Flink / Scala - 20.Scala API Extensions 扩展
Posted BIT_666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink / Scala - 20.Scala API Extensions 扩展相关的知识,希望对你有一定的参考价值。
目录
2.[DataStream] flatMap => flatMapWith
Flink / Scala - TimeWindow 处理迟到数据详解
目录
一.引言
在事件时间 EventTime 语义环境下,窗口中可能出现数据迟到的情况,即 Event 时间戳小于水位线 Watermark,此时数据流未乱序流,水位线不能保证小于自己的时间戳的 Event 不会到来。这时会出现一种情况,水位线到达窗口触发时间触发窗口计算,而属于该窗口的迟到数据到来,默认情况下该类数据会被丢弃。数据的丢弃会导致窗口的计算结果不准确,因此 Flink 推出了 3 种方法处理迟到数据:
- WatermarkStrategy.forBoundedOutOfOrderness 最大延时
- Allowed Lateness 窗口延迟注销
- SideOutputLateData 侧输出流处理迟到数据
二.Flink TimeWindow 丢数据示例
1.代码分析
在介绍几种处理迟到数据方法之前,先示例一下 Flink 在正常情况下如何丢失数据导致计算不准确。以下 Demo 使用 Event 类作为 DataStream[T] 的数据类型,Event 为用户浏览 URL 的简单信息:
// 用户浏览行为
case class Event(user: String, url: String, timeStamp: Long) def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 全局并行度
env.setParallelism(1)
env.socketTextStream("localhost", 9999) // A.本地 Socket 流
.map(line =>
val info = line.split(",")
Event(info(0), info(1), info(2).toLong)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forBoundedOutOfOrderness[Event](Duration.ofSeconds(5)) // B.延时5s
.withTimestampAssigner(new SerializableTimestampAssigner[Event]
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
))
.keyBy(_.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10))) // C.10s滚动窗口
.process(new ProcessWindowFunction[Event, String, String, TimeWindow]
override def process(key: String, context: Context, elements: Iterable[Event], out: Collector[String]): Unit =
val set = new mutable.HashSet[String]()
elements.foreach(elem => set.add(elem.user))
val start: Long = context.window.getStart
val end: Long = context.window.getEnd
// D.获取当前 WaterMark
val currentWatermark = context.currentWatermark
val count = elements.size
val log = s"Window Start: $start End: $end CurrentWaterMark: $currentWatermark Count: $count"
out.collect(log)
).print()
env.execute()
上面是示例的代码,主要部分为 A、B、C、D:
A.本地 Socket 流:后续我们从本地开启通道模式 Event 数据写入
B.延时5s:这里表示了对迟到数据的容忍程度,生成 Watermark 时会延后5s
C.10s滚动窗口:滚动窗口的窗口开关时间固定,例如 10:10-10:20、10:20-10:30,以此类推
D.Watermark:获取当前 Watermark 并输出到下游
2.Watermark 生成逻辑

