无损半同步复制下,主从切换后数据一致吗?
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无损半同步复制下,主从切换后数据一致吗?相关的知识,希望对你有一定的参考价值。
作者:芬达
“芬达的数据库学习笔记" 公众号作者,国内最活跃 mysql ocp 考试讨论群群主,群号:120242978 。
本文来源:原创投稿
* 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
高能警告,因作者能力有限,文章的分析过程没有基于 MySQL 源码,而是根据一些业界大佬的文章和官方文档整理和思考得出的结论,如果觉得说得有道理,请点个赞,如果觉得胡说八道请留言。本文的受众是至少已经入门 MySQL 的 DBA。
前言
1. 我们简单地复习一下半同步的原理:
MySQL5.7 默认参数下我们开启了半同步,在一个事务提交(commit) 的过程时,在 MySQL 层的 write binlog 步骤后,Master 节点需要收到至少一个 Slave 节点回复的 ACK (表示收到了binlog )后,才能继续下一个事务;
如果在一定时间内(Timeout)内没有收到 ACK ,则切换为异步复制模式。
这能保证数据不丢失的高可用需求,因为他能保证从库确认到这个事务后,再通知主库提交事务。这种模式下,至少一个从库的日志数据和主库保证同步,从而保证主库挂了后,数据不丢失,因为最新数据的是从库。
2. 我先说一下我的半同步保证数据一致性的相关设置
sync_binlog=1
innodb_flush_log_at_trx_commit=1
...(等等)好了,不列出来了,我保证我半同步设置了最靠谱设置,不会因为参数设置错误而丢失数据。
3. 我再解释一下术语:
lossless semi-sync replication 、无损半同步、增强半同步,都是一回事,说的是 MySQL5.7 参数rpl_semi_sync_master_wait_point=AFTER_SYNC设置下的半同步,他是默认值,解决高可用切换后的幻读问题。MySQL5.6 没有这个参数设置,这个版本在高可用切换后有概率出现幻读,产生数据丢失,那就是数据不一致。如没有特别指出,本文的"半同步" 均指的是无损半同步。
4. 然后还有一点要注意的,kill -9 主库 mysqld 和 主动 shutdown 主库 mysqld 的行为引发高可用切换是不一样,后者行为有概率会导致幻读,也就是数据丢失,具体原因看这两篇文章详细了解。
《如何正确地关闭 MySQL 数据库?99%的 DBA 都是错的!》
5. 我确保我测试时,半同步复制没有降级为异步复制。
我上述说的,我假设大家都懂了,所以理论上,无损半同步复制下的主从高可用切换后数据一定一致吗?
客户角度
我先说答案,数据是一致的!但我这里说的数据一致,指的是,原主库上原先看到的数据库,在新主库(原备库)也是只能看到这些数据,不多也不少,也就是我指的是不会发生幻读。
主从角度
But!可能会有另外一种数据不一致,就是切换后,新主和旧主的数据不一致,旧主数据多了!
这篇文章,主要探讨,为什么在主从角度下,数据有可能不一致。
为什么旧主数据多了?
