DPCM预测编码
Posted BeatriceDluberry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DPCM预测编码相关的知识,希望对你有一定的参考价值。
基本原理
预测编码本质上利用了信源相邻符号之间的相关性,即根据某一模型利用以往的样本值对新样本进行预测,然后将样本的实际值与其预测值相减得到一个误差值,最后对这一误差值进行编码。这种编码方式很适用于去除图像或视频这样的信源的空间冗余,即每一帧相邻的像素之间有着较强的相关性,相邻像素的像素值相差并不大。
DPCM
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示
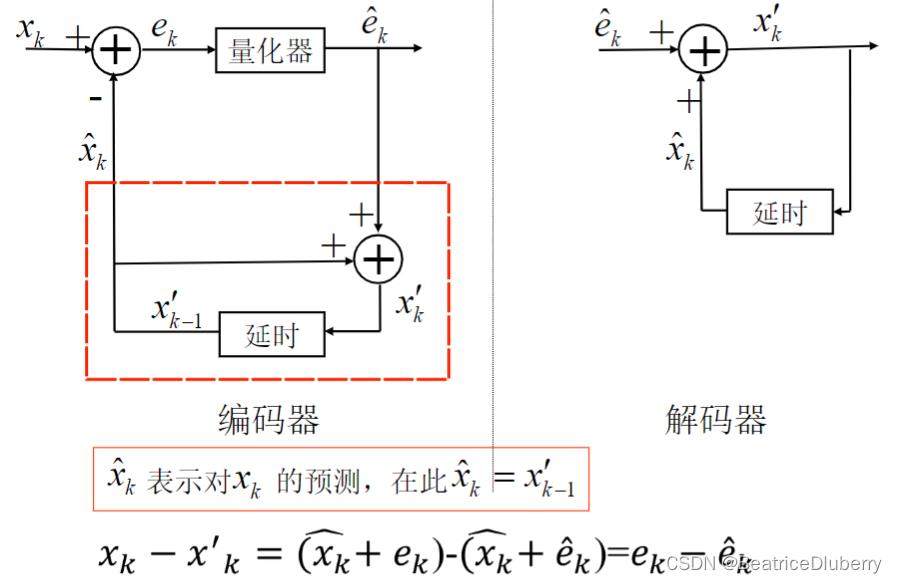
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
PSNR
为了便于我们对实验结果进行定量分析,先简单介绍一下PSNR(Peak Signal to Noise Ratio,峰值信号噪声比)。
计算均方误差 MSE(Mean Square Error):
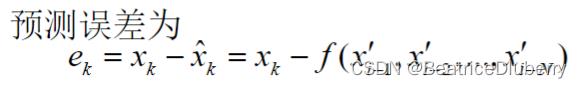
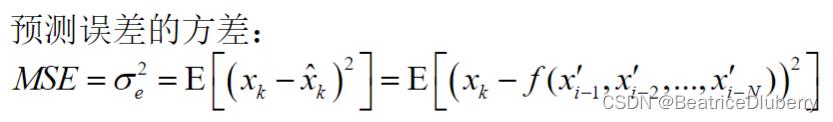
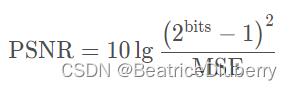
其中bits为原图像地量化比特数。
一般来说:
PSNR ≥ 40 dB时,图像质量非常好,接近于原图像;
30 dB ≤ PSNR < 40 dB 时,图像有人眼可察的失真,但质量尚可;
20 dB ≤ PSNR < 30 dB 时,图像质量较差;
PSNR < 20 dB 时,图像质量人眼无法接受。
Huffman编码
Huffman是一种无失真信源编码算法,编码后可以得到即时的最佳码。我们直接调用现有Huffman编码程序,将原图像及量化后的预测误差图像进行压缩编码。
代码实现
实现内容包括如下:
输入图片,根据给定的量化比特数进行量化和预测
void DpcmEncoding(unsigned char* yBuff, unsigned char* qPredErrBuff, unsigned char* reconBuff, int qBits)
int prediction;
int predErr; // 预测误差
int invPredErr; // 量化预测误差的逆量化值
for (int i = 0; i < h; i++)
prediction = 128; //预测每行的第一个像素集为128
predErr = yBuff[i * w] - prediction; // 预出错域为 [-128, 128] (8-bit)