WatermarkGenerator.BoundedOutOfOrdernessWatermarks 中 onPeriodicEmit 负责周期的生成 Watermark,通过 onEvent 更新当前最大时间戳,再通过 emitWatermark 生成水印,由于引入延迟 outOfOrdernessMillis 参数,该策略会调低水位线的生成,相当于人工把钟表调慢等待迟到的数据一定时间一样,默认情况下 emit 的 period 周期为 200ms。
Tips:
-1L:生成水位线时用了 -1L,这里和水位线的释义有关系,水位线标识小于等于自己的时间戳的 Event 都不会来了,而窗口的时间范围为左闭右开,例如 [0,10000),如果生成 10000 的水位线触发窗口,则代表小于等于 10000 时间戳的 Event 都不会到来了,此时 timestamp = 10000 的元素也会计入 [0,10000) 的窗口,因此影响数据准确性,所以这里通过 -1L 使得触发的数据范围为 [0, 9999],而窗口的起止为 [0,10000)。
3.丢失数据代码测试
在本地 terminal 内执行下述命令启动 Socket:
nc -lk 9999Alice,1,1000
Alice,2,2000
Alice,3,15000
Alice,4,9000
Alice,3,20000
Alice,4,25000依次输入上述信息得到如下结果:

| TimeStamp | MaxTimeStamp | Watermark | TimeWindow |
| 1000 | 1000 | / | / |
| 2000 | 2000 | / | / |
| 15000 | 15000 | 9999 | [0,10000) 触发 |
| 9000 | 15000 | 9999 | 数据迟到 |
| 20000 | 20000 | 14999 | / |
| 25000 | 25000 | 19999 | [10000,20000) 触发 |
| / | / | LONG.MAX_VALUE | [20000,30000) 触发 |
上面表格为每条数据输入对应的操作:
第一次触发:1000,2000 进入 [0,10000) 的窗口后,在 15000 对应 Event 达到后,水位线推进到 15000 - 5000 - 1 即 [0,10000) 窗口的触发时间,所以触发窗口计算,这时元素为 1000,2000,所以 Count = 2
第二次触发:15000 属于 [10000,20000) 窗口,在 25000 对应 Event 到达后,水位线推进到 25000 - 5000 -1 即 [10000,20000) 窗口的触发时间,所以触发窗口计算,这时元素为 15000,所以 Count = 1
第三次触发:20000,25000 属于 [20000,30000) 窗口,最终关闭 Socket 时,Flink 会发出一个 Long.MAX_VALUE = 9223372036854775807 的 WaterMark,从而触发所有窗口计算,此时只剩 [20000,30000) 窗口未触发,触发后元素为 20000,25000,所以 Count = 2
Tips:
累计 Count 为 2 + 1 + 2 = 5,而总共输入元素为 6 个,因为 9000 对应的 Event 输入的时候,属于它的窗口 [0,10000) 已经触发,所以 9000 没有在触发窗口逻辑中,这也就是乱序数据下 Flink 数据丢失的一种真实案例。
三.Flink 处理迟到数据策略
引言中提到了 Flink 3 种处理迟到数据的方法,下面一一介绍:
- WatermarkStrategy.forBoundedOutOfOrderness 最大延时
- Allowed Lateness 窗口延迟注销
- SideOutputLateData 侧输出流处理迟到数据
1.forBoundedOutOfOrderness
WatermarkStrategy 的方法属性,允许乱序流中的数据存在延迟,其中 maxOutOfOrderness 参数代表最大乱序程度,其中最关键的实现就是 onPeriodicEmit:
public void onPeriodicEmit(WatermarkOutput output)
output.emitWatermark(new Watermark(this.maxTimestamp - this.outOfOrdernessMillis - 1L));
其生成的水印会根据 maxOutOfOrderness 进行延迟,例如 10000 的数据到来,正常情况下触发 [0,10000) 的窗口触发,而设置5s延迟后,必须等到 15000 的数据来,[0,10000) 才会触发,因此在5s内迟到的数据,依然会进入到属于自己的窗口并最终统一计算。这里相当于是性能和时效性的权衡,延时一段时间,但是保障了数据的相对准确性。使用时只需要在 WaterMarkStrategy 中设置即可:
WatermarkStrategy
.forBoundedOutOfOrderness[Event](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[Event]
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
)2.Allowed Lateness
虽然设置了 maxOutOfOrderness 的最大延时时间,但是还是无法避免迟到过久的数据,像上面例子中的一样,9000 比 15000 延迟了 6s,而此时 9000 对应的窗口已经触发并销毁,因此 9000 对应的数据就被舍弃了。Allowed Lateness 参数允许设定一段延迟时间,在延时的这段时间内,窗口不会注销,如果此时有迟到且属于对应窗口的数据到来,数据仍然可以进入窗口并参与计算,直到 Watermark 推进至 窗口结束时间 + Allowed Lateness 设定的延时时间,窗口才会真正销毁,这时候如果还有迟到的数据,就找不到对应窗口了。这里相当于双保险,在水印延迟生成的情况下,窗口销毁时间也延后。
val result = stream.keyBy(_.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1)) // 1分钟的窗口迟到等待时间Flink 窗口的触发相关知识可以参考:Flink - Scala/Java trigger 简介与使用。
3.SideOutputLateData
无论是延迟水印,亦或是延迟窗口销毁时间,这个时间都是有限的,程序都无法永远等下去,因此超过双保险的数据还是会被丢弃,如果不想丢掉任何一个数据,则可以增加侧输出流,该数据流负责接收超时严重被舍弃的数据,而通过 stream.getSideOutput 方法可以获取该类数据,你需要重新增加处理逻辑处理,而他们依旧无法进入到之前的正确窗口中。
val sideOutputTag: OutputTag[Event] = new OutputTag[Event]("late")
val result = stream.keyBy(_.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1)) // 方法2:1分钟的窗口迟到等待时间
.sideOutputLateData(sideOutputTag) // 方法3: 最后迟到的数据输出到侧输出流
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
result.print("result")
result.getSideOutput(sideOutputTag).print("late")使用 SideOutputLateData 需要先定义 OutputTag 标记侧输出流类型,并在 window 后添加 SideOutputLateData 选项,最终通过 getSideOutput 输出,print 内的 "late" 为该数据流标记,后续日志中可以与 result 的正常日志区分。
四.Flink 处理迟到数据实战
下面通过一个案例,同时运用上述三个方法展示 Flink EventTime + TimeWindow 如何处理迟到数据。
1.代码分析
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 全局并行度
env.setParallelism(1)
val stream = env.socketTextStream("localhost", 9999)
.map(line =>
val info = line.split(",")
Event(info(0), info(1), info(2).toLong)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forBoundedOutOfOrderness[Event](Duration.ofSeconds(2)) // 方法1:延时等待2s
.withTimestampAssigner(new SerializableTimestampAssigner[Event]
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
))
val sideOutputTag: OutputTag[Event] = new OutputTag[Event]("late")
val result = stream.keyBy(_.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1)) // 方法2:1分钟的窗口迟到等待时间
.sideOutputLateData(sideOutputTag) // 方法3: 最后迟到的数据输出到侧输出流
