主成分分析(PCA)及其可视化——python
Posted 洋洋菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主成分分析(PCA)及其可视化——python相关的知识,希望对你有一定的参考价值。
可以看看这个哦python入门:Anaconda和Jupyter notebook的安装与使用_菜菜笨小孩的博客-CSDN博客
如果你学会了python 可以看看matlab的哦
主成分分析(PCA)及其可视化——matlab_菜菜笨小孩的博客-CSDN博客
目录
一、主成分分析的原理
主成分分析是利用降维的思想,在损失很少信息的前提下把多个指标转化为几个综合指标的多元统计方法。通常把转化生成的综合指标称之为主成分,其中每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,这就使得主成分比原始变量具有某些更优越的性能。这样在研究复杂问题时就可以只考虑少数几个主成分而不至于损失太多信息,从而更容易抓住主要矛盾,揭示事物内部变量之间的规律性,同时使问题得到简化,提高分析效率。
主成分分析正是研究如何通过原来变量的少数几个线性组合来解释原来变量绝大多数信息的一种多元统计方法。
二、主成分分析步骤
1.主成分分析的步骤:
1.根据研究问题选取初始分析变量;
2.根据初始变量特性判断由协方差阵求主成分还是由相关阵求主成分(数据标准化的话需要用系数相关矩阵,数据未标准化则用协方差阵);
3.求协差阵或相关阵的特征根与相应标准特征向量;
4.判断是否存在明显的多重共线性,若存在,则回到第一步;
5.主成分分析的适合性检验
6.得到主成分的表达式并确定主成分个数,选取主成分;
7.结合主成分对研究问题进行分析并深入研究。
2.部分说明
一组数据是否可以用主成分分析,必须做适合性检验。可以用球形检验和KMO统计量检验。(1)球形检验(Bartlett)
球形检验的假设:
H0:相关系数矩阵为单位阵(即变量不相关)
H1:相关系数矩阵不是单位阵(即变量间有相关关系)
2)KMO(Kaiser-Meyer-Olkin)统计量
KMO统计量比较样本相关系数与样本偏相关系数,它用于检验样本是否适于作主成分分析。
KMO的值在0,1之间,该值越大,则样本数据越适合作主成分分析和因子分析。一般要求该值大于0.5,方可作主成分分析或者相关分析。
Kaiser在1974年给出了经验原则:
0.9以上 适合性很好
0.8~0.9 适合性良好