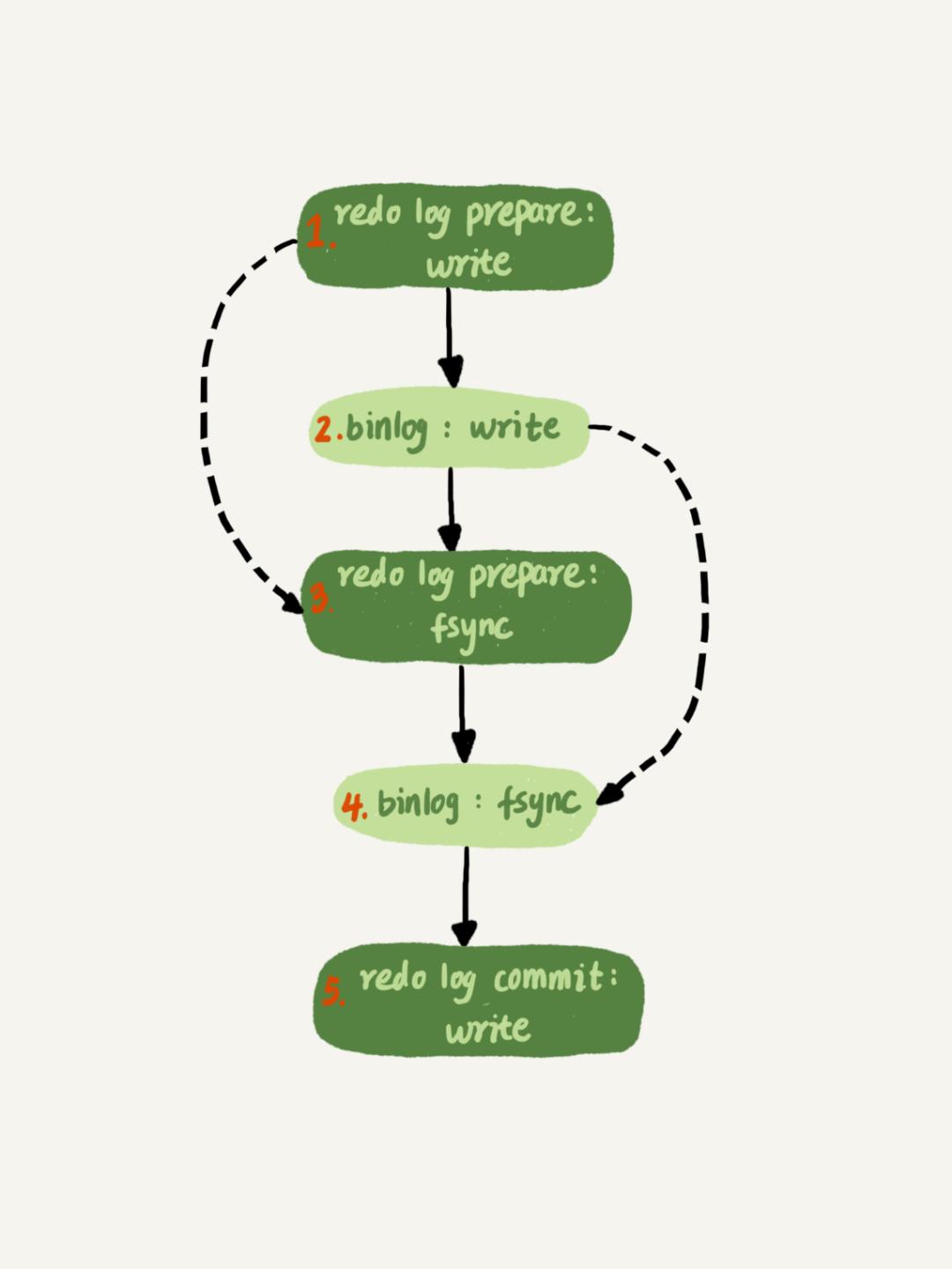
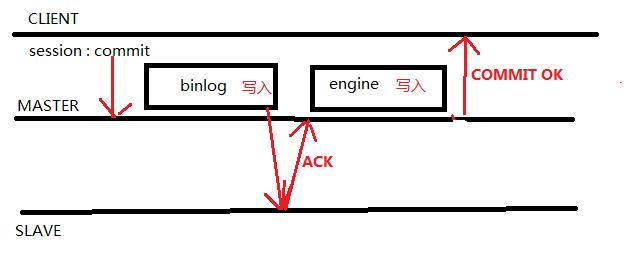
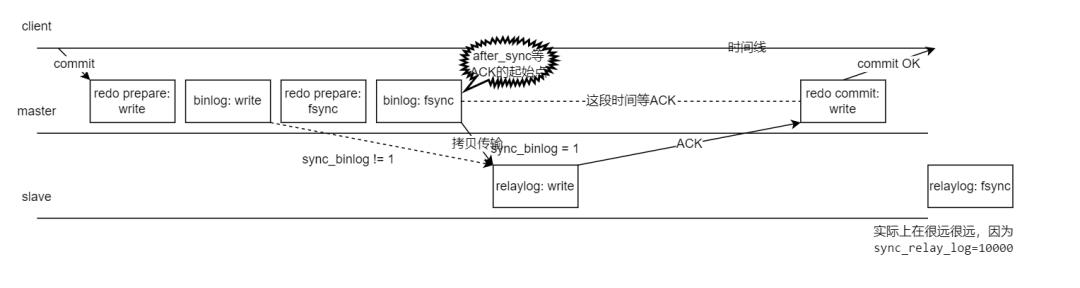
这两张网上流传很广的图,大家如果觉得似曾相似,那必须是资深 DBA 了。我整合了一下,再结合八怪的高清大图(《深入理解MySQL主从原理32讲》专栏第15节),画了以下这张原理图:
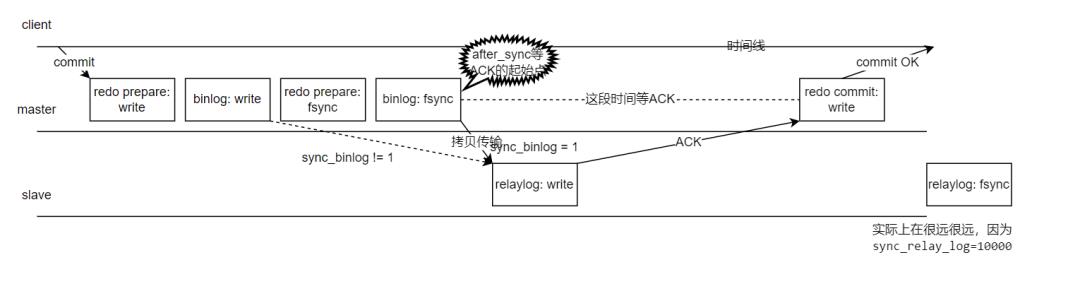
图中只关注 binlog、redo、relaylog 三个文件写入和刷盘行为。
图中 write 代表写入文件,对于 Linux 系统一般就是写入到 OS 的 page cache 了。这个时候服务器发生 crash,日志数据将丢失。
图中 fsync 代表 MySQL 调用 Linux 的 fsync 把 page cache 持久化到磁盘,我们称之为"刷盘"。
根据《深入理解MySQL主从原理32讲》专栏第15节,sync_binlog 设置不一样,MySQL 的 dump binlog 线程工作的起始点会不一样,我们本文用的是传说中最安全的双一设置,所以
sync_binlog=1,从库到主库拉去 binlog 的时间点发生在binlog: fsync后。
这里是步骤解释:
用户在 client 处执行 commit 提交了事务,主库写入了 redo 文件,对应"redo prepare: write"
binlog: write—— master 节点写入 binlog 文件。
