Transformer综述(A Survey on Vision Transformer) 阅读学习笔记--Transformer应用的图像处理与视频处理的研究
Posted 大黑山修道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer综述(A Survey on Vision Transformer) 阅读学习笔记--Transformer应用的图像处理与视频处理的研究相关的知识,希望对你有一定的参考价值。
论文综述:

文章主旨:在本文中,我们回顾了这些视觉Transformer模型,将它们分为不同的任务,并分析了它们的优缺点。我们探讨的主要类别包括主干网络、高/中级视觉、低级视觉和视频处理。我们还包括有效的Transformer方法,用于将Transformer推进基于设备的实际应用。此外,我们还简要介绍了计算机视觉中的自我注意机制,因为它是Transformer的基本组成部分。在本文的最后,我们讨论了视觉Transformer面临的挑战,并提供了几个进一步的研究方向。
其他章节:
Transformer综述(A Survey on Vision Transformer) 阅读学习笔记(一)----transformer的发展,transformer的基本结构和原理
Transformer综述(A Survey on Vision Transformer) 阅读学习笔记(二)-- transformer在计算机视觉领域的发展和应用
Transformer综述(A Survey on Vision Transformer) 阅读学习笔记(四)–高效Transformer、计算机视觉的自注意力、Transformer的总结与展望
A Survey on Vision Transformer
3.3 Low-level Vision 低层视觉领域
很少有作品将Transformer应用于低层视觉领域,如图像的超分辨率和生成。这些任务通常将图像作为输出(例如,高分辨率或去噪图像),这比诸如分类、分割和检测的高级视觉任务更具挑战性,后者的输出是标签或盒子。
3.3.1 Image Generation 图像生成
Parmaret al.[171]提出了图像Transformer(Image Transformer),向推广转换器模型以制定图像转换和生成任务迈出了第一步。图像Transformer由两部分组成:用于提取图像表示的编码器和用于生成像素的解码器。对于值为0的−255中的每个像素,学习256×d维嵌入,将每个值编码成附加向量,该向量作为输入输入编码器。编码器和解码器采用与[225]中相同的架构。每个输出像素q0是通过计算输入像素q与先前生成的像素1,m2,…之间的自关注来生成的,其中位置嵌入了p1,p2,…。对于图像条件生成,例如超分辨率和修复,使用编码器-解码器架构,其中编码器的输入是低分辨率或损坏的图像。对于无条件和类别条件生成(即,图像的噪声),仅解码器用于输入噪声向量。
由于解码器的输入是先前生成的像素(在生成高分辨率图像时需要很高的计算代价),因此提出了一种局部自关注方案。该方案只使用最近生成的像素作为解码器的输入,使得Image Transformer在图像生成和翻译任务中的性能与基于CNN的模型相当,展示了基于变压器的模型在低层视觉任务中的有效性。
[171]: Image transformer. InICML, pages 4055–4064. PMLR, 2018.
[225]: Attention is all you need.NeurIPS, 30:5998–6008, 2017.
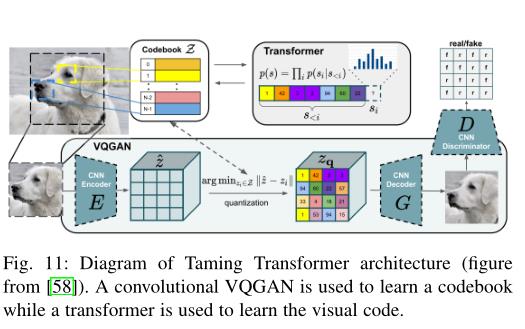
由于变压器模型很难直接生成高分辨率图像,Esseret等人在[58]中提出了驯化变压器(Taming Transformer)。如图11所示,Taming Transformer由两部分组成:VQGAN和变压器。VQGAN是VQV AE[165]的变体,它使用鉴别器和知觉损失来改善视觉质量。通过VQGAN,图像可以用一系列上下文丰富的离散向量来表示,因此这些向量可以很容易地被变压器模型通过自回归的方式来预测。变压器模型可以学习远程交互作用,以生成高分辨率图像。因此,建议的驯服变压器在各种图像合成任务中实现了最先进的结果。
除了图像生成,Dall·E[185]还提出了文本到图像生成的转换器模型,该模型根据给定的字幕合成图像。整个框架由两个阶段组成。在第一阶段,利用离散的VAE学习视觉码本。在第二阶段,文本被BPE编码解码,相应的图像被第一阶段学习的DVAE解码。然后使用自回归变换学习编码文本和图像之间的先验。在推理过程中,转换器预测图像的标记,并由学习的解码器解码。引入剪辑模型[180]来对生成的样本进行排序。在文本到图像生成任务上的实验证明了该模型的强大能力。请注意,我们的调查主要集中在纯视觉任务上,图13中没有包括Dall·E的框架。
与以往采用自回归模型生成图像的工作不同,Jianget et al.[111]提出了TransGAN,它使用变压器结构来构建GaN。由于很难生成像素级的高分辨率图像,因此采用记忆友好的生成器,在不同阶段逐步提高特征地图的分辨率。相应地,设计了一个多尺度鉴别器来处理不同阶段不同大小的输入。通过引入网格自关注、数据增强、相对位置编码和修正归一化等训练方法,稳定了训练过程,提高了训练性能。在不同基准数据集上的实验证明了基于变压器的GaN模型在图像生成任务中的有效性和潜力。
[58]: Taming transformers for high-resolution image synthesis. InCVPR, pages 12873–12883, 2021.