0.7~0.8 适合性中等
0.6~0.7 适合性一般
0.5~0.6 适合性不好
0.5以下 不能接受的
(3)主成分分析的逻辑框图
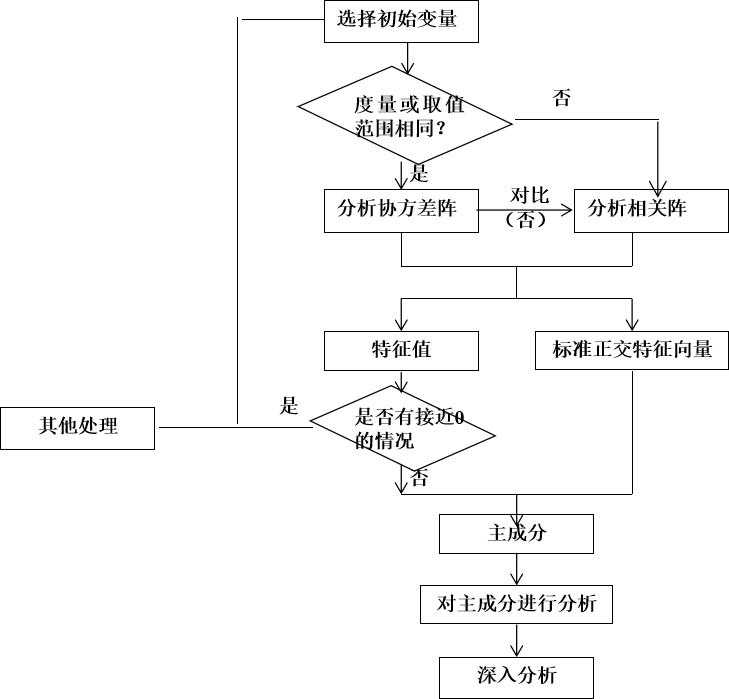
三、所用到的库 factor_analyzer库
1. pandas
pip instal pandas2.numpy
pip install numpy3.matplotlib
pip install matplotlib四、案例实战
1.数据集
数据集aa.xls - 蓝奏云 不能直接分享csv文件
2.导入库
导入数据处理和分析所需要的库:
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt3.读取数据集
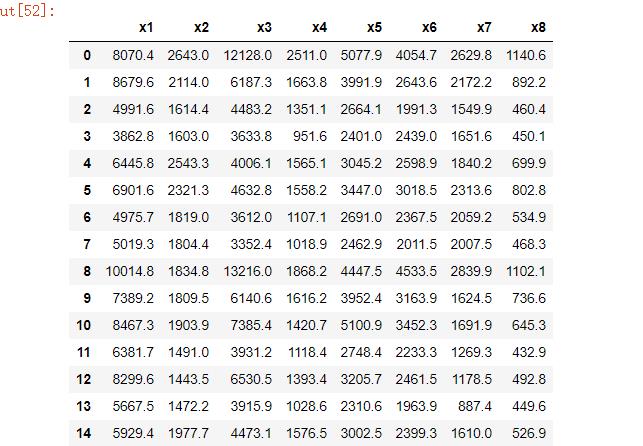
df = pd.read_csv(r"D:\\桌面\\aa.csv", encoding='gbk', index_col=0).reset_index(drop=True)
df运行结果:
4.进行球状检验
检验总体变量的相关矩阵是否是单位阵(相关系数矩阵对角线的所有元素均为1,所有非对角线上的元素均为零);即检验各个变量是否各自独立。
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
print(chi_square_value, p_value)运行结果:

5.KMO检验
检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# KMO检验
# 检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# 通常取值从0.6开始进行因子分析
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(df)
print(kmo_all)运行结果:

6.求相关矩阵
(1)数据标准化做法
1.进行标准化
用到了 preprocessing 库
怎么导入:
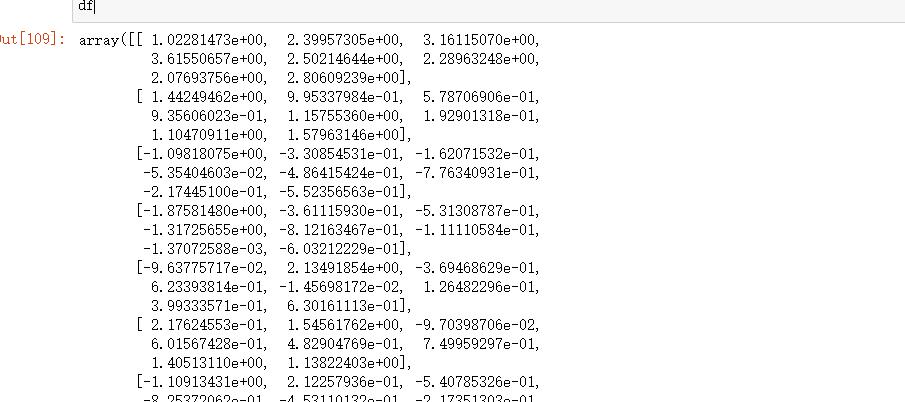
from sklearn import preprocessing标准化代码:
df = preprocessing.scale(df)
df结果:
2.求相关系数矩阵
为了方面下面引用,就和协方差阵的赋值符号一样了!!
