每日一读GMC: Graph-Based Multi-View Clustering
Posted 海轰Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一读GMC: Graph-Based Multi-View Clustering相关的知识,希望对你有一定的参考价值。
目录
- 简介
- 论文简介
- Abstract
- 1 I NTRODUCTION
- 2 R ELATED W ORK
- 3 G RAPH -B ASED MULTI-V IEW C LUSTERING
- 6 CONCLUSIONS
- 结语

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)
论文简介
原文链接:https://ieeexplore.ieee.org/document/8662703
期刊:IEEE Transactions on Knowledge and Data Engineering ( Volume: 32, Issue: 4, 01 April 2020) (CCF A类)
年度:2020年6月1日(发表日期)
Abstract
基于多视图图的聚类旨在为多视图数据提供聚类解决方案
然而,大多数现有方法没有充分考虑不同视图的权重,并且需要额外的聚类步骤来生成最终的聚类,他们通常还基于所有视图的固定图相似度矩阵来优化他们的目标
在本文中,我们提出了一种通用的基于图的多视图聚类(GMC)来解决这些问题
- GMC 将所有视图的数据图矩阵融合起来,生成一个统一的图矩阵
- 统一的图矩阵反过来改进了每个视图的数据图矩阵,也直接给出了最终的聚类
GMC的关键新颖之处
- 在于它的学习方法,它可以帮助每个视图图矩阵的学习和统一图矩阵的学习以相互强化的方式进行
- 一种新颖的多视图融合技术可以自动加权每个数据图矩阵以得出统一的图矩阵
- 没有引入调整参数的秩约束也被施加在统一矩阵的图拉普拉斯矩阵上,这有助于将数据点自然地划分为所需数量的集群
- 提出了一种交替迭代优化算法来优化目标函数
使用玩具数据和真实世界数据的实验结果表明,所提出的方法明显优于最先进的基线。
1 I NTRODUCTION
当前机器学习的主要范式是在单个视图中表示的数据上运行算法。我们称这种范式为单视图学习,因为它不考虑来自其他视图的任何其他相关信息。
这与我们人类的学习相反。我们人类经常从不同的角度看待问题。这就是为什么我们可以全面而全面地解决问题。在许多现实生活中的问题中,多视图数据自然而然地出现了。例如,同一条新闻可能由不同的新闻机构报道,一张图片可能由不同类型的特征编码,在网站上分享的一张图片可能有不同的文字描述。所有这些都被称为多视图数据,其中每个单独的视图构成一个学习任务,但每个视图也有其偏差。
多视图数据的自然和频繁出现孕育了一种新的学习范式,称为多视图学习。在 [1]、[2] 中调查了关于这种新范式的现有研究。在本文中,我们专注于多视图无监督学习,特别是多视图聚类。多视图聚类探索和利用来自多个视图的互补信息,以产生比单视图聚类 [3]、[4] 更准确和更健壮的数据分区。我们将在下一节讨论相关工作。在这些多视图聚类方法中,一类具有代表性的方法是基于图的方法 [5]、[6]、[7]、[8]、[9]、[10]、[11]、[12] .图是表示各类对象之间关系的重要数据结构。图中的每个节点对应一个对象,每条边代表两个对象之间的关系。从广义上讲,现实世界中的每个对象都有各种关系图,因为每个对象都可以在不同的视图中进行采样,并且每个视图的采样数据可以形成一个图。例如,不同书目数据库(例如 DBLP 和 IEEE)中的作者可能根据他/她的论文有不同的关系图。 Facebook 或 Twitter 中的用户可以根据他/她的个人资料数据库和社交关系形成多个社交网络/图表。一个网页有它的出站链接图、入站链接图和引文链接图。聚类是数据挖掘的一个基本主题,尤其是在没有数据对象标签的情况下。聚类结果常用于后续应用,如社区检测、推荐、信息检索等。