[165]: Neural discrete representation learning.arXiv preprint arXiv:1711.00937, 2017.
[185]: Zero-shot text-to-image generation. InICML, 2021.
[180]: Learning transferable visual models from natural language supervision.arXiv preprint arXiv:2103.00020, 2021.
[111]: Transgan: Two transformers can make one strong gan.arXiv preprint arXiv:2102.07074, 2021.
3.3.2 Image Processing 图像处理
许多最近的作品避免使用每个像素作为变压器模型的输入,而是使用补丁(像素集)作为输入。例如,y anget al. [251]提出了用于图像超分辨率(ttsr)的纹理变换网络,使用了基于参考的图像超分辨率问题中的变换器架构。它的目的是将相关的纹理从参考图像转移到低分辨率图像。以一幅低分辨率图像和一幅参考图像分别作为查询 q 和键 k,在 q 中的每个补丁 qi 和 k 中的 ki 之间计算相关子r(i,j)为:
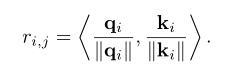
提出了一种硬注意模块,根据参考图像选择高分辨率的特征 v,利用相关性对低分辨率图像进行匹配。注意力分布图是这样计算的:

利用高分辨率纹理图像的转换特征和低分辨率特征生成低分辨率图像的输出特征。通过利用基于转换器的结构,ttsr 可以成功地将高分辨率参考图像的纹理信息转换为低分辨率图像,完成超分辨率任务。
不同于以往单一任务使用变压器模型的方法,chenet al. [27]提出了图像处理转换器(ipt) ,它充分利用了变压器的优点,通过使用大量的预训练数据集。它在几个图像处理任务中实现了最先进的性能,包括超分辨率、去噪和解除链。如图12所示 ipt 由多个头,编码器,解码器和多个尾部组成。针对不同的图像处理任务,引入了多头、多尾结构和任务嵌入。特征被分割成小块,并输入到编解码器结构中。然后,输出被重新组合成相同大小的特征。鉴于在大型数据集上预训练转换模型的优势,ipt 使用图像集数据集进行预训练。具体来说,来自这个数据集的图像通过手动添加噪音,雨条纹,或降采样来生成损坏的图像。降质后的图像作为IPT的输入,而原始图像作为输出的优化目标。为了增强IPT模型的泛化能力,还引入了一种自监督方法。一旦对模型进行了训练,就会使用相应的头、尾和任务嵌入对每个任务进行微调。IPT在很大程度上提高了图像处理任务的性能(例如,图像去噪任务中的2分贝),展示了将基于变压器的模型应用于低层视觉领域的巨大潜力。
除了单幅图像的生成,Wanget等人在[234]中提出将SceneFormer用于3D室内场景的生成。通过将场景视为一系列对象,变压器解码器可用于预测一系列对象及其位置、类别和大小。这使得SceneFormer在用户研究中的表现优于传统的基于CNN的方法。
应该注意的是,IGPT[29]是在类似修复的任务上预先训练的。由于iGPT主要关注图像分类任务的微调性能,所以我们将这项工作看作是对基于变换的图像分类任务的一种尝试,而不是对低层视觉任务的尝试。
[27]: Pre-trained image processing transformer. InCVPR, 2021.
