0、查看表中索引信息
show index from test;
只有主键索引。

1、当事SQL语句如下:
SELECT count(*) from test;
2、执行结果如下:
1306725
> OK
> 时间: 17.397s
3、查看执行计划:
desc SELECT count(*) from test
 确实是走了主键索引。
确实是走了主键索引。
4、重启数据库
window重启mysql:
net stop mysql
net start mysql
linux:
service mysqld restart
5、查看内存缓冲区情况
select * from sys.innodb_buffer_stats_by_table where object_schema = 'test';

6、再次执行SELECT count(*) from test查看内存缓冲区情况

7、加入二级索引重复以上验证
ALTER TABLE `test`.`test`
ADD INDEX `idx_id`(`id`) USING BTREE;
查看二级索引大小:大约15M。
SELECT CONCAT(ROUND(SUM((data_length+index_length)/1024/1024),2),'MB') AS DATA FROM information_schema.`TABLES` WHERE table_schema='test' AND table_name='test';
加索引前表数据大小
931.50MB
加索引后前表数据大小
916.98MB
执行:
SELECT count(*) from test
1306725
> OK
> 时间: 0.198s
查看执行计划:
 使用的二级索引。
使用的二级索引。
查看缓冲区情况:
 缓冲区数据大小与二级索引大小基本相同。
缓冲区数据大小与二级索引大小基本相同。
小结
通过验证与猜想中的实际理论相符。在没有二级索引的情况下, select count(*) 会走主键索引,缓存整表数据到缓冲区。如果存在二级索引,只需要读取索引页到缓冲区,查询速度显著提高几百倍。以上是基于MySQL版本5.7进行测试,如果是MySQL 8.0就能使用新特性 并行查询 innodb_parallel_read_threads ,再次提高查询速度。
并行查询示例如下:
set local innodb_parallel_read_threads=888;
select count (*) from test;
小拓展
count(*)、count(1)、count(0)、count(列名)用哪个?
使用count(*) 就可以了
阿里巴巴规范参考:
【强制】不要使用 count(列名)或 count(常量)来替代 count(),count()是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*)会统计值为 NULL 的行,而count(列名)不会统计此列为 NULL 值的行。
【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
【强制】当某一列的值全是 NULL时,count(col)的返回结果为 0,但 sum(col)的返回结果为NULL,因此使用 sum()时需注意 NPE 问题。
查询一个库中每个表的数据大小,索引大小和总大小
SELECT
CONCAT(a.table_schema,'.',a.table_name) as '表名',
CONCAT(ROUND(table_rows/1000,4),'KB') AS '行大小',
CONCAT(ROUND(data_length/(1024*1024),4),',') AS '数据大小',
CONCAT(ROUND(index_length/(1024*1024),4),'M') AS '索引大小',
CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),4),'G') AS'总大小'
FROM
information_schema.TABLES a
WHERE
a.table_schema = 'test'
ORDER BY index_length desc

点赞 收藏 关注
山花对海树,赤日对苍穹。
Mysql性能优化:为什么你的count(*)这么慢?
原文:Mysql性能优化:为什么你的count(*)这么慢?
导读
- 在开发中一定会用到统计一张表的行数,比如一个交易系统,老板会让你每天生成一个报表,这些统计信息少不了 sql 中的count函数。
- 但是随着记录越来越多,查询的速度会越来越慢,为什么会这样呢?Mysql内部到底是怎么处理的?
- 今天这篇文章将从Mysql内部对于
count函数是怎样处理的? - 本文首发于作者微信公众号【码猿技术专栏】Mysql性能优化:为什么你的count(*)这么慢?,原创不易,喜欢的请支持一下,谢谢!!!
count的实现方式
- 在Mysql中的不同的存储引擎对
count函数有不同的实现方式。 MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高(没有where查询条件)。InnoDB引擎并没有直接将总数存在磁盘上,在执行count(*)函数的时候需要一行一行的将数据读出来,然后累计总数。
为什么InnoDB不将总数存起来?
-
说到InnoDB相信读者总会想到其支持事务的特性,事务具有隔离性,如果将总数存起来,怎么保证各个事务之间的总数的一致性呢?不明白的看图

-
事务A和事务B中的count(*)的执行结果是不同的,因此InnoDB引擎在每个事务中返回多少行是不确定的,只能一行一行的读出来用来判断总数。
如何提升count效率
- 在
InnoDB对于如何提升count(*)的查询效率,网上有多种解决办法,这里主要介绍三种,并分析可行性。
show table status
show table status这个命令能够很快的查询出数据库中每个表的行数,但是真的能够替代count(*)吗?- 答案是不能。原因很简单,这个命令统计出来的值是一个「估值」,因此是不准确的,官方文档说误差大概在
40%-50%。 - 因此这种方法直接pass,不准确还用它干嘛。
缓存系统存储总数
-
这种方法也是最容易想到的,增加一行就
+1,删除一行就-1,并且缓存系统读取也是很快,既简单又方便的为什么不用? -
缓存系统和Mysql是两个系统,比如
redis和Mysql这两个是典型的比较。两个系统最难的就是在高并发下无法保证数据的一致性。

