一文看懂 MySQL 高性能优化技巧实践
Posted Java技术那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂 MySQL 高性能优化技巧实践相关的知识,希望对你有一定的参考价值。
一、背景
最近公司项目添加新功能,上线后发现有些功能的列表查询时间很久。原因是新功能用到旧功能的接口,而这些旧接口的 SQL 查询语句关联5,6张表且编写不够规范,导致 mysql 在执行 SQL 语句时索引失效,进行全表扫描。原本负责优化的同事有事请假回家,因此优化查询数据的问题落在笔者手中。笔者在查阅网上 SQL 优化的资料后成功解决了问题,在此从全局角度记录和总结 MySQL 查询优化相关技巧。
二、优化思路
数据查询慢,不代表 SQL 语句写法有问题。 首先,我们需要找到问题的源头才能“对症下药”。笔者用一张流程图展示 MySQL 优化的思路:
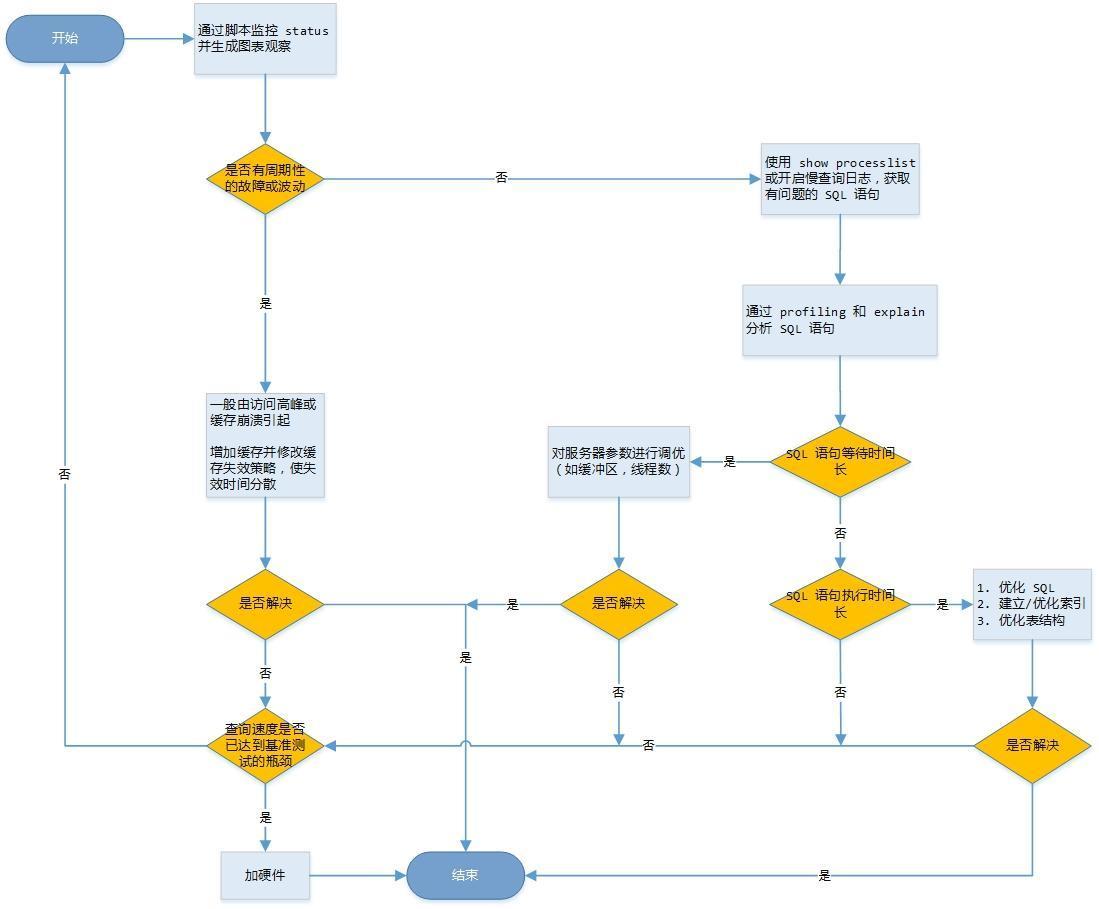
无需更多言语,从图中可以清楚地看出,导致数据查询慢的原因有多种,如:缓存失效,在此一段时间内由于高并发访问导致 MySQL 服务器崩溃;SQL 语句编写问题;MySQL 服务器参数问题;硬件配置限制 MySQL 服务性能问题等。
三、查看 MySQL 服务器运行的状态值
如果系统的并发请求数不高,且查询速度慢,可以忽略该步骤直接进行 SQL 语句调优步骤。
执行命令:
show status
由于返回结果太多,此处不贴出结果。其中,再返回的结果中,我们主要关注 “Queries”、“Threads_connected” 和 “Threads_running” 的值,即查询次数、线程连接数和线程运行数。
我们可以通过执行如下脚本监控 MySQL 服务器运行的状态值
#!/bin/bash
while true
do
mysqladmin -uroot -p"密码" ext | awk '/Queries/q=$4/Threads_connected/c=$4/Threads_running/r=$4ENDprintf("%d %d %d\\n",q,c,r)' >> status.txt
sleep 1
done
执行该脚本 24 小时,获取 status.txt 里的内容,再次通过 awk 计算每秒请求 MySQL 服务的次数
awk 'q=$1-last;last=$1printf("%d %d %d\\n",q,$2,$3)' status.txt
复制计算好的内容到 Excel 中生成图表观察数据周期性。
如果观察的数据有周期性的变化,如上图的解释,需要修改缓存失效策略。
例如:
通过随机数在[3,6,9] 区间获取其中一个值作为缓存失效时间,这样分散了缓存失效时间,从而节省了一部分内存的消耗。
当访问高峰期时,一部分请求分流到未失效的缓存,另一部分则访问 MySQL 数据库,这样减少了 MySQL 服务器的压力。
四、获取需要优化的 SQL 语句
### 4.1 方式一:查看运行的线程
执行命令:
show processlist
返回结果:
mysql> show processlist;
+----+------+-----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+----------+------------------+
| 9 | root | localhost | test | Query | 0 | starting | show processlist |
+----+------+-----------+------+---------+------+----------+------------------+
1 row in set (0.00 sec)
从返回结果中我们可以了解该线程执行了什么命令/SQL 语句以及执行的时间。实际应用中,查询的返回结果会有 N 条记录。
其中,返回的 State 的值是我们判断性能好坏的关键,其值出现如下内容,则该行记录的 SQL 语句需要优化:
Converting HEAP to MyISAM # 查询结果太大时,把结果放到磁盘,严重
Create tmp table #创建临时表,严重
Copying to tmp table on disk #把内存临时表复制到磁盘,严重
locked #被其他查询锁住,严重
loggin slow query #记录慢查询
Sorting result #排序
State 字段有很多值,如需了解更多,可以参看文章末尾提供的链接。
### 4.2 方式二:开启慢查询日志
在配置文件 my.cnf 中的 [mysqld] 一行下边添加两个参数:
slow_query_log = 1
slow_query_log_file=/var/lib/mysql/slow-query.log
long_query_time = 2
log_queries_not_using_indexes = 1