[29]: Generative pretraining from pixels. InInternational Conference on Machine Learning, pages 1691–1703. PMLR, 2020.
[234]: Sceneformer: Indoor scene generation with transformers.arXiv preprint arXiv:2012.09793, 2020.
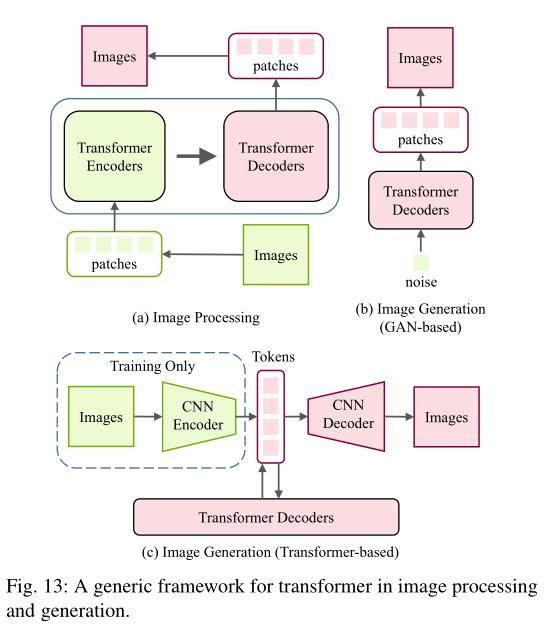
总之,与分类和检测任务不同,图像生成和处理的输出是图像。图13说明了在低级视野中使用转换器。在图像处理任务中,图像首先被编码成令牌或补丁序列,并且变压器编码器使用该序列作为输入,从而允许变压器解码器成功地产生所需的图像。在图像生成任务中,基于GaN的模型直接学习解码器生成补丁并通过线性投影输出图像,而基于变压器的模型训练自动编码器学习图像的码本,并使用自回归变压器模型预测编码后的令牌。为不同的图像处理任务设计合适的体系结构将是未来研究的一个有意义的方向。
3.4 Video Processing 视频处理
转换器在基于序列的任务,特别是NLP任务上执行得出奇地好。在计算机视觉(具体地说,视频任务)中,空间和时间维度信息受到青睐,导致转换器在许多视频任务中的应用,例如帧合成[149]、动作识别[74]和视频检索[142]。
3.4.1 High-level Video Processing 高级视频处理
Video Action Recognition. 视频动作识别
视频人类动作任务,顾名思义,涉及识别和定位视频中的人类动作。语境(如其他人和物体)在识别人类行为方面起着至关重要的作用。Rohitet等人提出了动作转换器[74]来对感兴趣的人和周围环境之间的潜在关系进行建模。具体地说,i3D[20]被用作提取高级特征地图的主干。从中间特征图提取的特征(使用ROI池)被视为查询(Q),而关键字(K)和值(V)是从中间特征计算的。对这三个部分应用自我注意机制,并输出分类和回归预测。Lohitet et al.[152]提出了一种可解释的微分模型,称为时态变换网络,以减少类内方差和增加类间方差。此外,Fayyaz和Gall提出了一个时间转换器[65]来在弱监督环境下执行动作识别任务。除了人类行为识别之外,转换器还被用于群体活动识别[42]。Gavrilyuket等人提出了一种用2D和3D网络生成的静态和动态表示作为输入来学习表示的电抗器[72]架构。变压器的输出是预测的活动。
[74]: Video action transformer network. InCVPR, pages 244–253, 2019.
[20]: Quo vadis, action recognition? a new model and the kinetics dataset. InCVPR, pages 6299–6308, 2017.
[152]: Temporal transformer networks: Joint learning of invariant and discriminative time warping. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12426–12435, 2019.
[65]: Sct: Set constrained temporal transformer for set supervised action segmentation. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 501–510, 2020.
[42]: What are they doing?: Collective activity classification using spatio-temporal relationship among people. In2009 IEEE 12th international conference on computer vision work- shops, ICCV Workshops, pages 1282–1289. IEEE, 2009.
[72]: Actor-transformers for group activity recognition. InCVPR, pages 839–848, 2020.
