GPU架构和CUDA简单介绍(未来继续补充)
Posted eecspan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU架构和CUDA简单介绍(未来继续补充)相关的知识,希望对你有一定的参考价值。
参考
- Exploring the GPU Architecture
- GPU vs CPU: What Are The Key Differences?
- Everything You Need to Know About GPU Architecture and How It Has Evolved
- 深入GPU硬件架构及运行机制
- 如何设置CUDA Kernel中的grid_size和block_size?
SIMD和SIMT
-
SISD:单一的指令流执行单一的数据流,即每条指令只能执行其对应的一个数据,也不会有不同的核执行不同的指令流,即只有一个核心。
-
SIMD:该架构只有一个控制单元和一个指令内存,因此同一时刻只能有一条指令被执行,但是这条指令可以同时处理多个数据,类似于指令的操作数不再是针对单个数字,而是针对向量。例如在SISD情境下,如果abc都是四维数据,我们想要执行
c = a + b:ADD c.x, a.x, b.x ADD c.y, a.y, b.y ADD c.z, a.z, b.z ADD c.w, a.w, b.w但是在SIMD下,只需要执行一条指令即可:
SIMD_ADD c, a, b

-
MISD:不同的指令对同一数据进行操作,很少使用。
-
MIMD:指令和数据都可以并行,不同的核心可以对不同的数据执行不同的指令流,可以认为是多个SISD的并行?
-
SIMT:可以认为是SIMD的升级版,同一条指令可以被多个并发线程执行,并且不同线程执行的统一指令,其操作数也可以不同。
Fermi架构

- 有16个SM (Streaming Processor),即上图黑框
- 上图右侧为SM,一个SM拥有:
- 2个Warp,每个Warp有16个Core
- 16组LD/ST(加载处理单元)
- 4个SFU(特殊函数处理单元)
- shared memory
- 每个Warp包括:
- 16个Core
- 一个Warp Scheduler
- 一个Dispatch Unit
- 每个Core(Streaming Processor,SP)包括:
- 一个 INT Unit(整数计算单元、ALU)
- 一个 FP Unit(浮点计算单元)
CUDA
cuda核函数启动时,主要是如下形式:
cuda_kernel<<<grid_size, block_size, Ns, stream>>>(...)
- grid_size:dim3型数据,例如x、y和z,设置了grid的维度。x * y * z就等于启动的blocks的数目。Grid中所有的线程共享global memory。
- blcok_size:dim3型数据,设置了每个block的维度。例如x * y * z就等于每个block包含的线程(thread)数目。block内部的线程可以同步,可以访问shared memory。
- Ns:默认为0,代表在shared memory中,可以为每个block动态申请的memory,大小是字节数。
- stream:就是指明该核函数匹配的stream,默认是0,即GPU中默认的stream。
与GPU架构的联系和层次
- Cuda中的 Thread:就对应GPU中的Core。
- Cuda中的 block:可以认为它可以由多个warp组成,也就是由多个thread构成,但是其不够大过SM,也就是说,一个block中的所有thread,都必须是同一个SM中的,这样才能使用shared memory。
- warp:是调度和运行的基本单元,规定了block中 32个 thread 组成一个 warp,如果最后剩下的thread不够32个,也要占一个warp。因此,block_size最好是32的整数倍。warp中的32个thread每次都会执行同一条指令,也就是SIMT。
- 对于Cuda中的block,其在同一个SM上运行,但是可被调度到不同的SM中。同一个SM可以同时运行多个block(并发执行)。但是SM中的资源有限,例如shared memory或者寄存器,因此有限制:
Maximum number of resident blocks per SM和Maximum number of resident threads per SM。因为有该限制,一个block中的thread数目应该尽量大于SM的core数目/SM最多驻留block数目,不同的架构比值不同,例如对GTX 1080 Ti 是 2048 / 32 = 64。128作为block的通用值比较合适。 - 一个SM可以并行执行多个warp,这主要由一个SM有几个warp scheduler决定。但是这并行执行的多个warp,是只能属于同一个block还是可以属于多个不同的block?似乎可以属于不同的block,感觉有多种说法。
异构计算--CUDA架构
1.CUDA是什么?