int temp = (predErr + 128) / pow(2, 8 - qBits); // qBits-bit 量化
// (predErr + 128) with the domain of [0, 256]
qPredErrBuff[i * w] = PixelOverflow(temp, 0, pow(2, qBits) - 1);
invPredErr = qPredErrBuff[i * w] * pow(2, 8 - qBits) - 128; // 逆量化
reconBuff[i * w] = PixelOverflow(invPredErr + prediction, 0, 255); // 重建量化级别
for (int j = 1; j < w; j++) // 从每行的第二个像素开始
prediction = reconBuff[i * w + j - 1]; // 设置为预测的上一个像素值
predErr = yBuff[i * w + j] - prediction; // predErr with the domain of [-255, 255] (9-bit)
int temp = (predErr + 255) / pow(2, 9 - qBits); // qBits-bit 量化
// (predErr + 255) with the domain of [0, 510]; [0, 2^(qBits) - 1] after division
qPredErrBuff[i * w + j] = PixelOverflow(temp, 0, (pow(2, qBits) - 1)); // (predErr + 255) with the domain of [0, 255]
invPredErr = qPredErrBuff[i * w + j] * pow(2, 9 - qBits) - 255;
reconBuff[i * w + j] = PixelOverflow(invPredErr + prediction, 0, 255); // 重建级别
同时输出预测误差图像和重建图像,计算:
原图像的概率分布和熵;预测误差图像的概率分布和熵;重建图像的PSNR
void PrintPMF_Entropy(unsigned char* buffer, int qBits, const char* pmfFileName, const char* entrFileName)
int count[256] = 0 ; // 计数器
double freq[256] = 0 ; // 频率
double entropy = 0;
/* 计算每个灰度的频率 */
for (int i = 0; i < w * h; i++)
int index = (int)buffer[i];
count[index]++;
/* 计算PMF和熵 */