covX = np.around(np.corrcoef(df.T),decimals=3)
covX运行结果:
 3.求解特征值和特征向量
3.求解特征值和特征向量
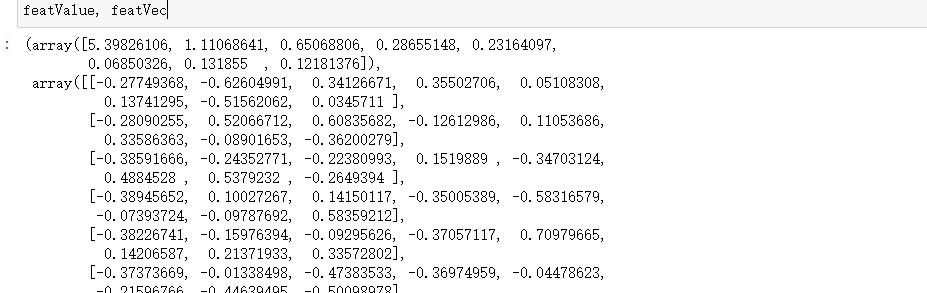
featValue, featVec= np.linalg.eig(covX.T) #求解系数相关矩阵的特征值和特征向量
featValue, featVec运行结果:
(2)数据不标准化做法
1.求均值
def meanX(dataX):
return np.mean(dataX,axis=0)#axis=0表示依照列来求均值。假设输入list,则axis=1
average = meanX(df)
average运行结果:

2.查看列数和行数
m, n = np.shape(df)
m,n运行结果:

3.写出同数据集一样的均值矩阵
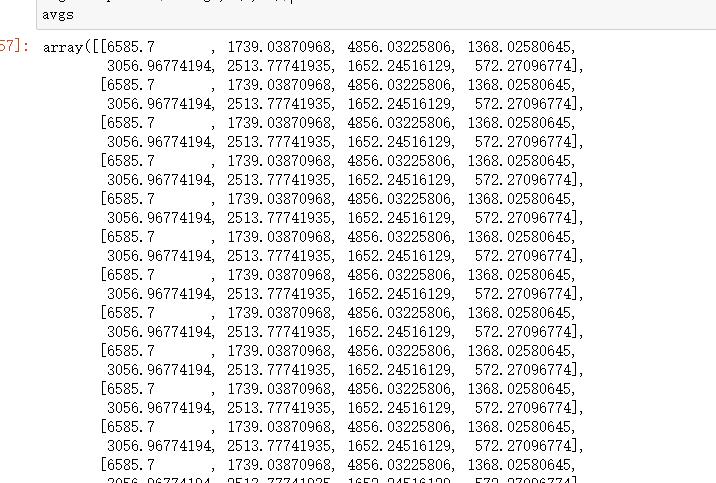
data_adjust = []
avgs = np.tile(average, (m, 1))
avgs运行结果:
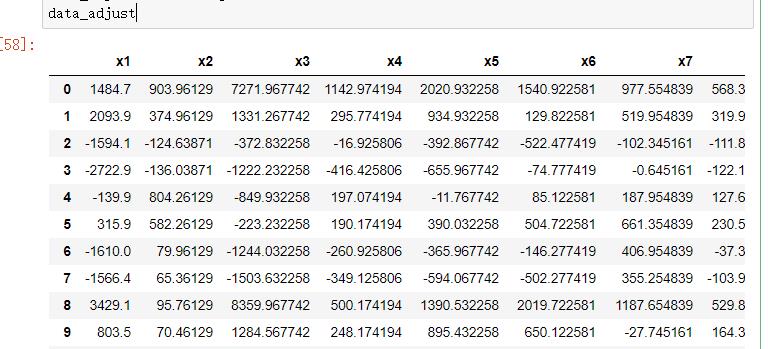
4.对数据集进行去中心化
data_adjust = df - avgs
data_adjust运行结果:
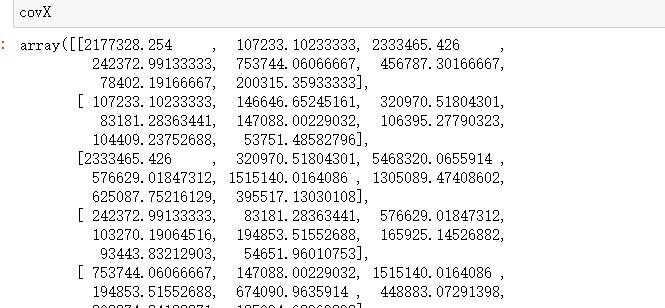
5.计算协方差阵
covX = np.cov(data_adjust.T) #计算协方差矩阵
covX运行结果:
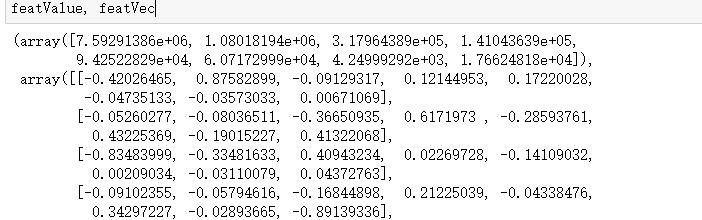
6.计算协方差阵的特征值和特征向量
featValue, featVec= np.linalg.eig(covX) #求解协方差矩阵的特征值和特征向量
featValue, featVec运行结果:
下面的做法不再区分标不标准化了,你上面用哪种都行
在这里仅拿为标准化做法的数据进行下面操作!!!