其中,slow_query_log = 1 表示开启慢查询;
slow_query_log_file 表示慢查询日志存放的位置;
long_query_time = 2 表示查询 >=2 秒才记录日志;
log_queries_not_using_indexes = 1 记录没有使用索引的 SQL 语句。
注意:slow_query_log_file 的路径不能随便写,否则 MySQL 服务器可能没有权限将日志文件写到指定的目录中。建议直接复制上文的路径。
修改保存文件后,重启 MySQL 服务。在 /var/lib/mysql/ 目录下会创建 slow-query.log 日志文件。连接 MySQL 服务端执行如下命令可以查看配置情况。
show variables like 'slow_query%';
show variables like 'long_query_time';
测试慢查询日志:
mysql> select sleep(2);
+----------+
| sleep(2) |
+----------+
| 0 |
+----------+
1 row in set (2.00 sec)
打开慢查询日志文件
[root@localhost mysql]# vim /var/lib/mysql/slow-query.log
/usr/sbin/mysqld, Version: 5.7.19-log (MySQL Community Server (GPL)). started with:
Tcp port: 0 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument
# Time: 2017-10-05T04:39:11.408964Z
# User@Host: root[root] @ localhost [] Id: 3
# Query_time: 2.001395 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use test;
SET timestamp=1507178351;
select sleep(2);
我们可以看到刚才执行了 2 秒的 SQL 语句被记录下来了。
虽然在慢查询日志中记录查询慢的 SQL 信息,但是日志记录的内容密集且不易查阅。因此,我们需要通过工具将 SQL 筛选出来。
MySQL 提供 mysqldumpslow 工具对日志进行分析。我们可以使用 mysqldumpslow --help 查看命令相关用法。
常用参数如下:
-s:排序方式,后边接着如下参数
c:访问次数
l:锁定时间
r:返回记录
t:查询时间
al:平均锁定时间
ar:平均返回记录书
at:平均查询时间
-t:返回前面多少条的数据
-g:翻遍搭配一个正则表达式,大小写不敏感
案例:
获取返回记录集最多的10个sql
mysqldumpslow -s r -t 10 /var/lib/mysql/slow-query.log
获取访问次数最多的10个sql
mysqldumpslow -s c -t 10 /var/lib/mysql/slow-query.log
获取按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/slow-query.log
五、分析 SQL 语句
5.1 方式一:explain
筛选出有问题的 SQL,我们可以使用 MySQL 提供的 explain 查看 SQL 执行计划情况(关联表,表查询顺序、索引使用情况等)。
用法:
explain select * from category;
返回结果:
mysql> explain select * from category;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | category | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
字段解释:
1. id:select 查询序列号。id相同,执行顺序由上至下;id不同,id值越大优先级越高,越先被执行
2. select_type:查询数据的操作类型,其值如下:
simple:简单查询,不包含子查询或 union
primary:包含复杂的子查询,最外层查询标记为该值
subquery:在 select 或 where 包含子查询,被标记为该值
derived:在 from 列表中包含的子查询被标记为该值,MySQL 会递归执行这些子查询,把结果放在临时表
union:若第二个 select 出现在 union 之后,则被标记为该值。若 union 包含在 from 的子查询中,外层 select 被标记为 derived
union result:从 union 表获取结果的 select
3. table:显示该行数据是关于哪张表
4. partitions:匹配的分区
5. type:表的连接类型,其值,性能由高到底排列如下:
system:表只有一行记录,相当于系统表
const:通过索引一次就找到,只匹配一行数据
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常用于主键或唯一索引扫描
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。用于=、< 或 > 操作符带索引的列
range:只检索给定范围的行,使用一个索引来选择行。一般使用between、>、<情况
index:只遍历索引树
ALL:全表扫描,性能最差
注:前5种情况都是理想情况的索引使用情况。通常优化至少到range级别,最好能优化到 ref
6. possible_keys:指出 MySQL 使用哪个索引在该表找到行记录。如果该值为 NULL,说明没有使用索引,可以建立索引提高性能
7. key:显示 MySQL 实际使用的索引。如果为 NULL,则没有使用索引查询
8. key_len:表示索引中使用的字节数,通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好 显示的是索引字段的最大长度,并非实际使用长度
9. ref:显示该表的索引字段关联了哪张表的哪个字段
10. rows:根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好
11. filtered:返回结果的行数占读取行数的百分比,值越大越好
12. extra: 包含不合适在其他列中显示但十分重要的额外信息,常见的值如下:
using filesort:说明 MySQL 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。出现该值,应该优化 SQL
using temporary:使用了临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。出现该值,应该优化 SQL
using index:表示相应的 select 操作使用了覆盖索引,避免了访问表的数据行,效率不错
using where:where 子句用于限制哪一行
using join buffer:使用连接缓存
distinct:发现第一个匹配后,停止为当前的行组合搜索更多的行
注意:出现前 2 个值,SQL 语句必须要优化。
5.2 方式二:profiling
使用 profiling 命令可以了解 SQL 语句消耗资源的详细信息(每个执行步骤的开销)。
5.2.1 查看 profile 开启情况
select @@profiling;
返回结果:
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+
1 row in set, 1 warning (0.00 sec)
0 表示关闭状态,1 表示开启
# 5.2.2 启用 profile
set profiling = 1;
返回结果:
mysql> set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 1 |
+-------------+
1 row in set, 1 warning (0.00 sec)
在连接关闭后,profiling 状态自动设置为关闭状态。
# 5.2.3 查看执行的 SQL 列表
show profiles;
返回结果:
mysql> show profiles;
+----------+------------+------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------+
| 1 | 0.00062925 | select @@profiling |
| 2 | 0.00094150 | show tables |
| 3 | 0.00119125 | show databases |
| 4 | 0.00029750 | SELECT DATABASE() |
| 5 | 0.00025975 | show databases |
| 6 | 0.00023050 | show tables |
| 7 | 0.00042000 | show tables |
| 8 | 0.00260675 | desc role |
| 9 | 0.00074900 | select name,is_key from role |
+----------+------------+------------------------------+
9 rows in set, 1 warning (0.00 sec)
该命令执行之前,需要执行其他 SQL 语句才有记录。
5.2.4 查询指定 ID 的执行详细信息
show profile for query Query_ID;
返回结果:
