基于MapReduce实现用户基础数据统计
Posted pblh123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MapReduce实现用户基础数据统计相关的知识,希望对你有一定的参考价值。
CSDN话题挑战赛第2期
参赛话题:大数据学习成长记录
文章目录
使用MapReduce实现用户基础数据统计
基础数据
项目原始数据如下
create table ods_t_bank(
id INT COMMENT '表自增主键',
age INT COMMENT '年龄',
job STRING COMMENT '工作类型',
marital STRING COMMENT '婚否',
education STRING COMMENT '教育程度',
credit STRING COMMENT '是否有信用卡',
housing STRING COMMENT '房贷',
loan STRING COMMENT '贷款',
contact STRING COMMENT '联系途径',
month_of_year STRING COMMENT '月份',
day_of_week STRING COMMENT '星期几',
duration INT COMMENT '持续时间',
campaign INT COMMENT '本次活动联系的次数',
pdays INT COMMENT '与上一次联系的时间间隔',
previous INT COMMENT '之前与客户联系的次数',
poutcome STRING COMMENT '之前市场活动的结果',
emp_var_rate DOUBLE COMMENT '就业变化速率',
cons_price_idx DOUBLE COMMENT '消费者物价指数',
cons_conf_idx DOUBLE COMMENT '消费者信心指数',
euribor3m DOUBLE COMMENT '欧元存款利率',
nr_employed DOUBLE COMMENT '职工人数',
y TINYINT COMMENT '是否有定期存款'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t';
原始数据存储在mysql数据库中,可以通过Sqoop或者DataX导入到hive,这块教程参照后续博客
业务分析点
基于原始数据,可知用户的基本统计指标有:
- 教育程度分析
- 年龄分析
- 年龄小于40 -> 年轻人
- 年龄介于40~60 -> 中年人
- 年龄大于60 -> 老年人
- 其他分析项(可依据数据自由扩展)
业务开发流程
MR开发流程图
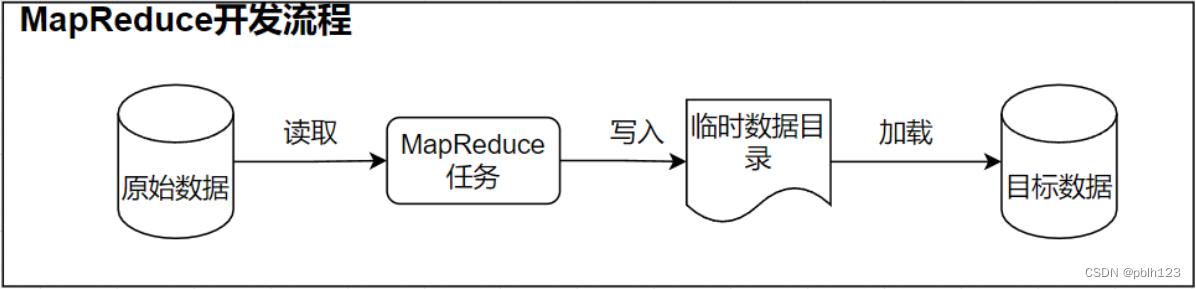
在Hive中创建hive表
-- 配合java开发的MR需要更新字段的分隔符
drop table if exists dws.dws_t_bank_age;
CREATE TABLE dws.dws_t_bank_age
(age string,
num int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' LINES TERMINATED BY '\\n' STORED AS TEXTFILE;
drop table if exists dws.dws_t_bank_edu;
create table dws.dws_t_bank_edu(
education string,
num int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' LINES TERMINATED BY '\\n' STORED AS TEXTFILE;
基于Java开发MR
在idea-community中中开发MR
配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.huike</groupId>
<artifactId>bank_v2</artifactId>
<version>1.2</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.7.3</hadoop.version>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.8</spark.version>
<java.version>1.8</java.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-annotations</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>$scala.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>$hadoop.version</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.50.Final</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.7</version>
</dependency>
<!-- 添加对应的 jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 这是个编译java代码的 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>8</source>
<target>8</target>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 这是个编译scala代码的 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 将依赖也进行打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.5</version>
<configuration>
<!--<archive>
<manifest>
<mainClass>com.xxg.Main</mainClass>
</manifest>
</archive>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
开发com.lh.banksys.mr.AgeStatJob
package com.lh.banksys.mr;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @Classname AgeStatJob
* @Description 年龄阶段统计分析
* @Date 2021/10/14 19:14
* @Created by Tiger_Li
*/
public class AgeStatJob
public static class AgeStatMap extends Mapper<Object, Text, Text, IntWritable>
// private static Text newKey =new Text();
public void map(Object key, Text value, Context context)throws IOException, InterruptedException
String[] words = StringUtils.split(value.toString(), '\\001');
if(words[0] != "" && StringUtils.isNotEmpty(words[0]))
int age = Integer.parseInt(words[0]);
if(age <= 40)
context.write(new Text("young"), new IntWritable(1));
else if(age > 40 && age <=60)
context.write(new Text("middle"), new IntWritable(1));
else
context.write(new Text("old"), new IntWritable(1));
public static class AgeStatReducer extends Reducer<Text, IntWritable, Text, IntWritable>
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException
int sum = 0;
for(IntWritable i : values)
sum += i.get();