gan算法不包括以下哪个模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gan算法不包括以下哪个模型相关的知识,希望对你有一定的参考价值。
不管何种模型,其损失函数(Loss Function)选择,将影响到训练结果质量,是机器学习模型设计的重要部分。对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数却是不容易定义的。2014年GoodFellow等人发表了一篇论文“Goodfellow, Ian, et al. Generative adversarial nets." Advances inNeural Information Processing Systems. 2014”,引发了GAN生成式对抗网络的研究,值得学习和探讨。今天就跟大家探讨一下GAN算法。
GAN算法概念:
对于生成结果的期望,往往是一个难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。于是Goodfellow等人将机器学习中的两类模型(G、D模型)紧密地联合在了一起(该算法最巧妙的地方!)。
一个优秀的GAN模型应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出结果不理想。
GAN算法原理:
1.先以生成图片为例进行说明:
1)G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
3)在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
4)这样目的就达成了:得到了一个生成式的模型G,它可以用来生成图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而判别网络D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
2.再以理论抽象进行说明:
GAN是一种通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5(D判断不出真假,50%概率,跟抛硬币决定一样)。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔科夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估,证明了GAN框架的潜在优势。
Goodfellow从理论上证明了该算法的收敛性。在模型收敛时,生成数据和真实数据具有相同分布,从而保证了模型效果。
GAN公式形式如下:
GAN公式说明如下:
1)公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片;
2)D(x)表示D网络判断图片是否真实的概率,因为x就是真实的,所以对于D来说,这个值越接近1越好。
3)G的目的:D(G(z))是D网络判断G生成的图片的是否真实的概率。G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此公式的最前面记号是min_G。
4)D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大max_D。
GAN训练过程:
GAN通过随机梯度下降法来训练D和G。
1)首先训练D,D希望V(G, D)越大越好,所以是加上梯度(ascending)
2)然后训练G时,G希望V(G, D)越小越好,所以是减去梯度(descending);
3) 整个训练过程交替进行。
GAN训练具体过程如下:
GAN算法优点:
1)使用了latent code,用以表达latent dimension、控制数据隐含关系等;
2)数据会逐渐统一;
3)不需要马尔可夫链;
4)被认为可以生成最好的样本(不过没法鉴定“好”与“不好”);
5)只有反向传播被用来获得梯度,学习期间不需要推理;
6)各种各样的功能可以被纳入到模型中;
7)可以表示非常尖锐,甚至退化的分布。
GAN算法缺点:
1)Pg(x)没有显式表示;
2)D在训练过程中必须与G同步良好;
3)G不能被训练太多;
4)波兹曼机必须在学习步骤之间保持最新。
GAN算法扩展:
GAN框架允许有许多扩展:
1)通过将C作为输入,输入G和D,可以得到条件生成模型P(x|c);
2)学习近似推理,可以通过训练辅助网络来预测Z。
3)通过训练一组共享参数的条件模型,可以近似地模拟所有条件。本质上,可以使用对抗性网络实现确定性MP-DBM的随机扩展。
4)半监督学习:当仅有有限标记数据时,来自判别器或推理网络的特征可以提高分类器的性能。
5)效率改进:通过划分更好的方法可以大大加快训练,更好的方法包括:a)协调G和D; b) 在训练期间,确定训练样本Z的更好分布。
GAN算法应用:
GAN的应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域。
1)图像生成:
目前GAN最常使用的地方就是图像生成,如超分辨率任务,语义分割等。
2)数据增强:
用GAN生成的图像来做数据增强。主要解决的问题是a)对于小数据集,数据量不足,可以生成一些数据;b)用原始数据训练一个GAN,GAN生成的数据label不同类别。
结语:
GAN生成式对抗网络是一种深度学习模型,是近年来复杂分布上无监督学习最具有前景的方法之一,值得深入研究。GAN生成式对抗网络的模型至少包括两个模块:G模型-生成模型和D模型-判别模型。两者互相博弈学习产生相当好的输出结果。GAN算法应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域 参考技术A 不管何种模型,其损失函数(Loss Function)选择,将影响到训练结果质量,是机器学习模型设计的重要部分。对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数却是不容易定义的。
2014年GoodFellow等人发表了一篇论文“Goodfellow, Ian, et al. Generative adversarial nets." Advances inNeural Information Processing Systems. 2014”,引发了GAN生成式对抗网络的研究,值得学习和探讨。今天就跟大家探讨一下GAN算法。
GAN算法概念:
对于生成结果的期望,往往是一个难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。于是Goodfellow等人将机器学习中的两类模型(G、D模型)紧密地联合在了一起(该算法最巧妙的地方!)。
一个优秀的GAN模型应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出结果不理想。
GAN算法原理:
1.先以生成图片为例进行说明:
1)G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
3)在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
4)这样目的就达成了:得到了一个生成式的模型G,它可以用来生成图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而判别网络D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
Facebook发布史上最强GAN模型
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
GAN模型好是好,但就是对训练数据的要求太高,并且在场景和物体的语义组合时容易出现不合常理的生成图像,导致一眼假!最近Facebook发布了一个IC-GAN模型,迁移能力号称史上最强,能把各种场景和物体组合起来,训练集中没出现过的也能完美复原!甚至把雪地和骆驼放一起都毫无违和感!
生成对抗网络 (GAN) 在图像生成领域可以说是最强大的 AI 模型,无论是逼真的图片、抽象的拼贴画、风格迁移都不在话下。
但GAN 也有神经网络模型所共有的致命缺点,就是具有局限性,通常只能生成与训练数据集密切相关的物体或场景的图像。
例如,在汽车图像上训练的 GAN 在生成汽车相关图像时可以做到特别逼真,但可能让它生成鲜花、动物之类的模型就会一眼假,因为生成的图像可能会违反物理常识等。