基于多视图图的聚类方法通常
- 首先在所有视图的输入图中找到一个融合图
- 然后在该融合图上采用额外的聚类算法以产生最终的聚类
在这些方法中,每个视图的输入图通常由数据相似度矩阵生成,每个矩阵条目代表两个数据点的相似度
尽管这些方法已经实现了最先进的性能,但它们仍然存在一些局限性
- 首先,在某些方法中没有考虑不同视图重要性的差异,例如 [5]。我们的方法通过自动生成的权重来处理差异
- 其次,许多现有的方法需要一个额外的聚类步骤来在融合后产生最终的聚类,例如,[5]、[6]、[7]。我们的模型直接在融合中生成集群,无需额外的集群步骤
- 第三,大多数当前的方法是单独构建每个视图的图,并在融合过程中保持构建的图固定,例如,[5]、[6]、[7]、[9]、[10]、[12]。我们的方法联合构建每个视图图和融合图。因此,两种施工工艺自然相辅相成。据我们所知,没有现有的工作可以同时解决所有这三个限制。
在这项工作中,我们同时解决了这些限制,并首次使用联合框架制定了我们的解决方案。
为什么我们需要解决这三个限制?原因如下
- 首先,样本选择偏差[13]导致视图多样性
- 其次,额外的聚类步骤会带来额外的可能近似正确 (PAC) 界限 [14]
- 第三,不同的相似性度量对多视图聚类质量有影响[15]。
在本文中,我们提出了一种新颖的多视图聚类模型,称为基于图的多视图聚类(GMC)
- GMC不仅可以自动对每个视图进行加权,融合后直接生成最终的聚类,无需执行任何额外的聚类步骤
- 而且可以共同构建每个视图的图和融合图,从而相互帮助,相互增强
我们的 GMC 的整体流程如图 1 所示
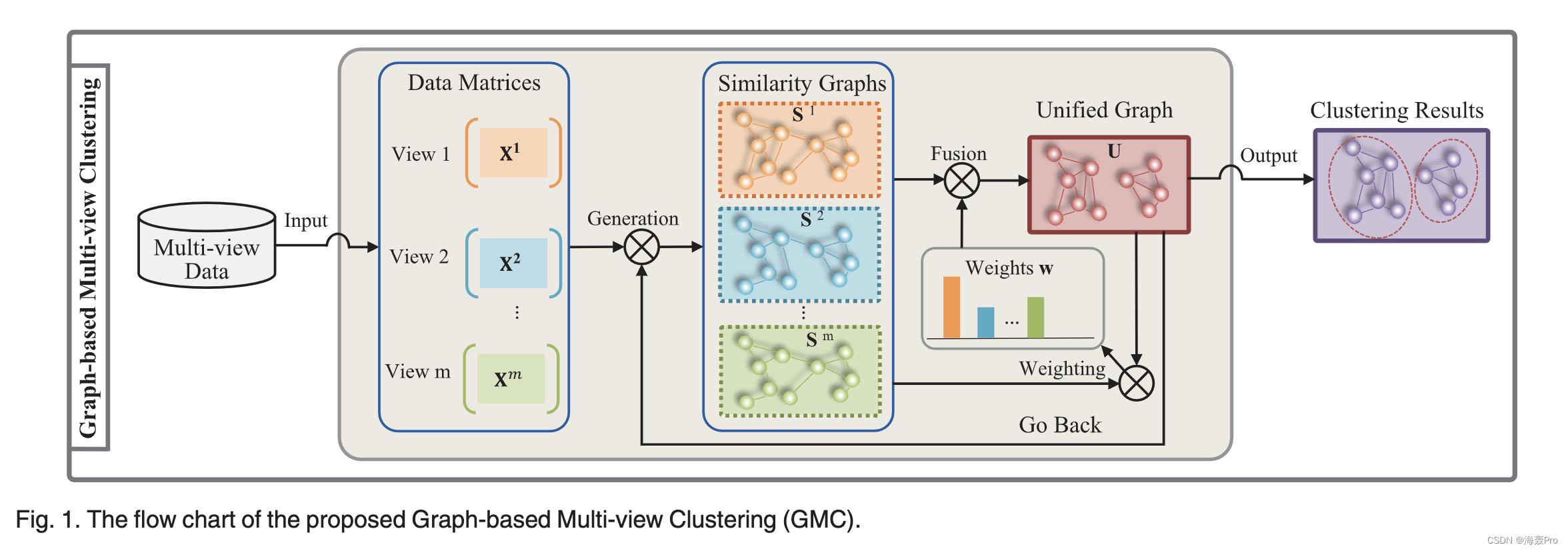
具体而言
- 首先将每个视图的数据矩阵转换为从相似图矩阵生成的图矩阵。我们将此图矩阵称为相似性诱导图 (SIG) 矩阵
- 然后将所提出的融合方法应用于所有视图的 SIG 矩阵,以便从 SIG 矩阵中学习统一矩阵(即融合图矩阵)U。 U 的学习会自动考虑不同视图 (v) 的不同权重 (wv)。同时,学习到的统一矩阵 U 回去改进每个视图的 SIG 矩阵。还对统一矩阵的拉普拉斯矩阵 LU 施加秩约束,以约束统一矩阵中的连通分量数等于所需的簇数 c。
因此,我们的模型 GMC 对每个视图的 SIG 矩阵进行加权和改进,并同时生成统一矩阵和最终集群。
综上所述,本文有以下贡献:
- 动机:它研究了一种先进的多视图聚类范式,并为多视图数据提供了一种新的聚类解决方案。
- 模型:它提出了一种通用的基于图的多视图聚类方法来解决当前方法的上述局限性。 GMC自动对每个视图进行加权,联合学习每个视图的图和融合图,融合后直接生成最终的聚类。值得注意的是,每个视图图的学习和融合图的学习可以互相帮助。
- 算法:它提出了一种交替迭代优化算法来解决GMC问题,其中每个子问题都有一个最优解。
- 结果:实验结果表明,所提出的 GMC 方法比最先进的基线方法有相当大的改进。
2 R ELATED W ORK