redo prepare: fsync—— 传说中的两阶段提交的第一阶段 prepare 刷盘(从 OS 层 page cache 持久化刷新到硬盘)了。
binlog: fsync—— binlog 刷盘。
拷贝 binlog 到 slave 写入到 relaylog 文件,写完则返回 ACK 给 master 节点,表示收到这个 binlog 了,relaylog 根据参数
sync_relay_log=10000每 10000 个事务刷一次刷盘(因为我们只讨论主库 crash 的情况,这个从库 relay 刷盘行为我们不用管)根据参数设置
rpl_semi_sync_master_wait_point=AFTER_SYNC,所以在这个位置点开始等待 slave 节点完成"relaylog: write",然后返回个 ACK 给 master。master 节点收到 ACK 后,知道从库收到这个 binlog 后就可以提交事务了,发起"redo commit:write",传说中的两阶段提交的第二阶段 commit 阶段,commit 到文件。
master 回复客户端 ACK: commit OK。
其中,我设置了双一参数:
sync_binlog=1,表示事务提交之前,MySQL 都需要先把 BINLOG 刷新到磁盘
innodb_flush_log_at_trx_commit=1,表示在每次事务提交的时候,都把 log buffer (内存)刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。
我认为这里指的是刷 redo prepare 状态,redo commit 状态是不需要刷盘的,这是安全的,并且减少一次 io。懂源码的大佬欢迎打脸。