mysql> show profile for query 9;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000207 |
| checking permissions | 0.000010 |
| Opening tables | 0.000042 |
| init | 0.000050 |
| System lock | 0.000012 |
| optimizing | 0.000003 |
| statistics | 0.000011 |
| preparing | 0.000011 |
| executing | 0.000002 |
| Sending data | 0.000362 |
| end | 0.000006 |
| query end | 0.000006 |
| closing tables | 0.000006 |
| freeing items | 0.000011 |
| cleaning up | 0.000013 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)
每行都是状态变化的过程以及它们持续的时间。Status 这一列和 show processlist 的 State 是一致的。因此,需要优化的注意点与上文描述的一样。
其中,Status 字段的值同样可以参考末尾链接。
5.2.5 获取 CPU、 Block IO 等信息
show profile block io,cpu for query Query_ID;
show profile cpu,block io,memory,swaps,context switches,source for query Query_ID;
show profile all for query Query_ID;
六、优化手段
主要以查询优化、索引使用和表结构设计方面进行讲解。
6.1 查询优化
-
避免 SELECT *,需要什么数据,就查询对应的字段。
-
小表驱动大表,即小的数据集驱动大的数据集。如:以 A,B 两表为例,两表通过 id 字段进行关联。
当 B 表的数据集小于 A 表时,用 in 优化 exist;使用 in ,两表执行顺序是先查 B 表,再查 A 表
select * from A where id in (select id from B)
当 A 表的数据集小于 B 表时,用 exist 优化 in;使用 exists,两表执行顺序是先查 A 表,再查 B 表
select * from A where exists (select 1 from B where B.id = A.id)
-
一些情况下,可以使用连接代替子查询,因为使用 join,MySQL 不会在内存中创建临时表。
-
适当添加冗余字段,减少表关联。
-
合理使用索引(下文介绍)。如:为排序、分组字段建立索引,避免 filesort 的出现。
6.2 索引使用
6.2.1 适合使用索引的场景
-
主键自动创建唯一索引
-
频繁作为查询条件的字段
-
查询中与其他表关联的字段
-
查询中排序的字段
-
查询中统计或分组字段
6.2.2 不适合使用索引的场景
-
频繁更新的字段
-
where 条件中用不到的字段
-
表记录太少
-
经常增删改的表
-
字段的值的差异性不大或重复性高
6.2.3 索引创建和使用原则
-
单表查询:哪个列作查询条件,就在该列创建索引
-
多表查询:left join 时,索引添加到右表关联字段;right join 时,索引添加到左表关联字段
-
不要对索引列进行任何操作(计算、函数、类型转换)
-
索引列中不要使用 !=,<> 非等于
-
索引列不要为空,且不要使用 is null 或 is not null 判断
-
索引字段是字符串类型,查询条件的值要加’'单引号,避免底层类型自动转换
违背上述原则可能会导致索引失效,具体情况需要使用 explain 命令进行查看
6.2.4 索引失效情况
除了违背索引创建和使用原则外,如下情况也会导致索引失效:
-
模糊查询时,以 % 开头
-
使用 or 时,如:字段1(非索引)or 字段2(索引)会导致索引失效。
-
使用复合索引时,不使用第一个索引列。
index(a,b,c) ,以字段 a,b,c 作为复合索引为例:
| 语句 | 索引是否生效 |
|---|---|
| where a = 1 | 是,字段 a 索引生效 |
| where a = 1 and b = 2 | 是,字段 a 和 b 索引生效 |
| where a = 1 and b = 2 and c = 3 | 是,全部生效 |
| where b = 2 或 where c = 3 | 否 |
| where a = 1 and c = 3 | 字段 a 生效,字段 c 失效 |
| where a = 1 and b > 2 and c = 3 | 字段 a,b 生效,字段 c 失效 |
| where a = 1 and b like ‘xxx%’ and c = 3 | 字段 a,b 生效,字段 c 失效 |