Video Retrieval 视频检索
基于内容的视频检索的关键是找出视频之间的相似度。Shaoet al.[194]建议仅利用视频级特征的图像级别来克服相关挑战,并建议使用转换器对长期语义依赖进行建模。他们还引入了有监督的对比学习策略来进行硬性负挖掘。在基准数据集上的实验结果表明了该方法在性能和速度上的优势。此外,Gabeuret al.[70]提出了一种多模态转换器来学习不同的跨模态线索来表示视频。
[194]: Temporal context aggregation for video retrieval with contrastive learning.
[70]: Multi-modal transformer for video retrieval. InECCV, pages 214–229, 2020.
Video Object Detection 视频对象检测
要检测视频中的对象,需要全局和局部信息。Chenet等人引入了内存增强型全局-局部聚合(MEGA)[34]来捕获更多内容。具有代表性的特点提升了整体性能,解决了效果不佳和不足的问题。此外,Yinet al.[258]还提出了一种时空变换来聚合空间和时间信息。与另一个空间特征编码组件一起,这两个组件在3D视频对象检测任务中表现良好。
[34]: Memory enhanced global-local aggregation for video object detection. InCVPR, pages 10337–10346, 2020.
[258]: Lidar-based online 3d video object detection with graph-based message passing and spatiotemporal transformer attention. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11495–11504, 2020.
Multi-task Learning 多任务学习
未裁剪的视频通常包含许多与目标任务无关的帧。因此,挖掘相关信息,剔除冗余信息是至关重要的。为了提取这样的信息,Seonget等人提出了视频多任务转换网络[192],它处理未裁剪视频的多任务学习。对于CoVieW数据集,其任务是场景识别、动作识别和重要性得分预测。ImageNet和Places365上的两个预先训练的网络提取场景特征和对象特征。利用类转换矩阵(CCM)堆叠多任务转换器以实现特征融合。
[192]: Video multitask transformer network. InICCV Workshops, pages 0–0, 2019.
3.4.2 Low-level Video Processing 低级视频处理
Frame/Video Synthesis 帧/视频合成
帧合成任务涉及合成两个连续帧之间或帧序列之后的帧,而视频合成任务涉及合成视频。Liuet等人提出了ConvTransformer[149],它由五个组件组成:特征嵌入、位置编码、编码器、查询解码器和综合前馈网络。与基于LSTM的Works相比,ConvTransformer以更可并行化的体系结构获得了更好的结果。另一种基于变压器的方法是由Schatzet等人提出的[191],它使用一个循环的变压器网络来从新的视角合成人类的行为。
[149]: Convtrans-former: A convolutional transformer network for video frame synthesis. arXiv preprint arXiv:2011.10185, 2020.
[191]: A recurrent transformer network for novel view action synthesis. InECCV (27), pages 410–426, 2020.
Video Inpainting 视频修复
视频修复任务涉及完成帧内任何缺失的区域。这很有挑战性,因为它需要将空间和时间维度上的信息合并。Zenget等人提出了一种时空变换网络[268],它使用所有输入帧作为输入,并并行填充它们。利用时空对抗性损耗对变压器网络进行优化。
[268]: Learning joint spatial-temporal trans- formations for video inpainting. InECCV, pages 528–543. Springer, 2020.
3.4.3 Discussions
与图像相比,视频具有额外的维度来编码时间信息。同时利用空间和时间信息有助于更好地理解视频。由于变压器的关系建模能力,通过同时挖掘空间和时间信息,视频处理任务得到了改善。然而,由于视频数据的高度复杂性和冗余性,如何高效、准确地对空间和时间关系进行建模仍然是一个悬而未决的问题。
3.5 Multi-Modal Tasks 多通道任务
由于Transform在基于文本的自然语言处理任务上的成功,许多研究都热衷于挖掘其在处理多模式任务(如视频-文本、图像-文本和音频-文本)方面的潜力。这方面的一个例子是VideoBERT[206],它使用基于CNN的模块对视频进行预处理以获得表示令牌。然后,转换器编码器对这些令牌进行训练,以学习下游任务(如视频字幕)的视频-文本表示。其他一些例子包括VisualBERT[127]和VL-BERT[204],它们采用单流统一转换器来捕获视觉元素和图文关系,用于下游任务,如视觉问答(VQA)和视觉常识推理(VCR)。此外,SpeechBERT[45]等多项研究探索了使用转换器编码器对音频和文本对进行编码的可能性,以处理语音问答(SQA)等自动文本任务。
[206]: Videobert: A joint model for video and language representation learning. InICCV, pages 7464–7473, 2019.