7.对特征值进行排序并输出 降序
featValue = sorted(featValue)[::-1]
featValue运行结果:

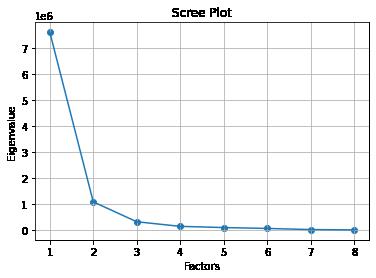
8.绘制散点图和折线图
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), featValue)
plt.plot(range(1, df.shape[1] + 1), featValue)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形运行结果:
9.求特征值的贡献度
gx = featValue/np.sum(featValue)
gx运行结果:

10.求特征值的累计贡献度
lg = np.cumsum(gx)
lg运行结果:

11.选出主成分
#选出主成分
k=[i for i in range(len(lg)) if lg[i]<0.85]
k = list(k)
print(k)运行结果:

12.选出主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVe=selectVec*(-1)
selectVec运行结果:

13.求主成分得分
finalData = np.dot(data_adjust,selectVec)
finalData运行结果:
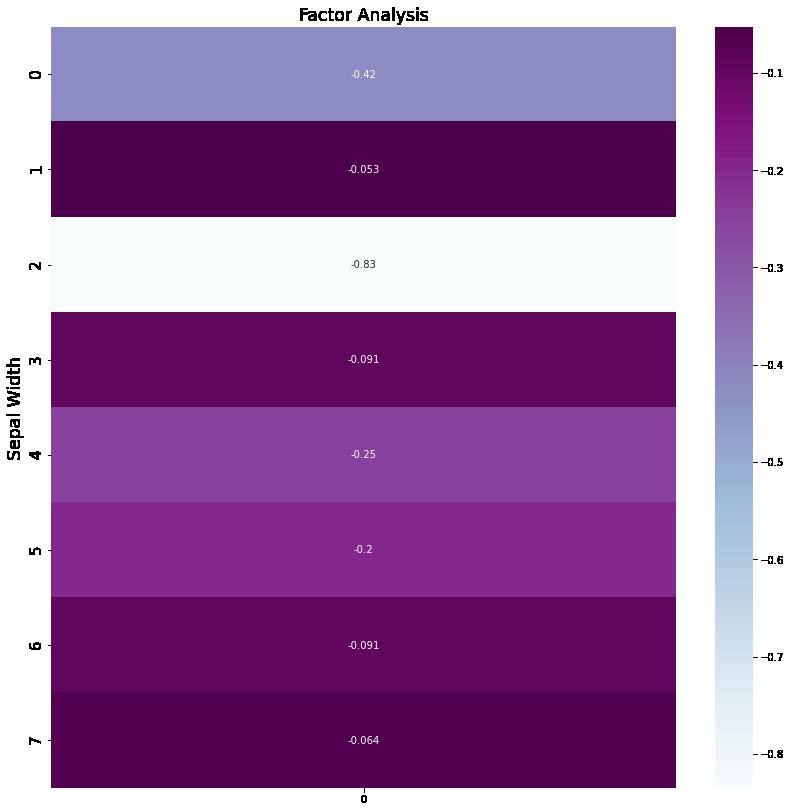
14.绘制热力图
# 绘图
plt.figure(figsize = (14,14))
ax = sns.heatmap(selectVec, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)运行结果:
完整代码:
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv(r"D:\\桌面\\aa.csv", encoding='gbk', index_col=0).reset_index(drop=True)
print(df)
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
print(chi_square_value, p_value)
# KMO检验
# 检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# 通常取值从0.6开始进行因子分析
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(df)
print(kmo_all)
# #标准化
# #所需库
# from sklearn import preprocessing
# #进行标准化
# df = preprocessing.scale(df)
# print(df)
# #求解系数相关矩阵
# covX = np.around(np.corrcoef(df.T),decimals=3)
# print(covX)
# #求解特征值和特征向量
# featValue, featVec= np.linalg.eig(covX.T) #求解系数相关矩阵的特征值和特征向量
# print(featValue, featVec)
#不标准化