主库崩溃后主从复制的行为,我直接引用丁奇的《MySQL 45讲》第十五章的文字,有兴趣的同学可以直接去阅读原文。
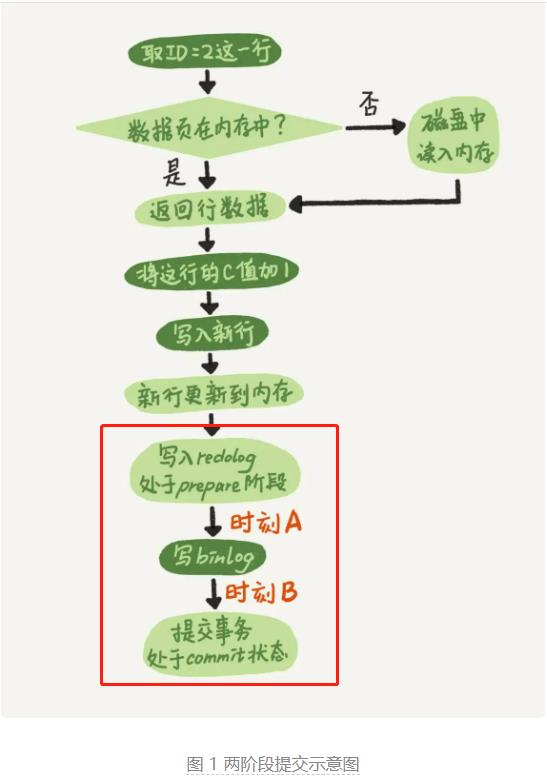
A 阶段对应的是我图的这个位置
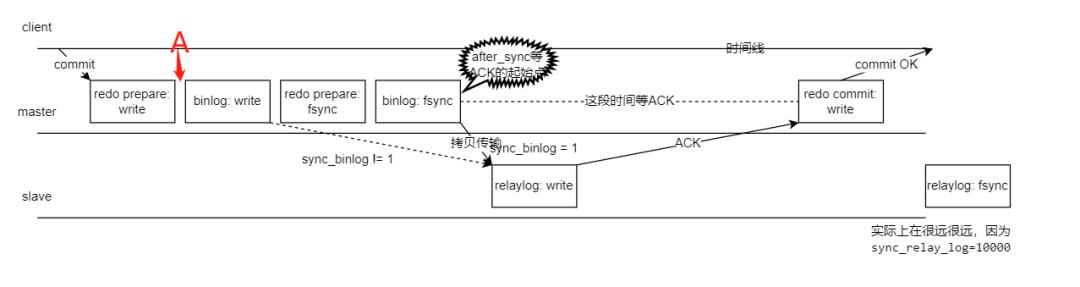
如果主库在 A 阶段发生了 crash,丁奇大佬这么说:

所以 A 阶段主库发生了 crash,主从数据会一致的。
B 阶段对应的是我图的这些位置,按丁奇的说法细分为三种可能,我单独标记了。
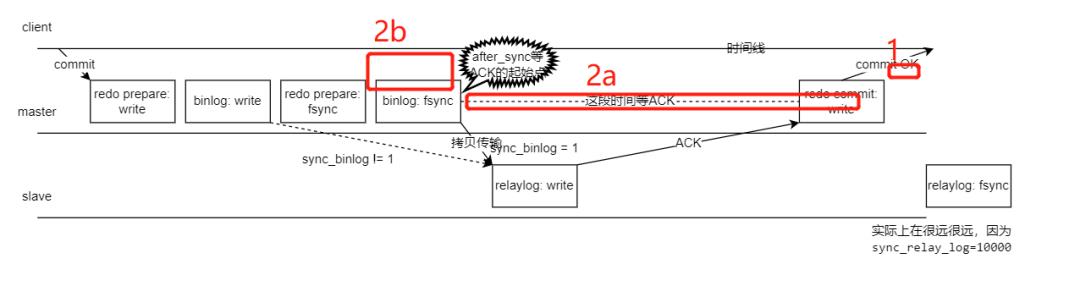
如果主库在 B 阶段发生了 crash,丁奇大佬这么说:

2(a) 这个情况下,主库承认 binlog 的数据,但在拷贝到从库时,我对丁奇大佬的说法又细分为两个阶段,分别是 2aa 和 2ab 阶段,如下图:
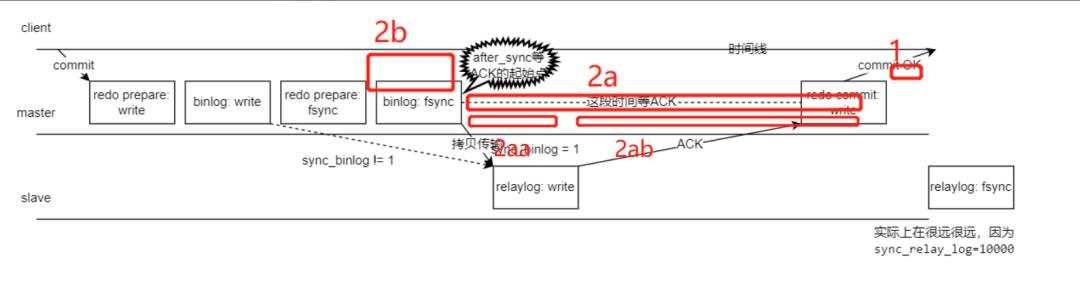
2aa 阶段: 这个阶段从库 relaylog 没有拷贝完,主库就挂了,那么从库是不认这些 relaylog 的,所以主库会多了事务。
2ab 阶段: 这个阶段从库 relaylog 已经拷贝完, ack 没有返回成功给主库,这个时候主库挂了,大家都基于相同的 binlog 承认相同的事务,数据是一致的。
数据不一致的最直接证明就是,高可用切换后,旧主库起来后 gtid 比新主库(原备库)要多。
老主库的 uuid 下的 gtid 编号要多。
测试
原理上,我们分析明白了,我们来实际测试一下,是不是真的会这样。
实验设计:
搭建一主一从半同步复制数据库