-
通过上面两张图,无论是
redis计数+1还是insert into user先执行,最终都会导致数据在逻辑上的不一致。第一张图会出现redis计数少了,第二张图虽然计数正确了但是并没有查询出插入的那一行数据。 -
在并发系统里面,我们是无法精确控制不同线程的执行时刻的,因为存在图中的这种操作序列,所以,我们说即使Redis正常工作,这个计数值还是逻辑上不精确的。
在数据库保存计数
-
通过缓存系统保存的分析得知了使用缓存无法保证数据在逻辑上的一致性,因此我们想到了直接使用数据库来保存,有了「事务」的支持,也就保证了数据的一致性了。
-
如何使用呢?很简单,直接将计数保存在一张表中
(table_name,total)。 -
至于执行的逻辑只需要将缓存系统中
redis计数+1改成total字段+1即可,如下图: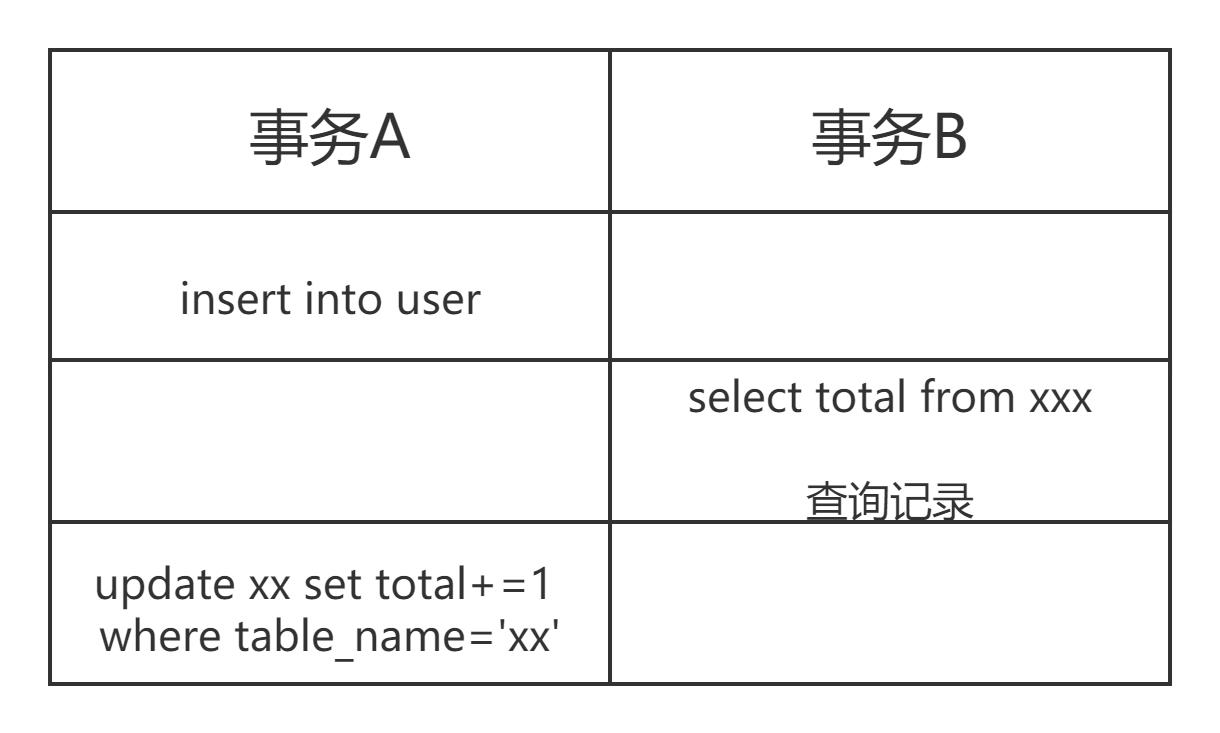
-
由于在同一个事务中,保证了数据在逻辑上的一致性。
不同count的用法
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。count的用法有多种,分别是count(*)、count(字段)、count(1)、count(主键id)。那么多种用法,到底有什么差别呢?当然,「前提是没有where条件语句」。count(id):InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。count(1):InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字1进去,判断是不可能为空的,按行累加。count(字段):count(*):不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。- 如果这个“字段”是定义为
not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加; - 如果这个字段定义允许为
null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
- 如果这个“字段”是定义为
- 所以结论很简单:「按照效率排序的话,
count(字段)<count(主键id)<count(1)≈count(*),所以建议读者,尽量使用count(*)。」 - 「注意」:这里肯定有人会问,
count(id)不是走的索引吗,为什么查询效率和其他的差不多呢?陈某在这里解释一下,虽然走的索引,但是还是要一行一行的扫描才能统计出来总数。
总结
MyISAM表虽然count(*)很快,但是不支持事务;show table status命令虽然返回很快,但是不准确;InnoDB直接count(*)会遍历全表(没有where条件),虽然结果准确,但会导致性能问题。- 缓存系统的存储计数虽然简单效率高,但是无法保证数据的一致性。
- 数据库保存计数很简单,也能保证数据的一致性,建议使用。
- 「思考题,读者留言区讨论」:在系统高并发的情况下,使用数据库保存计数,是先
更新计数+1,还是先插入数据。即是先update total+=1还是先insert into。
以上是关于MySQL性能优化系列select count(*)走二级索引比主键索引快几百倍,你敢信?的主要内容,如果未能解决你的问题,请参考以下文章