#均值
def meanX(dataX):
return np.mean(dataX,axis=0)#axis=0表示依照列来求均值。假设输入list,则axis=1
average = meanX(df)
print(average)
#查看列数和行数
m, n = np.shape(df)
print(m,n)
#均值矩阵
data_adjust = []
avgs = np.tile(average, (m, 1))
print(avgs)
#去中心化
data_adjust = df - avgs
print(data_adjust)
#协方差阵
covX = np.cov(data_adjust.T) #计算协方差矩阵
print(covX)
#计算协方差阵的特征值和特征向量
featValue, featVec= np.linalg.eig(covX) #求解协方差矩阵的特征值和特征向量
print(featValue, featVec)
####下面没有区分#######
#对特征值进行排序并输出 降序
featValue = sorted(featValue)[::-1]
print(featValue)
#绘制散点图和折线图
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), featValue)
plt.plot(range(1, df.shape[1] + 1), featValue)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形
#求特征值的贡献度
gx = featValue/np.sum(featValue)
print(gx)
#求特征值的累计贡献度
lg = np.cumsum(gx)
print(lg)
#选出主成分
k=[i for i in range(len(lg)) if lg[i]<0.85]
k = list(k)
print(k)
#选出主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVe=selectVec*(-1)
print(selectVec)
#主成分得分
finalData = np.dot(data_adjust,selectVec)
print(finalData)
#绘制热力图
plt.figure(figsize = (14,14))
ax = sns.heatmap(selectVec, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)总结:
几经周转终于完成了matlab和python的主成分分析,也学到了很多,也体会到了完成时的成就感
本文中遇到的问题,矩阵相乘,只能两两相乘,索引方式区别于matlab,但也有很多库类似,比如 cumsum python需调用numpy库使用,等等,如果本文有错误请大家多多指正,谢谢!!!