[127]: Visualbert: A simple and performant baseline for vision and language.arXiv preprint arXiv:1908.03557, 2019.
[204]: Vl-bert: Pre-training of generic visual-linguistic representations.arXiv preprint arXiv:1908.08530, 2019.
[45]: Speechbert: Cross-modal pre-trained language model for end-to-end spoken question answering. arXiv preprint arXiv:1910.11559, 2019.
除了前面提到的开创性的多模态转换器,对比语言-图像预训练(CLIP)[180]以自然语言为指导,学习更有效的图像表征。CLIP联合训练文本编码器和图像编码器来预测对应的训练文本-图像对。CLIP的文本编码器是一个带有掩蔽自我注意的标准转换器,用于保持预先训练的语言模型的初始化能力。对于图像编码器,Clip考虑了两种架构,ResNet和Vision Transformer。在包含从互联网收集的4亿(图像、文本)对的新数据集上训练CLIP。更具体地说,在给定一批n个(图像,文本)对的情况下,CLIP联合学习文本和图像嵌入,以最大化N个匹配嵌入的余弦相似度,同时最小化N2个正确匹配的嵌入−。在零镜头传输上,CLIP表现出惊人的零镜头分类性能,在ImageNet-1K数据集上无需使用任何ImageNet训练标签就达到了76.2%的TOP-1准确率。具体地说,在推理时,CLIP的文本编码器首先计算所有ImageNet标签的特征嵌入,然后图像编码器计算所有图像的嵌入。通过计算文本和图像嵌入的余弦相似度,得分最高的文本-图像对应该是图像及其对应的标签。在30个不同CV基准上的进一步实验表明了CLIP的零镜头迁移能力和CLIP学习到的特征多样性。
当裁剪根据文本中的描述映射图像时,另一作品Dall-E[185]合成输入文本中描述的类别的新图像。与GPT-3类似,DALL-E是一种多模式转换器,具有120亿个模型参数,在330万个文本-图像对的数据集上进行自回归训练。更具体地说,为了训练DALL-E,使用了两阶段训练过程,其中在阶段1中,使用离散变分自动编码器将256×256 RGB图像压缩成32×32个图像令牌,然后在阶段2中,训练自回归变换器来对图像和文本令牌上的联合分布进行建模。实验结果表明,Dall-E可以从头开始生成各种风格的图像,包括照片级真实感图像、卡通和表情符号,或者扩展现有的图像,同时仍然与文本中的描述相匹配。随后,Dinget等人提出了CogView[51],这是一种具有类似于Dall-E的VQ-V AE标记器的转换器,但支持中文文本输入。他们声称,CogView的性能优于Dall-E和以前的Gan-bsed方法,而且与Dalle不同的是,CogView不需要额外的剪辑模型来重新排序从变压器中提取的样本,即DALL-E。
[185]: Zero-shot text-to-image generation. InICML, 2021.
[51]: Cogview: Mastering text-to-image generation via transformers.arXiv preprint arXiv:2105.13290, 2021.
当裁剪根据文本中的描述映射图像时,另一作品Dall-E[185]合成输入文本中描述的类别的新图像。与GPT-3类似,DALL-E是一种多模式转换器,具有120亿个模型参数,在330万个文本-图像对的数据集上进行自回归训练。更具体地说,为了训练DALL-E,使用了两阶段训练过程,其中在阶段1中,使用离散变分自动编码器将256×256 RGB图像压缩成32×32个图像令牌,然后在阶段2中,训练自回归变换器来对图像和文本令牌上的联合分布进行建模。实验结果表明,Dall-E可以从头开始生成各种风格的图像,包括照片级真实感图像、卡通和表情符号,或者扩展现有的图像,同时仍然与文本中的描述相匹配。随后,Dinget等人提出了CogView[51],这是一种具有类似于Dall-E的VQ-V AE标记器的转换器,但支持中文文本输入。他们声称,CogView的性能优于Dall-E和以前的Gan-bsed方法,而且与Dalle不同的是,CogView不需要额外的剪辑模型来重新排序从变压器中提取的样本,即DALL-E。
最近,人们提出了一种处理多模态多任务学习的统一变压器(单元)[100]模型,该模型可以同时处理不同领域的多个任务,包括目标检测、自然语言理解和视觉语言推理。具体地说,单元有两个转换器编码器,分别处理图像和文本输入,然后转换器解码器根据任务模态获取单个或串联的编码器输出。最后,针对不同的任务,将特定于任务的预测头应用于解码器输出。在训练阶段,通过在迭代中随机选择特定任务来联合训练所有任务。实验表明,在紧凑的模型参数集合下,单元在每一项任务上都取得了令人满意的性能。
[100]: Unit: Multimodal multitask learning with a unified transformer.arXiv preprint arXiv:2102.10772, 2021.