Facebook AI Research 为了解决这个问题,提出了一个新模型Instance-Conditioned GAN (IC-GAN) ,可以生成逼真的、没有见过的图像组合。

https://arxiv.org/abs/2109.05070
例如雪和骆驼这种照片或者在城市中的斑马,可以无缝衔接起来。

目前代码已经开源。
研究人员从核密度估计(kernel density estimation, KDE)技术中得到启发,引入了一种非参数化方法来建模复杂数据集的分布。KDE是一种非参数密度估计器,以参数化核的混合形式对每个训练数据点周围的密度进行建模。

IC-GAN可以看作是一种混合密度估计器,其中每个分量都是通过对训练实例进行条件化得到的。
然而与KDE不同的是,IC-GAN 没有显式地对数据概率进行建模,而是采用了一种对抗性的方法,其中我们使用一个神经网络隐式地对局部密度进行建模,该神经网络将条件实例和噪声向量作为输入。
因此,IC-GAN中的内核不再独立于我们所处理的数据点,我们通过选择实例的邻域大小来控制平滑度,而不是内核带宽参数,我们从中采样真实样本以馈送到鉴别器。
IC-GAN 将数据流形划分为由数据点及其最近邻描述的重叠邻域的混合物,IC-GAN模型能够学习每个数据点周围的分布。通过在条件实例周围选择一个足够大的邻域,可以避免将数据过度划分为小的聚类簇。
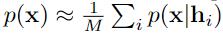
当给定一个具有M个数据样本的未标记数据集的嵌入函数f,首先使用无监督或自我监督训练得到f来提取实例特征(instance features)。
然后使用余弦相似度为每个数据样本定义k个最近邻的集合。
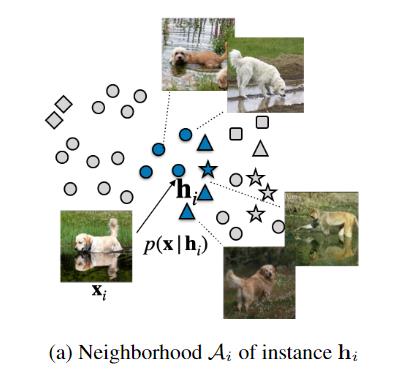
使用生成器隐式地模拟条件分布p(x | hi) 时,生成器从单位高斯先验z∼ N(0, 1)变换样本从条件分布中抽取样本x,其中hi是从训练数据中抽取的实例xi的特征向量。
在IC-GAN中,采用对抗式方法来训练生成器,因此生成器与判别器可以联合训练,判别器用来区分hi的真实相邻节点和生成的相邻点。对于每个hi,真实邻居都从Ai中均匀采样。
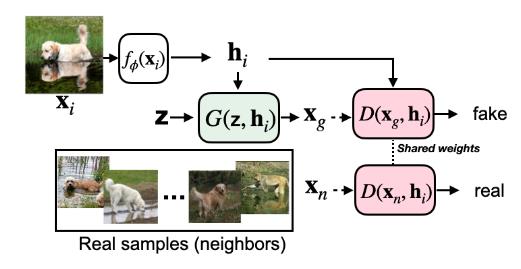
生成器 G和判别器 D都参与了一个两人最小-最大博弈,在博弈中,二者试图找到目标的纳什均衡的等式。