for (int i = 0; i < 256; i++)
freq[i] = (double)count[i] / (w * h);
if (freq[i] != 0)
entropy += (-freq[i]) * log(freq[i]) / log(2);
/* 将统计数据输出到csv文件中 */
FILE* pmfFilePtr;
FILE* entrFilePtr;
if (fopen_s(&pmfFilePtr, pmfFileName, "wb") == 0)
cout << "Successfully opened \\"" << pmfFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << pmfFileName << "\\".\\n";
exit(-1);
if (fopen_s(&entrFilePtr, entrFileName, "ab") == 0)
cout << "Successfully opened \\"" << entrFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << entrFileName << "\\".\\n";
exit(-1);
fprintf(pmfFilePtr, "Symbol,Frequency\\n");
for (int i = 0; i < 256; i++)
fprintf(pmfFilePtr, "%-3d,%-8.2e\\n", i, freq[i]); // 将数据输出到文件中(csv文件以“,”作为分隔符)
fprintf(entrFilePtr, "%d,%.4lf\\n", qBits, entropy);
fclose(pmfFilePtr);
fclose(entrFilePtr);
void PrintPSNR(unsigned char* oriBuffer, unsigned char* recBuffer, int qBits, const char* psnrFileName)
double mse;
double sum = 0;
double temp;
double psnr;
for (int i = 0; i < w * h; i++)
temp = pow((oriBuffer[i] - recBuffer[i]), 2);
sum += temp;
mse = sum / (w * h);
psnr = 10 * log10(255 * 255 / mse);
/* 将统计数据输出到csv文件中 */
FILE* outFilePtr;
if (fopen_s(&outFilePtr, psnrFileName, "ab") == 0)