6.3 数据库表结构设计
6.3.1 选择合适的数据类型
-
使用可以存下数据最小的数据类型
-
使用简单的数据类型。int 要比 varchar 类型在mysql处理简单
-
尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int
-
尽可能使用 not null 定义字段,因为 null 占用4字节空间
-
尽量少用 text 类型,非用不可时最好考虑分表
-
尽量使用 timestamp 而非 datetime
-
单表不要有太多字段,建议在 20 以内
6.3.2 表的拆分
当数据库中的数据非常大时,查询优化方案也不能解决查询速度慢的问题时,我们可以考虑拆分表,让每张表的数据量变小,从而提高查询效率。
1. 垂直拆分:将表中多个列分开放到不同的表中。例如用户表中一些字段经常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中。 插入数据时,使用事务确保两张表的数据一致性。
2. 水平拆分:按照行进行拆分。例如用户表中,使用用户ID,对用户ID取10的余数,将用户数据均匀的分配到0~9的10个用户表中。查找时也按照这个规则查询数据。
6.3.3 读写分离
一般情况下对数据库而言都是“读多写少”。换言之,数据库的压力多数是因为大量的读取数据的操作造成的。我们可以采用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库为从库,负责读取数据。这样可以缓解对数据库的访问压力。
七、服务器参数调优
7.1 内存相关
sort_buffer_size 排序缓冲区内存大小
join_buffer_size 使用连接缓冲区大小
read_buffer_size 全表扫描时分配的缓冲区大小
7.2 IO 相关
Innodb_log_file_size 事务日志大小
Innodb_log_files_in_group 事务日志个数
Innodb_log_buffer_size 事务日志缓冲区大小
Innodb_flush_log_at_trx_commit 事务日志刷新策略,其值如下:
0:每秒进行一次 log 写入 cache,并 flush log 到磁盘
1:在每次事务提交执行 log 写入 cache,并 flush log 到磁盘
2:每次事务提交,执行 log 数据写到 cache,每秒执行一次 flush log 到磁盘
7.3 安全相关
expire_logs_days 指定自动清理 binlog 的天数
max_allowed_packet 控制 MySQL 可以接收的包的大小
skip_name_resolve 禁用 DNS 查找
read_only 禁止非 super 权限用户写权限
skip_slave_start 级你用 slave 自动恢复
### 7.4 其他
max_connections 控制允许的最大连接数
tmp_table_size 临时表大小
max_heap_table_size 最大内存表大小
笔者并没有使用这些参数对 MySQL 服务器进行调优,具体详情介绍和性能效果请参考文章末尾的资料或另行百度。
八、硬件选购和参数优化
硬件的性能直接决定 MySQL 数据库的性能瓶颈,直接决定 MySQL 数据库的运行数据和效率。
作为软件开发程序员,我们主要关注软件方面的优化内容,以下硬件方面的优化作为了解即可
8.1 内存相关
内存的 IO 比硬盘的速度快很多,可以增加系统的缓冲区容量,使数据在内存停留的时间更长,以减少磁盘的 IO
8.2 磁盘 I/O 相关
-
使用 SSD 或 PCle SSD 设备,至少获得数百倍甚至万倍的 IOPS 提升
-
购置阵列卡同时配备 CACHE 及 BBU 模块,可以明显提升 IOPS
-
尽可能选用 RAID-10,而非 RAID-5
### 8.3 配置 CUP 相关
在服务器的 Bios 设置中,调整如下配置:
-
选择 Performance Per Watt Optimized(DAPC)模式,发挥 CPU 最大性能
-
关闭 C1E 和 C States 等选项,提升 CPU 效率
-
Memory Frequency(内存频率)选择 Maximum Performance
MySQL性能优化的21个最佳实践 和 mysql使用索引
今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我 们程序员需要去关注的事情。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。这里,我们不会讲过 多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库。希望下面的这些优化技巧对你有用。
1. 为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:

上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而 开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:

当我们为 group_id 字段加上索引后:

我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看rows列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)

4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。

从上图你可以看到那个搜索字串 “last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了4倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
5. 在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)

6. 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得 不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录

7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。

8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比 如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课 程ID叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在phpmyadmin里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议

一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
12. Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。
Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题, 而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
在性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而MySQL只会解析一次。
虽然最新版本的MySQL在传输Prepared Statements是使用二进制形势,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本5.1后支持了。
在PHP中要使用prepared statements,你可以查看其使用手册:mysqli 扩展 或是使用数据库抽象层,如: PDO.

13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大 量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用 mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
14. 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当 你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。

15. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改 写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有 好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户 ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
17. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:

18. 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
19. 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都 无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
target=”_blank”MyISAM Storage Engine
InnoDB Storage Engine
20. 使用一个对象关系映射器(Object Relational Mapper)
使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的PHP的ORM是:Doctrine。
21. 小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自 从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
PHP手册:mysql_pconnect()
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。
补充:
mysql强制索引和禁止某个索引
1、mysql强制使用索引:force index(索引名或者主键PRI)
例如:
select * from table force index(PRI) limit 2;(强制使用主键)
select * from table force index(ziduan1_index) limit 2;(强制使用索引”ziduan1_index”)
select * from table force index(PRI,ziduan1_index) limit 2;(强制使用索引”PRI和ziduan1_index”)
2、mysql禁止某个索引:ignore index(索引名或者主键PRI)
例如:
select * from table ignore index(PRI) limit 2;(禁止使用主键)
select * from table ignore index(ziduan1_index) limit 2;(禁止使用索引”ziduan1_index”)
select * from table ignore index(PRI,ziduan1_index) limit 2;(禁止使用索引”PRI,ziduan1_index”)
以上是关于一文看懂 MySQL 高性能优化技巧实践的主要内容,如果未能解决你的问题,请参考以下文章