综上所述,基于电流互感器的多模态模型在统一各种模态的数据和任务方面显示了其体系结构的优越性,显示了变压器构建能够处理大量应用的通用智能代理的潜力。未来的研究可以在探索多模态变压器的有效培训或可扩充性方面进行。
综述A Comprehensive Survey on Graph NeuralNetworks
目录
- 前言
- 专业名词
- 笔记
- 结语

前言
Hello!小伙伴!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
文章仅作为自己的学习笔记 用于知识体系建立以及复习
知其然 知其所以然!
专业名词
- directed acyclic graph 有向无环图
笔记
Recurrent Graphneural networks 递归图神经网络
Recurrent graph neural networks (RecGNNs) are mostly pi-oneer works of GNNs. They apply the same set of parametersrecurrently over nodes in a graph to extract high-level noderepresentations. Constrained by computational power, earlierresearch mainly focused on directed acyclic graphs [13], [80].
递归图神经网络(Recurrent graph neural networks,RECGNN)是GNN的重要组成部分。它们在图中的节点上应用相同的参数集来提取高级节点表示。受计算能力的限制,早期的研究主要集中在有向无环图[13],[80]。
Graph Neural Network (GNN2) proposed by Scarselli etal. extends prior recurrent models to handle general types ofgraphs, e.g., acyclic, cyclic, directed, and undirected graphs[15]. Based on an information diffusion mechanism, GNNupdates nodes’ states by exchanging neighborhood informationrecurrently until a stable equilibrium is reached.
Scarselli等人提出的图形神经网络(GNN*2)。扩展了以前的递归模型,以处理一般类型的图,例如无环图、循环图、有向图和无向图[15]。基于信息扩散机制,GNN通过反复交换邻域信息来更新节点状态,直到达到稳定平衡 。
Gated Graph Neural Network (GGNN) [17] employs a gatedrecurrent unit (GRU) [81] as a recurrent function, reducing therecurrence to a fixed number of steps. The advantage is that itno longer needs to constrain parameters to ensure convergence
门控图神经网络(GGNN)[17]使用门控电流单元(GRU)[81]作为递归函数,将递归减少到固定的步数。优点是它不再需要约束参数以确保收敛
A node hidden state is updated by its previous hidden statesand its neighboring hidden states, defined a
节点隐藏状态由其以前的隐藏状态及其相邻的隐藏状态(定义为

Different from GNN* and GraphESN,GGNN uses the back-propagation through time (BPTT) algo-rithm to learn the model parameters. This can be problematicfor large graphs, as GGNN needs to run the recurrent functionmultiple times over all nodes, requiring the intermediate statesof all nodes to be stored in memory
与GNN*和GraphESN不同,GGNN使用时间反向传播(BPTT)算法来学习模型参数。这对于大型图来说可能是个问题,因为GGNN需要在所有节点上多次运行递归函数,需要将所有节点的中间状态存储在内存中