cout << "Successfully opened \\"" << psnrFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << psnrFileName << "\\".\\n";
exit(-1);
fprintf(outFilePtr, "%d,%lf\\n", qBits, psnr);
fclose(outFilePtr);
将预测误差图像写入文件并将该文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。
或者直接将原始图像文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。
最后比较两种系统(1.DPCM+熵编码和2.仅进行熵编码)之间的编码效率(压缩比和图像质量)。压缩质量以PSNR进行计算。
量化预测误差QPE(quantisied prediction error);概率分布PMF
int main(int argc, char* argv[])
int qBits = 8;
const char* orFileName = "Lena.yuv";
const char* qpeFileName = "Lena_QPE (8 bit).yuv"; //量化预测误差文件的名称
const char* recFileName = "Lena_reconstruction (8 bit).yuv"; // 重建级文件的名称
FILE* oriFilePtr;
FILE* qpeFilePtr;
FILE* recFilePtr;
/* 打开文件 */
if (fopen_s(&oriFilePtr, orFileName, "rb") == 0)
cout << "Successfully opened \\"" << orFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << orFileName << "\\".\\n";
exit(-1);
if (fopen_s(&qpeFilePtr, qpeFileName, "wb") == 0)
cout << "Successfully opened \\"" << qpeFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << qpeFileName << "\\".\\n";
exit(-1);
if (fopen_s(&recFilePtr, recFileName, "wb") == 0)
cout << "Successfully opened \\"" << recFileName << "\\".\\n";
else
cout << "WARNING!! Failed to open \\"" << recFileName << "\\".\\n";