sysbench 压测主库几十秒后
kill -9 主库 mysqld
修改 mysqld_safe 或者 systemd 设置,确保防止主库自动被拉起来。
查看主库 binlog,查看从库show slave status\\G ,对比看两者 gtid 是否一致。
一开始,因为虚拟机,我的 sysbench 压测只能达到 20 tps时,测了好几次,都无法测出来问题。然后我调整了虚拟机的配置从 1 vcpu 升级到 8 vcpu,压测能压到 60 tps了上不去了,测了好几次,还是无法测出来问题。然后,我发现了瓶颈在于网络,因为我的 sysbench 连接数据库走的无线网卡了,我更换为走有线网卡后,压测性能达到了 200 tps。我调整压测的 lua 脚本,从 oltp_read_write 调整为 oltp_write_only,增加写 binlog 的机会,那更容易模拟到 gtid 不一致问题,并且此调整后 tps 涨到了 800。
终于,我模拟到了现象。
主库崩溃后,我查看从库情况,发现 gtid 跑到 283030 这个编号。
[root@192-168-199-132 3306]# mysql -uadmin -pGta@2019 -S /database/mysql/data/3306/mysqld.sock -e "show slave status\\G" |grep "ffc43852-1d82-11ed-a65f-000c29375703"
mysql: [Warning] Using a password on the command line interface can be insecure.