Stochastic Steady-state Embedding (SSE) proposes a learn-ing algorithm that is more scalable to large graphs [18]. SSEupdates node hidden states recurrently in a stochastic andasynchronous fashion. It alternatively samples a batch of nodesfor state update and a batch of nodes for gradient computation.To maintain stability, the recurrent function of SSE is definedas a weighted average of the historical states and new states,which takes the form
随机稳态嵌入(SSE)提出了一种学习算法,该算法更适用于大型图[18]。SSE以随机同步的方式重复更新节点隐藏状态。它也可以对一批节点进行采样以进行状态更新,并对一批节点进行梯度计算。为了保持稳定性,SSE的回归函数定义为历史状态和新状态的加权平均,其形式为
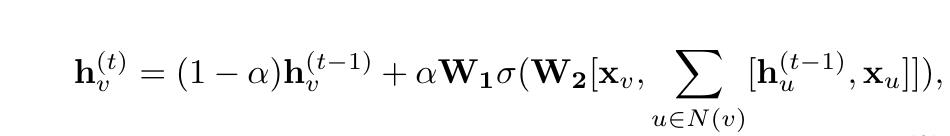
Convolutional graph neural networks 卷积图神经网络(ConvGNNs)
Instead of iterating node states with contractive constraints, ConvGNNsaddress the cyclic mutual dependencies architecturally using afixed number of layers with different weights in each layer
onvGNN不使用压缩约束来迭代节点状态,而是使用固定数量的层,在每层中使用不同的权重,在体系结构上解决循环相互依赖关系。
RecGNNs v.s. ConvGNNs
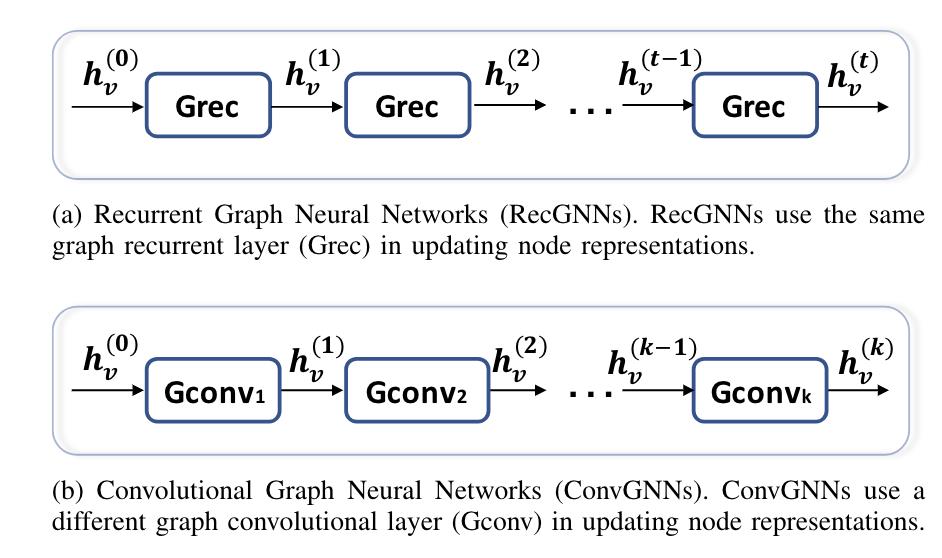
- RECGNS在更新节点表示时使用同样的图递归层(Grec)
- ConvGNS在更新节点表示时使用不同的图卷积层(Gconv)
ConvGNNs fallinto two categories, spectral-based and spatial-based.
ConvGNS分为两类,基于光谱的和基于空间的。
Spectral-based ConvGNNs 基于光谱的ConvGNS
Spectral CNN facesthree limitations. First, any perturbation to a graph results ina change of eigenbasis. Second, the learned filters are domaindependent, meaning they cannot be applied to a graph with adifferent structure. Third, eigen-decomposition requiresO(n3)computational complexity. In follow-up works, ChebNet [21]and GCN [22] reduce the computational complexity toO(m)by making several approximations and simplifications
基于光谱的CNN面临三个限制:
- 首先,对图的任何扰动都会导致特征基的变化。
- 其次,学习到的过滤器依赖于域,这意味着它们不能应用于具有不同结构的图。
- 第三,特征分解需要计算复杂度。
在后续工作中,ChebNet[21]和GCN[22]通过进行多次近似和简化,也降低了计算复杂度(m)
Spatial-based ConvGNNs 基于空间的convgns
Analogous to the convolutional operation of a conventionalCNN on an image, spatial-based methods define graph convo-lutions based on a node’s spatial relations.
与传统CNN对图像的卷积运算类似,基于空间的方法基于节点的空间关系定义图卷积。
The spatial graph convolutional operationessentially propagates node information along edges
空间图卷积运算本质上是沿着边传播节点信息
Comparison between spectral and spatial models 光谱模型和空间模型的比较
spatial modelsare preferred over spectral models due to efficiency, generality,and flexibility issues.