exit(-1);
/* 缓冲区分配 */
unsigned char* oriYBuff = new unsigned char[w * h];
unsigned char* qpeYBuff = new unsigned char[w * h];
unsigned char* recYbuff = new unsigned char[w * h];
unsigned char* uBuff = new unsigned char[w * h / 4];
unsigned char* vBuff = new unsigned char[w * h / 4];
/* 读取灰度数据 */
fread(oriYBuff, sizeof(unsigned char), w * h, oriFilePtr);
/* DPCM */
DpcmEncoding(oriYBuff, qpeYBuff, recYbuff, qBits);
memset(uBuff, 128, w * h / 4);
memset(vBuff, 128, w * h / 4);
fwrite(qpeYBuff, sizeof(unsigned char), w * h, qpeFilePtr);
fwrite(uBuff, sizeof(unsigned char), w * h / 4, qpeFilePtr); // Greyscale image
fwrite(vBuff, sizeof(unsigned char), w * h / 4, qpeFilePtr);
fwrite(recYbuff, sizeof(unsigned char), w * h, recFilePtr);
fwrite(uBuff, sizeof(unsigned char), w * h / 4, recFilePtr); // Greyscale image
fwrite(vBuff, sizeof(unsigned char), w * h / 4, recFilePtr);
/* 在csv中写入数据 */
PrintPMF_Entropy(oriYBuff, qBits, "Lena-PMF (8 bit).csv", "Lena-entropy.csv");
PrintPMF_Entropy(qpeYBuff, qBits, "Lena_QPE-PMF (8 bit).csv", "Lena_QPE-entropy.csv");
PrintPSNR(oriYBuff, recYbuff, qBits, "Lena_reconstruction-PSNR.csv");
fclose(oriFilePtr);
fclose(qpeFilePtr);
fclose(recFilePtr);
delete[]oriYBuff;
delete[]qpeYBuff;