Master_UUID: ffc43852-1d82-11ed-a65f-000c29375703
Retrieved_Gtid_Set: ffc43852-1d82-11ed-a65f-000c29375703:210837-283030
Executed_Gtid_Set: ffc43852-1d82-11ed-a65f-000c29375703:1-283030接着,我解析主库的 binlog,发现多了红色的三条 gtid 编号。
[root@192-168-199-131 3306]# cat 16.txt | grep GTID |grep "ffc43852-1d82-11ed-a65f-000c29375703:28303"
SET @@SESSION.GTID_NEXT= 'ffc43852-1d82-11ed-a65f-000c29375703:283030'/*!*/;
SET @@SESSION.GTID_NEXT= 'ffc43852-1d82-11ed-a65f-000c29375703:283031'/*!*/;
SET @@SESSION.GTID_NEXT= 'ffc43852-1d82-11ed-a65f-000c29375703:283032'/*!*/;
SET @@SESSION.GTID_NEXT= 'ffc43852-1d82-11ed-a65f-000c29375703:283033'/*!*/;为什么这么难模拟
说难模拟也不难,只要 tps 高是很容易模拟出来的,这么难模拟出来,还有一个原因是, 2aa 阶段其实持续时间很短。
有一个技巧,使用《第02问:怎么模仿磁盘 IO 慢的情况?》》大佬黄炎提及的模拟 io 慢的方法,可以让你几乎每次都能模拟出来。
造一个慢的 io 设备 (好像只能造读写都慢的情况,没关系我们仅需要利用他读慢这个特性)
把它挂载到 binlog 盘
利用 io 设备的读很慢的特点,使从库拷贝 binlog 的持续时间拉长。如图 2aa 阶段。
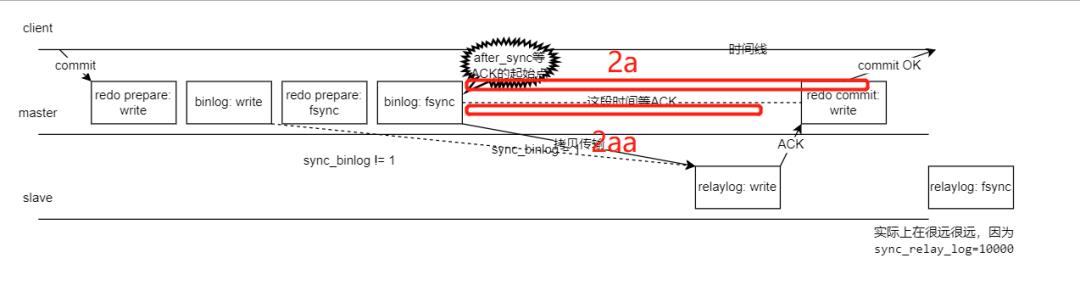
模拟网络慢应该也能达到类似效果
为什么差异了三条 gtid 而不是一条?
这个可能和组提交有关,也可能和并发线程有关,这里不方便展开研究,这可能是另一篇文章。
主从数据不一致,如何修复
方法一 重启优先于切换
很多情况下,主库 crash 后,会被 mysqld_safe 或者 systemd 服务自动拉起来,如果数据库重启速度很快,其实不一定要切换,RTO 也能得到保证。旧主有多的 gtid 没关系,拉起来后,gtid 会自动同步到从库,数据就不会不一致啦!
方法二 切换后补数据
我们知道 MHA 的切换的大概逻辑是这样的:
卸载旧主库 VIP
选主,选出有最新 gtid 的从库作为新主(我只有一个从库,就是选他了。。)
等待 sql thread 补齐数据(if 有复制延迟)
主从角色切换
io thread 级补数, ssh 到旧主拉取 binlog 补数(if 主库 binlog 和从库有 gtid 差异)
新主(原备库) 挂载VIP,去掉 read_only ,提供服务
也就是如果你用 MHA 这个高可用,基于 binlog pos 的传统复制模式下,发生了主从切换,并且主库的主机没死,能 ssh 过去的情况下,从库会拉去主库 binlog 来补数,数据不会不一致。
But! 很多 DBA 都知道了, MHA 在 gtid 模式下有 bug,他 5 这个流程是不走的。我们大多数人用的都是 gtid 复制模式下的 MySQL,所以这种情况下,主从数据是有概率不一致的。
方法三 切换后旧主 flashback 数据
我看沃趣和万里开源的技术人写的文章发现,他们玩法居然是不补数据,如果发现旧主多了 gtid 则 flashback 回退这些 gtid!这样旧主才可以作为新从,加回集群。
修复方法,从库补数,还是主库回滚,谁对谁错?
