用高并发技巧解决redis热key问题
Posted Java_LingFeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用高并发技巧解决redis热key问题相关的知识,希望对你有一定的参考价值。

这篇文章我将介绍工作中处理热key问题的常用手段,可能介绍的不是很全,毕竟不同的业务场景可能有不同的解决方案,但是相信通过这部分的介绍能提供一个热key问题的思路。
热key问题,简单来说就是对某一资源的访问量过高问题,再简单一点来说就是对某个资源访问的qps过高,而解决访问量高的问题通常我们使用分布式缓存,最常见的就是redis,这个资源对应redis的一个key简称热key。热key在开发中是非常常见的,比如各种app的榜单,活动页面上的一些资源。
虽然redis号称单节点能扛住10Wqps,但是开发中肯定不能这样去估计,毕竟安全第一,比如5000似乎就可能就可以作为上限。如果超过5000该怎么处理呢?下面将提供几种常见的解决方案。
冗余写/随机读
假设在做活动,活动总金额为amount,用户每次完成任务会得到一笔奖金,每天结算一次,在页面会展示剩余金额restAmount。我们将剩余金额存到redis中,key: pool, value: restAmount
由于每天统一结算,所以写的qps不会很高,毕竟我们能自己控制流量,比如用户完成后发个延迟结算消息到mq,然后由消费者来处理计算剩余金额最后更新到redis中。
但是在页面的读的qps是很高的。显然奖池pool就是个热key。
既然单节点扛不住,那么显然可以将数据写到N个节点上,也就是将奖池存到多个节点,在页面读取的时候随机选一个节点去读。假如有10W的qps,N=10,那么每个节点的流量就成了1W的qps。
大key问题与分shard处理
上面介绍的奖池问题显然不是大key问题,工作中常见的大key问题通常涉及到批量用户存储在set或者map中。举个不恰当的例子(之所以说不恰当是因为大量数据判存完全可以使用布隆过滤器)。假如同时存在若干个活动,对于每个活动,如果用户完成了,需要记录下用户完成情况,在后续页面进行对应的完成情况展示。这里可以使用map来处理,key:activityId, value:field:userId, value:完成情况
那么这显然是一个大key问题,同时也是个热点问题。但是用上面介绍的办法能解决热key问题,解决不了大key问题。
解决这个问题其实也可以采用分而治之的思路,就是将大key拆分为若干小key,并且尽量让若干小key存在不同的redis节点中。
比如对于一个活动id我可以分为10个shard,shard_1,...,shard_10,使用userId%10得到归属的shard。
这样每次判断取出用户完成情况,就先找到对应活动的shard然后拿出该用户即可。如果要拿出活动下的所有用户来做榜单,则只需要将所有shard都拿出来排序即可;
由于不同的shard在不同的redis节点,这样就又解决了热点问题。
本地缓存
如果条件允许的话,也就是本地缓存够用,或者说数据量不是很大,同时能够接受一定的延迟的话,那么可以直接使用本地缓存。这里就以guava的LoadingCache为例。
以奖池的例子来说,数据量小的忽略不计,因为结算时同一结算并更新奖池,也就是说一天中23个多小时数据都不会变,变动的时间也很短,所以我们可以接受一定的延迟,只要记得讲本地缓存过期时间设置短一点,比如10分钟。
此外需要有个地方供过期后的本地缓存读取,可以使用db或者redis,这样每次更新数据的时候就得更新db或者redis。为了防止击穿,记得使用load-miss方法。
LoadingCache<String, String> cache = CacheBuilder.newBuilder() .maximumSize(1000L) .expireAfterAccess(Duration.ofSeconds(600L)) .expireAfterWrite(Duration.ofSeconds(600L)) .build(new CacheLoader<String, String>() @Override public String load(String key) throws Exception // load from db ); String restAmount = cache.get("pool"); 复制代码
使用Memcached
这在公司基础架构用的会更多一点,为什么可以使用memcached,看下面两段话的介绍就知道了.