delete[]recYbuff;
delete[]uBuff;
delete[]vBuff;
实验结果
DPCM部分
| 量化比特数bit | PSNR(客观评价) | 预测误差图像 | 重建图像(主观评价) |
| 8 | 51.147337 | 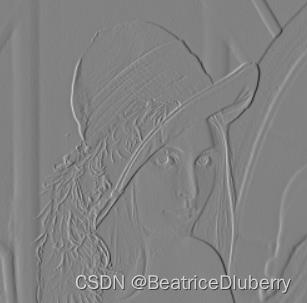 |  |
| 4 | 23.13889 |  |  |
| 2 | 11.93524 |  |  |
| 1 | 9.95645 |  |  |
- 8bit量化时,重建效果较好;4bit量化时出现肉眼可察的失真;2bit量化以下时图像质量无法接受。
- 在这里我们也可以发现一点,例如对于量化误差进行1 bit量化,并不代表重建图像只有0和255两个亮度电平,这也是相比于直接对原图像进行量化的优势之一。
- 对于PSNR的计算符合上文的分析。
即一般来说:
PSNR ≥ 40 dB时,图像质量非常好,接近于原图像;
30 dB ≤ PSNR < 40 dB 时,图像有人眼可察的失真,但质量尚可;
20 dB ≤ PSNR < 30 dB 时,图像质量较差;
PSNR < 20 dB 时,图像质量人眼无法接受。
| 量化比特数bit | 原文件概率分布 | 预测误差概率分布 |
| 8 | 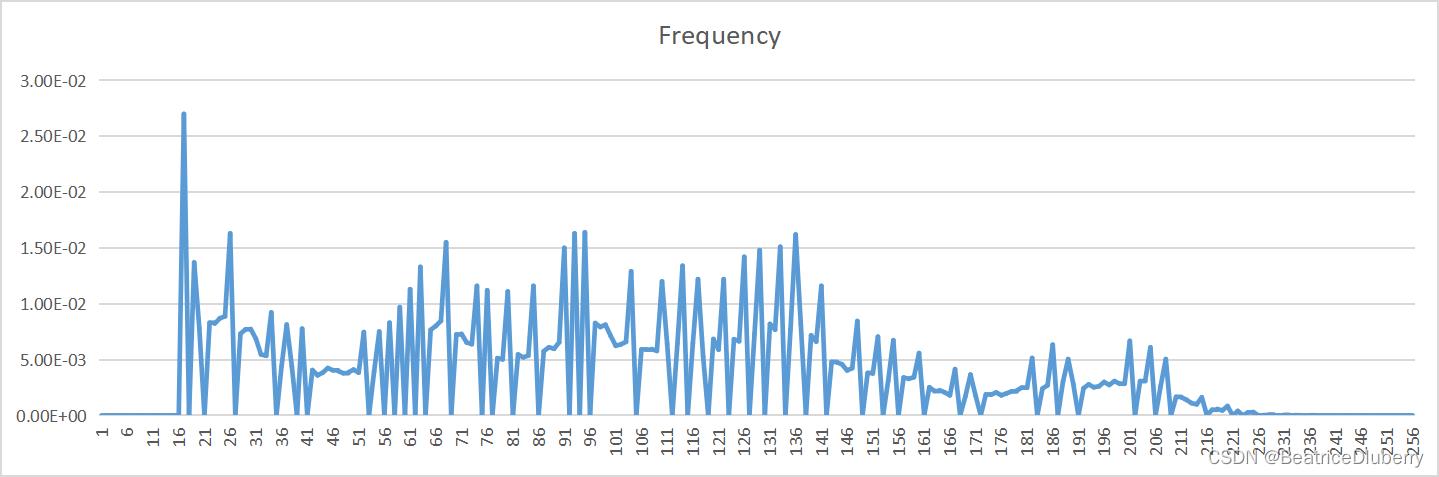 | 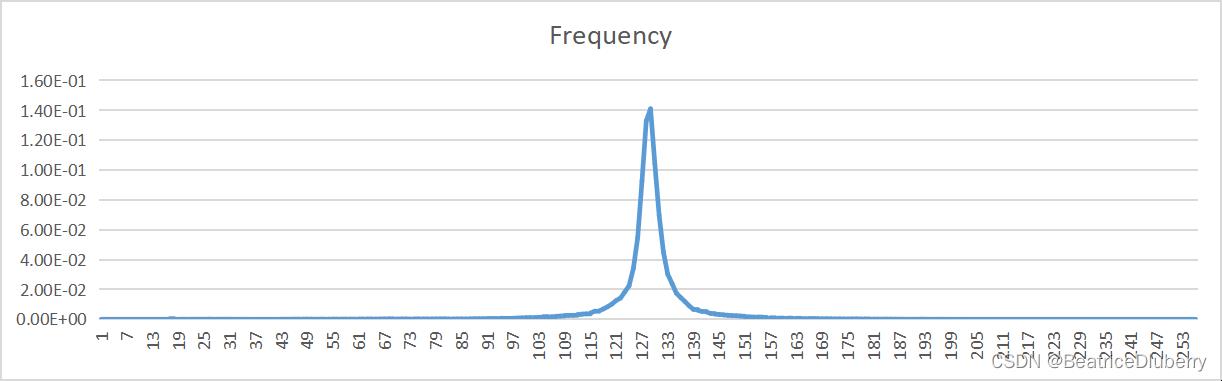 |
| 4 | 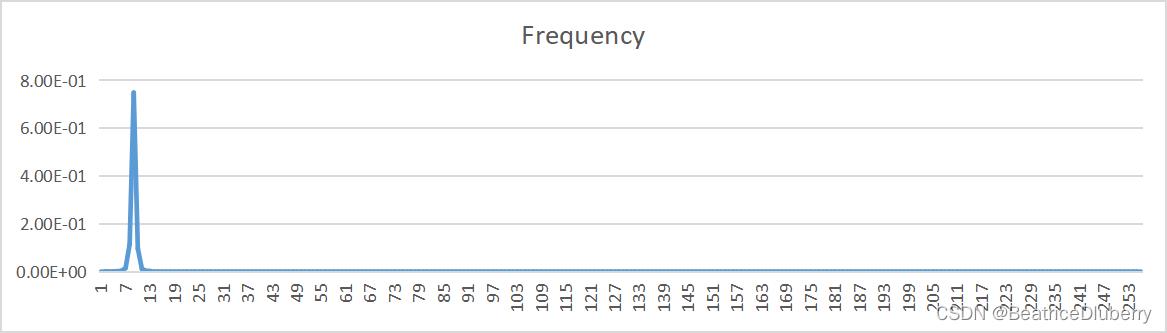 | |
| 2 | 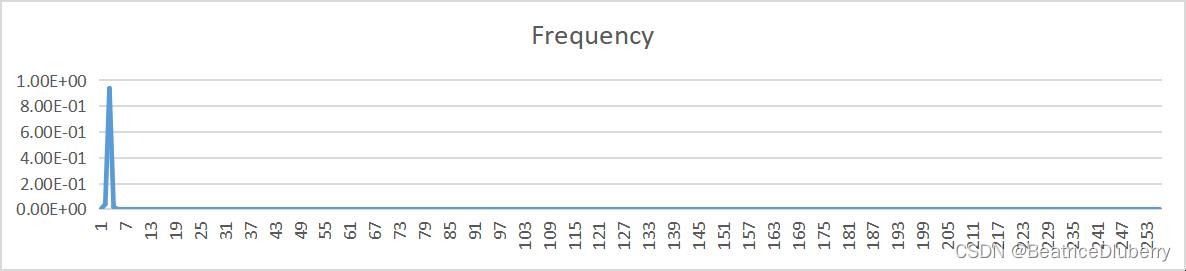 | |
| 1 | 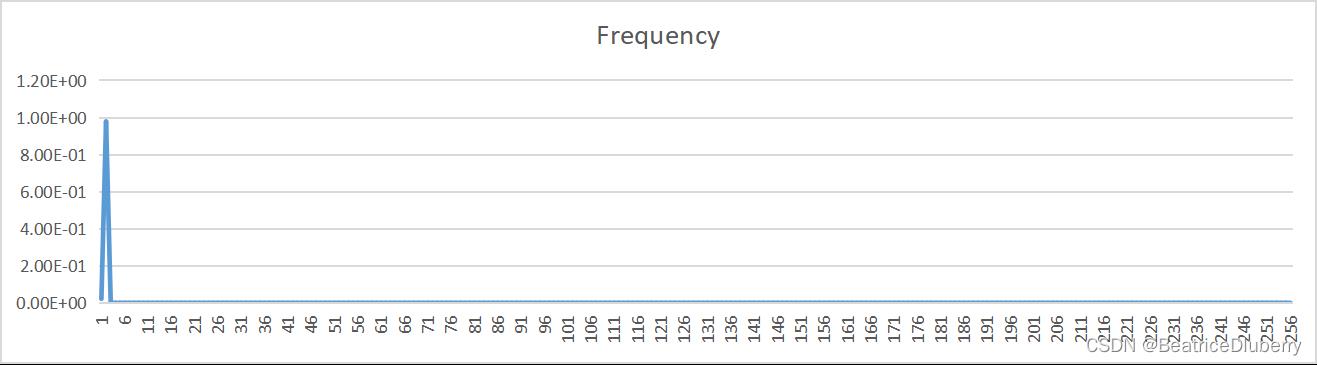 |
| 量化比特数bit | 原文件熵 | DPCM后熵 |
| 8 | 7.0534 | 4.6098 |
| 4 | 1.2735 | |
| 2 | 0.3984 | |
| 1 | 0.1545 |
可以看到,原图像中存在较大的相关性,进行了DPCM编码后,相关性得到了较好的去除,从而实现了压缩。
哈夫曼编码部分
将原始图像文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。最
后比较两种系统(1.DPCM+熵编码和2.仅进行熵编码)之间的编码效率。
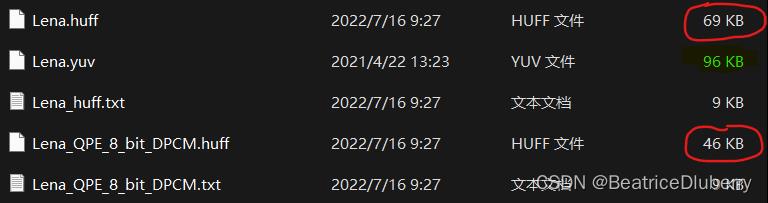
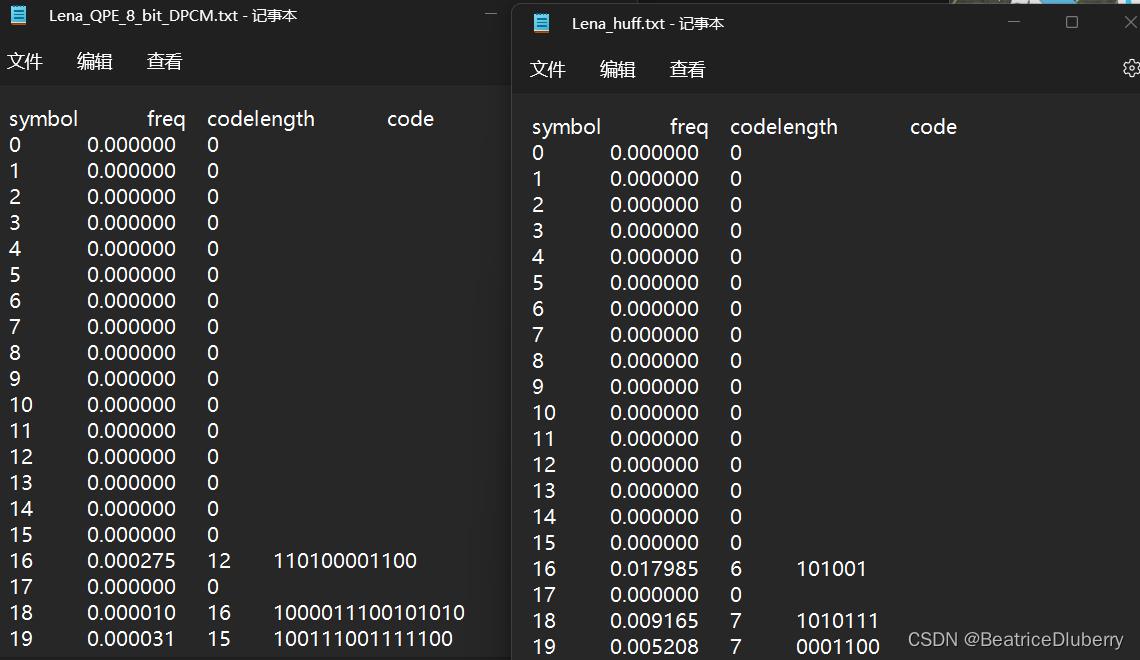
DPCM+8bit量化+熵编码-----压缩比: 96/46=2.1
仅进行熵编码---------压缩比:96/69=1.4
调用了已给的哈夫曼程序后,可以看到经过DPCM编码后再进行哈夫曼编码得到的文件体积明显更小,即系统的压缩效果更好。