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台,是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可以使用GPU来并行完成像神经网络、图像处理算法这些在CPU上跑起来比较吃力的程序。通过GPU和高并行,我们可以大大提高这些算法的运行速度。
2.CPU&CUDA架构
处理器结构有2个指标要经常考虑的:延迟和吞吐。延迟指从发出指令到返回最终结果中间经历的时间间隔;吞吐指单位时间内处理的指令的条数。由于CPU以处理计算和控制为主要任务,所以设计理念是延迟导向内核;由于GPU以并行处理为主要任务,所以设计理念是吞吐导向内核。
(1)CPU
CPU(CentralProcessing Unit)中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control,运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。简单说,就是计算单元、控制单元和存储单元。
架构图如下所示:
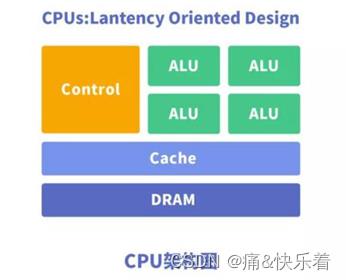
CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算方面受到限制,相对而言更擅长于处理逻辑控制。CPU无法做到大量数据并行计算的能力,但GPU可以。
(2)GPU
GPU(GraphicsProcessing Unit),即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,早先由CPU中分出来专门用于处理图像并行计算数据,专为同时处理多重并行计算任务而设计。GPU中也包含基本的计算单元、控制单元和存储单元,但GPU的架构与CPU有很大不同,其架构图如下所示。
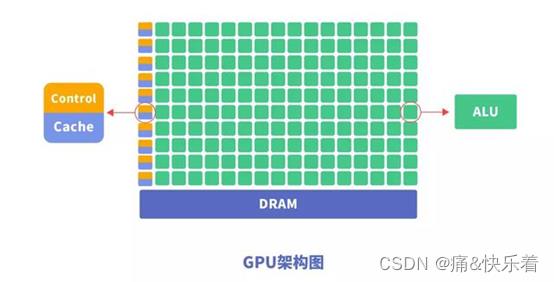
与CPU相比,CPU芯片空间的不到20%是ALU,而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。这就是为什么GPU可以具备强大的并行计算能力的原因。