与我们最相关的工作是 [5]、[6]、[7]、[8]、[9]、[10]、[11]、[12] 中的那些,它们是现有的基于多视图图的聚类方法。然而,现有的基于图的方法不能同时处理上述限制。例如,[5] 中提出了一种基于 3 阶段图的多视图聚类方法,该方法利用子空间的图表示和分层凝聚聚类方法。它不考虑不同视图的权重。为此,在 [6]、[7] 中研究了基于加权多视图图的聚类。这两种方法首先为每个视图生成一个图,然后对每个图进行加权,为 K-means 构建一个统一的表示,从而生成最终的集群。 [8]、[9]、[10]、[11]、[12] 中介绍了更先进的加权方法。虽然这些方法在没有额外的聚类算法的情况下生成最终的集群,但它们独立地构建每个视图的图,并在融合期间保持构建的图固定,除了 [8] 和 [11],它们只学习所有视图的全局图(没有为每个视图构建图表)。我们提出的方法可以解决这些限制。我们还将通过实验与这些方法进行比较。除了上述方法中使用的成对相似度矩阵融合之外,在[16]、[17]中提出了通过交叉视图图随机游走的高阶相似度矩阵(即数据簇相似度矩阵)融合,其中数据聚类相似度是数据点与聚类中心的相似度。虽然这些方法可以避免成对相似矩阵的高计算复杂度,但它们需要运行额外的聚类算法。
我们的工作还与多视图光谱聚类[18]、[19]、[20]、[21]、[22]、[23]、[24]、[25]有关。谱聚类在由数据构成的图上运行,数据点作为节点,它们之间的边作为相似性 [21]。也就是说,谱聚类的输入也是一个相似图。与基于图的聚类的区别在于,谱聚类通常首先找到数据的低维嵌入表示,然后对这个嵌入表示执行 Kmeans 以产生最终的聚类。这样,多视图谱聚类也需要对嵌入表示进行额外的聚类步骤。基于图的聚类在构建的数据图上产生聚类,而不是新的嵌入表示,尽管它们中的大多数仍然需要额外的聚类步骤。我们的方法直接从数据的学习图中获得聚类指标。
除了基于多视图图的聚类和多视图谱聚类之外,还有一些其他类别的多视图聚类方法。其他相关的多视图聚类方法大致可分为三类:协同训练风格聚类[19]、[26]、[27]、[28]、多核聚类[29]、[30]、[ 31]、[32] 和多视图子空间聚类 [33]、[34]、[35]、[36]、[37]、[38]、[39]、[40]、[41]、[42] ,[43]。协同训练风格聚类使用协同训练策略 [44] 处理多视图数据。它通过使用彼此的先验或学习知识来引导不同视图的分区。通过迭代执行该策略,所有视图的划分达到最广泛的共识。多核聚类预先定义了一组基本核,然后将这些核进行线性或非线性组合以提高聚类性能。多视图子空间聚类旨在通过假设所有视图共享该统一表示,从所有视图的特征子空间中学习统一表示。然后,这个统一的表示被输入到聚类模型中以产生最终结果。一般来说,基于协同训练的方法依赖于条件独立,多核聚类方法计算复杂度高,多视图子空间聚类方法对初始化敏感。在实验部分(即第 5 部分),我们将把我们的模型与这些类别的代表性方法进行比较。
除了聚类之外,[45]、[46]、[47]、[48]、[49]、[50] 中还研究了多视图学习方法和应用,仅举几例
3 G RAPH -B ASED MULTI-V IEW C LUSTERING
…
6 CONCLUSIONS
本文提出了一种新的多视图聚类方法,称为基于图的多视图聚类
GMC 将每个视图的相似性诱导图的学习、所有视图的统一图的学习和聚类任务耦合到一个联合框架中
- 特别是,GMC 自动从所有视图的学习 SIG 中学习统一的融合图
- 学习到的统一图还可以帮助每个视图的 SIG 的学习使用图拉普拉斯矩阵的秩约束,统一图中的连通分量数等于所需的簇数
- 结果,在生成统一图的同时发现了聚类结构
通过与九个基线进行比较,两个玩具数据集和八个真实数据集的实验结果证明了所提出的 GMC 方法的优越性能
我们未来的工作包括设计一个更通用的框架,该框架适用于无监督环境和半监督环境
我们也有兴趣探索加速我们处理大规模数据的方法的技术。
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

以上是关于每日一读GMC: Graph-Based Multi-View Clustering的主要内容,如果未能解决你的问题,请参考以下文章
每日一读:《关于python2和python3中的range》