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
result.print("result")
result.getSideOutput(sideOutputTag).print("late")
// 原始数据
stream.print("input")
env.execute()
上面分别使用了 2s 的水印生成延迟策略,1min 的窗口延时注销策略以及兜底的侧输出流策略保证迟到数据的处理,同时使用 "input" Tag 输出原始数据,"result" Tag 输出窗口聚合数据,"late" Tag 输出迟到过久的数据。处理逻辑中使用了 aggregate 以及对应的 ACC 与 ProcessFunction,具体代码细节请参考:Flink / Scala - Aggregate 详解与 UV、PV 统计实战。
2.迟到数据处理实战
在本地 terminal 内执行下述命令启动 Socket:
nc -lk 9999a,1,1000
a,1,2000
a,1,10000
a,1,9000
a,1,12000
a,1,15000
a,1,9000
a,1,8000
a,1,70000
a,1,8000
a,1,72000
a,1,8000依次输入上述 Event 并得到下述结果:

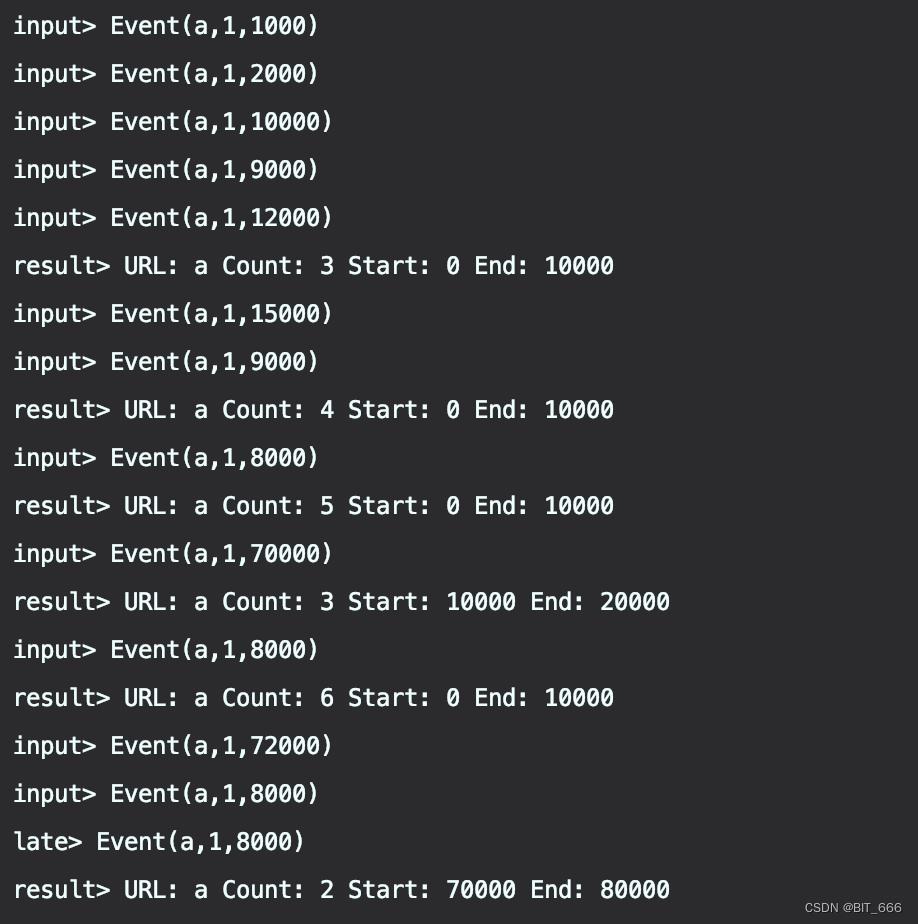
3.日志分析
下面以 "Result" Tag 触发的日志为分界线,详细分析窗口的触发逻辑。
A.第一次触发
上面的数据与日志比较多,这里做分解的详细分析:
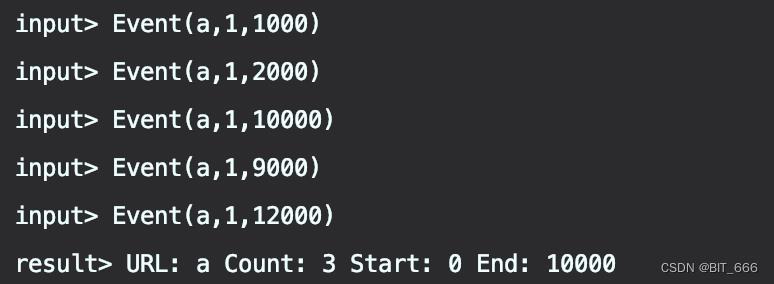
因为设置了 2s 的延迟,所以 [0,10000) 的窗口需要等到 12000 的元素到来,此时 Watermark 为 12000 - 2000 - 1 = 9999,所以第一次窗口触发,此时窗口元素包含 1000,2000,9000,可以看到 9000 虽然比 10000 迟到了,但是由于 2s 的延迟,使得其进入正确的窗口并触发计算。注意,这里 [0,10000) 触发后并未销毁,需要再等 1min,即水位线到达 10000 + 60000 = 70000 时,窗口才会真正销毁,不再接收迟到数据。
B.第二,三次触发
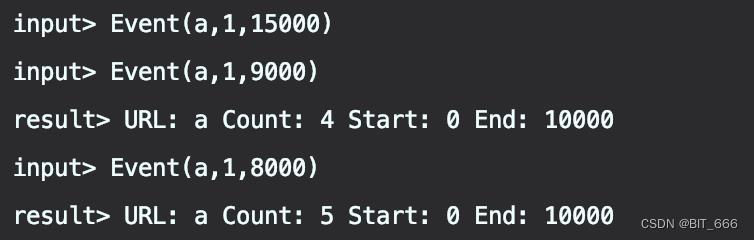
15000 后迟到数据 9000 和 8000 到达,此时水位线为 15000 - 2000 - 1 = 12999 未达到 70000,所以 [0,10000)窗口未销毁,所以 9000,8000 继续触发对应窗口计算,所以 Count 由 3 变为 5,其余日志不变。
C.第四,五次触发
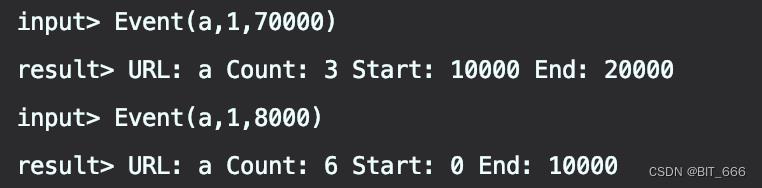
随着 70000 的到来,水位线推进至 70000 - 2000 - 1 = 67999,此时触发 [10000,20000) 的窗口,其实这里 [20000,30000),[30000,40000) 等的窗口也会被触发,但是由于没有对应元素开窗,所以只触发 [10000,20000) 内的 10000,12000,15000 计算,此时 Count 为 3。而在 70000 后迟到数据 8000 再次到来,这时 67999 未达到 70000 的窗口销毁时间,所以还能继续触发 [0,10000) 窗口的计算,此时 Count 由 5 转换为 6。
D.第六次触发
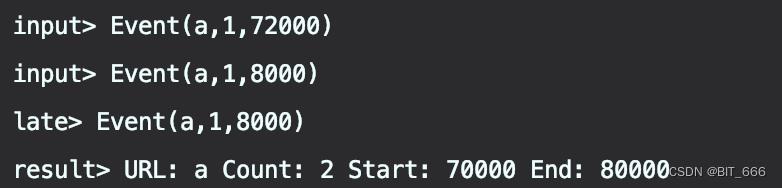
随着 72000 的到来,水位线推进至 72000 - 2000 - 1 = 69999,达到 [0,10000) 窗口注销的条件,所以 [0,10000)窗口注销,此时再有属于 [0,10000) 窗口的数据到来将不会窗口计算,而是输入到侧输出流,所以 72000 后到达的 8000,以 "late" Tag 输出。最终的触发为关闭 Socket,Flink 发出 LONG.MAX_VALUE,触发了 [70000,80000) 的窗口,此时剩余的元素 70000,72000 触发窗口计算,此时 Count = 2。
五.总结
至此,一次完整的迟到数据处理也就结束了,可以看到,迟到相对较近的元素可以通过 forBoundedOutOfOrderness 策略捕获,迟到相对较远的元素则需要通过 Allowed Lateness 捕获,二者都未捕获的,需要 SideOutputLateData 兜底并最终捕获。迟到数据的处理本质上就是精准度与效率以及资源的权衡,大家可以根据自己的业务场景与实际需求,决定每个策略的容忍度。
以上是关于Flink / Scala - 20.Scala API Extensions 扩展的主要内容,如果未能解决你的问题,请参考以下文章