微调后 OpenAI 预测的编码问题
【中文标题】微调后 OpenAI 预测的编码问题【英文标题】:Encoding issues on OpenAI predictions after fine-tuning 【发布时间】:2021-12-23 22:50:45 【问题描述】:我正在关注this OpenAI tutorial 进行微调。
我已经使用 openai 工具生成了数据集。问题是输出编码(推理结果)混合了 UTF-8 和非 UTF-8 字符。
生成的模型如下所示:
"prompt":"Usuario: Quién eres\\nAsistente:","completion":" Soy un Asistente\n"
"prompt":"Usuario: Qué puedes hacer\\nAsistente:","completion":" Ayudarte con cualquier gestión o ofrecerte información sobre tu cuenta\n"
例如,如果我问“¿Cómo estás?”并且该句子有一个经过训练的补全:“Estoy bien, ¿y tú?”,推理通常返回完全相同(这很好),但有时它会添加非编码词:“Estoy bien, ¿y tú? Cuà ©ntame algo de ti”,添加“é”而不是“é”。
有时,它返回的句子与经过训练的句子完全相同,没有编码问题。 我不知道推理是从我的模型中还是从其他地方获取非编码字符。
我该怎么办? 我应该用 UTF-8 编码数据集吗? 我应该使用 UTF-8 保留数据集并解码响应中的错误编码字符吗?
用于微调的 OpenAI 文档不包含任何关于编码的内容。
【问题讨论】:
【参考方案1】:我在处理葡萄牙语字符串时遇到了同样的问题。
尝试在字符串后使用.encode("cp1252").decode():
"Cuéntame algo de ti".encode("cp1252").decode()
这应该会导致:
"Cuéntame algo de ti"
cp1252 与 windows-1252 西欧编解码器有关。如果这不起作用,请从这里尝试另一个编解码器:
https://docs.python.org/3.7/library/codecs.html#standard-encodings
【讨论】:
对包含编码和解码字符的字符串执行此操作时会出现问题,就是这种情况。所以我认为这是因为模型合并了不同的句子,一些编码良好,一些错误,所以这个问题并没有解决。也许我错误地训练了模型......一个例子是:“Estoy bien, ¿y tú? Cuéntame algo de ti”。有了这句话,我不知道该怎么办了。以上是关于DPCM预测编码的主要内容,如果未能解决你的问题,请参考以下文章