-
Redis是单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题;性能受限于CPU,单实例QPS在4-6w。Memcached是多线程,可以利用多核优势,单实例在正常情况下,可以达到写入60-80w qps,读80-100w qps。
-
Redis的big key与热key类操作,如果qps较高则容易造成redis阻塞,影响整体请求。Memcached因为是多线程,与redis相比,在big key与热key类操作上支持较好。
高并发架构系列:Redis并发竞争key的解决方案详解
需求由来
1.Redis高并发的问题
Redis缓存的高性能有目共睹,应用的场景也是非常广泛,但是在高并发的场景下,也会出现问题:缓存击穿、缓存雪崩、缓存和数据一致性,以及今天要谈到的缓存并发竞争。
这里的并发指的是多个redis的client同时set key引起的并发问题。
2.出现并发设置Key的原因
Redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以Redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对Redis进行并发访问时会出现问题。
比如:同时有多个子系统去set一个key。这个时候要注意什么呢?
3.举一个例子
多客户端同时并发写一个key,一个key的值是1,本来按顺序修改为2,3,4,最后是4,但是顺序变成了4,3,2,最后变成了2。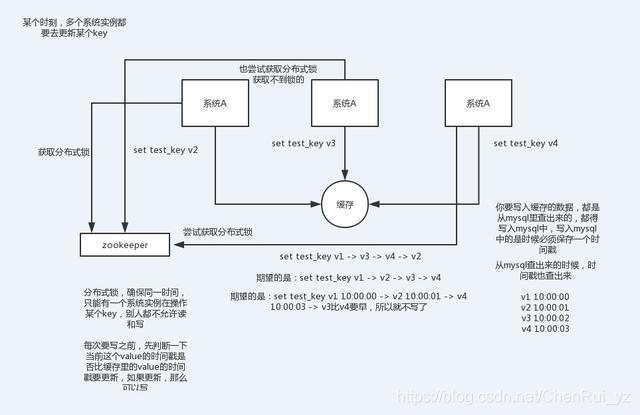
如何解决redis的并发竞争key问题呢?下面给到2个Redis并发竞争的解决方案。
第一种方案:分布式锁+时间戳
1.整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
加锁的目的实际上就是把并行读写改成串行读写的方式,从而来避免资源竞争。
2.Redis分布式锁的实现
主要用到的redis函数是setnx()
用SETNX实现分布式锁
利用SETNX非常简单地实现分布式锁。例如:某客户端要获得一个名字youzhi的锁,客户端使用下面的命令进行获取:
SETNX lock.youzhi<current Unix time + lock timeout + 1>
如返回1,则该客户端获得锁,把lock.youzhi的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
3.时间戳
由于上面举的例子,要求key的操作需要顺序执行,所以需要保存一个时间戳判断set顺序。
系统A key 1 ValueA 7:00
系统B key 1 ValueB 7:05
假设系统B先抢到锁,将key1设置为ValueB 7:05。接下来系统A抢到锁,发现自己的key1的时间戳早于缓存中的时间戳(7:00<7:05),那就不做set操作了。
4.什么是分布式锁
因为传统的加锁的做法(如java的synchronized和Lock)这里没用,只适合单点。因为这是分布式环境,需要的是分布式锁。
当然,分布式锁可以基于很多种方式实现,比如zookeeper、redis等,不管哪种方式实现,基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
第二种方案:利用消息队列
在并发量过大的情况下,可以通过消息中间件进行处理,把并行读写进行串行化。
把Redis.set操作放在队列中使其串行化,必须的一个一个执行。
这种方式在一些高并发的场景中算是一种通用的解决方案。
以上就是Redis并发竞争key技术方案详解,相关的Redis高并发问题具体还可以参考:高并发架构系列:如何解决Redis雪崩、穿透、并发等5大难题
参考:高并发架构系列:Redis并发竞争key的解决方案详解
以上是关于用高并发技巧解决redis热key问题的主要内容,如果未能解决你的问题,请参考以下文章