对于主从 gtid 差异的修复方法,居然分了两个派别:
从库补数据
主库回退数据
那么谁是对的谁是错的?答案是—— 都行!
在主库 crash 或kill -9这种情况下,mysql 客户端会返回 【ERROR 2013 (HY000) at line 1: Lost connection to MySQL server during query】。发生了这个报错,其实服务器是告诉你 “在执行查询的时候,你与服务器失去连接了”当你重新连上服务器后,你应该发起一次重连确认数据的。我举个例子假设你原本在主库上执行以下 SQL,一个叫 fander 的人给他老婆转账 10 万元。
begin;
update accounts set amount = amount - 100000 where account_id=1 and name='fander';
update accounts set amount = amount + 100000 where account_id=2 and name='fander's wife';
commit;这个时候如果处理这笔业务的 MySQL 服务器主库 crash 了,数据库给应用程序抛出的异常就类似于我刚才说的【ERROR 2013 (HY000) at line 1: Lost connection to MySQL server during query】,应用程序重连,连上了高可用切换后的新主库(原备库),本身就应该去查一下,转账成功没,转账成功就完事了,没成功那就再执行一次这条事务。
所以这个转账成功与否,是 MySQL 告诉他。你从库补数,还是不补数,是数据库层决定,然后告诉客户即可。
如果是主库 mysqld crash 了,在新主提供服务之前,可以选择基于远程拷贝 binlog,把旧主日志补到新主。但 server crash 了,从库已作为新主提供业务了,这时旧主不能再往新主补数据了,这会造成数据不一致!这个场景下,旧主要加回集群只有两种选择:
回退多余 gtid 建立复制,加回集群
对新主的备份,重做旧主,作为从库建立复制,加回集群。
扩展思考
有没有可能主从高可用切换后,不是主库比从库数据要多 gtid,而是从库要比主库要多 gtid?在sync_binlog=1的情况下不会。
因为主库 binlog 持久化后才会同步给从库,不可能从库的 binlog 会比主库要新。
但sync_binlog !=1的情况下,有两个原因会导致主库的 binlog 没有从库新。
binlog 不是每次事务都刷盘,主库挂了后,丢失一些事务。
即使每次刷盘也没用,因为 dump binlog 起始位置不一样,如果主库挂载在写入 binlog 后,网速很快完成传输到从库,但 binlog 还没有来得及 fsync 这种极限情况下发生了 crash,还是会导致主库丢失了这些 binlog,而从库承认了这些 binlog。
总结
无损半同步复制下,主从高可用切换后对于业务层面来说数据一致,对于运维层面来说,底层主从可能数据不一致,需要知道如何修复主从数据到一致。
参考
https://upload-images.jianshu.io/upload_images/7398834-4714e92068825403.png
https://mp.weixin.qq.com/s/uZ5cr0-bB6K3GbokBmORqA
https://mp.weixin.qq.com/s/1BuNsfVBRwnxe1BNjLeiWg
https://mp.weixin.qq.com/s/8JNv17llDfwMbTdBsTxhxQ
MySQL实战45讲丁奇(林晓斌)
《深入浅出MGR》视频课程
戳此小程序即可直达B站
https://www.bilibili.com/medialist/play/1363850082?business=space_collection&business_id=343928&desc=0
文章推荐:
想看更多技术好文,点个“在看”吧!
以上是关于无损半同步复制下,主从切换后数据一致吗?的主要内容,如果未能解决你的问题,请参考以下文章