从硬件架构分析来看,CPU和GPU似乎很像,都有内存、Cache、ALU、CU,都有着很多的核心,但是CPU的核心占比比较重,相对计算单元ALU很少,可以用来处理非常复杂的控制逻辑,预测分支、乱序执行、多级流水任务等等。相对而言GPU的核心就是比较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。
简单来说就是CPU的核心擅长完成多重复杂任务,重在逻辑,重在串行程序;GPU的核心擅长完成具有简单的控制逻辑的 任务,重在计算,重在并行。
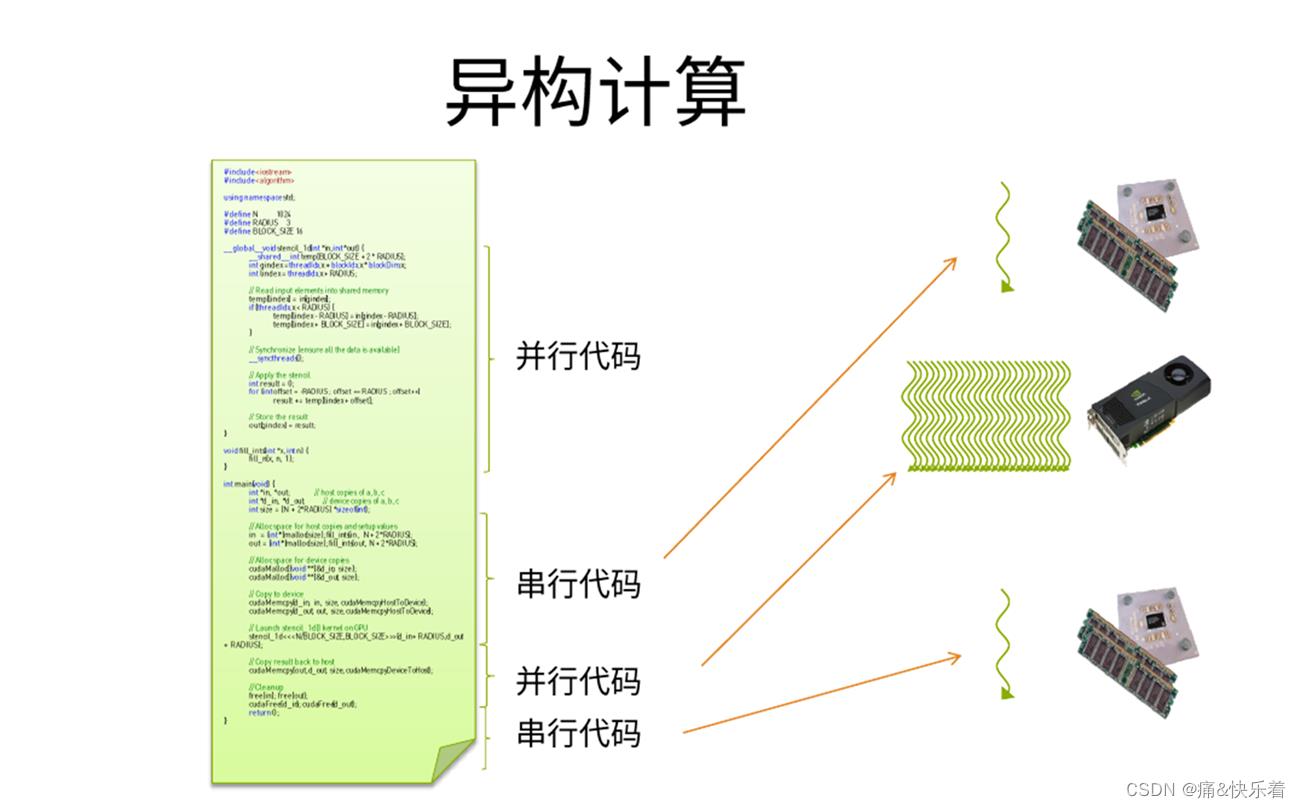
3.异构计算
所谓异构计算,是指CPU+ GPU或者CPU+ 其它设备(如FPGA等)协同计算。⼀般我们的程序,是在CPU上计算。但是,当⼤量的数据需要计算时,CPU显得⼒不从⼼。那么,是否可以找寻其它的⽅法来解决计算速度呢?那就是异构计算。例如可利⽤CPU(Central Processing Unit)、GPU(Graphic Processing Unit)、甚⾄APU(Accelerated Processing Units, CPU与GPU的融合)等计算设备的计算能⼒从⽽来提⾼系统的速度。异构系统越来越普遍,对于⽀持这种环境的计算⽽⾔,也正受到越来越多的关注。
⽬前异构计算使⽤最多的是利⽤GPU来加速。主流GPU都采⽤了统⼀架构单元,凭借强⼤的可编程流处理器阵容,GPU在单精度浮点运算⽅⾯将CPU远远甩在⾝后。如图所示为CPU+GPU异构计算的一个示意图,其中GPU主要负责并行计算。
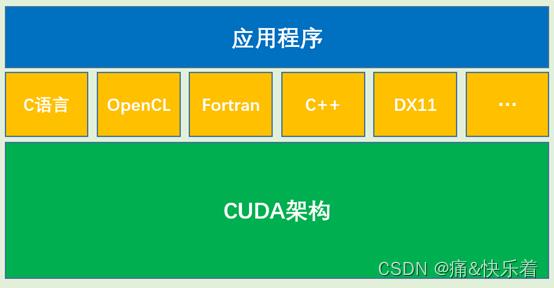
4.OpenCL与CUDA的关系
NVIDIA的CUDA架构和KHRONOS制定的OpenCL并不冲突,他们之间的关系是API与执行架构之间的关系,举个简单的例子:我们熟悉的X86架构是一种CPU架构,而各种编程语言,如:汇编语言、C语言等低级语言或高级语言仅仅是建立在X86运算架构之上的一种编程环境。那么,CUDA架构和OpenCL之间的关系和X86与编程语言的关系是相同的。
CUDA架构是OpenCL的运行平台之一,因此他们之间并不存在谁取代谁的关系。OpenCL仅仅是为CUDA架构提供了一个可编程的API而已。
参考原文
[1]http://t.zoukankan.com/liuyufei-p-13259264.html
以上是关于GPU架构和CUDA简单介绍(未来继续补充)的主要内容,如果未能解决你的问题,请参考以下文章