在训练IC-GAN时,使用所有可用的训练数据点来微调模型。在推理时,与KDE等非参数密度估计方法一样,IC-GAN的生成器也需要实例特征,这些特征可能来自于训练分布或不同的分布。
并且这种方法可以扩展到具有类条件(class condition)的生成上。通过在类标签y上添加一个额外的生成器和判别器,可以让IC-GAN 用于有类条件的生成。IC-GAN 通过向生成器和判别器提供实例的表示作为额外的输入,并通过使用实例的邻居作为鉴别器的真实样本,学习对数据点(也称为实例)的邻域的分布建模。
与对离散簇索引进行条件处理不同,对实例表示进行条件处理自然会导致生成器为相似实例生成相似样本。并且一旦训练完成,IC-GAN可以通过在推理时简单地交换条件实例,轻松地迁移到训练期间未看到的其他数据集。
实验部分研究人员使用了ImageNet和COCO Stuff数据集,实验结果表明,与无条件模型和无监督数据分割基线相比,IC-GAN显著提高了性能。
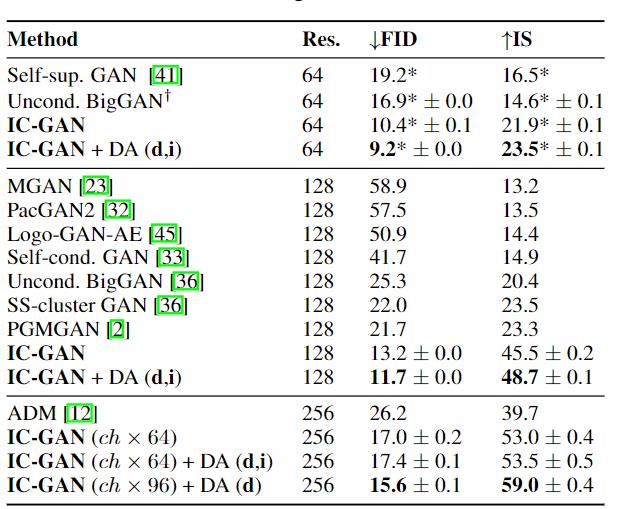
非选择性的基线模型BigGAN 是通过将训练集中的所有标签设置为零来训练的,IC-GAN在FID和IS分数方面均以64×64和128×128分辨率超过了所有以前的方法,并可以在高分辨率下生成更高的质量的图像。

在进行迁移实验时,首先使用ImageNet上使用BigGAN架构训练IC-GAN,并在测试时使用COCO Stuff实例生成图像,这种数据分割模式都包含未见过的对象组合方式。在ImageNet上训练的IC-GAN在所有分割方面都优于在COCO Stuff上训练的相同模型:在128分辨率下8.5比16.8训练FID。

为了研究ImageNet和COCO Stuff数据分布的接近程度,研究人员以128×128分辨率计算了两个数据集的实际数据序列分割之间的FID 得分为37.2。
因此,IC-GAN的显著迁移能力不能用数据集的相似性来解释,而可以归因于ImageNet预先训练的特征提取器和生成器的有效性。
将COCO Stuff中的条件实例替换为ImageNet中的条件实例时,可以得到43.5的训练FID分数,强调了通过改变条件实例可以实现的重要分布迁移。
研究人员将IC-GAN扩展到类条件情况,并在ImageNet上显示语义可控生成和可比的量化结果。
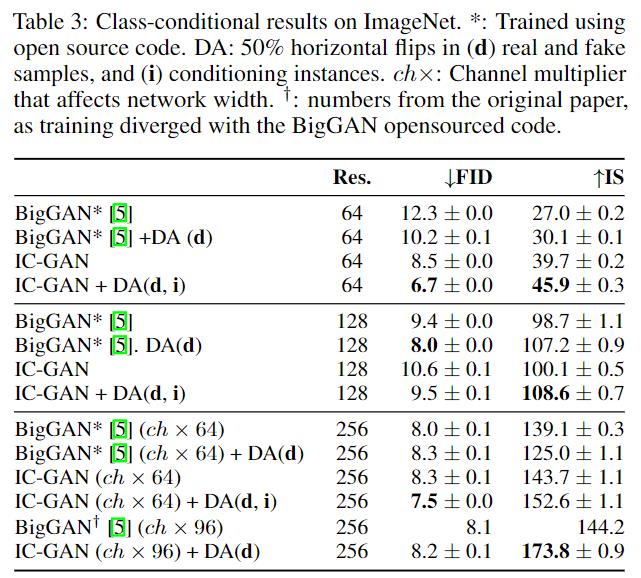
类条件IC-GAN在FID和所有分辨率方面都优于BigGAN,除了FID在128×128分辨率下的分数。与BigGAN不同,IC-GAN可以通过固定实例特征和交换类条件,或者通过固定类条件和交换实例特征来控制生成图像的语义。

生成的图像保留了类标签和实例的语义,可以在相似的背景下生成不同的狗品种,或在雪地中生成骆驼,在ImageNet中属于未知场景。
凭借这些新功能,IC-GAN 可用于创建新的视觉示例,以扩充数据集以包含不同的对象和场景;为艺术家和创作者提供更广泛、更有创意的 AI 生成内容;并推进高质量图像生成的研究。
参考资料:
https://ai.facebook.com/blog/instance-conditioned-gans/
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于gan算法不包括以下哪个模型的主要内容,如果未能解决你的问题,请参考以下文章
tflearn kears GAN官方demo代码——本质上GAN是先训练判别模型让你能够识别噪声,然后生成模型基于噪声生成数据,目标是让判别模型出错。GAN的过程就是训练这个生成模型参数!!!(代码