由于效率、通用性和灵活性问题,空间模型优于光谱模型。
First, spectral models are less efficientthan spatial models. Spectral models either need to performeigenvector computation or handle the whole graph at thesame time. Spatial models are more scalable to large graphsas they directly perform convolutions in the graph domain viainformation propagation.
首先,光谱模型的效率低于空间模型。
- 光谱模型要么需要进行矢量计算,要么同时处理整个图形。
- 空间模型更适合于大型图形,因为它们通过信息传播直接在图形域中执行卷积。
Second, spectral models which rely on a graph Fourier basis generalize poorly to new graphs. They assume a fixed graph. Any perturbationsto a graph would result in a change of eigenbasis. Spatial-based models, on the other hand, perform graph convolutionslocally on each node where weights can be easily shared acrossdifferent locations and structures.
其次,依赖于图傅里叶基的谱模型很难推广到新的图。他们假设一个固定的图形。对图形的任何扰动都会导致特征基的变化。另一方面,基于空间的模型在每个节点上局部执行图卷积,在这些节点上,权重可以很容易地跨不同的位置和结构共享。
Third, spectral-based modelsare limited to operate on undirected graphs. Spatial-basedmodels are more flexible to handle multi-source graph inputssuch as edge inputs [15], [27], [86], [95], [96], directed graphs[25], [72], signed graphs [97], and heterogeneous graphs [98],[99], because these graph inputs can be incorporated into theaggregation function easily
第三,基于谱的模型仅限于对无向图进行操作。基于空间的模型更灵活地处理多源图形输入,例如边输入[15]、[27]、[86]、[95]、[96]、有向图[25]、[72]、符号图[97]和异构图[98]、[99],因为这些图形输入可以很容易地合并到聚合函数中
Graph Pooling Modules 图池模块
After a GNN generates node features, we can use themfor the final task. But using all these features directly can becomputationally challenging, thus, a down-sampling strategyis needed. Depending on the objective and the role it playsin the network, different names are given to this strategy: (1)the pooling operation aims to reduce the size of parametersby down-sampling the nodes to generate smaller representa-tions and thus avoid overfitting, permutation invariance, andcomputational complexity issues; (2) the readout operation ismainly used to generate graph-level representation based onnode representations.
在GNN生成节点特征后,我们可以将它们用于最终任务。但直接使用所有这些特性可能会带来计算上的挑战,因此,需要一种下采样策略。
根据目标及其在网络中扮演的角色,该策略有不同的名称:
- (1)池操作旨在通过对节点进行下采样来减少参数的大小,从而生成更小的表示,从而避免过度拟合、排列不变性,以及计算复杂性问题;
- (2) 读出操作主要用于基于节点表示生成图形级表示。
它们的机制非常相似。
VC dimension VC维度
The VC dimension is a measure of modelcomplexity defined as the largest number of points that canbe shattered by a model.
VC维度是模型复杂度的度量,定义为一个模型可以打破的最大点数
Graph isomorphism 图同构
Two graphs are isomorphic if they aretopologically identical
如果两个图在拓扑上相同,那么它们是同构的
Equivariance and invariance 等变与不变性
A GNN must be an equivariantfunction when performing node-level tasks and must be aninvariant function when performing graph-level tasks
GNN在
- 执行节点级任务时必须是一个等变量函数,
- 执行图形级任务时必须是一个变量函数
In order to achieveequivariance or invariance, components of a GNN must beinvariant to node orderings. Maron et al.
为了实现等效性或不变性,GNN的组件必须随节点顺序而变化
Universal approximation 万能近似
It is well known that multi-perceptron feedforward neural networks with one hidden layercan approximate any Borel measurable functions [105]
众所周知,具有一个隐藏层的多感知器前馈神经网络可以逼近任何Borel可测函数[105]
结语
参考:《A Comprehensive Survey on Graph NeuralNetworks》
总结:有一些专业名词还是不太认识,速度很慢,只能了解一些概念上的大概,详细原理没有深入了解
文章仅作为学习笔记,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

以上是关于Transformer综述(A Survey on Vision Transformer) 阅读学习笔记--Transformer应用的图像处理与视频处理的研究的主要内容,如果未能解决你的问题,请参考以下文章