主成分分析(PCA)
参考技术A在前面我们学习了一种有监督的降维方法——线性判别分析(Linear Dscriminant Analysis,LDA)。LDA不仅是一种数据压缩方法还是一种分类算法,LDA将一个高维空间中的数据投影到一个低维空间中去,通过最小化投影后各个类别的类内方差和类间均值差来寻找最佳的投影空间。
本文介绍的主成分分析(Principe Component Analysis,PCA)也是一种降维技术,与LDA不同的是,PCA是一种无监督降维技术,因此PCA的主要思想也与LDA不同。LDA是一种有监督的分类兼降维技术,因此其最大化均值差最小化类内差的思想够保证在降维后各个类别依然能够很好地分开。但PCA只用来降维而无需分类,因此PCA需要考虑的是如何在降维压缩数据后尽可能的减少数据信息的损失。在PCA中使用协方差来表示信息量的多少,至于为什么能这么表示后面再进行介绍。下面我们从一些基本的线代知识开始。
在进行数据分析时我们的数据样本经常被抽象为矩阵中的一组向量,了解一些线代基础知识理解PCA非常重要,但在这里我们并不准备也不可能将所有的线代知识都罗列以便,因此这里我们仅会复习一些对理解PCA较为重要的东西。更多线代的内容可参考下面几个链接:
为了方便,我们这里以一个二维平面为例。
在前面我们说了,在数据处理时我们经常讲一个样本数据当作一个向量。在二维平面中,一个向量从不同的角度有不同的理解方式,例如对于向量 (-2, 3) T :
在我们描述任何东西的时候其实都是选择了一个参照系的,也即事物都是相对的,最简单的运动与静止(以静止的事物为参照),说一个有点意思的——人,人其实也是放在一个参考系中的,我们可以将其理解为生物种类系统,抛开这个大的系统去独立的定义人是很难让人理解的。向量也是这样的,虽然我们前面没有指明,但是上面的向量其实是在一个默认坐标系(或称为空间)中的,也即x,y轴,但是在线性代数中我们称其为基。在线代中任何空间都是由一组线性无关的(一维空间由一个基组成)基向量组成。这些基向量可以组成空间中的任何向量。
现在假设我们有如下一个矩阵相乘的式子:
因此,上面的例子可以有两种理解方式:
(1)如果我们将值全为1对角方阵视为标准坐标系,则它表示在 i=(1, -2) T 和 j=(3, 0) T 这组基底下的坐标 (-1, 2) T 在基底 (1, 0) T 、(0, 1) T 下的坐标,如下:
当我们讨论向量 (-1, 2) T 时,都隐含了一个默认的基向量假设:沿着x轴方向长度为1的 i,沿着y轴长度为1的j。
但是,(-1, 2) T 可以是任何一组基底下的向量。例如,他可能是i\'=(2,1) T , j\'=(-1, 1) T 这组基下的一个向量。此时他在我们默认坐标系 i=(1, 0) T ,j=(0, 1) T 下的计算过程如下:
我们可以从另一个角度理解基地变换的过程:我们先 误认为 (-1, 2) T 是坐标系i=(1, 0) T ,j=(0, 1) T 下的坐标,此时我们通过线性变换[[2, -1], [1, 1]](每个嵌套列表看做一行)把坐标轴i,j(基坐标)分别变换到了新的位置 i1=(2, 1) T , j1=(-1, 1) T (他们也是用默认坐标系表示的),即[2, -1], [1, 1]]。此时我们把“误解”转换成了真正的向量。如下:
在上面我们说了矩阵是一种变换,现在我们继续从这个角度来理解特征值和特征向量。为了方便理解,我们在这里做一个类比——将变换看作物理中的作用力。我们知道一个力必须有速度和方向,而矩阵对一个向量施加的变换也是一样的。考虑一下特征向量的定义:
上面介绍了一些基本的线性代数相关的知识,下面开始介绍PCA的原理。
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。
为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0(这样做的道理和好处后面会看到)。中心化的数据为:
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
以上图为例,可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠。所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述这个问题。
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。 从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m。
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标: 将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
然后我们用X乘以X的转置,并乘上系数1/m:
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设C=1/m(XX T ),则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的 。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为P对X做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。
由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λ重数为r,则必然存在r个线性无关的特征向量对应于λ,因此可以将这r个特征向量单位正交化。
则对协方差矩阵C有如下结论:
以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
到这里,我们发现我们已经找到了需要的矩阵P:P = E T .
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照Λ中特征值的从大到小,将特征向量从上到下排列,则用P的前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
PCA的特征向量的求解除了使用上述最大化方差的矩阵分解方法,还可以使用最小化损失法,具体可参见: 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA) 。
总结一下PCA的算法步骤:
设有m条n维数据。
LDA和PCA都用于降维,两者有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
我们接着看看不同点:
参考:
PCA的数学原理
线性代数的直觉
线性判别分析LDA原理总结
以上是关于主成分分析(PCA)及其可视化——python的主要内容,如果未能解决你的问题,请参考以下文章